HEP Software Foundation Community White Paper Working Group – Data and Software Preservation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

KDE 2.0 Development, Which Is Directly Supported
23 8911 CH18 10/16/00 1:44 PM Page 401 The KDevelop IDE: The CHAPTER Integrated Development Environment for KDE by Ralf Nolden 18 IN THIS CHAPTER • General Issues 402 • Creating KDE 2.0 Applications 409 • Getting Started with the KDE 2.0 API 413 • The Classbrowser and Your Project 416 • The File Viewers—The Windows to Your Project Files 419 • The KDevelop Debugger 421 • KDevelop 2.0—A Preview 425 23 8911 CH18 10/16/00 1:44 PM Page 402 Developer Tools and Support 402 PART IV Although developing applications under UNIX systems can be a lot of fun, until now the pro- grammer was lacking a comfortable environment that takes away the usual standard activities that have to be done over and over in the process of programming. The KDevelop IDE closes this gap and makes it a joy to work within a complete, integrated development environment, combining the use of the GNU standard development tools such as the g++ compiler and the gdb debugger with the advantages of a GUI-based environment that automates all standard actions and allows the developer to concentrate on the work of writing software instead of managing command-line tools. It also offers direct and quick access to source files and docu- mentation. KDevelop primarily aims to provide the best means to rapidly set up and write KDE software; it also supports extended features such as GUI designing and translation in con- junction with other tools available especially for KDE development. The KDevelop IDE itself is published under the GNU Public License (GPL), like KDE, and is therefore publicly avail- able at no cost—including its source code—and it may be used both for free and for commer- cial development. -
Q1 Where Do You Use C++? (Select All That Apply)
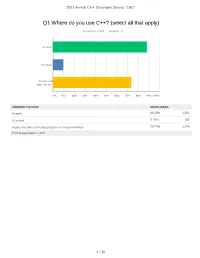
2021 Annual C++ Developer Survey "Lite" Q1 Where do you use C++? (select all that apply) Answered: 1,870 Skipped: 3 At work At school In personal time, for ho... 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES At work 88.29% 1,651 At school 9.79% 183 In personal time, for hobby projects or to try new things 73.74% 1,379 Total Respondents: 1,870 1 / 35 2021 Annual C++ Developer Survey "Lite" Q2 How many years of programming experience do you have in C++ specifically? Answered: 1,869 Skipped: 4 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 7.60% 142 3-5 years 20.60% 385 6-10 years 20.71% 387 10-20 years 30.02% 561 >20 years 21.08% 394 TOTAL 1,869 2 / 35 2021 Annual C++ Developer Survey "Lite" Q3 How many years of programming experience do you have overall (all languages)? Answered: 1,865 Skipped: 8 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 1.02% 19 3-5 years 12.17% 227 6-10 years 22.68% 423 10-20 years 29.71% 554 >20 years 34.42% 642 TOTAL 1,865 3 / 35 2021 Annual C++ Developer Survey "Lite" Q4 What types of projects do you work on? (select all that apply) Answered: 1,861 Skipped: 12 Gaming (e.g., console and.. -

The Breadth and Depth of Early Learning Standards
March 2005 INSIDE THE CONTENT: THE BREADTH AND DEPTH OF EARLY LEARNING STANDARDS By Catherine Scott-Little Sharon Lynn Kagan Victoria Stebbins Frelow Inside the Content: The Breadth and Depth of Early Learning Standards By Catherine Scott-Little, Ph.D. Human Development and Family Studies SERVE University of North Carolina at Greensboro Sharon Lynn Kagan, Ed.D. Victoria Stebbins Frelow Teachers College Columbia University In Association with the School of Education University of North Carolina at Greensboro 2005 Edited by Donna Nalley, Ph.D., SERVE Publications Director Karen DeMeester, Ph.D., SERVE Publications Cover Design by Shelley Call, SERVE Graphic Designer Research and production of this document were supported by the Institute of Education Sciences, U.S. Department of Education, through the Regional Educational Laboratory at SERVE (under contract no. ED-01-CO-0015). The findings and opinions expressed do not necessarily reflect the position or policies of IES or the U.S. Department of Education. Acknowledgments We would like to thank a number of persons who were instrumental to our efforts to bring this work to fruition. Rosemarie Andrews, Sarah Boeving, Amanda Weisner, and Jennifer Kunzman’s assistance in development of the document was invaluable. We would also like to thank Victoria Seitz for her insightful assistance with data analysis for the report. We especially would like to thank the early childhood specialists in state departments of education who participated in the interviews for Phase 1 of this study and have continued to provide us with updated standards documents and insights on early learning standards. We are grateful to each of the informants for their interest in this study and their tireless dedication to their work on behalf of families and children. -

