Spring 2014 • Vol
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Base Performance for Beegfs with Data Protection
BeeGFS Data Integrity Improvements without impacting Performance Presenter: Dr. M. K. Jibbe Technical Director , NetApp ESG Presenter: Joey Parnell 1 SW2019 StorageArchitect, Developer Conference. NetApp © 2019 NetApp ESG Inc. NetApp Proprietary All Rights Reserved. Current Problem • Lustre has been a common choice in the HPC market for years but the acquisition of the Lustre intellectual property by storage provider in 2018 has created a challenge for users that want to avoid vendor lock-in. • Parallel file system needs are expanding beyond HPC, but most lack enterprise reliability • Any BeeGFS configuration does Lack Data protection at different locations: • Storage Client and servers do not have cache protection in the event of kernel panics, software crashes or power loss. Potential issues are: • Data cached in the BeeGFS client itself • Data cached at the underlying filesystem layer in the storage server (XFS, ZFS, ext4, etc.) • Data cached by the OS kernel itself underneath the filesystem in the storage server Goal of the Team (Remove Competitor and Expand Market Reach of BeeGFS) Parallel File system Improve solution resiliency to ensure data integrity by ML BeeGFS Swim lane identifying potential component faults that could lead to BeeGFS IB and FC data loss and changing system design to handle the fault Address known Market without any data integrity challenges. Opportunity Simple solution and support 2 2 2019 Storage Developer Conference. © 2019 NetApp Inc. NetApp Proprietary All Rights Reserved. Data Integrity & Availability expectations in HPC (Provide Enterprise Reliability with E-series Storage – BeeGFS) However, . The market we serve goes beyond the HPC scratch file system use cases . -

Data Integration and Analysis 10 Distributed Data Storage
1 SCIENCE PASSION TECHNOLOGY Data Integration and Analysis 10 Distributed Data Storage Matthias Boehm Graz University of Technology, Austria Computer Science and Biomedical Engineering Institute of Interactive Systems and Data Science BMK endowed chair for Data Management Last update: Dec 11, 2020 2 Announcements/Org . #1 Video Recording . Link in TeachCenter & TUbe (lectures will be public) . Optional attendance (independent of COVID) . #2 COVID‐19 Restrictions (HS i5) . Corona Traffic Light: RED ORANGE (Dec 07) . Webex lectures revaluated over holidays . #3 Projects and Exercises . 34x SystemDS projects, 11x exercise projects . Final kickoff discussions last week . #4 Course Evaluation . Evaluation period: Dec 15 – Jan 31 . Exam date: TBD, but likely end of January 706.520 Data Integration and Large‐Scale Analysis – 10 Distributed Data Storage Matthias Boehm, Graz University of Technology, WS 2020/21 3 Course Outline Part B: Large‐Scale Data Management and Analysis 12 Distributed Stream 13 Distributed Machine Processing [Jan 15] Learning Systems [Jan 22] 11 Distributed Data‐Parallel Computation [Jan 08] Compute/ Storage 10 Distributed Data Storage [Dec 11] 09 Cloud Resource Management and Scheduling [Dec 04] Infra 08 Cloud Computing Fundamentals [Nov 27] 706.520 Data Integration and Large‐Scale Analysis – 10 Distributed Data Storage Matthias Boehm, Graz University of Technology, WS 2020/21 4 Agenda . Motivation and Terminology . Object Stores and Distributed File Systems . Key‐Value Stores and Cloud DBMS 706.520 Data Integration and Large‐Scale Analysis – 10 Distributed Data Storage Matthias Boehm, Graz University of Technology, WS 2020/21 5 Motivation and Terminology 706.520 Data Integration and Large‐Scale Analysis – 10 Distributed Data Storage Matthias Boehm, Graz University of Technology, WS 2020/21 Motivation and Terminology 6 Overview Distributed Data Storage Global . -

