A Dataset for Github Repository Deduplication
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

What If What I Need Is Not in Powerai (Yet)? What You Need to Know to Build from Scratch?
IBM Systems What if what I need is not in PowerAI (yet)? What you need to know to build from scratch? Jean-Armand Broyelle June 2018 IBM Systems – Cognitive Era Things to consider when you have to rebuild a framework © 2017 International Business Machines Corporation 2 IBM Systems – Cognitive Era CUDA Downloads © 2017 International Business Machines Corporation 3 IBM Systems – Cognitive Era CUDA 8 – under Legacy Releases © 2017 International Business Machines Corporation 4 IBM Systems – Cognitive Era CUDA 8 Install Steps © 2017 International Business Machines Corporation 5 IBM Systems – Cognitive Era cuDNN and NVIDIA drivers © 2017 International Business Machines Corporation 6 IBM Systems – Cognitive Era cuDNN v6.0 for CUDA 8.0 © 2017 International Business Machines Corporation 7 IBM Systems – Cognitive Era cuDNN and NVIDIA drivers © 2017 International Business Machines Corporation 8 IBM Systems – Cognitive Era © 2017 International Business Machines Corporation 9 IBM Systems – Cognitive Era © 2017 International Business Machines Corporation 10 IBM Systems – Cognitive Era cuDNN and NVIDIA drivers © 2017 International Business Machines Corporation 11 IBM Systems – Cognitive Era Prepare your environment • When something goes wrong it’s better to Remove local anaconda installation $ cd ~; rm –rf anaconda2 .conda • Reinstall anaconda $ cd /tmp; wget https://repo.anaconda.com/archive/Anaconda2-5.1.0-Linux- ppc64le.sh $ bash /tmp/Anaconda2-5.1.0-Linux-ppc64le.sh • Activate PowerAI $ source /opt/DL/tensorflow/bin/tensorflow-activate • When you -

Open Source Copyrights
Kuri App - Open Source Copyrights: 001_talker_listener-master_2015-03-02 ===================================== Source Code can be found at: https://github.com/awesomebytes/python_profiling_tutorial_with_ros 001_talker_listener-master_2016-03-22 ===================================== Source Code can be found at: https://github.com/ashfaqfarooqui/ROSTutorials acl_2.2.52-1_amd64.deb ====================== Licensed under GPL 2.0 License terms can be found at: http://savannah.nongnu.org/projects/acl/ acl_2.2.52-1_i386.deb ===================== Licensed under LGPL 2.1 License terms can be found at: http://metadata.ftp- master.debian.org/changelogs/main/a/acl/acl_2.2.51-8_copyright actionlib-1.11.2 ================ Licensed under BSD Source Code can be found at: https://github.com/ros/actionlib License terms can be found at: http://wiki.ros.org/actionlib actionlib-common-1.5.4 ====================== Licensed under BSD Source Code can be found at: https://github.com/ros-windows/actionlib License terms can be found at: http://wiki.ros.org/actionlib adduser_3.113+nmu3ubuntu3_all.deb ================================= Licensed under GPL 2.0 License terms can be found at: http://mirrors.kernel.org/ubuntu/pool/main/a/adduser/adduser_3.113+nmu3ubuntu3_all. deb alsa-base_1.0.25+dfsg-0ubuntu4_all.deb ====================================== Licensed under GPL 2.0 License terms can be found at: http://mirrors.kernel.org/ubuntu/pool/main/a/alsa- driver/alsa-base_1.0.25+dfsg-0ubuntu4_all.deb alsa-utils_1.0.27.2-1ubuntu2_amd64.deb ====================================== -

