WHAD: Wikipedia Historical Attributes Data Historical Structured Data Extraction and Vandalism Detection from the Wikipedia Edit History
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Position Description Addenda
POSITION DESCRIPTION January 2014 Wikimedia Foundation Executive Director - Addenda The Wikimedia Foundation is a radically transparent organization, and much information can be found at www.wikimediafoundation.org . That said, certain information might be particularly useful to nominators and prospective candidates, including: Announcements pertaining to the Wikimedia Foundation Executive Director Search Kicking off the search for our next Executive Director by Former Wikimedia Foundation Board Chair Kat Walsh An announcement from Wikimedia Foundation ED Sue Gardner by Wikimedia Executive Director Sue Gardner Video Interviews on the Wikimedia Community and Foundation and Its History Some of the values and experiences of the Wikimedia Community are best described directly by those who have been intimately involved in the organization’s dramatic expansion. The following interviews are available for viewing though mOppenheim.TV . • 2013 Interview with Former Wikimedia Board Chair Kat Walsh • 2013 Interview with Wikimedia Executive Director Sue Gardner • 2009 Interview with Wikimedia Executive Director Sue Gardner Guiding Principles of the Wikimedia Foundation and the Wikimedia Community The following article by Sue Gardner, the current Executive Director of the Wikimedia Foundation, has received broad distribution and summarizes some of the core cultural values shared by Wikimedia’s staff, board and community. Topics covered include: • Freedom and open source • Serving every human being • Transparency • Accountability • Stewardship • Shared power • Internationalism • Free speech • Independence More information can be found at: https://meta.wikimedia.org/wiki/User:Sue_Gardner/Wikimedia_Foundation_Guiding_Principles Wikimedia Policies The Wikimedia Foundation has an extensive list of policies and procedures available online at: http://wikimediafoundation.org/wiki/Policies Wikimedia Projects All major projects of the Wikimedia Foundation are collaboratively developed by users around the world using the MediaWiki software. -

Wikibase Knowledge Graphs for Data Management & Data Science
Business and Economics Research Data Center https://www.berd-bw.de Baden-Württemberg Wikibase knowledge graphs for data management & data science Dr. Renat Shigapov 23.06.2021 @shigapov @_shigapov DATA Motivation MANAGEMENT 1. people DATA SCIENCE knowledg! 2. processes information linking 3. technology data things KNOWLEDGE GRAPHS 2 DATA Flow MANAGEMENT Definitions DATA Wikidata & Tools SCIENCE Local Wikibase Wikibase Ecosystem Summary KNOWLEDGE GRAPHS 29.10.2012 2030 2021 3 DATA Example: Named Entity Linking SCIENCE https://commons.wikimedia.org/wiki/File:Entity_Linking_-_Short_Example.png Rule#$as!d problems Machine Learning De!' Learning Learn data science at https://www.kaggle.com 4 https://commons.wikimedia.org/wiki/File:Data_visualization_process_v1.png DATA Example: general MANAGEMENT research data silos data fabric data mesh data space data marketplace data lake data swamp Research data lifecycle https://www.reading.ac.uk/research-services/research-data-management/ 5 https://www.dama.org/cpages/body-of-knowledge about-research-data-management/the-research-data-lifecycle KNOWLEDGE ONTOLOG( + GRAPH = + THINGS https://www.mediawiki.org https://www.wikiba.se ✔ “Things, not strings” by Google, 2012 + ✔ A knowledge graph links things in different datasets https://mariadb.org https://blazegraph.com ✔ A knowledge graph can link people & relational database graph database processes and enhance technologies The main example: “THE KNOWLEDGE GRAPH COOKBOOK RECIPES THAT WORK” by ANDREAS BLUMAUER & HELMUT NAGY, 2020. https://www.wikidata.org -

