Imperative Programs and the Lambda Calculus in This Handout, We Discuss How Imperative Programming and the Lambda Calculus Framework Can Work Together
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

General Education and Liberal Studies Course List
GELS 2020–2021 General Education/Liberal Studies/Minnesota Transfer Curriculum 2020–2021 Course List This course list is current as of March 25, 2021. For the most current information view the Current GELS/MnTC list on the Class Schedule page at www.metrostate.edu. This is the official list of Metropolitan State University courses that meet the General Education and Liberal Studies (GELS) requirements for all undergraduate students admitted to the university. To meet the university’s General Education and Liberal Studies (GELS) requirements, students must complete each of the 10 goal areas of the Minnesota Transfer Curriculum (MnTC) and complete 48 unduplicated credits. Eight (8) of the 48 credits must be upper division (300-level or higher) to fulfill the university’s Liberal Studies requirement. Each course title is followed by a number in parenthesis (4). This number indicates the number of credits for that course. Course titles followed by more than one number, such as (2-4), indicate a variable-credit course. Superscript Number: • Superscript number (10) indicates that a course meets more than one goal area requirement. For example, NSCI 20410 listed under Goal 3 meets Goals 3 and 10. Although the credits count only once, the course satisfies the two goal area requirements. • Separated by a comma (3,LS) indicates that a course will meet both areas indicated. • Separated by a forward slash (7/8) indicates that a course will meet one or the other goal area but not both. Superscript LS (LS): • Indicates that a course will meet the Liberal Studies requirement. Asterisk (*): • Indicates that a course can be used to meet goal area requirements, but cannot be used as General Education or Liberal Studies Electives. -

Understanding the Syntactic Rule Usage in Java
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by UCL Discovery Understanding the Syntactic Rule Usage in Java Dong Qiua, Bixin Lia,∗, Earl T. Barrb, Zhendong Suc aSchool of Computer Science and Engineering, Southeast University, China bDepartment of Computer Science, University College London, UK cDepartment of Computer Science, University of California Davis, USA Abstract Context: Syntax is fundamental to any programming language: syntax defines valid programs. In the 1970s, computer scientists rigorously and empirically studied programming languages to guide and inform language design. Since then, language design has been artistic, driven by the aesthetic concerns and intuitions of language architects. Despite recent studies on small sets of selected language features, we lack a comprehensive, quantitative, empirical analysis of how modern, real-world source code exercises the syntax of its programming language. Objective: This study aims to understand how programming language syntax is employed in actual development and explore their potential applications based on the results of syntax usage analysis. Method: We present our results on the first such study on Java, a modern, mature, and widely-used programming language. Our corpus contains over 5,000 open-source Java projects, totalling 150 million source lines of code (SLoC). We study both independent (i.e. applications of a single syntax rule) and dependent (i.e. applications of multiple syntax rules) rule usage, and quantify their impact over time and project size. Results: Our study provides detailed quantitative information and yields insight, particularly (i) confirming the conventional wisdom that the usage of syntax rules is Zipfian; (ii) showing that the adoption of new rules and their impact on the usage of pre-existing rules vary significantly over time; and (iii) showing that rule usage is highly contextual. -