Mochi-JCST-01-20.Pdf
Ross R, Amvrosiadis G, Carns P et al. Mochi: Composing data services for high-performance computing environments. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 35(1): 121–144 Jan. 2020. DOI 10.1007/s11390-020-9802-0 Mochi: Composing Data Services for High-Performance Computing Environments Robert B. Ross1, George Amvrosiadis2, Philip Carns1, Charles D. Cranor2, Matthieu Dorier1, Kevin Harms1 Greg Ganger2, Garth Gibson3, Samuel K. Gutierrez4, Robert Latham1, Bob Robey4, Dana Robinson5 Bradley Settlemyer4, Galen Shipman4, Shane Snyder1, Jerome Soumagne5, and Qing Zheng2 1Argonne National Laboratory, Lemont, IL 60439, U.S.A. 2Parallel Data Laboratory, Carnegie Mellon University, Pittsburgh, PA 15213, U.S.A. 3Vector Institute for Artificial Intelligence, Toronto, Ontario, Canada 4Los Alamos National Laboratory, Los Alamos NM, U.S.A. 5The HDF Group, Champaign IL, U.S.A. E-mail: [email protected]; [email protected]; [email protected]; [email protected]; [email protected] E-mail: [email protected]; [email protected]; [email protected]; [email protected] E-mail: [email protected]; [email protected]; [email protected]; {bws, gshipman}@lanl.gov E-mail: [email protected]; [email protected]; [email protected] Received July 1, 2019; revised November 2, 2019. Abstract Technology enhancements and the growing breadth of application workflows running on high-performance computing (HPC) platforms drive the development of new data services that provide high performance on these new platforms, provide capable and productive interfaces and abstractions for a variety of applications, and are readily adapted when new technologies are deployed. The Mochi framework enables composition of specialized distributed data services from a collection of connectable modules and subservices. -

Enforcing Abstract Immutability
Enforcing Abstract Immutability by Jonathan Eyolfson A thesis presented to the University of Waterloo in fulfillment of the thesis requirement for the degree of Doctor of Philosophy in Electrical and Computer Engineering Waterloo, Ontario, Canada, 2018 © Jonathan Eyolfson 2018 Examining Committee Membership The following served on the Examining Committee for this thesis. The decision of the Examining Committee is by majority vote. External Examiner Ana Milanova Associate Professor Rensselaer Polytechnic Institute Supervisor Patrick Lam Associate Professor University of Waterloo Internal Member Lin Tan Associate Professor University of Waterloo Internal Member Werner Dietl Assistant Professor University of Waterloo Internal-external Member Gregor Richards Assistant Professor University of Waterloo ii I hereby declare that I am the sole author of this thesis. This is a true copy of the thesis, including any required final revisions, as accepted by my examiners. I understand that my thesis may be made electronically available to the public. iii Abstract Researchers have recently proposed a number of systems for expressing, verifying, and inferring immutability declarations. These systems are often rigid, and do not support “abstract immutability”. An abstractly immutable object is an object o which is immutable from the point of view of any external methods. The C++ programming language is not rigid—it allows developers to express intent by adding immutability declarations to methods. Abstract immutability allows for performance improvements such as caching, even in the presence of writes to object fields. This dissertation presents a system to enforce abstract immutability. First, we explore abstract immutability in real-world systems. We found that developers often incorrectly use abstract immutability, perhaps because no programming language helps developers correctly implement abstract immutability. -

Mlsm: Making Authenticated Storage Faster in Ethereum
mLSM: Making Authenticated Storage Faster in Ethereum Pandian Raju1 Soujanya Ponnapalli1 Evan Kaminsky1 Gilad Oved1 Zachary Keener1 Vijay Chidambaram1;2 Ittai Abraham2 1University of Texas at Austin 2VMware Research Abstract the LevelDB [15] key-value store. We show that reading a single key (e.g., the amount of ether in a given account) Ethereum provides authenticated storage: each read can result in 64 LevelDB reads, while writing a single returns a value and a proof that allows the client to verify key can lead to a similar number of LevelDB writes. In- the value returned is correct. We experimentally show ternally, LevelDB induces extra write amplification [23], that such authentication leads to high read and write am- further increasing overall amplification. Such write and × plification (64 in the worst case). We present a novel read amplification reduces throughput (storage band- data structure, Merkelized LSM (mLSM), that signifi- width is wasted by the amplification), and write ampli- cantly reduces the read and write amplification while still fication in particular significantly reduces the lifetime of allowing client verification of reads. mLSM significantly devices such as Solid State Drives (SSDs) which wear increases the performance of the storage subsystem in out after a limited number of write cycles [1, 16, 20]. Ethereum, thereby increasing the performance of a wide Thus, reducing the read and write amplification can both range of Ethereum applications. increase Ethereum throughput and reduce hardware re- 1 Introduction placement costs. Modern crypto-currencies such as Bitcoin [21] and We trace the read and write amplification in Ethereum Ethereum [26] seek to provide a decentralized, to the fact that it provides authenticated storage. -