Wiki-Reliability: a Large Scale Dataset for Content Reliability on Wikipedia
Wiki-Reliability: A Large Scale Dataset for Content Reliability on Wikipedia KayYen Wong∗ Miriam Redi Diego Saez-Trumper Outreachy Wikimedia Foundation Wikimedia Foundation Kuala Lumpur, Malaysia London, United Kingdom Barcelona, Spain [email protected] [email protected] [email protected] ABSTRACT Wikipedia is the largest online encyclopedia, used by algorithms and web users as a central hub of reliable information on the web. The quality and reliability of Wikipedia content is maintained by a community of volunteer editors. Machine learning and information retrieval algorithms could help scale up editors’ manual efforts around Wikipedia content reliability. However, there is a lack of large-scale data to support the development of such research. To fill this gap, in this paper, we propose Wiki-Reliability, the first dataset of English Wikipedia articles annotated with a wide set of content reliability issues. To build this dataset, we rely on Wikipedia “templates”. Tem- plates are tags used by expert Wikipedia editors to indicate con- Figure 1: Example of an English Wikipedia page with several tent issues, such as the presence of “non-neutral point of view” template messages describing reliability issues. or “contradictory articles”, and serve as a strong signal for detect- ing reliability issues in a revision. We select the 10 most popular 1 INTRODUCTION reliability-related templates on Wikipedia, and propose an effective method to label almost 1M samples of Wikipedia article revisions Wikipedia is one the largest and most widely used knowledge as positive or negative with respect to each template. Each posi- repositories in the world. People use Wikipedia for studying, fact tive/negative example in the dataset comes with the full article checking and a wide set of different information needs [11]. -

Towards a Korean Dbpedia and an Approach for Complementing the Korean Wikipedia Based on Dbpedia
Towards a Korean DBpedia and an Approach for Complementing the Korean Wikipedia based on DBpedia Eun-kyung Kim1, Matthias Weidl2, Key-Sun Choi1, S¨orenAuer2 1 Semantic Web Research Center, CS Department, KAIST, Korea, 305-701 2 Universit¨at Leipzig, Department of Computer Science, Johannisgasse 26, D-04103 Leipzig, Germany [email protected], [email protected] [email protected], [email protected] Abstract. In the first part of this paper we report about experiences when applying the DBpedia extraction framework to the Korean Wikipedia. We improved the extraction of non-Latin characters and extended the framework with pluggable internationalization components in order to fa- cilitate the extraction of localized information. With these improvements we almost doubled the amount of extracted triples. We also will present the results of the extraction for Korean. In the second part, we present a conceptual study aimed at understanding the impact of international resource synchronization in DBpedia. In the absence of any informa- tion synchronization, each country would construct its own datasets and manage it from its users. Moreover the cooperation across the various countries is adversely affected. Keywords: Synchronization, Wikipedia, DBpedia, Multi-lingual 1 Introduction Wikipedia is the largest encyclopedia of mankind and is written collaboratively by people all around the world. Everybody can access this knowledge as well as add and edit articles. Right now Wikipedia is available in 260 languages and the quality of the articles reached a high level [1]. However, Wikipedia only offers full-text search for this textual information. For that reason, different projects have been started to convert this information into structured knowledge, which can be used by Semantic Web technologies to ask sophisticated queries against Wikipedia. -
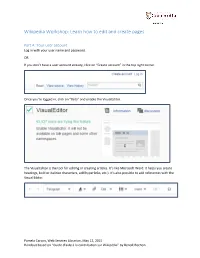
Wikipedia Workshop: Learn How to Edit and Create Pages
Wikipedia Workshop: Learn how to edit and create pages Part A: Your user account Log in with your user name and password. OR If you don’t have a user account already, click on “Create account” in the top right corner. Once you’re logged in, click on “Beta” and enable the VisualEditor. The VisualEditor is the tool for editing or creating articles. It’s like Microsoft Word: it helps you create headings, bold or italicize characters, add hyperlinks, etc.). It’s also possible to add references with the Visual Editor. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part B: Write a sentence or two about yourself Click on your username. This will lead you to your user page. The URL will be: https://en.wikipedia.org/wiki/User:[your user name] Exercise: Click on “Edit source” and write about yourself, then enter a description of your change in the “Edit summary” box and click “Save page”. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part C: Edit an existing article To edit a Wikipedia article, click on the tab “Edit” or “Edit source” (for more advanced users) available at the top of any page. These tabs are also available beside any section title within an article. Editing an entire page Editing just a section Need help? https://en.wikipedia.org/wiki/Wikipedia:Tutorial/Editing Exercise: Go to http://www.statcan.gc.ca/ and find a statistic that interests you. -

