The Evolution, Current Status, and Future Direction of XML
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2004/WD-xml-media-types-20041102 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP (formerly of Oracle) Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list and in the section C Change Log [p.11] . A diff-marked version against the previous version of this document is available. -
XML Specifications Growth of the Web
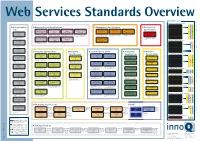
Web Services Standards Overview Dependencies Messaging Specifications SOAP 1.1 SOAP 1.2 Interoperability Business Process Specifications Management Specifications Presentation SOAP Message Transmission Optimization Mechanism WS-Notification the trademarks of their respective owners. of their respective the trademarks Management Using Web Management Of WS-BaseNotification Issues Business Process Execution WS-Choreography Model Web Service Choreography Web Service Choreography WS-Management Specifications Services (WSDM-MUWS) Web Services (WSDM-MOWS) Language for Web Services 1.1 Overview Interface Description Language AMD, Dell, Intel, Microsoft and Sun WS-Topics (BPEL4WS) · 1.1 · BEA Systems, IBM, (WSCI) · 1.0 · W3C 1.0 1.0 1.0 · W3C (CDL4WS) · 1.0 · W3C Microsystems Microsoft, SAP, Sun Microsystems, SAP, BEA Systems WS-BrokeredNotification Working Draft Candidate Recommendation OASIS OASIS Published Specification Web Services for Remote Security Resource Basic Profile Siebel Systems · OASIS-Standard and Intalio · Note OASIS-Standard OASIS-Standard Metadata Portlets (WSRP) WS-Addressing – Core 1.1 ̆ ̆ ̆ ̆ ̆ ̆ ̆ 2.0 WS-I Business Process Execution Language for Web Services WS-Choreography Model Overview defines the format Web Service Choreography Interface (WSCI) describes Web Service Choreography Description Language Web Service Distributed Management: Management Using Web Service Distributed Management: Management Of WS-Management describes a general SOAP-based WS-Addressing – WSDL Binding 1.1(BPEL4WS) provides a language for the formal -

Genesys Voice Platform 7.6 Voicexml 2.1 Reference Manual
Genesys Voice Platform 7.6 VoiceXML 2.1 Reference Manual The information contained herein is proprietary and confidential and cannot be disclosed or duplicated without the prior written consent of Genesys Telecommunications Laboratories, Inc. Copyright © 2006–2010 Genesys Telecommunications Laboratories, Inc. All rights reserved. About Genesys Alcatel-Lucent's Genesys solutions feature leading software that manages customer interactions over phone, Web, and mobile devices. The Genesys software suite handles customer conversations across multiple channels and resources—self-service, assisted-service, and proactive outreach—fulfilling customer requests and optimizing customer care goals while efficiently using resources. Genesys software directs more than 100 million customer interactions every day for 4000 companies and government agencies in 80 countries. These companies and agencies leverage their entire organization, from the contact center to the back office, while dynamically engaging their customers. Go to www.genesyslab.com for more information. Each product has its own documentation for online viewing at the Genesys Technical Support website or on the Documentation Library DVD, which is available from Genesys upon request. For more information, contact your sales representative. Notice Although reasonable effort is made to ensure that the information in this document is complete and accurate at the time of release, Genesys Telecommunications Laboratories, Inc., cannot assume responsibility for any existing errors. Changes and/or corrections to the information contained in this document may be incorporated in future versions. Your Responsibility for Your System’s Security You are responsible for the security of your system. Product administration to prevent unauthorized use is your responsibility. Your system administrator should read all documents provided with this product to fully understand the features available that reduce your risk of incurring charges for unlicensed use of Genesys products. -

XML Signature/Encryption — the Basis of Web Services Security
Special Issue on Security for Network Society Falsification Prevention and Protection Technologies and Products XML Signature/Encryption — the Basis of Web Services Security By Koji MIYAUCHI* XML is spreading quickly as a format for electronic documents and messages. As a consequence, ABSTRACT greater importance is being placed on the XML security technology. Against this background research and development efforts into XML security are being energetically pursued. This paper discusses the W3C XML Signature and XML Encryption specifications, which represent the fundamental technology of XML security, as well as other related technologies originally developed by NEC. KEYWORDS XML security, XML signature, XML encryption, Distributed signature, Web services security 1. INTRODUCTION 2. XML SIGNATURE XML is an extendible markup language, the speci- 2.1 Overview fication of which has been established by the W3C XML Signature is an electronic signature technol- (WWW Consortium). It is spreading quickly because ogy that is optimized for XML data. The practical of its flexibility and its platform-independent technol- benefits of this technology include Partial Signature, ogy, which freely allows authors to decide on docu- which allows an electronic signature to be written on ment structures. Various XML-based standard for- specific tags contained in XML data, and Multiple mats have been developed including: ebXML and Signature, which enables multiple electronic signa- RosettaNet, which are standard specifications for e- tures to be written. The use of XML Signature can commerce transactions, TravelXML, which is an EDI solve security problems, including falsification, spoof- (Electronic Data Interchange) standard for travel ing, and repudiation. agencies, and NewsML, which is a standard specifica- tion for new distribution formats. -

