Measuring and Forecasting Mobile Game App Engagement
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Android (Operating System) 1 Android (Operating System)
Android (operating system) 1 Android (operating system) Android Home screen displayed by Samsung Nexus S with Google running Android 2.3 "Gingerbread" Company / developer Google Inc., Open Handset Alliance [1] Programmed in C (core), C++ (some third-party libraries), Java (UI) Working state Current [2] Source model Free and open source software (3.0 is currently in closed development) Initial release 21 October 2008 Latest stable release Tablets: [3] 3.0.1 (Honeycomb) Phones: [3] 2.3.3 (Gingerbread) / 24 February 2011 [4] Supported platforms ARM, MIPS, Power, x86 Kernel type Monolithic, modified Linux kernel Default user interface Graphical [5] License Apache 2.0, Linux kernel patches are under GPL v2 Official website [www.android.com www.android.com] Android is a software stack for mobile devices that includes an operating system, middleware and key applications.[6] [7] Google Inc. purchased the initial developer of the software, Android Inc., in 2005.[8] Android's mobile operating system is based on a modified version of the Linux kernel. Google and other members of the Open Handset Alliance collaborated on Android's development and release.[9] [10] The Android Open Source Project (AOSP) is tasked with the maintenance and further development of Android.[11] The Android operating system is the world's best-selling Smartphone platform.[12] [13] Android has a large community of developers writing applications ("apps") that extend the functionality of the devices. There are currently over 150,000 apps available for Android.[14] [15] Android Market is the online app store run by Google, though apps can also be downloaded from third-party sites. -

Complete Control Mobile App for Ios User's Guide
Complete Control Mobile App for use with a Complete Control system from URC iPhone/iPod touch iPad Complete Control Mobile App Overview As with iOS apps for the iPad, iPhone and iPod touch, finding your way around the Complete Control Mobile App is simple. Although, with the power of a Complete Control system, each and every page shown on the application could be slightly different ( depending upon the system programmer ), there are some consistencies. The button layout for the iOS devices consists of Volume, Channel, Colored, Numeric Keypad, Navigation/Information, Transport and Custom Keys. No matter which view your iOS device is in, portrait or landscape, the button layout is available for full control of your entertainment system. Features and Benefits ● House-Wide Control Control any IR, RS-232 or Relay controlled device anywhere in your home! By simply adding additional MRX-1s, expand control anywhere on your local network. ● iOS Gesture Navigation Use the familiar iOS gestures, like swipe, tap and rotate, to access and control your devices. Browse through the devices and their pages by swiping. Rotate the iPad, iPhone or iPod touch to display the remote in portrait or landscape view. ● Home Lighting Control With the addition of the optional RFTX-1 and URC Lighting by Lutron, easily control the environment within the home. Access lighting scenes, room scenes and specific control of each individual lighting load. 1 Complete Control Mobile App Button Overview The following common buttons are found in the Complete Control Mobile app, regardless of how the system was programmed: Volume/Channel Keys In this section you find VOLUME (Vol +, Vol -, Mute ) commands as well as CHANNEL (CH+, CH-, Jump ) commands for applicable devices. -
Going Live with a Mobile App
An AppDynamics Business White Paper Going live with a mobile app According to a report from Kleiner Perkins, mobile applications now account for 15% of all Internet traffic, with 1.5 billion users worldwide. Whether you are a brick and mortar retailer or an ecommerce web site the need to go mobile is greater than ever. With mobile market share growing year over year, mobile applications are the new web site. If you don’t have one available you are missing a major market. Mobile adoption has accelerated like never before. http://visual.ly/reaching-50-million-users As of May 2013 91% of American adults own a cell phone and 56% of American adults own a smart phone according to a recent survey by Pew Internet. So you want to launch a mobile application and skyrocket to your first 50 million users. There are many concerns when going live with a modern mobile application. From project planning, to development, to quality assurance and managing a successful launch. In this white paper we’ll talk about some important considerations for planning, building and launching a mobile application in order to ensure a good experience for your end users and a good outcome for your business. Phase 1: Planning a mobile application Planning a major mobile application is the one of the most difficult projects to execute. What platforms do you build for and what devices should you support? Do you build your own backend or use a platform as a service? Do you build a native mobile application or a web based HTML5 application? All of these questions and more will come up and you need to understand the market to make decisions you won’t soon regret. -