Performance Optimization of Deep Learning Frameworks Caffe* and Tensorflow* for Xeon Phi Cluster
Performance Optimization of Deep Learning Frameworks on Modern Intel Architectures ElMoustapha Ould-Ahmed-Vall, AG Ramesh, Vamsi Sripathi and Karthik Raman Representing the work of many at Intel Agenda • Op#mizaon maers on modern architectures • Intel’s recent Xeon and Xeon Phi products • Introduc#on to Deep Learning • Op#mizing DL frameworks on IA • Key challenges • Op#mizaon techniques • Performance data • DL scaling Moore’s Law Goes on! Increasing clock speeds -> more cores + wider SIMD (Hierarchical parallelism) Combined Amdahl’s Law for Vector Mul<cores* �������=(1/������↓���� +1−������↓���� /�������� )∗(1/������↓���� +1−������↓���� /������������ ) Goal: Reduce Serial Fraction and Reduce Scalar Fraction of Code Ideal Speedup: NumCores*VectorLength (requires zero scalar, zero serial work) Peak “Compute” Gflops/s Compute Bound Performance Most kernels of ML codes are compute bound i.e. raw FLOPS matter Peak “Compute” Gflops/s without SIMD Roofline Model Gflops/s = min (Peak Gflops/s, Stream BW * flops/byte) A+ainable Gflops/s Compute intensity (flops/byte) Overview of Current Generation of Intel Xeon and Xeon Phi Products Current Intel® Xeon PlaBorms 45nm Process 14nm Process Technology 32nm Process Technology 22nm Process Technology Technology Nehalem Westmere Sandy Bridge Ivy Bridge Haswell Broadwell NEW Intel® Intel NEW Intel Intel NEW Intel Intel Microarchitecture Microarchitecture Microarchitecture Microarchitecture Microarchitecture Microarchitecture (Nehalem) (Nehalem) (Sandy Bridge) (Sandy Bridge) (Haswell) (Haswell) TOCK -

Operations Hub Open Source Software List
GE Operations Hub Open Source Software List (for Version 1.7) In accordance with certain software license terms, the General Electric Company (“GE”) makes available the following software package installations. This code is provided to you on an “as is” basis, and GE makes no representations or warranties for the use of this code by you independent of any GE provided software or services. Refer to the licenses and copyright notices files for each package for any specific license terms that apply to each software bundle, associated with this product release. NOTE: These software package versions may change or be removed as needed for updates to this product. Copyright © 2018 General Electric Company. All rights reserved. Page 1 of 67 Software Name & Company Link License Name & Copyright Version Version (by Component) HikariCP https://github.com/brettwooldr Apache 2.0 3.4.2 idge/HikariCP Not found MsSql Jdbc 7.4.1.jre8 Copyright(c) 2019 Microsoft MIT https://www.microsoft.com/ Corporation snakeyaml http://www.snakeyaml.org Copyright (c) 2008, Apache License 2.0 1.2.6 http://www.snakeyaml.org COMMON DEVELOPMENT HK2 Class-Model 2.5.0-b06 https://javaee.github.io/glassfish/ AND DISTRIBUTION LICENSE Copyright (c) 2010-2015 Oracle and/or (CDDL) Version 1.1 its affiliates. All rights reserved. https://code.google.com/archive/p/ Copyright (C) 2003-2013 Virginia Tech. VT Crypt Library 2.1.4 Apache License 2.0 vt-middleware/ All rights reserved. https://code.google.com/archive/p/ Copyright (C) 2003-2013 Virginia Tech. VT Dictionary Libraries 3.0 Apache License 2.0 vt-middleware/ All rights reserved. -
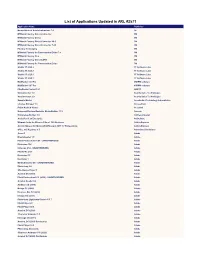
List of Applications Updated in ARL #2571
List of Applications Updated in ARL #2571 Application Name Publisher Nomad Branch Admin Extensions 7.0 1E M*Modal Fluency Direct Connector 3M M*Modal Fluency Direct 3M M*Modal Fluency Direct Connector 10.0 3M M*Modal Fluency Direct Connector 7.85 3M Fluency for Imaging 3M M*Modal Fluency for Transcription Editor 7.6 3M M*Modal Fluency Flex 3M M*Modal Fluency Direct CAPD 3M M*Modal Fluency for Transcription Editor 3M Studio 3T 2020.2 3T Software Labs Studio 3T 2020.8 3T Software Labs Studio 3T 2020.3 3T Software Labs Studio 3T 2020.7 3T Software Labs MailRaider 3.69 Pro 45RPM software MailRaider 3.67 Pro 45RPM software FineReader Server 14.1 ABBYY VoxConverter 3.0 Acarda Sales Technologies VoxConverter 2.0 Acarda Sales Technologies Sample Master Accelerated Technology Laboratories License Manager 3.5 AccessData Prizm ActiveX Viewer AccuSoft Universal Restore Bootable Media Builder 11.5 Acronis Knowledge Builder 4.0 ActiveCampaign ActivePerl 5.26 Enterprise ActiveState Ultimate Suite for Microsoft Excel 18.5 Business Add-in Express Add-in Express for Microsoft Office and .NET 7.7 Professional Add-in Express Office 365 Reporter 3.5 AdminDroid Solutions Scout 1 Adobe Dreamweaver 1.0 Adobe Flash Professional CS6 - UNAUTHORIZED Adobe Illustrator CS6 Adobe InDesign CS6 - UNAUTHORIZED Adobe Fireworks CS6 Adobe Illustrator CC Adobe Illustrator 1 Adobe Media Encoder CC - UNAUTHORIZED Adobe Photoshop 1.0 Adobe Shockwave Player 1 Adobe Acrobat DC (2015) Adobe Flash Professional CC (2015) - UNAUTHORIZED Adobe Acrobat Reader DC Adobe Audition CC (2018) -