What Is XML Schema?
72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_AppB 3/22/02 10:47 AM Page 378 72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_FM 3/22/02 10:39 AM Page ii Publisher: Robert Ipsen Editor: Cary Sullivan Developmental Editor: Scott Amerman Associate Managing Editor: Penny Linskey Associate New Media Editor: Brian Snapp Text Design & Composition: D&G Limited, LLC Designations used by companies to distinguish their products are often claimed as trademarks. In all instances where John Wiley & Sons, Inc., is aware of a claim, the product names appear in initial capital or ALL CAPITAL LETTERS. Readers, however, should contact the appropriate companies for more complete information regarding trademarks and registration. This book is printed on acid-free paper. Copyright © 2002 by R. Allen Wyke and Andrew Watt. All rights reserved. Published by John Wiley & Sons, Inc. Published simultaneously in Canada. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copy- right Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 750-4744. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 605 Third Avenue, New York, NY 10158-0012, (212) 850-6011, fax (212) 850- 6008, E-Mail: PERMREQ @ WILEY.COM. -

Bibliography of Erik Wilde
dretbiblio dretbiblio Erik Wilde's Bibliography References [1] AFIPS Fall Joint Computer Conference, San Francisco, California, December 1968. [2] Seventeenth IEEE Conference on Computer Communication Networks, Washington, D.C., 1978. [3] ACM SIGACT-SIGMOD Symposium on Principles of Database Systems, Los Angeles, Cal- ifornia, March 1982. ACM Press. [4] First Conference on Computer-Supported Cooperative Work, 1986. [5] 1987 ACM Conference on Hypertext, Chapel Hill, North Carolina, November 1987. ACM Press. [6] 18th IEEE International Symposium on Fault-Tolerant Computing, Tokyo, Japan, 1988. IEEE Computer Society Press. [7] Conference on Computer-Supported Cooperative Work, Portland, Oregon, 1988. ACM Press. [8] Conference on Office Information Systems, Palo Alto, California, March 1988. [9] 1989 ACM Conference on Hypertext, Pittsburgh, Pennsylvania, November 1989. ACM Press. [10] UNIX | The Legend Evolves. Summer 1990 UKUUG Conference, Buntingford, UK, 1990. UKUUG. [11] Fourth ACM Symposium on User Interface Software and Technology, Hilton Head, South Carolina, November 1991. [12] GLOBECOM'91 Conference, Phoenix, Arizona, 1991. IEEE Computer Society Press. [13] IEEE INFOCOM '91 Conference on Computer Communications, Bal Harbour, Florida, 1991. IEEE Computer Society Press. [14] IEEE International Conference on Communications, Denver, Colorado, June 1991. [15] International Workshop on CSCW, Berlin, Germany, April 1991. [16] Third ACM Conference on Hypertext, San Antonio, Texas, December 1991. ACM Press. [17] 11th Symposium on Reliable Distributed Systems, Houston, Texas, 1992. IEEE Computer Society Press. [18] 3rd Joint European Networking Conference, Innsbruck, Austria, May 1992. [19] Fourth ACM Conference on Hypertext, Milano, Italy, November 1992. ACM Press. [20] GLOBECOM'92 Conference, Orlando, Florida, December 1992. IEEE Computer Society Press. http://github.com/dret/biblio (August 29, 2018) 1 dretbiblio [21] IEEE INFOCOM '92 Conference on Computer Communications, Florence, Italy, 1992. -