Taxonomy of Cross-Platform Mobile Applications Development Approaches
Ain Shams Engineering Journal (2015) xxx, xxx–xxx Ain Shams University Ain Shams Engineering Journal www.elsevier.com/locate/asej www.sciencedirect.com ELECTRICAL ENGINEERING Taxonomy of Cross-Platform Mobile Applications Development Approaches Wafaa S. El-Kassas *, Bassem A. Abdullah, Ahmed H. Yousef, Ayman M. Wahba Department of Computer and Systems Engineering, Faculty of Engineering, Ain Shams University, Egypt Received 13 September 2014; revised 30 May 2015; accepted 3 August 2015 KEYWORDS Abstract The developers use the cross-platform mobile development solutions to develop the Cross-platform mobile mobile application once and run it on many platforms. Many of these cross-platform solutions development; are still under research and development. Also, these solutions are based on different approaches Interpretation approach; such as Cross-Compilation approach, Virtual Machine approach, and Web-Based approach. There Cloud computing; are many survey papers about the cross-platform mobile development solutions but they do not Compilation approach; include the most recent approaches, including Component-Based approach, Cloud-Based Component-Based approach, and Merged approach. The main aim of this paper is helping the researchers to know approach; the most recent approaches and the open research issues. This paper surveys the existing cross- Model-Driven Engineering platform mobile development approaches and attempts to provide a global view: it thoroughly introduces a comprehensive categorization to the cross-platform approaches, defines the pros and cons of each approach, explains sample solutions per approach, compares the cross-platform mobile development solutions, and ends with the open research areas. Ó 2015 Faculty of Engineering, Ain Shams University. Production and hosting by Elsevier B.V. -

