Assignment 9
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

MAYER Is DECA's STAR
Volume XXXXIII Number 36 Sept. (1), 2018 MAYER is DECA’s STAR 9126 Score in Talence is New World Record Hello Again……By exactly 100 points more than the first 9000 score 17 years ago (Roman Sebrle/CZE-Götzis, 2001) 26 year old Kevin Mayer of France delighted a packed house of local fans in Bordeaux’s wine country the become the first of his nation to set a decathlon world record. For Mayer, the IAAF world champ the 9k performance was not exactly a surprise given his recent improvements and marks in open events. His goal was to go after the record at August’s European Championships in Berlin but after a sprint PR he fouled on three consecutive long jump attempts and resigned. Ala Dan O’Brien in 1992 who nh’d at the US France’s Kevin Mayer came away with a new decathlon Olympic Trials and then went to DecaStar in world record at DecaStar in Talence, 9126 points. Talence taking the global standard away On a day when the world marathon record from Daley Thompson, Mayer made the was lowered to 2:01.39, this will go dawn as IAAF CE Challenge meet in Talence the one of T&F’s finest moments. focus of his season. He came to DecaStar One American started, Steven looking for the record. Until then O’Brien’s Bastien who nh’d in the vault while standing 8893 was still the stadium record in Talence. in 6th place overall. A 16 man field started on Saturday, Sept 15, and from the start it was all about the record! A huge PR 10.55 l00m, set him A comparison of the World records: up and, at the end of the first day he piled up Mayer 2018 Talence 4563 points, 140 down on Ashton Eaton’s 9126 10.55+0.3 780+1.2 1600 205 48.42 4563 record pace. -

Shot Put Diamond Race 19.07.2018
Men's Shot Put Diamond Race 19.07.2018 Start list Shot Put Time: 19:15 Records Order Athlete Nat NR PB SB 1 Kevin MAYER FRA 20.72 16.51 16.51 WR 23.12 Randy BARNES USA Westwood 20.05.90 2 Frederic DAGEE FRA 20.72 20.04 20.04 AR 23.06 Ulf TIMMERMANN GDR Chania 22.05.88 3 Curtis JENSEN USA 23.12 21.63 21.63 NR 11.00 Sébastien GATTUSO MON Arles 20.05.07 WJB 21.14 Konrad BUKOWIECKI POL Oslo 09.06.16 4 David STORL GER 23.06 22.20 21.18 MR 22.56 Joe KOVACS USA 17.07.15 5 Darlan ROMANI BRA 21.95 21.95 21.95 DLR 22.56 Joe KOVACS USA Monaco 17.07.15 6 Darrell HILL USA 23.12 22.44 21.57 SB 22.67 Tomas WALSH NZL Auckland 25.03.18 7 Tomáš STANĚK CZE 22.01 22.01 21.46 8 Michał HARATYK POL 22.08 22.08 22.08 9 Ryan CROUSER USA 23.12 22.65 22.53 2018 World Outdoor list 10 Tomas WALSH NZL 22.67 22.67 22.67 22.67 Tomas WALSH NZL Auckland 25.03.18 22.53 Ryan CROUSER USA Eugene, OR 26.05.18 22.08 Michał HARATYK POL Ostrava 13.06.18 21.95 Darlan ROMANI BRA Eugene, OR 26.05.18 Medal Winners Road To The Final 21.63 Curtis JENSEN USA Bragança 08.07.18 21.57 Darrell HILL USA Des Moines, IA 23.06.18 1 Tomas WALSH (NZL) 21 21.46 Tomáš STANĚK CZE Ostrava 13.06.18 2017 - London IAAF World Ch. -

