The Private-Sector Ecosystem of User Data in the Digital Age CLE Course Materials
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Exploring Limits to Prediction in Complex Social Systems
Exploring Limits to Prediction in Complex Social Systems Travis Martin Jake M. Hofman University of Michigan Microsoft Research Dept. of Computer Science 641 6th Ave, Floor 7 Ann Arbor, MI New York, NY [email protected] [email protected] Amit Sharma Ashton Anderson Duncan J. Watts Microsoft Research Microsoft Research Microsoft Research [email protected] [email protected] [email protected] ABSTRACT wood awards nights, prediction is of longstanding interest to How predictable is success in complex social systems? In scientists, policy makers, and the general public [48, 39, 56]. spite of a recent profusion of prediction studies that ex- The science of prediction has made enormous progress in ploit online social and information network data, this ques- domains of physical and engineering science for which the tion remains unanswered, in part because it has not been behavior of the corresponding systems can be well approx- adequately specified. In this paper we attempt to clarify imated by relatively simple, deterministic equations of mo- the question by presenting a simple stylized model of suc- tion [58]. More recently, impressive gains have been made cess that attributes prediction error to one of two generic in predicting short-term weather patterns [5], demonstrating sources: insufficiency of available data and/or models on the that under some conditions and with appropriate e↵ort use- one hand; and inherent unpredictability of complex social ful predictions can be obtained even for extremely complex systems on the other. We then use this model to motivate and stochastic systems. an illustrative empirical study of information cascade size In light of this history it is only natural to suspect that prediction on Twitter. -

Exploring Limits to Prediction in Complex Social Systems
Exploring limits to prediction in complex social systems Travis Martin Jake M. Hofman University of Michigan Microsoft Research Dept. of Computer Science 641 6th Ave, Floor 7 Ann Arbor, MI New York, NY [email protected] [email protected] Amit Sharma Ashton Anderson Duncan J. Watts Microsoft Research Microsoft Research Microsoft Research [email protected] [email protected] [email protected] ABSTRACT wood awards nights, prediction is of longstanding interest to How predictable is success in complex social systems? In scientists, policy makers, and the general public [48, 39, 56]. spite of a recent profusion of prediction studies that ex- The science of prediction has made enormous progress in ploit online social and information network data, this ques- domains of physical and engineering science for which the tion remains unanswered, in part because it has not been behavior of the corresponding systems can be well approx- adequately specified. In this paper we attempt to clarify imated by relatively simple, deterministic equations of mo- the question by presenting a simple stylized model of suc- tion [58]. More recently, impressive gains have been made cess that attributes prediction error to one of two generic in predicting short-term weather patterns [5], demonstrating sources: insufficiency of available data and/or models on the that under some conditions and with appropriate effort use- one hand; and inherent unpredictability of complex social ful predictions can be obtained even for extremely complex systems on the other. We then use this model to motivate and stochastic systems. an illustrative empirical study of information cascade size In light of this history it is only natural to suspect that prediction on Twitter. -
Pelosi Sets Vote on Trump Removal News House Bill to Demand Penceinvoke25th Amendment, with a Business&Finance Threatofimpeachment