Towards Efficient, Portable Application-Level Consistency
Towards Efficient, Portable Application-Level Consistency Thanumalayan Sankaranarayana Pillai, Vijay Chidambaram, † Joo-Young Hwang , Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau † University of Wisconsin, Madison Samsung Electronics Co., LTD. ABSTRACT are fully replaced [21]. Specifically, crash invariants are Applications employ complex protocols to ensure consis- held only if the replacement is atomic with respect to a tency after system crashes. Such protocols are affected by system crash. This dependency is sometimes a bug, and the exact behavior of file systems. However, modern file sys- is sometimes intentional, to provide reasonable application tems vary widely in such behavior, reducing the correctness performance over different file systems with widely varying and performance of applications. In this paper, we study performance characteristics. For the safe execution of application-level crash consistency. Through the detailed applications, many modern file systems explicitly ensure study of two popular database libraries (SQLite, LevelDB), atomic file replacement (during certain sequences of system we show that application performance and correctness heav- calls), even though this is not a part of the POSIX standard. ily depend on file-system properties previously ignored in re- However, application-level consistency is also affected by search. We define a number of such properties and show that other undocumented (and unexplored) crash-related behav- they vary widely among file systems. We conclude with im- ior that differs between file systems. This severely con- plications for future file-system and dependability research. strains the portability of applications. There is no consensus on what file-system behavior affects application-level consis- tency, and what behaviors file systems should hence guar- 1. -

