Verteilte Systeme / Ubiquitous Computing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Astromist 2.2 User Guide
Astromist 2.2 User Guide Astromist 2.2 User Guide 1. Introduction.........................................................................................6 1.1. Objectives.................................................................................................................................. 6 1.2. Main features............................................................................................................................. 7 1.3. Limitations ................................................................................................................................. 9 1.3.1. Scope drives ................................................................................................................... 9 1.3.2. Photos............................................................................................................................. 9 2. Installation ........................................................................................10 2.1. Prerequisites ........................................................................................................................... 10 2.1.1. Operating system.......................................................................................................... 10 2.1.2. Hardware ...................................................................................................................... 10 2.1.3. Required “Plug-Ins”....................................................................................................... 10 2.2. Free and Registered -

1 Star Trac Pro Partner – Training Partner Operations Manual Table of Contents I. Introduction II. Selecting Workout Partner
Star Trac Pro Partner – Training Partner Operations Manual Table of Contents I. Introduction II. Selecting Workout Partner a. Creating a Custom Workout III. Creating a Pro or Elite Treadmill Custom Workout a. Naming Your Workout b. Entering Weight/Time c. Designing Your Incline Profile d. Designing Your Speed Profile IV. Creating a Pro Bike Custom Workout a. Naming Your Workout b. Entering Weight/Time c. Designing Your Resistance Profile V. Accessing a Custom Workout VI. Beaming a Custom Workout a. Beaming to a Pro or Elite Treadmill b. Beaming to a Pro Bike c. Beaming to a PDA Device VII. Editing a Custom Workout VIII. Deleting a Custom Workout IX. Reviewing a Completed Workout X. Collecting an Existing Workout from a Pro or Elite Treadmill or Pro Bike XI. Appendix A: List of PDAs Compatible with Pro Partner 1 I. Introduction Thank you for choosing Star Trac for your fitness needs. Are you ready to take your clients’ workout to a new level? The Star Trac Pro Partner software program will make your Palm-powered PDA (Personal Digital Assistant) an integral part of your personal training experience when using a Star Trac Pro or Elite Treadmill or Pro Bike. Personalized workouts and tracking client workout data are now all in the palm of your hand! In this manual you will learn how to use the Training Partner application to design custom workouts and track workout information for your clients for a more personal approach. It’s simple! Just follow the steps in this user manual and you’re one step closer to making your personal training more efficient. -
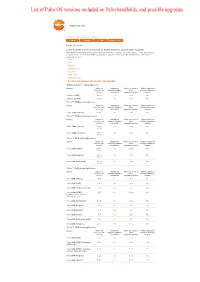
List of Palm OS Versions Included on Palm Handhelds, and Possible Upgrades
List of Palm OS versions included on Palm handhelds, and possible upgrades www.palm.com < Home < Support < Knowledge Library Article ID: 10714 List of Palm OS versions included on Palm handhelds, and possible upgrades Palm OS® is the operating system that drives Palm devices. In some cases, it may be possible to update your device with ROM upgrades or patches. Find your device below to see what's available for you: Centro Treo LifeDrive Tungsten, T|X Zire, Z22 Palm (older) Handspring Visor Questions & Answers about Palm OS upgrades Palm Centro™ smartphone Device Palm OS Handheld Palm OS version Palm Desktop & version (out- Upgrade/Update after HotSync Manager of-box) available? upgrade/update update Centro (AT&T) 5.4.9 No N/A No Centro (Sprint) 5.4.9 No N/A No Treo™ 755p smartphone Device Palm OS Handheld Palm OS version Palm Desktop & version (out- Upgrade/Update after HotSync Manager of-box) available? upgrade/update update Treo 755p (Sprint) 5.4.9 No N/A No Treo™ 700p smartphones Device Palm OS Handheld Palm OS version Palm Desktop & version (out- Upgrade/Update after HotSync Manager of-box) available? upgrade/update update Treo 700p (Sprint) Garnet Yes N/A No 5.4.9 Treo 700p (Verizon) Garnet No N/A No 5.4.9 Treo™ 680 smartphones Device Palm OS Handheld Palm OS version Palm Desktop & version (out- Upgrade/Update after HotSync Manager of-box) available? upgrade/update update Treo 680 (AT&T) Garnet Yes 5.4.9 No 5.4.9 Treo 680 (Rogers) Garnet No N/A No 5.4.9 Treo 680 (Unlocked) Garnet No N/A No 5.4.9 Treo™ 650 smartphones Device Palm OS -

Hart Pocket Configurator for Palm Organizer Features
HART POCKET CONFIGURATOR FOR PALM ORGANIZER The HPC301 Hart Pocket Configurator is a new HPC301- HART® Configurator Screen Configurator Software from Smar for HART® protocol Instruments and systems. This has been developed to work with a Palm Organizer. The configurator consists of HPC301 (the software), HPI311 (the interface) and acessories to configure and calibrate HART® equipment. This packageconfigures Series 301 products from Smar and many others wich have the HART® protocol and where a portable configurator is needed. It therefore can be used to configure field devices. Interface HPI311 V-HART® PalmVx Handheld FEATURES üThis configuration tool supports various commercial üIt can support various devices from different types of handheld based on Palm O.S. vendors. (The generic configuration tool üMuch faster than other handheld solutions. version is always available) üProduct User's Guide and Device Information üOnly one software application can configure could be provided online. (Online Help) various field devices. (No need datapacks or memory modules for every device type). üRechargeable battery. (The interface power üSynchronize data with the PC. Configuration supply can recharge both handheld and interface). files can be exchanged with PC applications. üEasy to upgrade on site. üOther useful programs could be installed in the handheld. (For example Unit Converter, History üEasy Interface Connection Reports, E-mail, etc.). üBattery Status Indicator üLight and slim. It really fits in a pocket. üStandard modem D11 smar ORDERING CODE DESCRIPTION CODE Description Palm-VX Palm Vx handheld Palm-IIIC Palm IIIc handheld HPI311-V HART Pocket Interface for Palm V handhelds (includes HPC301 software) HPI311-III HART Pocket Interface for Palm III handhelds (includes HPC301 software) D12 smar. -