S-Algol Reference Manual Ron Morrison
S-algol Reference Manual Ron Morrison University of St. Andrews, North Haugh, Fife, Scotland. KY16 9SS CS/79/1 1 Contents Chapter 1. Preface 2. Syntax Specification 3. Types and Type Rules 3.1 Universe of Discourse 3.2 Type Rules 4. Literals 4.1 Integer Literals 4.2 Real Literals 4.3 Boolean Literals 4.4 String Literals 4.5 Pixel Literals 4.6 File Literal 4.7 pntr Literal 5. Primitive Expressions and Operators 5.1 Boolean Expressions 5.2 Comparison Operators 5.3 Arithmetic Expressions 5.4 Arithmetic Precedence Rules 5.5 String Expressions 5.6 Picture Expressions 5.7 Pixel Expressions 5.8 Precedence Table 5.9 Other Expressions 6. Declarations 6.1 Identifiers 6.2 Variables, Constants and Declaration of Data Objects 6.3 Sequences 6.4 Brackets 6.5 Scope Rules 7. Clauses 7.1 Assignment Clause 7.2 if Clause 7.3 case Clause 7.4 repeat ... while ... do ... Clause 7.5 for Clause 7.6 abort Clause 8. Procedures 8.1 Declarations and Calls 8.2 Forward Declarations 2 9. Aggregates 9.1 Vectors 9.1.1 Creation of Vectors 9.1.2 upb and lwb 9.1.3 Indexing 9.1.4 Equality and Equivalence 9.2 Structures 9.2.1 Creation of Structures 9.2.2 Equality and Equivalence 9.2.3 Indexing 9.3 Images 9.3.1 Creation of Images 9.3.2 Indexing 9.3.3 Depth Selection 9.3.4 Equality and Equivalence 10. Input and Output 10.1 Input 10.2 Output 10.3 i.w, s.w and r.w 10.4 End of File 11. -

LINUX INTERNALS LABORATORY III. Understand Process
LINUX INTERNALS LABORATORY VI Semester: IT Course Code Category Hours / Week Credits Maximum Marks L T P C CIA SEE Total AIT105 Core - - 3 2 30 70 100 Contact Classes: Nil Tutorial Classes: Nil Practical Classes: 36 Total Classes: 36 OBJECTIVES: The course should enable the students to: I. Familiar with the Linux command-line environment. II. Understand system administration processes by providing a hands-on experience. III. Understand Process management and inter-process communications techniques. LIST OF EXPERIMENTS Week-1 BASIC COMMANDS I Study and Practice on various commands like man, passwd, tty, script, clear, date, cal, cp, mv, ln, rm, unlink, mkdir, rmdir, du, df, mount, umount, find, unmask, ulimit, ps, who, w. Week-2 BASIC COMMANDS II Study and Practice on various commands like cat, tail, head , sort, nl, uniq, grep, egrep,fgrep, cut, paste, join, tee, pg, comm, cmp, diff, tr, awk, tar, cpio. Week-3 SHELL PROGRAMMING I a) Write a Shell Program to print all .txt files and .c files. b) Write a Shell program to move a set of files to a specified directory. c) Write a Shell program to display all the users who are currently logged in after a specified time. d) Write a Shell Program to wish the user based on the login time. Week-4 SHELL PROGRAMMING II a) Write a Shell program to pass a message to a group of members, individual member and all. b) Write a Shell program to count the number of words in a file. c) Write a Shell program to calculate the factorial of a given number. -
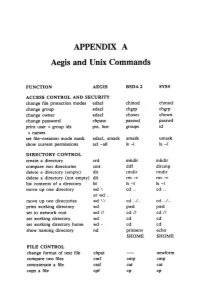
APPENDIX a Aegis and Unix Commands
APPENDIX A Aegis and Unix Commands FUNCTION AEGIS BSD4.2 SYSS ACCESS CONTROL AND SECURITY change file protection modes edacl chmod chmod change group edacl chgrp chgrp change owner edacl chown chown change password chpass passwd passwd print user + group ids pst, lusr groups id +names set file-creation mode mask edacl, umask umask umask show current permissions acl -all Is -I Is -I DIRECTORY CONTROL create a directory crd mkdir mkdir compare two directories cmt diff dircmp delete a directory (empty) dlt rmdir rmdir delete a directory (not empty) dlt rm -r rm -r list contents of a directory ld Is -I Is -I move up one directory wd \ cd .. cd .. or wd .. move up two directories wd \\ cd . ./ .. cd . ./ .. print working directory wd pwd pwd set to network root wd II cd II cd II set working directory wd cd cd set working directory home wd- cd cd show naming directory nd printenv echo $HOME $HOME FILE CONTROL change format of text file chpat newform compare two files emf cmp cmp concatenate a file catf cat cat copy a file cpf cp cp Using and Administering an Apollo Network 265 copy std input to std output tee tee tee + files create a (symbolic) link crl In -s In -s delete a file dlf rm rm maintain an archive a ref ar ar move a file mvf mv mv dump a file dmpf od od print checksum and block- salvol -a sum sum -count of file rename a file chn mv mv search a file for a pattern fpat grep grep search or reject lines cmsrf comm comm common to 2 sorted files translate characters tic tr tr SHELL SCRIPT TOOLS condition evaluation tools existf test test -