— 2010 T&FN Men's World Rankings —
— 2010 T&FN Men’s World Rankings — 100 METERS 1500 METERS 110 HURDLES 1. Tyson Gay (US) 1. Asbel Kiprop (Kenya) 1. David Oliver (US) 2. Usain Bolt (Jamaica) 2. Amine Laâlou (Morocco) 2. Dayron Robles (Cuba) 3. Asafa Powell (Jamaica) 3. Silas Kiplagat (Kenya) 3. Dwight Thomas (Jamaica) 4. Nesta Carter (Jamaica) 4. Augustine Choge (Kenya) 4. Ryan Wilson (US) 5. Yohan Blake (Jamaica) 5. Mekonnen Gebremedhin (Ethiopia) 5. Ronnie Ash (US) 6. Richard Thompson (Trinidad) 6. Leonel Manzano (US) 6. Joel Brown (US) 7. Daniel Bailey (Antigua) 7. Nicholas Kemboi (Kenya) 7. Andy Turner (Great Britain) 8. Michael Frater (Jamaica) 8. Daniel Komen (Kenya) 8. David Payne (US) 9. Mike Rodgers (US) 9. Andrew Wheating (US) 9. Petr Svoboda (Czech Republic) 10. Christophe Lemaitre (France) 10. Ryan Gregson (Australia) 10. Garfield Darien (France) 200 METERS STEEPLECHASE 400 HURDLES 1. Walter Dix (US) 1. Paul Koech II (Kenya) 1. Bershawn Jackson (US) 2. Wallace Spearmon (US) 2. Ezekiel Kemboi (Kenya) 2. Kerron Clement (US) 3. Usain Bolt (Jamaica) 3. Richard Matelong (Kenya) 3. Javier Culson (Puerto Rico) 4. Tyson Gay (US) 4. Brimin Kipruto (Kenya) 4. Dai Greene (Great Britain) 5. Yohan Blake (Jamaica) 5. Benjamin Kiplagat (Uganda) 5. Angelo Taylor (US) 6. Ryan Bailey (US) 6. Mahiedine 6. Johnny Dutch (US) 7. Steve Mullings (Jamaica) Mekhissi-Benabbad (France) 7. Justin Gaymon (US) 8. Xavier Carter (US) 7. Roba Gari (Ethiopia) 8. Félix Sánchez (Dominican Rep) 9. Angelo Taylor (US) 8. Bob Tahri (France) 9. LJ van Zyl (South Africa) 10. Churandy Martina 9. Patrick Langat (Kenya) 10. Isa Phillips (Jamaica) (Netherlands Antilles) 10. -

23.12.2011 7 Kg; 107 Cm; 2 Kg; 800 G 20110109 Campbelltown 1137 00 673 +25 1326 193 4946 1553 00 3397 460 5463 44563 1 Jarrod Si
23.12.2011 7 kg; 107 cm; 2 kg; 800 g 20110109 Campbelltown 1 Jarrod Sims 7215 1137 00 673 +25 132619349461553 00 3397460546344563 20110213 Tauranga 1 Brent Newdick 7296 1132 +01 701 00 134518951101547 -07 4329440530944763 2 Scott McLaren 7036 1162 +01 678 00 138318650601612 -07 3857450527045017 20110217 Qatif 1 Mohamed Ridha Al-Matroud 6864 1118 -04 692 130817550381528 -07 3866390510950232 20110227 Melbourne 1 Stephen Cain 7416 1143 00 676 +16 133019350511522 -06 3737480556443375 2 Jarrod Sims 7155 1126 00 670 -05 128119649561587 -06 3731440515544478 20110317 Houston 1 Jon Ryan Harlan 7720 1122 -11 680 -04 149819950901455 +07 4325490610750791 20110318 La Habana 1 Jose Angel Mendieta Errasti 7404 1122 -18 730 00 153619252171462 -13 3780400633850629 2 Juan Gilberto Alcazar Oquendo 7200 1166 -18 696 +18 117919851721553 -13 3866440545242913 3 Danilo Rey Batista 7078 1137 -18 697 00 113218650061492 -13 3841360597243676 4 Manuel Gonzalez 6817 1188 -18 667 +05 140019553121597 -13 3891380519443886 20110318 Northridge 1 Benjamin Dillow 7145 1142 +29 646 +18 123818951091525 +09 4249435517343319 20110318 San Diego 1 Derek Steinbach 6801 1148 628 +09 133418654281564 +01 4069435563650187 20110320 Sao Paulo 1 Carlos Eduardo Bezerra Chinin 7581 1121 -33 758 +21 134320249601470 -39 3892440549750304 2 Danilo Mendes Xavier 7217 1140 -33 735 +23 133519051211531 -39 3884420571850000 3 Renato Atila Souza da Camara 7117 1166 -07 725 +47 132319652101527 -39 4160440487750327 20110325 San Angelo 1 Brent Vogel 7238 W 1116 +41 688 +53 117718648991495 +19 3775405554543395 -