Download the Chinook Winds Mobile App 1
Download the Chinook Winds Mobile App 1. Navigate to the mobile device’s application store. 2. Search for the Chinook Winds mobile application. 3. Download and install the Chinook Winds mobile application. App Features: Check point balances and tier status. Check your mail offers instantly. Receive additional bonus offers. Easy access to all current events and promotions. Play the Mobile Game Win points or free play! Download the app between November 4, 2020 and April 30, 2021. Must be a Winners Circle member to participate and must be signed into the mobile app with your Winners Circle Player ID. Participants must be onsite at Chinook Winds Casino Resort and have location services turned on to play the mobile game. To access the mobile game, log into the app and click on “Promotions.” Select the “Beach Goes Mobile” tile to access the game. "It's Better at the Beach!" • Lincoln City • 1-888-Chinook Quick Reference Chinook Winds PKMM Patron Access Patrons can download the Chinook Winds loyalty mobile application from their Android or iOS app store and opt in to location services with the touch of a button to access promotions, mobile offers, and more. Download the Chinook Winds Mobile Application NEnableavigate to the Location mobile device’s Services application store.from the SearchMobile for the Application Chinook Winds mobile application. Download and install the Chinook Winds mobile application. Some promotions and offers are available only to patrons who are within specified location ranges. Patrons must opt in to location Enable Locationservices to beServices eligible for from location-enforced the Mobile promotions Application and offers. -
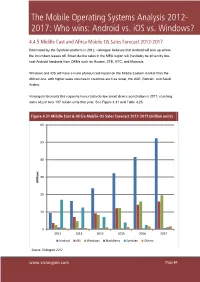
The Mobile Operating Systems Analysis 2012- 2017: Who Wins: Android Vs
The Mobile Operating Systems Analysis 2012- 2017: Who wins: Android vs. iOS vs. Windows? 4.4.5 Middle East and Africa Mobile OS Sales Forecast 2012-2017 Dominated by the Symbian platform in 2012, visiongain believes that Android will pick up where the incumbent leaves off. Smart device sales in the MEA region will inevitably be driven by low- cost Android handsets from OEMs such as Huawei, ZTE, HTC, and Motorola. Windows and iOS will have a more pronounced impact on the Middle Eastern market than the African one, with higher sales volumes in countries such as Israel, the UAE, Bahrain, and Saudi Arabia. Visiongain forecasts this region to have relatively low smart device penetration in 2017, reaching sales of just over 107 million units that year. See Figure 4.31 and Table 4.25. Figure 4.31 Middle East & Africa Mobile OS Sales Forecast 2012-2017 (million units) 60 50 40 30 Millions 20 10 0 2012 2013 2014 2015 2016 2017 Android iOS Windows BlackBerry Symbian Others Source: Visiongain 2012 www.visiongain.com PagePage 8484 The Mobile Operating Systems Analysis 2012- 2017: Who wins: Android vs. iOS vs. Windows? Figure 4.32 Middle East & Africa Mobile OS Sales Forecast Market Share 2012 (% Share) 2.5% 27.2% 49.6% 10.5% 7.0% 3.1% Android iOS Windows BlackBerry Symbian Others Source: Visiongain 2012 Figure 4.33 Middle East & Africa Mobile OS Sales Forecast Market Share 2014 (% Share) 2.4% 14.3% 1.2% 47.4% 16.4% 18.3% Android iOS Windows BlackBerry Symbian Others Source: Visiongain 2012 www.visiongain.com PagePage 8686 The Mobile Operating Systems Analysis 2012- 2017: Who wins: Android vs. -
![[WEEKLY WIRELESS REPORT] Week Ending September 30, 2011](https://docslib.b-cdn.net/cover/6675/weekly-wireless-report-week-ending-september-30-2011-1036675.webp)
[WEEKLY WIRELESS REPORT] Week Ending September 30, 2011
[WEEKLY WIRELESS REPORT] Week ending September 30, 2011 This Week’s Stories key rhetorical question: "Why not just evolve MeeGo?" The answer, he said, is that "the future belongs to HTML5-based applications, outside of a AT&T Mobility Suffers Huge relatively small percentage of apps ," and Intel Network Outage in Los Angeles believes its investment should shift in that direction. September 26, 2011 But, he added, "shifting to HTML5 doesn't just mean slapping a web runtime on an existing Linux, even AT&T Mobility subscribers in Los Angeles can now one aimed at mobile, as MeeGo has been." text and make calls again on their mobile devices after technicians repaired a widespread network outage that affected millions of people. Sousou said that emphasizing HTML5 means APIs need to evolve with platform technology and by market segment, which a new platform could more AT&T spokesperson Meredith Red said late yesterday easily provide. that a hardware failure led to network issues with about 900 cellular towers across LA. Tizen will reside within the Linux Foundation, be governed by a Technical Steering Group, will be The service problems began at about 3.00 P.M. developed openly, and will support tablets, notebooks, Saturday and contributed to an evening of missed, handsets, smart TVs, and in-vehicle infotainment dropped and failed calls. Service was fully restored systems. early Sunday morning, local time. On the new Tizen.org website, a welcoming Red says it's unclear how many wireless subscribers statement said that Tizen APIs will cover various were affected, but conservative estimates are in the platform capabilities, including messaging, multimedia, millions. -
Mobile Gaming Apps Report UA Trends & Benchmarks
2020 Mobile Shopping Apps Report 2 0 2 0 Mobile Gaming Apps Report UA Trends & Benchmarks With retention data from Table of Contents 1 Introduction ..……………………………..…………..……………………………………..…………….. 3 2 Highlights ….………..……….……..…………………………………..…………………………………... 5 3 Methodology ….……….…………………………….………..…………………………………….…….. 6 4 Global Trends & Benchmarks …….…………………………..…………………………..……... 9 5 Casual Gaming Apps ……………….…………………………......….……………………….…….. 22 6 Hyper Casual Gaming Apps …..…..………………..……...………………………………..…... 29 7 Midcore, Hardcore & Strategy Gaming Apps .....……………………………………….. 36 8 Social Casino Gaming Apps ...…………………………………………...……………………….. 45 9 Country Deep Dives ……..…………………………………………………...……………………….. 52 2 Introduction In 2020, mobile gaming apps rule the world, fueled by record levels of app downloads and consumer spend. Games research firm Newzoo reckons roughly one-third of the planet’s population – that’s 2.6 billion people – will play mobile games this year. That number is projected to grow to 2.7 billion by 2021. Many are gaming fans, and many more are part of a new and captive audience forced by global events to practice social distancing and use their downtime to seek digital distractions. The outcome is a "bonanza" for gaming apps, an industry sure to experience a windfall of profits despite the tailwinds of a potential global recession. Overall, mobile gaming revenues are now set to top $100 billion this year, according to the latest data from app market intelligence provider App Annie and global research firm IDC. In total, the research concludes, mobile game spending will grow to more than 2.8x over desktop gaming and 3.1x more than home game consoles. ● Mobile gaming is the fastest growing segment and will account for 48% of all gaming revenues in 2020, up 13% from the previous year, thanks to blockbuster hits, including Fortnite, League of Legends and Pokémon Go. -

Mobile Privacy Disclosures: Building Trust Through Transparency
# Mobile Privacy Disclosures Building Trust Through Transparency FTC Staff Report | February 2013 This report is available online at www.ftc.gov/os/2013/02/130201mobileprivacyreport.pdf. The online version of this report contains live hyperlinks. Contents Executive Summary . i Mobile Privacy Disclosures: Building Trust Through Transparency . 1 I. Benefits and Risks of Mobile Technologies . 2 II. FTC’s Prior Work . 4 A. Efforts to Address Mobile Privacy . 4 1. Privacy Report . 5 2 . Kids App Reports . 7 B . General Research on Disclosures . 8 III . Common Themes From Panel Participants and Commenters . 9 IV. Post-Workshop Developments . 12 V . Recommendations . 13 A . Platforms . 14 1 . Platform Disclosures About Information Apps are Accessing from the Application Programming Interface (API) . 15. i . Just-in-Time Disclosures . 15 ii. Privacy Dashboard . 16 iii . Icons . 17 2. Platform Oversight of Apps . 18 3. Transparency About the App Review Process . 20 4. DNT for Mobile . 20 B. App Developers . 22 C. Recommendations for Advertising Networks and Other Third Parties . 24 D . Recommendations for App Trade Associations . 25 VI . Conclusion . 28 FTC Staff Report Executive Summary Mobile technology has come a long way in the last quarter century. In the 1980s, mobile cellular devices weighed over two pounds, were about the size of a brick, and cost close to $1,000. And they could be used for one thing: phone calls. Fast forward to 2012: In the fourth quarter of 2012, consumers worldwide bought approximately 217 million smartphones, which weigh about four ounces and fit in the palm of the hand. Consumers derive enormous benefits from these devices, which are used to make audio and video phone calls, buy movie tickets, check traffic on the regular commute, browse a digital library while waiting for an appointment, and connect with friends for spontaneous get-togethers. -