The Culture of Wikipedia
Good Faith Collaboration: The Culture of Wikipedia Good Faith Collaboration The Culture of Wikipedia Joseph Michael Reagle Jr. Foreword by Lawrence Lessig The MIT Press, Cambridge, MA. Web edition, Copyright © 2011 by Joseph Michael Reagle Jr. CC-NC-SA 3.0 Purchase at Amazon.com | Barnes and Noble | IndieBound | MIT Press Wikipedia's style of collaborative production has been lauded, lambasted, and satirized. Despite unease over its implications for the character (and quality) of knowledge, Wikipedia has brought us closer than ever to a realization of the centuries-old Author Bio & Research Blog pursuit of a universal encyclopedia. Good Faith Collaboration: The Culture of Wikipedia is a rich ethnographic portrayal of Wikipedia's historical roots, collaborative culture, and much debated legacy. Foreword Preface to the Web Edition Praise for Good Faith Collaboration Preface Extended Table of Contents "Reagle offers a compelling case that Wikipedia's most fascinating and unprecedented aspect isn't the encyclopedia itself — rather, it's the collaborative culture that underpins it: brawling, self-reflexive, funny, serious, and full-tilt committed to the 1. Nazis and Norms project, even if it means setting aside personal differences. Reagle's position as a scholar and a member of the community 2. The Pursuit of the Universal makes him uniquely situated to describe this culture." —Cory Doctorow , Boing Boing Encyclopedia "Reagle provides ample data regarding the everyday practices and cultural norms of the community which collaborates to 3. Good Faith Collaboration produce Wikipedia. His rich research and nuanced appreciation of the complexities of cultural digital media research are 4. The Puzzle of Openness well presented. -

Initiativen Roger Cloes Infobrief
Wissenschaftliche Dienste Deutscher Bundestag Infobrief Entwicklung und Bedeutung der im Internet ehrenamtlich eingestell- ten Wissensangebote insbesondere im Hinblick auf die Wiki- Initiativen Roger Cloes WD 10 - 3010 - 074/11 Wissenschaftliche Dienste Infobrief Seite 2 WD 10 - 3010 - 074/11 Entwicklung und Bedeutung der ehrenamtlich im Internet eingestellten Wissensangebote insbe- sondere im Hinblick auf die Wiki-Initiativen Verfasser: Dr. Roger Cloes / Tim Moritz Hector (Praktikant) Aktenzeichen: WD 10 - 3010 - 074/11 Abschluss der Arbeit: 1. Juli 2011 Fachbereich: WD 10: Kultur, Medien und Sport Ausarbeitungen und andere Informationsangebote der Wissenschaftlichen Dienste geben nicht die Auffassung des Deutschen Bundestages, eines seiner Organe oder der Bundestagsverwaltung wieder. Vielmehr liegen sie in der fachlichen Verantwortung der Verfasserinnen und Verfasser sowie der Fachbereichsleitung. Der Deutsche Bundestag behält sich die Rechte der Veröffentlichung und Verbreitung vor. Beides bedarf der Zustimmung der Leitung der Abteilung W, Platz der Republik 1, 11011 Berlin. Wissenschaftliche Dienste Infobrief Seite 3 WD 10 - 3010 - 074/11 Zusammenfassung Ehrenamtlich ins Internet eingestelltes Wissen spielt in Zeiten des sogenannten „Mitmachweb“ eine zunehmend herausgehobene Rolle. Vor allem Wikis und insbesondere Wikipedia sind ein nicht mehr wegzudenkendes Element des Internets. Keine anderen vergleichbaren Wissensange- bote im Internet, auch wenn sie zum freien Abruf eingestellt sind und mit Steuern, Gebühren, Werbeeinnahmen finanziert oder als Gratisproben im Rahmen von Geschäftsmodellen verschenkt werden, erreichen die Zugriffszahlen von Wikipedia. Das ist ein Phänomen, das in seiner Dimension vor dem Hintergrund der urheberrechtlichen Dis- kussion und der Begründung von staatlichem Schutz als Voraussetzung für die Schaffung von geistigen Gütern kaum Beachtung findet. Relativ niedrige Verbreitungskosten im Internet und geringe oder keine Erfordernisse an Kapitalinvestitionen begünstigen diese Entwicklung. -
Building a Visual Editor for Wikipedia
Building a Visual Editor for Wikipedia Trevor Parscal and Roan Kattouw Wikimania D.C. 2012 (Introduce yourself) (Introduce yourself) We’d like to talk to you about how we’ve been building a visual editor for Wikipedia Trevor Parscal Roan Kattouw Rob Moen Lead Designer and Engineer Data Model Engineer User Interface Engineer Wikimedia Wikimedia Wikimedia Inez Korczynski Christian Williams James Forrester Edit Surface Engineer Edit Surface Engineer Product Analyst Wikia Wikia Wikimedia The People Wikimania D.C. 2012 We are only 2/6ths of the VisualEditor team Our team includes 2 engineers from Wikia - they also use MediaWiki They also fight crime in their of time Parsoid Team Gabriel Wicke Subbu Sastry Lead Parser Engineer Parser Engineer Wikimedia Wikimedia The People Wikimania D.C. 2012 There’s also two remote people working on a new parser This parser makes what we are doing with the VisualEditor possible The Project Wikimania D.C. 2012 You might recognize this, it’s a Wikipedia article You should edit it! Seems simple enough, just hit the edit button and be on your way... The Complexity Problem Wikimania D.C. 2012 Or not... What is all this nonsense you may ask? Well, it’s called Wikitext! Even really smart people who have a lot to contribute to Wikipedia find it confusing The truth is, Wikitext is a lousy IQ test, and it’s holding Wikipedia back, severely Active Editors 20k 0 2001 2007 Today Growth Stagnation The Complexity Problem Wikimania D.C. 2012 The internet has normal people on it now, not just geeks and weirdoes Normal people like simple things, and simple things are growing fast We must make editing Wikipedia easier to use, not just to grow, but even just to stay alive The Complexity Problem Wikimania D.C. -