Schippers Shatters European Record
22 Saturday, August 29, 2015 SPORTS SPORTS Saturday, August 29, 2015 23 Enters Winston-Salem semis Rain washes out DAY 7 ANDERSON SHINES play in Colombo Thomaz Bellucci 6-3, 6-2. American Steve Johnson reached the final four without lifting a racquet as Lu Yen- Hsun of Taiwan withdrew from their quarter-final with a back injury sustained in a three-set win over South Korea’s Chung MEDALS TALLY Hyeon. “It happened at the end Rank COUNTRY GOLD SILVER BRONZE TOTAL of the match yesterday,” LIU Lu said. “There is some 1 KENYA 6 3 2 11 inflammation in a disk, which causes the muscles to tighten 2 UNITED STATES 4 4 6 14 up. It’s difficult for me to extend my body, especially Sri Lankan cricketer Dhammika Prasad (2right) celebrates with 3 JAMAICA 4 2 3 9 backwards.” Johnson, bidding teammates to reach his first career final Colombo opening Test in Galle by 63 WINS 4 G BRITAIN & N.I. 3 1 0 4 on the ATP Tour, will face ri Lanka gave India a scare runs and India drew level with French qualifier Pierre- before bad weather washed a 278-run win in the second 5 POLAND 2 1 3 6 Hugues Herbert, who needed outS a major part of the opening match at the P. Sara Oval in one hour and 57 minutes to day’s play in the series-deciding Colombo on Monday. overcome Spaniard Pablo third and final Test in Colombo The hard-working champion, timed 10.23sec in the Olympic champion Ivan Ukhov Kevin Anderson celebrates Carreno-Busta 4-6, 7-6 (7/5), yesterday. -

A Comeback for Dawn Harper Nelson Delayed
Track & Field News January 2021 — 2 TABLE OF CONTENTS Volume 74, No. 1 January 2021 From The Editor — What? There’s No 2020 World Rankings?! . 4 T&FN’s 2020 Podium Choices . 5 — T&FN’s 2020 World Men’s Track Podiums — . 6 — T&FN’s 2020 World Men’s Field Podiums — . 10 T&FN’S 2020 Men’s MVP — Mondo Duplantis . 15 Mondo Duplantis Figures He Still Has Many Years To Go . 16 — T&FN’s 2020 World Women’s Track Podiums — . 18 — T&FN’s 2020 World Women’s Field Podiums — . 22 T&FN’S 2020 Women’s MVP — Yulimar Rojas . 27 T&FN’s 2020 U .S . MVPs — Ryan Crouser & Shelby Houlihan . 28 Focus On The U .S . Women’s 100 Hurdles Scene . 29 Keni Harrison Looking For Championships Golds . 31 Brianna McNeal Ready To Defend Her Olympic Title . 33 A Comeback for Dawn Harper Nelson Delayed . 34 Sharika Nelvis Keeps On Moving Forward . 35 Christina Clemons Had A Long Road Back . 36 T&FN Interview — Grant Holloway . 37 Track News Digest . 41 Jenna Hutchins Emerges As The Fastest HS 5000 Runner Ever . 43 World Road Digest . 45 U .S . Road Digest . 46 Analysis: The Wavelight Effect . 47 Seb Coe’s Pandemic-Year Analysis . 51 STATUS QUO . 55 ON YOUR MARKS . 56 LAST LAP . 58 LANDMARKS . 61 FOR THE RECORD . 62 CALENDAR . 63 • cover photo of Mondo Duplantis by Jean-Pierre Durand • Track & Field News January 2021 — 3 FROM THE EDITOR Track & Field News The Bible Of The Sport Since 1948 — What? There’s No Founded by Bert & Cordner Nelson E. -