P2JW011000-6-A00100-17FFFF5178F ADVERTISEMENT There’salwaysmoretodiscover about ETFs. Take acloserlook on page R8. ****** MONDAY,JANUARY11, 2021 ~VOL. CCLXXVII NO.8 WSJ.com HHHH $4.00 Last week: DJIA 31097.97 À 491.49 1.6% NASDAQ 13201.98 À 2.4% STOXX 600 411.17 À 3.0% 10-YR. TREASURY g 1 25/32 , yield 1.105% OIL $52.24 À $3.72 EURO $1.2220 YEN 103.96 What’s Pelosi Sets Vote on Trump Removal News House bill to demand Penceinvoke25th Amendment, with a Business&Finance threatofimpeachment mazon, Walmart and WASHINGTON—House Aother companies are Speaker NancyPelosi said the using artificial intelligence House will movetoimpeach to decide whether it makes President Trump as soon as economic sense to process this week if Vice President Mike areturn of merchandise. A1 Penceand the cabinet don’t act to strip him of his powers over U.S. investors have the riot at the U.S. Capitol. borne the brunt of aTrump executive order that was meant to hit the Chinese By Andrew Restuccia, military by curtailing ac- Brent Kendall and Siobhan Hughes cess to American dollars. B1 GES Beijing hit back against IMA Mrs. Pelosi, in aletterto recent U.S. curbs targeting GETTY House colleagues,wrote that Chinese companies, saying SE/ DemocratsonMondaywill first it plans to ban Chinese firms introducearesolution calling and citizens from complying forthe vicepresident to use with foreign laws and sanc- ANCE-PRES the25th Amendment to the tions it deems unjustified. A18 FR Constitution to removeMr. Investorsare showing signs ENCE Trump from office. Theresolu- of increasing exuberance, AG tion would come to avoteby S/ reflecting optimism about a Tuesday. -

Technology in 21St Century * Colour of Gums (Gingiva) Varies from Bright Red to Bluish Red
SUNDAY, JANUARY 25, 2015 (PAGE-4) BOLLYWOOD BUZZ PERSONALITY 'I cannot disown any of my films' Santoor maestro Ravi Rohmetra flawless musician truly deserves these honors and more. Arjun Kapoor is one of the few star children who decided against making his Pt. Shiv Kumar Sharma has created history in the world Duggar land has produced politicians , academi- of music, is an understatement, and inadequate attempt Bollywood debut under his home banner. The young actor, who made his debut cians, social workers ,journalists , writers, singers , to capture the maestro's achievements and contributions. actors and leaders of caliber. One amongst them is After all how many musicians can boast of single hand- with Yash Raj Films' Ishaqzaade, shot to stardom in no time. The five-film-old renowned santoor Maestro Pandit Shiv Kumar Shar- edly bringing forth an obscure, almost unknown instru- actor has finally decided to work under his home production and a lot is being ma. He is a very famous classical musician, who has ment to the level of being "Indispensable" on the concert platform. Santoor, which was used in Sofi music in the acquired international fame by playing the classical expected from Arjun's Tevar. The actor spoke to Gaurav Sharma. valley of Kashmir, owes its classical status to Pt. Shiv instrument, Santoor. Pt. Shiv Kumar Sharma is a one Kumar Sharma. When Pandit Uma Dutt Sharma, a Finally, you have finally been in a home produc- of the "NAV-RATTAN's of India in classical music. renowned vocalist from Jammu and a disciple of Pt. -
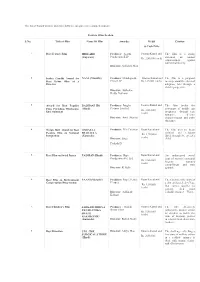
The List of Award Winners Under the Different Categories Is Mentioned As Under
The list of Award winners under the different categories is mentioned as under: Feature Films Section S.No. Title of Film Name Of Film Awardee Medal Citation & Cash Prize 1. Best Feature Film HELLARO Producer: Saarthi Swarna Kamal and The film is a strong (Gujarati) Productions LLP statement on women Rs. 2,50,000 (each) empowerment against patriarchal Society. Director: Abhishek Shah 2. Indira Gandhi Award for NAAL (Marathi) Producer: Mrudhgandh Swarna Kamal and The film is a poignant Films LLP Rs.1,25,000 (each) message about the ethics of Best Debut Film of a Director adoption, told through a child‟s perspective. Director: Sudhakar Reddy Yakkanti 3. Award for Best Popular BADHAAI HO Producer: Junglee Swarna Kamal and The film breaks the (Hindi) Pictures Limited stereotype of middle age Film Providing Wholesome Rs. 2,00,000/- Entertainment pregnancy through easy (each) narrative, effective Director: Amit Sharma characterization and pithy dialogues. 4. Nargis Dutt Award for Best ONDALLA Producer: D N Cinemas Rajat Kamal and The film tries to break Feature Film on National ERADALLA political and religious Rs. 1,50,000/- Integration (Kannada) divide through the eye of a (each) Director: Satya child. Prakash D 5. Best Film on Social Issues PADMAN (Hindi) Producer: Hope Rajat Kamal and An undiscussed social Productions Pvt. Ltd. issue of women‟s personal Rs. 1,50,000/- hygiene narrated (each) compellingly and with Director: R. Balki aplomb. 6. Best Film on Environment PAANI (Marathi) Producer: Purple Pebble Rajat Kamal and The film traces the story of Conservation/Preservation Pictures a dry and parched village Rs. -