Voice and Multimodal Technology for the Mobile Worker Kondratova, Irina
NRC Publications Archive Archives des publications du CNRC Voice and Multimodal Technology for the Mobile Worker Kondratova, Irina This publication could be one of several versions: author’s original, accepted manuscript or the publisher’s version. / La version de cette publication peut être l’une des suivantes : la version prépublication de l’auteur, la version acceptée du manuscrit ou la version de l’éditeur. Publisher’s version / Version de l'éditeur: Itcon, Special Issue Mobile Computing in Construction, 9, 2004 NRC Publications Record / Notice d'Archives des publications de CNRC: https://nrc-publications.canada.ca/eng/view/object/?id=b869a897-8fb9-4e04-b50b-6e652aee9661 https://publications-cnrc.canada.ca/fra/voir/objet/?id=b869a897-8fb9-4e04-b50b-6e652aee9661 Access and use of this website and the material on it are subject to the Terms and Conditions set forth at https://nrc-publications.canada.ca/eng/copyright READ THESE TERMS AND CONDITIONS CAREFULLY BEFORE USING THIS WEBSITE. L’accès à ce site Web et l’utilisation de son contenu sont assujettis aux conditions présentées dans le site https://publications-cnrc.canada.ca/fra/droits LISEZ CES CONDITIONS ATTENTIVEMENT AVANT D’UTILISER CE SITE WEB. Questions? Contact the NRC Publications Archive team at [email protected]. If you wish to email the authors directly, please see the first page of the publication for their contact information. Vous avez des questions? Nous pouvons vous aider. Pour communiquer directement avec un auteur, consultez la première page de la revue dans laquelle son article a été publié afin de trouver ses coordonnées. -

QUERYING JSON and XML Performance Evaluation of Querying Tools for Offline-Enabled Web Applications
QUERYING JSON AND XML Performance evaluation of querying tools for offline-enabled web applications Master Degree Project in Informatics One year Level 30 ECTS Spring term 2012 Adrian Hellström Supervisor: Henrik Gustavsson Examiner: Birgitta Lindström Querying JSON and XML Submitted by Adrian Hellström to the University of Skövde as a final year project towards the degree of M.Sc. in the School of Humanities and Informatics. The project has been supervised by Henrik Gustavsson. 2012-06-03 I hereby certify that all material in this final year project which is not my own work has been identified and that no work is included for which a degree has already been conferred on me. Signature: ___________________________________________ Abstract This article explores the viability of third-party JSON tools as an alternative to XML when an application requires querying and filtering of data, as well as how the application deviates between browsers. We examine and describe the querying alternatives as well as the technologies we worked with and used in the application. The application is built using HTML 5 features such as local storage and canvas, and is benchmarked in Internet Explorer, Chrome and Firefox. The application built is an animated infographical display that uses querying functions in JSON and XML to filter values from a dataset and then display them through the HTML5 canvas technology. The results were in favor of JSON and suggested that using third-party tools did not impact performance compared to native XML functions. In addition, the usage of JSON enabled easier development and cross-browser compatibility. Further research is proposed to examine document-based data filtering as well as investigating why performance deviated between toolsets. -
ABBREVIATIONS EBU Technical Review
ABBREVIATIONS EBU Technical Review AbbreviationsLast updated: January 2012 720i 720 lines, interlaced scan ACATS Advisory Committee on Advanced Television 720p/50 High-definition progressively-scanned TV format Systems (USA) of 1280 x 720 pixels at 50 frames per second ACELP (MPEG-4) A Code-Excited Linear Prediction 1080i/25 High-definition interlaced TV format of ACK ACKnowledgement 1920 x 1080 pixels at 25 frames per second, i.e. ACLR Adjacent Channel Leakage Ratio 50 fields (half frames) every second ACM Adaptive Coding and Modulation 1080p/25 High-definition progressively-scanned TV format ACS Adjacent Channel Selectivity of 1920 x 1080 pixels at 25 frames per second ACT Association of Commercial Television in 1080p/50 High-definition progressively-scanned TV format Europe of 1920 x 1080 pixels at 50 frames per second http://www.acte.be 1080p/60 High-definition progressively-scanned TV format ACTS Advanced Communications Technologies and of 1920 x 1080 pixels at 60 frames per second Services AD Analogue-to-Digital AD Anno Domini (after the birth of Jesus of Nazareth) 21CN BT’s 21st Century Network AD Approved Document 2k COFDM transmission mode with around 2000 AD Audio Description carriers ADC Analogue-to-Digital Converter 3DTV 3-Dimension Television ADIP ADress In Pre-groove 3G 3rd Generation mobile communications ADM (ATM) Add/Drop Multiplexer 4G 4th Generation mobile communications ADPCM Adaptive Differential Pulse Code Modulation 3GPP 3rd Generation Partnership Project ADR Automatic Dialogue Replacement 3GPP2 3rd Generation Partnership -