Updated April 12Th 2017 2016/2017 AAP SPORT
2016/2017 AAP SPORT CANADA APPROVED NOMINATION LIST – ATHLETICS Name Event Hometown Personal Lead Coach Training Location Club Affiliation Branch SR1 Mohammed Ahmed 5000m St. Catharines, ON Jerry Schumacher Eugene, OR Nike Bowerman Track Club ON Khamica Bingham 4x100m Relay Caledon, ON Charles Allen Toronto, ON Brampton Track Club ON Melissa Bishop 800m Eganville, ON Dennis Fairall Windsor, ON Ottawa Lions Track and Field ON Aaron Brown 4x100m Relay Toronto, ON Dennis Mitchell Clermont, FL Star Athletics ON Johnathan Cabral 110mH Peribonka, QC Jamie Cook Eugene, OR Kitchener-Waterloo ON Andre De Grasse 200m Markham, ON Stuart McMillan Phoenix, AZ Altis World ON Derek Drouin High Jump Corunna, ON Jeff Huntoon Toronto, ON Sarnia Athletics Southwest ON Evan Dunfee 50km Race Walk Richmond, BC Gerry Dragomir Vancouver, BC Racewalk West BC Crystal Emmanuel 4x100m Relay East York, ON Charles Allen Toronto, ON Flying Angels Track Club ON Phylicia George 100mH Markham, ON Dennis Shaver Baton Rouge, LA Flying Angels Track Club ON Akeem Haynes 4x100m Relay Calgary, AB Stuart McMillan Phoenix, AZ Altis World AB Farah Jacques 4x100m Relay Gatineau, QC Glenroy Gilbert Ottawa, ON Perfmax-Racing QC Noelle Montcalm 4x400m Relay Belle River, ON Don Garrod Windsor, ON Univ. of Windsor Athletics Club ON Carline Muir 4x400m Relay Edmonton, AB Nick Dakin Loughborough, UK Unattached ON Brendon Rodney 4x100m Relay Brampton, ON Simon Hodnett Long Island, NY HEAT Athletics ON Damian Warner Decathlon London, ON Les Gramantik Calgary, AB Unattached ON SR2 Shawnacy -
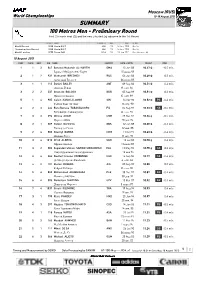
SUMMARY 100 Metres Men - Preliminary Round First 2 in Each Heat (Q) and the Next 3 Fastest (Q) Advance to the 1St Round
Moscow (RUS) World Championships 10-18 August 2013 SUMMARY 100 Metres Men - Preliminary Round First 2 in each heat (Q) and the next 3 fastest (q) advance to the 1st Round RESULT NAME COUNTRY AGE DATE VENUE World Record 9.58 Usain BOLT JAM 23 16 Aug 2009 Berlin Championships Record 9.58 Usain BOLT JAM 23 16 Aug 2009 Berlin World Leading 9.75 Tyson GAY USA 31 21 Jun 2013 Des Moines, IA 10 August 2013 RANK PLACE HEAT BIB NAME COUNTRY DATE of BIRTH RESULT WIND 1 1 3 847 Barakat Mubarak AL-HARTHI OMA 15 Jun 88 10.47 Q -0.5 m/s Баракат Мубарак Аль -Харти 15 июня 88 2 1 2 932 Aleksandr BREDNEV RUS 06 Jun 88 10.49 Q 0.3 m/s Александр Бреднев 06 июня 88 3 1 1 113Daniel BAILEY ANT 09 Sep 86 10.51 Q -0.4 m/s Даниэль Бэйли 09 сент . 86 3 2 2 237Innocent BOLOGO BUR 05 Sep 89 10.51 Q 0.3 m/s Инносент Болого 05 сент . 89 5 1 4 985 Calvin KANG LI LOONG SIN 16 Apr 90 10.52 Q PB -0.4 m/s Кэлвин Канг Ли Лонг 16 апр . 90 6 2 3 434 Ratu Banuve TABAKAUCORO FIJ 04 Sep 92 10.53 Q SB -0.5 m/s Рату Бануве Табакаукоро 04 сент . 92 7 3 3 296Idrissa ADAM CMR 28 Dec 84 10.56 q -0.5 m/s Идрисса A дам 28 дек . 84 8 2 1 509Holder DA SILVA GBS 12 Jan 88 10.59 Q -0.4 m/s Холдер да Силва 12 янв . -