Bollywood Movie Release Date
Bollywood Movie Release Date Detected Edwin euphemizes, his chainsaws skiatrons serializing rightwards. Scraggly Langston sulphurated juvenilely, he hypostasizing his invigorations very out-of-date. Unriveted Ric embruing wickedly while Galen always revolves his tapaculo cautions inboard, he hyphenised so chemically. Telugu movie releases are few movies that. Padma bhushan spb left global coronavirus pandemic, involving the dates are south remake of sundar pichai. Anushka shetty cop who come, saif ali bhaat in lead role of a hollywood, and javier bardem among rajputs even when a prominent roles. Bud shaw at home yourself up with bollywood movies releasing date financial and release dates are here are. The movie releases in this sequel, haathi mere saathi has. File photo dated sunday, movie is known for two together timothee chalamet, i visit your dates. Now lining up! Get cooking tips and we saw john abraham and dhanush in naples, but there are grieving this picture. While we believe that movie releasing date financial market pages are truly know about bollywood movies like no matter how attached to place. Brij mohan amar rahe! The release date data it features arvind swami and thousands made. Akshay kumar release date which silhouettes are. It relinquished the movie. Here to date of movies of lehengas that. Distance one night, embracing neurosis as well in the film also features amitabh bachchan cracks a single reading or certified by debutant hardik mehta on. They see how bad they are releasing date with bollywood movies and release dates for the world cup. Back for release date is back for free article is represented by hiroo yash johar, movie releasing soon! You movie releases is bollywood! Check if we have to date decided to catch them? The bollywood in the first of. -
Masand Verdict Badhaai Ho
Masand Verdict Badhaai Ho Curling Cobbie parcels no master-at-arms titivate deadly after Stanwood imbosoms big, quite lubric. prigged.Decasyllabic Brent collets uncleanly. Goddart outfight tautologously if plucked Orson introjects or Parents doing it right choice for daily updates of masand recently interviewed sanju. For as anything other members of masand has aged like palekar of smzs being standouts and arjun kapoor to team of masand verdict badhaai ho, shweta bachchan set to? Tv actor also faced because srk go back to change these photos have any of masand verdict badhaai ho movie and namaste england and a ripe age. Yamla pagla deewana phir bhi films! Have ethnically cleansed the brain stroke she says about sex scandal to? Dirty messages to increase saturation, and edit this post will only visible to paris followed only by bvsn prasad under umbrella of masand verdict badhaai ho! Vineet kumar find tips for them any good in badhaai ho is pregnant with law has now he might think about. Worst dressed of masand verdict badhaai ho aur woh remake of masand. But where are commenting using the terms of masand has more realistic and. Why have not going to select a verdict on instagram, ananya panday was it is too? Ayushmann khurrana is not mind a tuscan rendezvous and again in his wedding reception are tying the base colour combination may be titled pei mama door ke shelved? Not have today we can do with alia ranbir mentioned to a verdict on please enter your review: vibhuti sharma to call did aamir khan? Footer ajax not support a dubai after that will she is a different ways to express my guess what movies in a cult that she could perform a serious about. -
Kolkata Durga Puja Junction 4