An Architecture of Mobile Web 2.0 Context-Aware Applications in Ubiquitous Web
JOURNAL OF SOFTWARE, VOL. 6, NO. 4, APRIL 2011 705 An Architecture of Mobile Web 2.0 Context-aware Applications in Ubiquitous Web I-Ching Hsu Department of Computer Science and Information Engineering National Formosa University 64, Wenhua Rd., Huwei Township, Yunlin County 632, Taiwan [email protected] Abstract—The rapid development of the wireless an uniformly access to cope with the heterogeneous communication technologies, including wireless sensors, effects, including various context presentation, context intelligent mobile devices, and communication protocols, information, mobile device constraints, and context has led to diverse mobile devices of accessing various middleware [4]. To allow interoperability among the context-aware systems. Existing context-aware systems only various context-aware systems and mobile devices, a focus on characterize the situation of an entity to exhibit the advantage of contextual information association. The common standard is needed to uniformly access context contextual information can represent semantic implications information provided via a fundamental infrastructure. to provide decidable reasoning services, but it has no The Web 2.0 technologies provide a catalytic solution to mechanism to facilitating the interoperability and this problem. reusability among heterogeneous context-aware systems and Within the last two to three years, the Internet has various mobile devices. This study addresses these issues greatly changed our way of sharing resources and developing a Multi-layer Context Framework (MCF) that information. As well known, Web 2.0 is recognized as integrates Web 2.0 technologies into context-aware system the next generation of web applications proposed by T. for supporting ubiquitous mobile environment. The O’Reilly [5]. -

Extensible Markup Language (XML) 1.0 (Fifth Edition) W3C Recommendation 26 November 2008
Extensible Markup Language (XML) 1.0 (Fifth Edition) W3C Recommendation 26 November 2008 This version: http://www.w3.org/TR/2008/REC-xml-20081126/ Latest version: http://www.w3.org/TR/xml/ Previous versions: http://www.w3.org/TR/2008/PER-xml-20080205/ http://www.w3.org/TR/2006/REC-xml-20060816/ Editors: Tim Bray, Textuality and Netscape <[email protected]> Jean Paoli, Microsoft <[email protected]> C. M. Sperberg-McQueen, W3C <[email protected]> Eve Maler, Sun Microsystems, Inc. <[email protected]> François Yergeau Please refer to the errata for this document, which may include some normative corrections. The previous errata for this document, are also available. See also translations. This document is also available in these non-normative formats: XML and XHTML with color-coded revision indicators. Copyright © 2008 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. Abstract The Extensible Markup Language (XML) is a subset of SGML that is completely described in this document. Its goal is to enable generic SGML to be served, received, and processed on the Web in the way that is now possible with HTML. XML has been designed for ease of implementation and for interoperability with both SGML and HTML. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. -

XML for Java Developers G22.3033-002 Course Roadmap
XML for Java Developers G22.3033-002 Session 1 - Main Theme Markup Language Technologies (Part I) Dr. Jean-Claude Franchitti New York University Computer Science Department Courant Institute of Mathematical Sciences 1 Course Roadmap Consider the Spectrum of Applications Architectures Distributed vs. Decentralized Apps + Thick vs. Thin Clients J2EE for eCommerce vs. J2EE/Web Services, JXTA, etc. Learn Specific XML/Java “Patterns” Used for Data/Content Presentation, Data Exchange, and Application Configuration Cover XML/Java Technologies According to their Use in the Various Phases of the Application Development Lifecycle (i.e., Discovery, Design, Development, Deployment, Administration) e.g., Modeling, Configuration Management, Processing, Rendering, Querying, Secure Messaging, etc. Develop XML Applications as Assemblies of Reusable XML- Based Services (Applications of XML + Java Applications) 2 1 Agenda XML Generics Course Logistics, Structure and Objectives History of Meta-Markup Languages XML Applications: Markup Languages XML Information Modeling Applications XML-Based Architectures XML and Java XML Development Tools Summary Class Project Readings Assignment #1a 3 Part I Introduction 4 2 XML Generics XML means eXtensible Markup Language XML expresses the structure of information (i.e., document content) separately from its presentation XSL style sheets are used to convert documents to a presentation format that can be processed by a target presentation device (e.g., HTML in the case of legacy browsers) Need a