Towards Left Duff S Mdbg Holt Winters Gai Incl Tax Drupal Fapi Icici
jimportneoneo_clienterrorentitynotfoundrelatedtonoeneo_j_sdn neo_j_traversalcyperneo_jclientpy_neo_neo_jneo_jphpgraphesrelsjshelltraverserwritebatchtransactioneventhandlerbatchinsertereverymangraphenedbgraphdatabaseserviceneo_j_communityjconfigurationjserverstartnodenotintransactionexceptionrest_graphdbneographytransactionfailureexceptionrelationshipentityneo_j_ogmsdnwrappingneoserverbootstrappergraphrepositoryneo_j_graphdbnodeentityembeddedgraphdatabaseneo_jtemplate neo_j_spatialcypher_neo_jneo_j_cyphercypher_querynoe_jcypherneo_jrestclientpy_neoallshortestpathscypher_querieslinkuriousneoclipseexecutionresultbatch_importerwebadmingraphdatabasetimetreegraphawarerelatedtoviacypherqueryrecorelationshiptypespringrestgraphdatabaseflockdbneomodelneo_j_rbshortpathpersistable withindistancegraphdbneo_jneo_j_webadminmiddle_ground_betweenanormcypher materialised handaling hinted finds_nothingbulbsbulbflowrexprorexster cayleygremlintitandborient_dbaurelius tinkerpoptitan_cassandratitan_graph_dbtitan_graphorientdbtitan rexter enough_ram arangotinkerpop_gremlinpyorientlinkset arangodb_graphfoxxodocumentarangodborientjssails_orientdborientgraphexectedbaasbox spark_javarddrddsunpersist asigned aql fetchplanoriento bsonobjectpyspark_rddrddmatrixfactorizationmodelresultiterablemlibpushdownlineage transforamtionspark_rddpairrddreducebykeymappartitionstakeorderedrowmatrixpair_rddblockmanagerlinearregressionwithsgddstreamsencouter fieldtypes spark_dataframejavarddgroupbykeyorg_apache_spark_rddlabeledpointdatabricksaggregatebykeyjavasparkcontextsaveastextfilejavapairdstreamcombinebykeysparkcontext_textfilejavadstreammappartitionswithindexupdatestatebykeyreducebykeyandwindowrepartitioning -

4.X Is the System Default
EasyBuild Documentation Release 20190816.0 Ghent University Fri, 16 Aug 2019 18:07:17 Contents 1 Introductory topics 3 1.1 What is EasyBuild?...........................................3 1.2 Concepts and terminology........................................4 1.2.1 EasyBuild framework......................................4 1.2.2 Easyblocks...........................................5 1.2.3 Toolchains............................................5 1.2.4 Easyconfig files.........................................6 1.2.5 Extensions............................................6 1.3 Typical workflow example: building and installing WRF........................7 1.3.1 Searching for available easyconfigs files............................7 1.3.2 Getting an overview of planned installations..........................8 1.3.3 Installing a software stack...................................8 2 Getting started 11 2.1 Installing EasyBuild........................................... 11 2.1.1 Requirements.......................................... 12 2.1.2 Bootstrapping EasyBuild.................................... 12 2.1.3 Advanced bootstrapping options................................ 16 2.1.4 Updating an existing EasyBuild installation.......................... 17 2.1.5 Dependencies.......................................... 18 2.1.6 Sources............................................. 20 2.1.7 In case of installation issues. .................................. 21 2.2 Configuring EasyBuild.......................................... 21 2.2.1 Supported configuration types................................ -

SQL, Nosql, NEWSQL DATABASES)
International Research Journal of Modernization in Engineering Technology and Science Volume: 01/Issue: 01/December-2019 www.irjmets.com AN OVERVIEW OF BIG DATA STORAGE AND MANAGEMENT TOOLS (SQL, NoSQL, NEWSQL DATABASES) 1Satish Chandra Reddy Nandipati, 2Chew XinYing*, 3Mohd Adib Omar 1,2,3School of Computer Sciences, 11800, Universiti Sains Malaysia, Pulau Pinang, Malaysia ABSTRACT A huge amount of data referred to as ‘big data’ which are in the form of structured, semi and unstructured data produced by various organizations is said to have a huge potential in wide range of sectors. The big data is stored and managed by relational (SQL and New SQL) and non-relational (NoSQL) database management systems for easy data accessing and analysis. This paper performs a brief literature review to elicit the general background of storage & management tools, analytical platforms, analysis and visualization tools that are used to handle the big data and its management systems. A brief history, evolution, some of the characteristic features, comparison, advantages, strengths and weakness, and performance of three SQL databases with respect to functional and non-functional features are explained. Finally moved to the application of these databases in healthcare, education, and transportation, etc. Besides advantages, these databases possess disadvantages that have been overcome by up-gradation of databases and emerging new databases such as NewSQL, and in the view of this the future of the databases has been illustrated in brief. KEYWORDS: Big Data Management, SQL Databases, NoSQL Databases, New SQL Databases, Application of Databases. I. INTRODUCTION The year 1937-1943 has been known to be the history of data project i.e., during the time of the 2nd world war to interpret Nazi codes by the British.