Globalfs: a Strongly Consistent Multi-Site File System
GlobalFS: A Strongly Consistent Multi-Site File System Leandro Pacheco Raluca Halalai Valerio Schiavoni University of Lugano University of Neuchatelˆ University of Neuchatelˆ Fernando Pedone Etienne Riviere` Pascal Felber University of Lugano University of Neuchatelˆ University of Neuchatelˆ Abstract consistency, availability, and tolerance to partitions. Our goal is to ensure strongly consistent file system operations This paper introduces GlobalFS, a POSIX-compliant despite node failures, at the price of possibly reduced geographically distributed file system. GlobalFS builds availability in the event of a network partition. Weak on two fundamental building blocks, an atomic multicast consistency is suitable for domain-specific applications group communication abstraction and multiple instances of where programmers can anticipate and provide resolution a single-site data store. We define four execution modes and methods for conflicts, or work with last-writer-wins show how all file system operations can be implemented resolution methods. Our rationale is that for general-purpose with these modes while ensuring strong consistency and services such as a file system, strong consistency is more tolerating failures. We describe the GlobalFS prototype in appropriate as it is both more intuitive for the users and detail and report on an extensive performance assessment. does not require human intervention in case of conflicts. We have deployed GlobalFS across all EC2 regions and Strong consistency requires ordering commands across show that the system scales geographically, providing replicas, which needs coordination among nodes at performance comparable to other state-of-the-art distributed geographically distributed sites (i.e., regions). Designing file systems for local commands and allowing for strongly strongly consistent distributed systems that provide good consistent operations over the whole system. -

Towards Transparent Data Access with Context Awareness
Computer Science • 19(2) 2018 https://doi.org/10.7494/csci.2018.19.2.2844 Micha lWrzeszcz Renata G. S lota Jacek Kitowski TOWARDS TRANSPARENT DATA ACCESS WITH CONTEXT AWARENESS Abstract Open-data research is an important factor accelerating the production and analysis of scientific results as well as worldwide collaboration; still, very little dataEarly is being shared at scale. The aim of this bird article is to analyze existing data-access solutions along with their usage limitations. After analyzing the existing solutions and data-access stakeholder needs, the authors propose their own vision of a data-access model. Keywords distributed, transparent data access, distributed data storage, context awareness Citation Computer Science 19(2) 2018: 201{221 201 202 Micha Wrzeszcz, Jacek Kitowski, Renata S lota 1. Introduction Data access and management can be analyzed on several levels; from personal data to globally distributed shared data with different problems to be overcome by data access and management tools. The simplest case is access to local data; i.e., data stored on direct attached storage (DAS), where the focus is on providing the device drivers and solutions that use the hardware optimally. The next level is to provide data access for a group of users working for a single organization; e.g., provision of network attached storage (NAS). The problems en- countered in this case pertain to possible network failures, higher latencies [36], or the simultaneous work of many users influencing the quality of service [48, 59]. The balance of use of available storage systems to maintain QoS and cost effectiveness in an organization while request scheduling and resource allocation is also expected [28,56]. -

The Leading Parallel Cluster File System, Developed with a St Rong Focus on Perf Orm Ance and Designed for Very Ea Sy Inst All Ati on and Management
The Lead ing Para llel Clus ter File Syste m ww w.thinkpa rq.com ww w.beegfs.io UT BEEGFS ABO UT BEEGFS Wh at is Bee GFS System Archit ectu re BeeGFS (formerly FhGFS) is the leading parallel cluster file system, developed with a st rong focus on perf orm ance and designed for very ea sy inst all ati on and management. If I/O intensive workloads a re your p roblem, BeeGFS is the solution. Wh y use BeeGFS BeeGFS tr ansparentl y sp reads user data ac ross multiple servers. By inc reasing the number of servers and disks in the system, you can simply scale perf ormance and capacity of the file system to the level that you need, seamlessly f rom small clusters up to enterprise-class systems with thousands of nodes. Get The Most Out Of Your Data The flexibility, robustness, and outstanding performance of BeeGFS help our customers a round the globe to increa se prod uctivit y by delivering results faster and by enabli ng new data anal ysis met hod s that we re not possible without the advantages of BeeGFS. ASP ECTS KEY ASP ECTS Ma xim um Scala bili ty Ma xim um Flexibi lit y BeeGFS offers maximum performance and scalability on various BeeGFS supports a wide range of Linu x dist ribu ti on s such levels. It supports dist ribu te d fi le con te nts with flexible as RHEL/Fedora, SLES/OpenSuse or Debian/Ubuntu as well as a striping ac ross storage servers on a pe r-file or pe r-di rectory basis wide range of Linux ke rnels f rom ancient 2.6.18 up to the as well as dist ribu te d me tadat a. -