Sugarj: Library-Based Syntactic Language Extensibility
SugarJ: Library-based Syntactic Language Extensibility Sebastian Erdweg, Tillmann Rendel, Christian Kastner,¨ and Klaus Ostermann University of Marburg, Germany Abstract import pair.Sugar; Existing approaches to extend a programming language with syntactic sugar often leave a bitter taste, because they cannot public class Test f be used with the same ease as the main extension mechanism private (String, Integer) p = ("12", 34); of the programming language—libraries. Sugar libraries are g a novel approach for syntactically extending a programming Figure 1. Using a sugar library for pairs. language within the language. A sugar library is like an or- dinary library, but can, in addition, export syntactic sugar for using the library. Sugar libraries maintain the compos- 1. Introduction ability and scoping properties of ordinary libraries and are Bridging the gap between domain concepts and the imple- hence particularly well-suited for embedding a multitude of mentation of these concepts in a programming language is domain-specific languages into a host language. They also one of the “holy grails” of software development. Domain- inherit self-applicability from libraries, which means that specific languages (DSLs), such as regular expressions for sugar libraries can provide syntactic extensions for the defi- the domain of text recognition or Java Server Pages for the nition of other sugar libraries. domain of dynamic web pages have often been proposed To demonstrate the expressiveness and applicability of to address this problem [31]. To use DSLs in large soft- sugar libraries, we have developed SugarJ, a language on ware systems that touch multiple domains, developers have top of Java, SDF and Stratego, which supports syntactic to be able to compose multiple domain-specific languages extensibility. -

Syntactic Sugar Programming Languages' Constructs - Preliminary Study
ICIT 2011 The 5th International Conference on Information Technology Syntactic Sugar Programming Languages' Constructs - Preliminary Study #1 #2 Mustafa Al-Tamim , Rashid Jayousi Department of Computer Science, Al-Quds University, Jerusalem, Palestine [email protected] 00972-59-9293002 [email protected] 00972-52-7456731 ICIT 2011 The 5th International Conference on Information Technology Syntactic Sugar Programming Languages' Constructs - Preliminary Study #1 #2 Mustafa Al-Tamim , Rashid Jayousi Department of Computer Science, Al-Quds University, Jerusalem, Palestine [email protected] [email protected] Abstract— Software application development is a daily task done syntax and help in making it more readable, easier to write, by developers and code writer all over the world. Valuable less syntax errors and less ambiguous. portion of developers’ time is spent in writing repetitive In this research, we proposed new set of syntactic sugar keywords, debugging code, trying to understand its semantic, constructs that can be composed by a mixture of existing and fixing syntax errors. These tasks become harder when no constructs obtained from some programming languages in integrated development environment (IDE) is available or developers use remote access terminals like UNIX and simple addition to syntactic enhancements suggested by us. Through text editors for code writing. Syntactic sugar constructs in our work as software developer, team leaders, and guiding programming languages are found to offer simple and easy many students in their projects, we noticed that developers syntax constructs to make developers life easier and smother. In write a lot of repetitive keywords in specific parts of code like this paper, we propose a new set of syntactic sugar constructs, packages calling keywords, attributes access modifiers, code and try to find if they really can help developers in eliminating segments and building blocks’ scopes determination symbols syntax errors, make code more readable, more easier to write, and others. -