Kdevelop Handbook
KDevelop Handbook This documentation was converted from the KDE UserBase KDevelop4/Manual page. KDevelop Handbook 2 Contents 1 What is KDevelop?6 2 Sessions and projects: The basics of KDevelop8 2.1 Terminology . .8 2.2 Setting up a session and importing an existing project . .9 2.2.1 Option 1: Importing a project from a version control system server . .9 2.2.2 Option 2: Importing a project that is already on your hard drive . 10 2.3 Setting up an application as a second project . 10 2.4 Creating projects from scratch . 10 3 Working with source code 12 3.1 Tools and views . 12 3.2 Exploring source code . 14 3.2.1 Local information . 14 3.2.2 File scope information . 16 3.2.3 Project and session scope information . 17 3.2.4 Rainbow color highlighting explained . 19 3.3 Navigating in source code . 19 3.3.1 Local navigation . 19 3.3.2 File scope navigation and outline mode . 20 3.3.3 Project and session scope navigation: Semantic navigation . 21 3.4 Writing source code . 25 3.4.1 Auto-completion . 25 3.4.2 Adding new classes and implementing member functions . 27 3.4.3 Documenting declarations . 31 3.4.4 Renaming variables, functions and classes . 34 3.4.5 Code snippets . 35 3.5 Modes and working sets . 37 3.6 Some useful keyboard shortcuts . 39 KDevelop Handbook 4 Code generation with templates 41 4.1 Creating a new class . 41 4.2 Creating a new unit test . 43 4.3 Other files . -

KDE 2.0 Development
00 8911 FM 10/16/00 2:09 PM Page i KDE 2.0 Development David Sweet, et al. 201 West 103rd St., Indianapolis, Indiana, 46290 USA 00 8911 FM 10/16/00 2:09 PM Page ii KDE 2.0 Development ASSOCIATE PUBLISHER Michael Stephens Copyright © 2001 by Sams Publishing This material may be distributed only subject to the terms and conditions set ACQUISITIONS EDITOR forth in the Open Publication License, v1.0 or later (the latest version is Shelley Johnston presently available at http://www.opencontent.org/openpub/). DEVELOPMENT EDITOR Distribution of the work or derivative of the work in any standard (paper) book Heather Goodell form is prohibited unless prior permission is obtained from the copyright holder. MANAGING EDITOR No patent liability is assumed with respect to the use of the information con- Matt Purcell tained herein. Although every precaution has been taken in the preparation of PROJECT EDITOR this book, the publisher and author assume no responsibility for errors or omis- Christina Smith sions. Neither is any liability assumed for damages resulting from the use of the information contained herein. COPY EDITOR International Standard Book Number: 0-672-31891-1 Barbara Hacha Kim Cofer Library of Congress Catalog Card Number: 99-067972 Printed in the United States of America INDEXER Erika Millen First Printing: October 2000 PROOFREADER 03 02 01 00 4 3 2 1 Candice Hightower Trademarks TECHNICAL EDITOR Kurt Granroth All terms mentioned in this book that are known to be trademarks or service Matthias Ettrich marks have been appropriately capitalized. Sams Publishing cannot attest to Kurt Wall the accuracy of this information. -

IV. Программное Обеспечение Для Объектно-Ориентированного Программирования И Разработки Приложений (Kdevelop, Lazarus, Gambas)
IV. Программное обеспечение для объектно-ориентированного программирования и разработки приложений (Kdevelop, Lazarus, Gambas).............................................................. 2 1. Введение в ООП......................................................................................................................... 2 2. Разработка ПО с использованием Kdevelop.......................................................................... 16 2.1. Основы языка программирования C++.......................................................................... 17 2.2. Работа со средой разработки ПО KDevelop .................................................................. 30 3. Разработка ПО с использованием Lazarus............................................................................. 37 3.1. Основы языка программирования Pascal....................................................................... 38 3.2. Работа со средой разработки ПО Lazarus ...................................................................... 48 4. Разработка ПО с использованием Gambas ............................................................................ 54 4.1. Основы языка программирования BASIC (ОО диалект) ............................................. 55 4.2. Работа со средой разработки ПО Gambas...................................................................... 61 Академия АйТи Установка и администрирование ПСПО. Лекции. Часть 4 Страница 1 из 67 IV. Программное обеспечение для объектно- ориентированного программирования и разработки приложений -