Mobile App Installation and Login Instructions
Mobile App Installation and Login Instructions Our mobile app is a convenient and secure way to manage your account on the go. It can be used to file claims, upload receipts, check your balance(s), view account activity, access your message center and more! It is compatible with Android and Apple devices. Installation: There are a few different ways to download and install the mobile app. You can do so by following any of the bullet points below: Get the Apple app by clicking here or get the Android app by clicking here. The participant portal contains a direct link to the mobile apps as well. After entering your account, hover your mouse over the PROFILE tab and click the Mobile Access link that populates to find a direct link to each app. Search for “Discovery Benefits” in the Apple App or Google Play store on your device and install the “Discovery Benefits Mobile” app. The app icon will appear as: Logging In: 1. Launch the Discovery Benefits Mobile app on your device. 2. You will be prompted to enter your username and password. Due to additional features on your account, an alternate username and password is needed to log in to your mobile app. Your username and password will be the first initial of your first name (lower case), your full last name (lower case), date of birth (including zeros), and the last four digits of your social security number. o For example, an individual with the following information would use “jdoe010119901234” as their username and password: . First Name: John . -

Mobile Web Apps: the Best Option for Business? a Whitepaper from Mrc
Mobile web apps: The best option for business? A whitepaper from mrc Introduction Mobile apps have finally reached the point where businesses can no longer afford to ignore them. Recent surveys and studies all point to the same conclusion: This is the year of the mobile business app. This is the year that businesses finally accept that mobile is not only here to stay, it also offers very compelling benefits. What benefits do mobile apps provide? They let you operate anytime and anywhere, bringing productivity beyond the confines of the office. Salespeople have access to real-time product data. Customers have another way to interact with your business, or even make purchases. The list goes on, but the bottom line is this: More and more companies are finally realizing how important mobile apps could be to their business. However, businesses trying to build mobile apps are running into a problem: The mobile platform landscape is extremely fragmented. Right now, there are 4 major smartphone platforms: Android, iOS, RIM, and Windows Phone 7. The tablet landscape is a bit more complicated. Android and iOS are currently the big players, but RIM has a small presence as well. Amazon’s Kindle Fire runs a version of the Android OS, but is so heavily modified that it requires its own App Store. To further complicate matters, Microsoft’s Windows 8 OS should find its way onto tablets in the near future. The problem: Which platform should your company use? At this moment in time, the answer seems clear: Android and iOS are the big players. -

Browser App Approach: Can It Be an Answer to the Challenges in Cross-Platform App Development?
Volume 16, 2017 BROWSER APP APPROACH: CAN IT BE AN ANSWER TO THE CHALLENGES IN CROSS-PLATFORM APP DEVELOPMENT? Minh Huynh* Southeastern Louisiana University, [email protected] Hammond, LA USA Prashant Ghimire Southeastern Louisiana University, [email protected] Hammond, LA USA *Corresponding Author ABSTRACT Aim/Purpose As smartphones proliferate, many different platforms begin to emerge. The challenge to developers as well as IS educators and students is how to learn the skills to design and develop apps to run on cross-platforms. Background For developers, the purpose of this paper is to describe an alternative to the complex native app development. For IS educators and students, the paper pro- vides a feasible way to learn and develop fully functional mobile apps without technical burdens. Methodology The methods used in the development of browser-based apps is prototyping. Our proposed approach is browser-based, supports cross-platforms, uses open- source standards, and takes advantage of “write-once-and-run-anywhere” (WORA) concept. Contribution The paper illustrates the application of the browser-based approach to create a series of browser apps without high learning curve. Findings The results show the potentials for using browser app approach to teach as well as to create new apps. Recommendations Our proposed browser app development approach and example would be use- for Practitioners ful to mobile app developers/IS educators and non-technical students because the source code as well as documentations in this project are available for down- loading. Future Research For further work, we discuss the use of hybrid development framework to en- hance browser apps.