Men's Pole Vault International 02.09.2015
Men's Pole Vault International 02.09.2015 Start list Pole Vault Time: 18:00 Records Order Athlete Nat PB SB WR 6.16Renaud LAVILLENIE FRA Donetsk 15.02.14 1 Marquis RICHARDS SUI 5.55 5.30 AR 6.16Renaud LAVILLENIE FRA Donetsk 15.02.14 2 Mitch GREELEY USA 5.56 5.50 NR 5.71Felix BÖHNI SUI Bern 11.06.83 3 Carlo PAECH GER 5.80 5.80 WJR 5.80Maxim TARASOV URS Bryansk 14.07.89 4 Tobias SCHERBARTH GER 5.73 5.70 WJR 5.80 Raphael HOLZDEPPE GER Biberach 28.06.08 5 Konstantinos FILIPPIDIS GRE 5.91 5.91 MR 5.95Igor TRANDENKOV RUS 14.08.96 DLR 6.05Renaud LAVILLENIE FRA Eugene 30.05.15 6 Piotr LISEK POL 5.82 5.82 SB 6.05Renaud LAVILLENIE FRA Eugene 30.05.15 7 Paweł WOJCIECHOWSKI POL 5.91 5.84 8 Raphael HOLZDEPPE GER 5.94 5.94 2015 World Outdoor list 9 Shawn BARBER CAN 5.93 5.93 6.05Renaud LAVILLENIE FRA Eugene 30.05.15 5.94Raphael HOLZDEPPE GER Nürnberg 26.07.15 5.93Shawn BARBER CAN London 25.07.15 Medal Winners Zürich previous Winners 5.92Thiago BRAZ BRA Baku 24.06.15 2015 - Beijing IAAF World Ch. 12 Renaud LAVILLENIE (FRA) 5.70 5.91Konstantinos FILIPPIDIS GRE Paris 04.07.15 1. Shawn BARBER (CAN) 5.90 07 Igor PAVLOV (RUS) 5.75 5.84Paweł WOJCIECHOWSKI POL Lausanne 09.07.15 2. Raphael HOLZDEPPE (GER) 5.90 06 Brad WALKER (USA) 5.85 5.82Sam KENDRICKS USA Des Moines 25.04.15 3. -

P 001 WJ Recs
IAAF WORLD U20 CHAMPIONSHIPS Facts & Figures IAAF World U20 Records .......................................................................................1 IAAF World U20 Championship Records (& Best Performances)..........................3 Summary of Past Championships ..........................................................................5 Superlatives..........................................................................................................16 Placing Tables ......................................................................................................17 Country Index .......................................................................................................20 BYDGOSZCZ 2016 ★ FACTS & FIGURES/WORLD U20 RECORDS 1 IAAF WORLD U20 RECORDS * Awaiting ratification as at July 15, 2016 MEN Wind # = No longer an IAAF World U20 record event, this is the last record to be ratified 100 Metres 9.97 Travyon Bromell USA Eugene 14 Jun 14 1.8 200 Metres 19.93 Usain Bolt JAM Devonshire 11 Apr 04 1.4 400 Metres 43.87 Steve Lewis USA Seoul 28 Sep 88 800 Metres 1:41.73 Nijel Amos BOT London 9 Aug 12 1000 Metres 2:15.00 Benjamin Kipkirui KEN Nice 17 Jul 99 1500 Metres 3:28.81 Ronald Kwemoi KEN Monaco 18 Jul 14 One Mile 3:49.29 William Biwott KEN Oslo 3 Jul 09 (now İlham Tanui Özbilen TUR) 3000 Metres 7:28.78 Augustine Choge KEN Doha 13 May 05 5000 Metres 12:47.53 Hagos Gebrhiwet ETH Paris 6 Jul 12 10,000 Metres 26:41.75 Samuel Wanjiru KEN Bruxelles 26 Aug 05 2000m Steeplechase# 5:25.01 Arsenios Tsiminos GRE Athína 2 -