Compiler Construction E Syntactic Sugar E
Compiler Construction e Syntactic sugar E Compiler Construction Syntactic sugar 1 / 16 Syntactic sugar & Desugaring Syntactic Sugar Additions to a language to make it easier to read or write, but that do not change the expressiveness Desugaring Higher-level features that can be decomposed into language core of essential constructs ) This process is called ”desugaring”. Compiler Construction Syntactic sugar 2 / 16 Pros & Cons for syntactic sugar Pros More readable, More writable Express things more elegantly Cons Adds bloat to the languages Syntactic sugar can affect the formal structure of a language Compiler Construction Syntactic sugar 3 / 16 Syntactic Sugar in Lambda-Calculus The term ”syntactic sugar” was coined by Peter J. Landin in 1964, while describing an ALGOL-like language that was defined in term of lambda-calculus ) goal: replace λ by where Curryfication λxy:e ) λx:(λy:e) Local variables let x = e1 in e2 ) (λx:e2):e1 Compiler Construction Syntactic sugar 4 / 16 List Comprehension in Haskell qs [] = [] qs (x:xs) = qs lt_x ++ [x] ++ qs ge_x where lt_x = [y | y <- xs, y < x] ge_x = [y | y <- xs, x <= y] Compiler Construction Syntactic sugar 5 / 16 List Comprehension in Haskell Sugared [(x,y) | x <- [1 .. 6], y <- [1 .. x], x+y < 10] Desugared filter p (concat (map (\ x -> map (\ y -> (x,y)) [1..x]) [1..6] ) ) where p (x,y) = x+y < 10 Compiler Construction Syntactic sugar 6 / 16 Interferences with error messages ”true” | 42 standard input:1.1-6: type mismatch condition type: string expected type: int function _main() = ( (if "true" then 1 else (42 <> 0)); () ) Compiler Construction Syntactic sugar 7 / 16 Regular Unary - & and | Beware of ( exp ) vs. -

The UNIX Time- Sharing System
1. Introduction There have been three versions of UNIX. The earliest version (circa 1969–70) ran on the Digital Equipment Cor- poration PDP-7 and -9 computers. The second version ran on the unprotected PDP-11/20 computer. This paper describes only the PDP-11/40 and /45 [l] system since it is The UNIX Time- more modern and many of the differences between it and older UNIX systems result from redesign of features found Sharing System to be deficient or lacking. Since PDP-11 UNIX became operational in February Dennis M. Ritchie and Ken Thompson 1971, about 40 installations have been put into service; they Bell Laboratories are generally smaller than the system described here. Most of them are engaged in applications such as the preparation and formatting of patent applications and other textual material, the collection and processing of trouble data from various switching machines within the Bell System, and recording and checking telephone service orders. Our own installation is used mainly for research in operating sys- tems, languages, computer networks, and other topics in computer science, and also for document preparation. UNIX is a general-purpose, multi-user, interactive Perhaps the most important achievement of UNIX is to operating system for the Digital Equipment Corpora- demonstrate that a powerful operating system for interac- tion PDP-11/40 and 11/45 computers. It offers a number tive use need not be expensive either in equipment or in of features seldom found even in larger operating sys- human effort: UNIX can run on hardware costing as little as tems, including: (1) a hierarchical file system incorpo- $40,000, and less than two man years were spent on the rating demountable volumes; (2) compatible file, device, main system software. -