IDE, a Software Environment You Can Use to Develop Your C/C++ Programs
The University of CMSC 15200 ± Introduction to Computer Science 2 Chicago Summer Quarter 2005 Department of Lab #2 (08/01/2005) Computer Science Name: Student ID: Lab Instructor: Borja Sotomayor Do not write in this area 1 2 3 TOTAL Maximum possible points: 30 One of the goals of this lab is to introduce the Eclipse IDE, a software environment you can use to develop your C/C++ programs. We provide some basic instructions on how to write a program with Eclipse, and how to use Eclipse's debugging features. More complete documentation can be found in Eclipse's official website: http://www.eclipse.org/ http://www.eclipse.org/documentation/ http://help.eclipse.org/ IDE: Integrated Development Environment An IDE, or Integrated Development Environment, provides an environment that integrates all the tools necessary to develop a piece of software. IDEs typically include a text editor, a compiler, a debugger, and other tools to improve the productivity of the programmer. For example, many IDEs include tools that allow us to easily create graphical interfaces for our own applications (“UI designers”) The user can interact with all these tools (editor, compiler, etc.) using an interface which generally (but not always) will be an easy-to-use graphical interface. In fact, the main advantage of using an IDE is that the programmer can do all his work from a single interface, instead of having to constantly switch between different tools. The following are some popular IDEs: ➢ Free / Open source (UNIX/Linux) ● Eclipse (Multi-platform, Java, C/C++, other -

Building a Custom Linux with the Nimblex Live CD Generator
COVER STORY Custom NimbleX EASYBuilding a custom Linux with BUILDER the NimbleX Live CD Generator If you want customization without CD image on the basis of your specifica- Linux systems. It presents the user with tions. By simply selecting applications a series of choices defining the charac- all the fuss, then try building your from a series of menus, the Live CD teristics of the system and generates an Generator resolves own custom ISO image with the any dependencies behind the scenes. web-based Custom NimbleX Live Getting CD Generator. Started BY THOMAS PELKMANN Because the Live CD Generator is designed for speed imbleX [1] is a minimal Linux and ease of use, it distribution based on Slackware. does not offer the NThe compact NimbleX system full range of op- is used primarily for Live CDs and USB tions available if sticks, and according to the website, you are building a NimbleX also runs well from the hard complete system drive or even over the network. But per- from scratch. The haps the most interesting feature of Nim- tool resembles the bleX is the custom CD generation service graphical installa- Figure 1: The Live CD Generator starts with a simple welcome screen. available through the project website tion wizard in- The green progress indicator shows how much disk space your distri- [2]. The Custom NimbleX Live CD Gen- cluded with many bution needs. erator lets you select the components conventional and applications you want to include in the system, then it generates a Live www,sxc.hu 36 ISSUE 88 MARCH 2008 036-038_nimblx.indd 36 17.01.2008 14:54:06 Uhr Custom NimbleX COVER STORY Figure 2: The Custom and Recommended customization levels let Figure 3: Select wallpaper for your desktop or upload your own back- you add applications to the minimal system. -

Porting X/Motif Applications to Qt
PPoorrttiinngg XX//MMoottiiff AApppplliiccaattiioonnss ttoo QQtt ® Scenarios and Advice for a Smooth Migration Integrated Computer Solutions Incorporated The User Interface Company™ 54 B Middlesex Turnpike Bedford, MA 01730 617.621.0060 [email protected] www.ics.com ® Porting X/Motif Applications to Qt Scenarios and Advice for a Smooth Migration Table of Contents Introduction......................................................................................................................... 4 Reasons for porting......................................................................................................... 4 Evaluating the state of your application.......................................................................... 4 Anatomy of an application.................................................................................................. 5 Hello Motif, Hello Qt...................................................................................................... 6 Toolkit Comparison ............................................................................................................ 7 Widget-set comparison ................................................................................................... 7 Mapping of common UI objects ................................................................................. 7 Menus and Options ..................................................................................................... 8 Dialogs ....................................................................................................................... -
![Contents [Edit] Total Cost of Ownership](https://docslib.b-cdn.net/cover/2044/contents-edit-total-cost-of-ownership-3652044.webp)
Contents [Edit] Total Cost of Ownership
Comparisons between the Microsoft Windows and Linux computer operating systems are a long-running discussion topic within the personal computer industry.[citation needed] Throughout the entire period of the Windows 9x systems through the introduction of Windows 7, Windows has retained an extremely large retail sales majority among operating systems for personal desktop use, while Linux has sustained its status as the most prominent Free Software and Open Source operating system. Both operating systems are present on servers, embedded systems, mobile internet devices as well as supercomputers. Linux and Microsoft Windows differ in philosophy, cost, versatility and stability, with each seeking to improve in their perceived weaker areas. Comparisons of the two operating systems tend to reflect their origins, historic user bases and distribution models. Typical perceived weaknesses regularly cited have often included poor consumer familiarity with Linux, and Microsoft Windows' susceptibility to viruses and malware.[1][2] Contents [hide] 1 Total cost of ownership o 1.1 Real world experience 2 Market share 3 User interface 4 Installation and Live environments 5 Accessibility and usability 6 Stability 7 Performance 8 Support 9 Platform for third party applications o 9.1 Gaming 10 Software development 11 Security o 11.1 Threats and vulnerabilities o 11.2 Security features and architecture 12 Localization 13 See also 14 References 15 External links [edit] Total cost of ownership See also: Studies related to Microsoft In 2004, Microsoft -