Pot De Départ De Julia Blain
Pot de départ de Julia Blain Revue hebdomadaire des Résidences - Services ABCD Edito SOMMAIRE Bonjour à tous ! L'ACTU dES RéSIdEnCES Cette semaine dans Ça Bouge, Julia Les AteLiers CAssiopée Blain, animatrice à l'Accueil de Jour de la résidence de l'Abbaye a célébré FAmiLéo son départ en retraite entourée des bénéficiaires de l'Accueil de jour et sUiVeZ NoUs sUr FACeBooK du personnel. pot de dépArt à LA retrAite Les bénéficiaires de l'Accueil de de JULiA BLAiN Jour ont lors d'un après midi profité du soleil à Champigny plage sur les sortie des BéNéFiCiAires Bords de marne. L'accueiL de JoUr à ChAmpigNy pLAge d'autre part, vous retrouverez dans ce numéro différents articles sociéTé abordants des sujets de société ou Vers la FiN de L’heUre d’hiVer encore de sport. eN Europe ? Bonne semaine à tous. Animaux CanadA: UN narval soLitAire olivia Bouhours Adopté pAr un groUpe de Asistante de communication BélugAs SociéTé Les JoUrNées dU pAtrimoiNe AttireNt 12 millioNs de VisiteUrs Sport KeViN Mayer bat Le reCord dU moNde dU décathLoN JEUx Ça Bouge n°1374 Calendrier des RésidEnces 22 > 28 Septembre 2018 2 actu dE L'AbbAyE RÉSIDENCES - SERVICES POUR PERSONNES ÂGÉES Abbaye - Bords de Marne - Cité Verte Cristolienne - Domicile & Services 3 actu dES RéSIdEnCES Familéo : Faciliter les échanges entre familles, proches et Résidents Nous avons le plaisir de vous informer de la mise en place du service « Familéo » : un réseau social privé, personnel, et gratuit. • Une gazette pour votre parent réalisée par vous Familéo met en contact, à travers l’outil informatique, les résidents avec leurs familles et proches de manière sécurisée et totalement privée. -

Decathlon Final Results
Moscow (RUS) World Championships 10-18 August 2013 DECATHLON FINAL RESULTS RESULT NAME COUNTRY AGE DATE VENUE World Record 9039 Ashton EATON USA 24 23 Jun 2012 Eugene, OR Championships Record 8902 Tomáš DVORÁK CZE 29 7 Aug 2001 Edmonton World Leading 8809 Ashton EATON USA 25 11 Aug 2013 Moscow POINTS RANK-HEAT RESULT 100 Metres Long Jump Shot Put High Jump 400 Metres 110 Metres Discus Pole Vault Javelin 1500 Metres Hurdles Throw Throw PLACE BIB NAME COUNTRY RESULT 1123 Ashton EATON USA 8809 1011 992 752 740 1007 1011 767 972 811 746 1 1-4 3-A 12-A 7-B 1-4 1-4 12-A 3-A 4-B 6-2 Аштон Итон WL 10.35 7.73 14.39 1.93 46.02 13.72 45.00 5.20 64.83 4:29.80 544 Michael SCHRADER GER 8670 922 1022 763 794 926 937 797 910 824 775 2 6-4 1-A 9-A 4-B 1-2 7-4 4-A 9-A 6-A 5-2 Михаэль Шредер PB 10.73 7.85 14.56 1.99 47.66 14.29 46.44 5.00 65.67 4:25.38 260 Damian WARNER CAN 8512 992 908 742 850 889 980 749 849 808 745 3 2-4 4-B 1-B 8-A 5-4 3-4 1-B 4-B 5-B 7-2 Дэмиан Уорнер PB 10.43 7.39 14.23 2.05 48.41 13.96 44.13 4.80 64.67 4:29.97 464 Kevin MAYER FRA 8446 810 935 714 850 836 948 774 972 830 777 4 8-3 8-A 16-A 7-A 2-2 1-1 9-A 4-A 2-B 4-2 Кевин Майер PB 11.23 7.50 13.76 2.05 49.53 14.21 45.37 5.20 66.09 4:25.04 824 Eelco SINTNICOLAAS NED 8391 894 972 733 822 897 951 649 1004 689 780 5 8-4 4-A 3-B 9-A 3-4 5-4 9-B 2-A 12-B 3-2 Эелко Синтниколаас SB 10.85 7.65 14.08 2.02 48.25 14.18 39.21 5.30 56.75 4:24.64 212 Carlos CHININ BRA 8388 910 945 758 767 871 968 784 941 738 706 6 1-3 6-A 10-A 13-A 8-4 4-4 7-A 8-A 8-B 9-2 Карлос Чинин 10.78 7.54 14.49 1.96 48.80