How to Build a Search-Engine with Common Unix-Tools
The Tenth International Conference on Advances in Databases, Knowledge, and Data Applications Mai 20 - 24, 2018 - Nice/France How to build a Search-Engine with Common Unix-Tools Andreas Schmidt (1) (2) Department of Informatics and Institute for Automation and Applied Informatics Business Information Systems Karlsruhe Institute of Technologie University of Applied Sciences Karlsruhe Germany Germany Andreas Schmidt DBKDA - 2018 1/66 Resources available http://www.smiffy.de/dbkda-2018/ 1 • Slideset • Exercises • Command refcard 1. all materials copyright, 2018 by andreas schmidt Andreas Schmidt DBKDA - 2018 2/66 Outlook • General Architecture of an IR-System • Naive Search + 2 hands on exercices • Boolean Search • Text analytics • Vector Space Model • Building an Inverted Index & • Inverted Index Query processing • Query Processing • Overview of useful Unix Tools • Implementation Aspects • Summary Andreas Schmidt DBKDA - 2018 3/66 What is Information Retrieval ? Information Retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an informa- tion need (usually a query) from within large collections (usually stored on computers). [Manning et al., 2008] Andreas Schmidt DBKDA - 2018 4/66 What is Information Retrieval ? need for query information representation how to match? document document collection representation Andreas Schmidt DBKDA - 2018 5/66 Keyword Search • Given: • Number of Keywords • Document collection • Result: • All documents in the collection, cotaining the keywords • (ranked by relevance) Andreas Schmidt DBKDA - 2018 6/66 Naive Approach • Iterate over all documents d in document collection • For each document d, iterate all words w and check, if all the given keywords appear in this document • if yes, add document to result set • Output result set • Extensions/Variants • Ranking see examples later ... -

Sort, Uniq, Comm, Join Commands
The 19th International Conference on Web Engineering (ICWE-2019) June 11 - 14, 2019 - Daejeon, Korea Powerful Unix-Tools - sort & uniq & comm & join Andreas Schmidt Department of Informatics and Institute for Automation and Applied Informatics Business Information Systems Karlsruhe Institute of Technologie University of Applied Sciences Karlsruhe Germany Germany Andreas Schmidt ICWE - 2019 1/10 sort • Sort lines of text files • Write sorted concatenation of all FILE(s) to standard output. • With no FILE, or when FILE is -, read standard input. • sorting alpabetic, numeric, ascending, descending, case (in)sensitive • column(s)/bytes to be sorted can be specified • Random sort option (-R) • Remove of identical lines (-u) • Examples: • sort file city.csv starting with the second column (field delimiter: ,) sort -k2 -t',' city.csv • merge content of file1.txt and file2.txt and sort the result sort file1.txt file2.txt Andreas Schmidt ICWE - 2019 2/10 sort - examples • sort file by country code, and as a second criteria population (numeric, descending) sort -t, -k2,2 -k4,4nr city.csv numeric (-n), descending (-r) field separator: , second sort criteria from column 4 to column 4 first sort criteria from column 2 to column 2 Andreas Schmidt ICWE - 2019 3/10 sort - examples • Sort by the second and third character of the first column sort -t, -k1.2,1.2 city.csv • Generate a line of unique random numbers between 1 and 10 seq 1 10| sort -R | tr '\n' ' ' • Lottery-forecast (6 from 49) - defective from time to time ;-) seq 1 49 | sort -R | head -n6 -

The Linux Command Line
The Linux Command Line Second Internet Edition William E. Shotts, Jr. A LinuxCommand.org Book Copyright ©2008-2013, William E. Shotts, Jr. This work is licensed under the Creative Commons Attribution-Noncommercial-No De- rivative Works 3.0 United States License. To view a copy of this license, visit the link above or send a letter to Creative Commons, 171 Second Street, Suite 300, San Fran- cisco, California, 94105, USA. Linux® is the registered trademark of Linus Torvalds. All other trademarks belong to their respective owners. This book is part of the LinuxCommand.org project, a site for Linux education and advo- cacy devoted to helping users of legacy operating systems migrate into the future. You may contact the LinuxCommand.org project at http://linuxcommand.org. This book is also available in printed form, published by No Starch Press and may be purchased wherever fine books are sold. No Starch Press also offers this book in elec- tronic formats for most popular e-readers: http://nostarch.com/tlcl.htm Release History Version Date Description 13.07 July 6, 2013 Second Internet Edition. 09.12 December 14, 2009 First Internet Edition. 09.11 November 19, 2009 Fourth draft with almost all reviewer feedback incorporated and edited through chapter 37. 09.10 October 3, 2009 Third draft with revised table formatting, partial application of reviewers feedback and edited through chapter 18. 09.08 August 12, 2009 Second draft incorporating the first editing pass. 09.07 July 18, 2009 Completed first draft. Table of Contents Introduction....................................................................................................xvi