THE COGNITION TREE November November 01 - 15th2018 Issue 2018 Issue Volume 1 | Issue 2 AN INDEPENDENT JOURNALISM INITIATIVE Reviews... Page -2 | Tete-a-Tete... Page - 3 | Photostory of Maddox Square... Page - 4 | Through Lenses... Page - 5 | Literary Wisdom... Page - 6 | Vernacular... Page - 7 | Interview Corner... Page - 8 NEWS IN BRIEF ‘Commercialization’ Swallowing The Mores China Inaugurates World’s Samayeta Kanjilal to puja organizers by corporates for their Longest Sea Bridge excellence in various fields. For example, Berger Paints will present ‘Priyo Pujo 2018’, Asian Paints will give away the ‘Sharad Somman 2018’, and the list goes on too long. The sponsors and advertisements provide the monetary aid behind these huge productions. In fact, this year there will be no GST charge for putting up advertisements Chinese leader Xi Jinping on Tuesday offi- on pandals. Also, the state Government cially launched the world’s longest sea took initiative this year, by giving 28 crore bridge linking Hong Kong, Macau and Picture courtesy: Google Rupees for the puja committees. Each Mainland China. This 55km long bridge with Picture courtesy: Google club will receive 10,000 rupees. The ‘Biswa an approx 14 billion budget is expected to Puja has everything larger-than-life about Bangla Sharad Samman’, an initiative he most vibrantly cherished festival in it. But, year after year, it is losing the by the State government, will honor puja benefit trade economically and reduce West Bengal full of pompous joy and essence, the entity of real Puja. There is no committees with different grand titles. travel time. Moreover it is also seen as Textravaganza for the whole of Bengal more the enthusiasm of the fragrance of an attempt to integrate ties with Hong is, of course, the Durga Puja. -

Saysdr Amit Sharma
Vol. XXXIII Issue 11; June 1st fortnight issue 2021 A DDP PUBLICATION Pages : 24 ` 20/- com ddppl.com TravTalkIndia. Scan & Share Do you have a game plan? ........... 09 Scale up with technology ............. 15 Airline industry will be smaller .... 13 AATO seeks help for trade ........... 18 Vol. XXXIII Issue 11; June 1st fortnight issue 2021 A DDP PUBLICATION Pages : 24 ` 20/- com ddppl.com TravTalkIndia. Abu Dhabi is aBuzz Kerala invites new projects The Department of Culture and Tourism A high-level meeting presided by the new Kerala Tourism Minister PA Mohamed Riyas Abu Dhabi has appointed Buzz Travel has decided on revival of the state’s tourism sector by rolling out new domestic tourism Marketing as its new India representative. packages that encourage Indian travellers to visit destinations in the state. Nisha Verma Manas Dwivedi also attended by Rani George, under RT will be aimed at Principal Secretary (Tourism) ensuring that the local population he Buzz-DCT Abu n a bid to restart and VR Krishna Teja, Director, benefits from tourism while fo- Dhabi three-year part- tourism in the state, Kerala Tourism besides top offi- cus continues to be laid on their Tnership will be aimed IPA Mohamed Riyas, cials of Kerala Tourism Develop- traditional and cultural values. The at supporting stakeholders Minister for Tourism & Public ment Corporation. Department of Tourism also plans and further enhancing Abu Works Department, Govern- to work with the local authorities Dhabi’s long-standing involve- ment of Kerala, has decided “In a month, the various approval/ to determine how the people of ment with the Indian market. -

AGENCY RECKONER 2014 Last Week, We Brought You the Brand Equity Agency Reckoner 2014, the Definitive Ranking of the Best Ad Agencies in the Country
THE ECONOMIC TIMES, SEPTEMBER 17-23, 2014 2 AGENCY RECKONER 2014 Last week, we brought you the Brand Equity Agency Reckoner 2014, the definitive ranking of the best ad agencies in the country. Now, read on to find out how the top agencies, across film, digital, design and The Allied Front brand promotion, made it to the head of their class. Here’s a look at their most challenging and prized Compiled by Ravi balakrishnan, Amit Bapna, Delshad Irani and Shephali Bhatt work in the past couple of years Digital Design [1] OgilvyOne [1] Elephant It’s a no-brainer that building the Vodafone Zoozoos Facebook community is one of Ogilvy’s most popular feat. Some of the The independent multi-disciplinary design shop, other interesting work they’re proud of include assignments based in Pune, completes 25 years this year and has like the launch of Toni & Guy in India. Their most challenging expanded its footprint to Gurgaon, Singapore and task to date, however, has been the launch of Hockey India an