Maximizing the Performance of Scientific Data Transfer By
Maximizing the Performance of Scientific Data Transfer by Optimizing the Interface Between Parallel File Systems and Advanced Research Networks Nicholas Millsa,∗, F. Alex Feltusb, Walter B. Ligon IIIa aHolcombe Department of Electrical and Computer Engineering, Clemson University, Clemson, SC bDepartment of Genetics and Biochemistry, Clemson University, Clemson, SC Abstract The large amount of time spent transferring experimental data in fields such as genomics is hampering the ability of scientists to generate new knowledge. Often, computer hardware is capable of faster transfers but sub-optimal transfer software and configurations are limiting performance. This work seeks to serve as a guide to identifying the optimal configuration for performing genomics data transfers. A wide variety of tests narrow in on the optimal data transfer parameters for parallel data streaming across Internet2 and between two CloudLab clusters loading real genomics data onto a parallel file system. The best throughput was found to occur with a configuration using GridFTP with at least 5 parallel TCP streams with a 16 MiB TCP socket buffer size to transfer to/from 4{8 BeeGFS parallel file system nodes connected by InfiniBand. Keywords: Software Defined Networking, High Throughput Computing, DNA sequence, Parallel Data Transfer, Parallel File System, Data Intensive Science 1. Introduction of over 2,500 human genomes from 26 populations have been determined (The 1000 Genomes Project [3]); genome Solving scientific problems on a high-performance com- sequences have been produced for 3,000 rice varieties from puting (HPC) cluster will happen faster by taking full ad- 89 countries (The 3000 Rice Genomes Project [4]). These vantage of specialized infrastructure such as parallel file raw datasets are but a few examples that aggregate into systems and advanced software-defined networks. -

Understanding and Finding Crash-Consistency Bugs in Parallel File Systems Jinghan Sun, Chen Wang, Jian Huang, and Marc Snir University of Illinois at Urbana-Champaign
Understanding and Finding Crash-Consistency Bugs in Parallel File Systems Jinghan Sun, Chen Wang, Jian Huang, and Marc Snir University of Illinois at Urbana-Champaign Abstract directly applied to PFSes, due to the unique architecture of Parallel file systems (PFSes) and parallel I/O libraries have PFS, its workload characteristics, and the increased complex- been the backbone of high-performance computing (HPC) ity of HPC I/O stack. Specifically, files can be shared by all infrastructures for decades. However, their crash consistency processes in a parallel job, and I/O is performed through a bugs have not been extensively studied, and the corresponding variety of parallel I/O libraries which may have their own bug-finding or testing tools are lacking. In this paper, we first crash consistency implementation. A proper attribution of conduct a thorough bug study on the popular PFSes, such as application-level bugs to one layer or another in the I/O stack BeeGFS and OrangeFS, with a cross-stack approach that cov- depends on the "contract" between each layer. ers HPC I/O library, PFS, and interactions with local file sys- To further understand crash consistency bugs in parallel I/O, tems. The study results drive our design of a scalable testing we conduct a study with popular PFSes, including BeeGFS framework, named PFSCHECK. PFSCHECK is easy to use and OrangeFS. We manually create seven typical I/O work- with low performance overhead, as it can automatically gener- loads with the parallel I/O library HDF5 [5], and investigate ate test cases for triggering potential crash-consistency bugs, crash-consistency bugs across the I/O stack. -