Improving Knowledge Base Construction from Robust Infobox Extraction
Improving Knowledge Base Construction from Robust Infobox Extraction Boya Peng∗ Yejin Huh Xiao Ling Michele Banko∗ Apple Inc. 1 Apple Park Way Sentropy Technologies Cupertino, CA, USA {yejin.huh,xiaoling}@apple.com {emma,mbanko}@sentropy.io∗ Abstract knowledge graph created largely by human edi- tors. Only 46% of person entities in Wikidata A capable, automatic Question Answering have birth places available 1. An estimate of 584 (QA) system can provide more complete million facts are maintained in Wikipedia, not in and accurate answers using a comprehen- Wikidata (Hellmann, 2018). A downstream appli- sive knowledge base (KB). One important cation such as Question Answering (QA) will suf- approach to constructing a comprehensive knowledge base is to extract information from fer from this incompleteness, and fail to answer Wikipedia infobox tables to populate an ex- certain questions or even provide an incorrect an- isting KB. Despite previous successes in the swer especially for a question about a list of enti- Infobox Extraction (IBE) problem (e.g., DB- ties due to a closed-world assumption. Previous pedia), three major challenges remain: 1) De- work on enriching and growing existing knowl- terministic extraction patterns used in DBpe- edge bases includes relation extraction on nat- dia are vulnerable to template changes; 2) ural language text (Wu and Weld, 2007; Mintz Over-trusting Wikipedia anchor links can lead to entity disambiguation errors; 3) Heuristic- et al., 2009; Hoffmann et al., 2011; Surdeanu et al., based extraction of unlinkable entities yields 2012; Koch et al., 2014), knowledge base reason- low precision, hurting both accuracy and com- ing from existing facts (Lao et al., 2011; Guu et al., pleteness of the final KB. -