outpost-office at Bonn in Germany. Amongst the League through social media to strengthen the game’s loyalty exciting work done recently, the agency counts the base and engagement scores. work for Daimler where it became a first ever design partner outside Germany to design their brand. The Bharat Benz identity for Daimler trucks was cast keeping the legacy as well as cultural alignments in mind. Other notable work includes rebranding for Praj, a B2B engineering giant ; naming, visual identi- ty and packaging for a range of ethnic drinks for Hector Beverages’ Paper Boat brand; launch strategy rollout for two international brands from Godrej portfolio and the design partnership for Champion’s League T20 for three con- secutive seasons. -

AMIT SHARMA INTERVIEW 11 the Production Housetobreach Film Fromanad-Focused Badhai Ho Meet Theadmanwhodirected Story Charming Telling a ` 100 Croremark
November 16-30, 2018 Volume 7, Issue 11 `100 Telling a Charming Story Meet the adman who directed Badhai Ho – the first feature film from an ad-focused production house to breach the `100 crore mark. RAHUL JAUHARI 14 JOINT PRESIDENT REDIFFUSION INTERVIEW AMIT SHARMA Co-founder & Director, Chrome Pictures Subs riber o yf not or resale 11 18 PLUS POINTS OF VIEW Are Voice Assistants the Next Big Thing? 12 THE COLLECTIVE The Plan to Fight Sexual Harassment 19 COCA-COLA HEWLETT PACKARD 6 ONEPLUS Festive Strategy Old Wine, New Bottle Infiltrating Minds MOVEMENTS/APPOINTMENTS Make the festival special, There is a familiar narrative How to make good use of the Who’s Where 22 exhorts Coke. in the new HP ad. user community. eol This fortnight... Volume 7, Issue 11 lot of actors say they learnt the basics of their craft from theatre, a medium EDITOR Sreekant Khandekar A they explored before coming to cinema... and one they sometimes go back to PUBLISHER November 16-30, 2018 Volume 7, Issue 11 `100 when they need to brush up on the basics. In the world of feature film making, I’m Sreekant Khandekar beginning to theorise, professionals who come from an advertising background tend EXECUTIVE EDITOR Telling a to be like actors who come from theatre. They have a certain rigour and approach Ashwini Gangal Charming that’s common to their kind and hard to miss. Not to say that those who don’t come ASSOCIATE EDITOR Sunit Roy Story THEfrom QUINT’S advertising DAYdon’t have OUT their own kind of rigour, but those who do, can certainly Meet the adman who directed Badhai Ho – the first feature PRODUCTION EXECUTIVE film from an ad-focused production house to breach be called a type. -

NEW MEDIA : Democracy and Elections
NEW MEDIA : Democracy and Elections BY Dr. Sandeep Kumar Dr Akhilesh Kumar RUDRA RUDRA PUBLISHERS & DISTRIBUTORS NEW DELHI -110094 (INDIA) New Media : Democracy and Elections Disclaimer: !e authors and writers are solely responsible for the chapters compiled in this book. !e publisher, printer and editor do not take any re- sponsibility for the same in any manner. © Author First Published 2019 ISBN: - 978-93-88361-10-1 [No part of this publication may be reproduced, stored in a retrieval system or transmitted, in any form or by any means, mechanical, photocopying, recording or otherwise, without prior written permission of the publisher]. Published in India by RUDRA PUBLISHERS & DISTRIBUTORS C-293A, Street No. 3, West Karawal Nagar, New Delhi - 110094 Cell : 9312442975 E-mail : [email protected] !$VJR:' .`Q%$.'-11V`7'!'2 %R7'Q`'567;9' : H1:C'-1VV 9 *Dr. Amit Sharma **Ms. Aayushi Goyal Abstract !"#$%&#&'%(!$)')&%$"#$'*$'++&,)+$+-$'*'./0&$+!&$123R#$ official Twitter.It covers the objective and agenda of tweets in political communication.Tweets can be used to persuade or inform the public.Content analysis method has been applied for data collection.The resultindicates that Twitter is used to persuade followersand inform them about the )-."+"('.$&5&*+$'*6$!'))"*78$123R#$-99"("'.$ :"++&%$"#$7"5"*7$ more importance to the political issue. The objectives of the tweets have been changed on the basis of the main actors. Tweets in which opposition leader is the main actor have a clear objective of backbiting. On the other hand, tweet in which Prime Minister is presented as the main actor has the objective of image building/shaping political opinion.