Using On-Demand File Systems in HPC Environments
Using On-Demand File Systems in HPC Environments Mehmet Soysal, Marco Berghoff, Thorsten Zirwes, Marc-André Vef, Sebastian Oeste, André Brinkmann, Wolfgang E. Nagel, and Achim Streit Steinbuch Centre for Computing (SCC) / Scientific Computing and Simulation (SCS) KIT – The Research University in the Helmholtz Association www.kit.edu Overview Motivation Approach Related Work Use Cases and Results Remarks and Observations Conclusion & Future work 2/18 Wed, July 17, 2019 Mehmet Soysal – Using On-Demand File Systems in HPC Environments Steinbuch Centre for Computing (SCC) Motivation The I/O Subsystem (parallel FS) is a bottleneck in HPC Systems Bandwidth, metadata or latency Shared medium Applications interfere with each other New storage technologies (SSD, NVMe, NVRAM) 3/18 Wed, July 17, 2019 Mehmet Soysal – Using On-Demand File Systems in HPC Environments Steinbuch Centre for Computing (SCC) Motivation Proposed Solution Bring data closer to compute nodes On-demand file system (ODFS) node-local storage Tailor private ODFS Advantages Dedicated bandwidth / IOPS Independent to global file system Low latency due to SSD / NVMe / NVRAM No code changes needed to application 4/18 Wed, July 17, 2019 Mehmet Soysal – Using On-Demand File Systems in HPC Environments Steinbuch Centre for Computing (SCC) HPC: current file system usage App/Job 1 App/Job 2 Node 1 Node 2 Node 3 Node 4 Node 5 Node 6 Global Parallel File System $HOME / $WORK / Scratch 5/18 Wed, July 17, 2019 Mehmet Soysal – Using On-Demand File Systems in HPC Environments Steinbuch Centre for -

Performance and Scalability of a Sensor Data Storage Framework
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Aaltodoc Publication Archive Aalto University School of Science Degree Programme in Computer Science and Engineering Paul Tötterman Performance and Scalability of a Sensor Data Storage Framework Master’s Thesis Helsinki, March 10, 2015 Supervisor: Associate Professor Keijo Heljanko Advisor: Lasse Rasinen M.Sc. (Tech.) Aalto University School of Science ABSTRACT OF Degree Programme in Computer Science and Engineering MASTER’S THESIS Author: Paul Tötterman Title: Performance and Scalability of a Sensor Data Storage Framework Date: March 10, 2015 Pages: 67 Major: Software Technology Code: T-110 Supervisor: Associate Professor Keijo Heljanko Advisor: Lasse Rasinen M.Sc. (Tech.) Modern artificial intelligence and machine learning applications build on analysis and training using large datasets. New research and development does not always start with existing big datasets, but accumulate data over time. The same storage solution does not necessarily cover the scale during the lifetime of the research, especially if scaling up from using common workgroup storage technologies. The storage infrastructure at ZenRobotics has grown using standard workgroup technologies. The current approach is starting to show its limits, while the storage growth is predicted to continue and accelerate. Successful capacity planning and expansion requires a better understanding of the patterns of the use of storage and its growth. We have examined the current storage architecture and stored data from different perspectives in order to gain a better understanding of the situation. By performing a number of experiments we determine key properties of the employed technologies. The combination of these factors allows us to make informed decisions about future storage solutions. -