Libclang Integration in the Kdevelop IDE
Libclang Integration in the KDevelop IDE Kevin Funk ([email protected]) April 14, 2015 | London | EuroLLVM 2015 About KDevelop ● A free, open-source, plugin extensible IDE ● Started in 1998 – GPL ● Cross-platform – written in C++/Qt ● Supports many languages ● C++ ● Python, PHP, Ruby, QML/JS, … ● Debugger integration ● GDB, Xdebug (PHP) – no LLDB yet! :'( ● Known for its powerful code navigation/completion support History of C++ Language Support ● Issues with current C++ Support ● Custom parser living inside KDevelop code base ● Over 50 000 LOC ● Hard to maintain, even harder to extend – Hint: C++11, C++14, … ● Lots of issues with non-trivial C/C++ code – (designated initializers, ...) ● Not possible to disambiguate between C vs. C++, or separate C++ standard versions ● ... Kevin Funk Clang Integration in KDevelop 3 Clang to the Rescue! ● C/C++/ObjC language frontend for LLVM ● Features ● Expressive diagnostics ● Allows tight integration with IDEs ● BSD-licensed ● Highly active community ● Stable API via libclang Kevin Funk Clang Integration in KDevelop 4 Implementation overview Kevin Funk Clang Integration in KDevelop 5 Language Support Architecture 12 10 8 Column 1 6 Column 2 Column 3 4 2 0 Row 1 Row 2 Row 3 Row 4 new plugin Kevin Funk Clang Integration in KDevelop 6 Libclang Features Used ● C++ AST introspection ● Extract definitions, uses, their attributes ● Diagnostic reporting ● Spell-checking, fixits ● Macro definitions/expansions ● PCH generation ● Unsaved files for editor buffers ● Code completion Kevin Funk Clang Integration in KDevelop -

Easy Development of Web Applications Using Webodra2 and a Dedicated IDE
International Journal on Advances in Internet Technology, vol 6 no 3 & 4, year 2013, http://www.iariajournals.org/internet_technology/ 156 Easy Development of Web Applications using WebODRA2 and a Dedicated IDE Mariusz Trzaska Chair of Software Engineering Polish-Japanese Institute of Information Technology Warsaw, Poland [email protected] Abstract - The modern Web requires new ways for creating proposed to solve or reduce the problem. In particular, applications. We present our approach combining a web following Trzaska [2], the solution could use a single model framework with a modern object-oriented database and a both for the business logic and data. dedicated Integrated Development Environment (IDE). It Aside of frameworks, one of the most popular software, makes it easier to develop web applications by rising the level of widely utilized by programmers, is an Integrated abstraction. In contrast to many existing solutions, where the Development Environment (IDE). Various IDEs are on the business logic is developed in an object-oriented programming scene for many years. They provide many different services language and data is stored and processed in a relational system, and are invaluable help during software development. At the our proposal employs a single programming and query basic level they just support a programming language. language. Such a solution, together with flexible routing rules, However, their real power can be experienced when they have creates a coherent ecosystem and, as an additional benefit, reduces the impedance mismatch. Our research is supported by dedicated functionalities for particular frameworks. Similarly a working prototype of the IDE and a web framework for our to the situations with the frameworks, prototype solutions are own object-oriented database management system.