Wikipedia Editing History in Dbpedia Fabien Gandon, Raphael Boyer, Olivier Corby, Alexandre Monnin
Wikipedia editing history in DBpedia Fabien Gandon, Raphael Boyer, Olivier Corby, Alexandre Monnin To cite this version: Fabien Gandon, Raphael Boyer, Olivier Corby, Alexandre Monnin. Wikipedia editing history in DB- pedia : extracting and publishing the encyclopedia editing activity as linked data. IEEE/WIC/ACM International Joint Conference on Web Intelligence (WI’ 16), Oct 2016, Omaha, United States. hal- 01359575 HAL Id: hal-01359575 https://hal.inria.fr/hal-01359575 Submitted on 2 Sep 2016 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Wikipedia editing history in DBpedia extracting and publishing the encyclopedia editing activity as linked data Fabien Gandon, Raphael Boyer, Olivier Corby, Alexandre Monnin Université Côte d’Azur, Inria, CNRS, I3S, France Wimmics, Sophia Antipolis, France [email protected] Abstract— DBpedia is a huge dataset essentially extracted example, the French editing history dump represents 2TB of from the content and structure of Wikipedia. We present a new uncompressed data. This data extraction is performed by extraction producing a linked data representation of the editing stream in Node.js with a MongoDB instance. It takes 4 days to history of Wikipedia pages. This supports custom querying and extract 55 GB of RDF in turtle on 8 Intel(R) Xeon(R) CPU E5- combining with other data providing new indicators and insights. -

Reliability of Wikipedia 1 Reliability of Wikipedia
Reliability of Wikipedia 1 Reliability of Wikipedia The reliability of Wikipedia (primarily of the English language version), compared to other encyclopedias and more specialized sources, is assessed in many ways, including statistically, through comparative review, analysis of the historical patterns, and strengths and weaknesses inherent in the editing process unique to Wikipedia. [1] Because Wikipedia is open to anonymous and collaborative editing, assessments of its Vandalism of a Wikipedia article reliability usually include examinations of how quickly false or misleading information is removed. An early study conducted by IBM researchers in 2003—two years following Wikipedia's establishment—found that "vandalism is usually repaired extremely quickly — so quickly that most users will never see its effects"[2] and concluded that Wikipedia had "surprisingly effective self-healing capabilities".[3] A 2007 peer-reviewed study stated that "42% of damage is repaired almost immediately... Nonetheless, there are still hundreds of millions of damaged views."[4] Several studies have been done to assess the reliability of Wikipedia. A notable early study in the journal Nature suggested that in 2005, Wikipedia scientific articles came close to the level of accuracy in Encyclopædia Britannica and had a similar rate of "serious errors".[5] This study was disputed by Encyclopædia Britannica.[6] By 2010 reviewers in medical and scientific fields such as toxicology, cancer research and drug information reviewing Wikipedia against professional and peer-reviewed sources found that Wikipedia's depth and coverage were of a very high standard, often comparable in coverage to physician databases and considerably better than well known reputable national media outlets. -

A Complete, Longitudinal and Multi-Language Dataset of the Wikipedia Link Networks
WikiLinkGraphs: A Complete, Longitudinal and Multi-Language Dataset of the Wikipedia Link Networks Cristian Consonni David Laniado Alberto Montresor DISI, University of Trento Eurecat, Centre Tecnologic` de Catalunya DISI, University of Trento [email protected] [email protected] [email protected] Abstract and result in a huge conceptual network. According to Wiki- pedia policies2 (Wikipedia contributors 2018e), when a con- Wikipedia articles contain multiple links connecting a sub- cept is relevant within an article, the article should include a ject to other pages of the encyclopedia. In Wikipedia par- link to the page corresponding to such concept (Borra et al. lance, these links are called internal links or wikilinks. We present a complete dataset of the network of internal Wiki- 2015). Therefore, the network between articles may be seen pedia links for the 9 largest language editions. The dataset as a giant mind map, emerging from the links established by contains yearly snapshots of the network and spans 17 years, the community. Such graph is not static but is continuously from the creation of Wikipedia in 2001 to March 1st, 2018. growing and evolving, reflecting the endless collaborative While previous work has mostly focused on the complete hy- process behind it. perlink graph which includes also links automatically gener- The English Wikipedia includes over 163 million con- ated by templates, we parsed each revision of each article to nections between its articles. This huge graph has been track links appearing in the main text. In this way we obtained exploited for many purposes, from natural language pro- a cleaner network, discarding more than half of the links and cessing (Yeh et al.