Towards Transparent Data Access with Context Awareness
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Computer Science Journal (AGH University of Science and... Computer Science • 19(2) 2018 https://doi.org/10.7494/csci.2018.19.2.2844 Michał Wrzeszcz Renata G. Słota Jacek Kitowski TOWARDS TRANSPARENT DATA ACCESS WITH CONTEXT AWARENESS Abstract Open-data research is an important factor accelerating the production and analysis of scientific results as well as worldwide collaboration; still, very little data is being shared at scale. The aim of this article is to analyze existing data-access solutions along with their usage limitations. After analyzing the existing solutions and data-access stakeholder needs, the authors propose their own vision of a data-access model. Keywords distributed, transparent data access, distributed data storage, context awareness Citation Computer Science 19(2) 2018: 201–221 201 202 Michał Wrzeszcz, Renata G. Słota, Jacek Kitowski 1. Introduction Data access and management can be analyzed on several levels; from personal data to globally distributed shared data with different problems to be overcome by data access and management tools. The simplest case is access to local data; i.e., data stored on direct attached storage (DAS), where the focus is on providing the device drivers and solutions that use the hardware optimally. The next level is to provide data access for a group of users working for a single organization; e.g., provision of network attached storage (NAS). The problems en- countered in this case pertain to possible network failures, higher latencies [23], or the simultaneous work of many users influencing the quality of service [38, 53]. -

Beegfs Unofficial Documentation
BeeGFS unofficial documentation Sep 24, 2019 Architecture 1 General Architecture 3 1.1 The Management Service........................................5 1.2 The Metadata Service..........................................5 1.3 The Storage Service...........................................5 1.4 The Client Service............................................7 1.5 Admon: Administration and Monitoring System............................7 2 Built-in Replication: Buddy Mirroring9 2.1 Storage Service Buddy Mirroring.................................... 10 2.2 Buddy Groups.............................................. 10 2.3 Metadata Service Buddy Mirroring................................... 11 2.4 Define Stripe Pattern........................................... 11 2.5 Enabling and disabling Mirroring.................................... 12 2.6 Restoring Metadata and Storage Target Data after Failures....................... 13 2.7 Caveats of Storage Mirroring...................................... 14 3 Storage Pools 17 4 Cloud Integration 19 5 Striping 21 5.1 Buddy Mirroring............................................. 21 5.2 Impact on network communication................................... 22 6 Client Tuning 23 6.1 Parallel Network Requests........................................ 23 6.2 Remote fsync............................................... 23 6.3 Disable locate/mlocate/updatedb..................................... 24 7 Getting started and typical Configurations 25 8 Installation and Setup 27 8.1 General Notes............................................. -
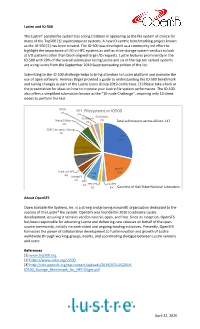
Filesystems in IO500 3% Gridscaler Datawarp 2% Wekaio Matrix 2% Total Submissions Across All Lists: 147 5% SUSE Enterprise Storage 1% Lustre 29%
Lustre and IO-500 The Lustre® parallel file system has a long tradition in appearing as the file system of choice for many of the Top500 [1] supercomputer systems. A new IO-centric benchmarking project known as the IO-500 [2] has been created. The IO-500 was developed as a community led effort to highlight the importance of I/O in HPC systems as well as drive storage system vendors to look at I/O patterns other than block-aligned large I/O requests. Lustre features prominently in the IO-500 with 29% of the overall submission listing Lustre and six of the top ten ranked systems are using Lustre from the September 2019 Supercomputing edition of the list. Submitting to the IO-500 challenge helps to bring attention to Lustre platform and promote the use of open software. Andreas Dilger provided a guide to understanding the IO-500 benchmark and tuning changes as part of the Lustre Users Group 2019 conference. [3] Please take a look at the presentation for ideas on how to improve your Lustre file system performance. The IO-500 also offers a simplified submission known as the “10-node Challenge”, requiring only 10 client nodes to perform the test. DAOS GPFS 1% Filesystems in IO500 3% GRIDScaler DataWarp 2% WekaIO Matrix 2% Total submissions across all lists: 147 5% SUSE Enterprise Storage 1% Lustre 29% Spectrum Scale 12% Scale-out NAS 7% BeeGFS Scale out NFS IME 20% 4% OrangeFS 7% 1% NFS 1% HPE XFS CephFS 2% 3% Courtesy of Oak Ridge National Laboratory About OpenSFS Open Scalable File Systems, Inc.