Palm OS Cobalt 6.1 in February 2004 6.1 in February Cobalt Palm OS Release: Last 11.2 Ios Release: Latest
…… Lecture 11 Market Overview of Mobile Operating Systems and Security Aspects Mobile Business I (WS 2017/18) Prof. Dr. Kai Rannenberg . Deutsche Telekom Chair of Mobile Business & Multilateral Security . Johann Wolfgang Goethe University Frankfurt a. M. Overview …… . The market for mobile devices and mobile OS . Mobile OS unavailable to other device manufacturers . Overview . Palm OS . Apple iOS (Unix-based) . Manufacturer-independent mobile OS . Overview . Symbian platform (by Symbian Foundation) . Embedded Linux . Android (by Open Handset Alliance) . Microsoft Windows CE, Pocket PC, Pocket PC Phone Edition, Mobile . Microsoft Windows Phone 10 . Firefox OS . Attacks and Attacks and security features of selected . mobile OS 2 100% 20% 40% 60% 80% 0% Q1 '09 Q2 '09 Q3 '09 Q1 '10 Android Q2 '10 Q3 '10 Q4 '10 u Q1 '11 sers by operating sers by operating iOS Q2 '11 Worldwide smartphone Worldwide smartphone Q3 '11 Q4 '11 Microsoft Q1 '12 Q2 '12 Q3 '12 OS Q4 '12 RIM Q1 '13 Q2 '13 Q3 '13 Bada Q4' 13** Q1 '14 Q2 '14 s ystem ystem (2009 Q3 '14 Symbian Q4 '14 Q1 '15 [ Q2 '15 Statista2017a] Q3 '15 s ales ales to end Others Q4 '15 Q1 '16 Q2 '16 Q3 '16 - 2017) Q4 '16 Q1 '17 Q2 '17 3 . …… Worldwide smartphone sales to end …… users by operating system (Q2 2013) Android 79,0% Others 0,2% Symbian 0,3% Bada 0,4% BlackBerry OS 2,7% Windows 3,3% iOS 14,2% [Gartner2013] . Android iOS Windows BlackBerry OS Bada Symbian Others 4 Worldwide smartphone sales to end …… users by operating system (Q2 2014) Android 84,7% Others 0,6% BlackBerry OS 0,5% Windows 2,5% iOS 11,7% . -

Quartus Handheld Software: Discussion Forum: General
This document holds all the Quartus Handheld Software discussion forum messages from March 17, 2000 to 6:31pm, December 17, 2000. The links in the document all work -- but please don't try and post new messages to the Forum via the buttons in this document, as the subject threads may eventually be archived from the web site. Enjoy! Neal Bridges Quartus Handheld Software http://www.quartus.net Discussion Forum General December 17 - 06:31 pm [236] Quartus Forth (PalmOS version) December 17 - 04:20 pm [2833] Questions and discussion about the Quartus Forth on-board compiler for Palm/Visor/WorkPad handhelds. Quartus Forth (Royal daVinci version) April 11 - 09:15 pm [19] Questions and discussion about the Royal daVinci version of the Quartus Forth on-board compiler. Other Quartus Products December 17 - 02:12 pm [25] All other (non-Forth) Quartus products. Everything else! December 5 - 02:37 pm [105] Anything you'd like to talk about! Back to the Quartus Home Page NOTE: When posting Forth source code, to preserve indentation, format it using the "\pre{}" tag like this: \pre{ : hello \ A simple message: ." Hello World!" 10 0 do i . loop cr ; } If you wish to include a } character, enter it as: \} General Quartus Handheld Software: Discussion Forum: General ● Archive of the forum 12/17 06:31pm [2] ● Manual in Doc or TealDoc format 12/14 04:23pm [3] ● Starting New Project 12/10 06:59am [2] ● PalmSource 2000 12/14 12:38am [8] ● Easy Data Input From Paper 12/12 03:56pm [11] ● IBM Palm Devices 12/7 03:44am [3] ● Message Archives temporarily unavailable -

Mobile OS and Security Aspects
…… Lecture 11 Market Overview of Mobile Operating Systems and Security Aspects Mobile Business I (WS 2015/16) Prof. Dr. Kai Rannenberg . Deutsche Telekom Chair of Mobile Business & Multilateral Security . Johann Wolfgang Goethe University Frankfurt a. M. Overview - Market Overview of Mobile Operating …… Systems and Security Aspects § The Market for mobile devices and mobile OS § Mobile OS unavailable to other device manufacturers § Overview § Palm OS § Apple iOS (Unix-based) § Manufacturer-independent mobile OS § Overview § Symbian platform (by Symbian Foundation) § Embedded Linux § Android (by Open Handset Alliance) § Microsoft Windows CE, Pocket PC, Pocket PC Phone Edition, Mobile § Microsoft Windows Phone 10 . § Firefox OS . § Security features of selected mobile OS . 2 Worldwide Smartphone Sales to End …… Users by Operating System (2009-2015) Market share Market . OS [Statista 2015a] 3 Worldwide Smartphone Sales to End …… Users by Operating System (Q2 2012) Android 64,2% Others 0,6% Symbian 5,9% Bada 2,7% BlackBerry OS 5,2% [Gartner2013] Windows 2,6% . iOS 18,8% . Android iOS Windows BlackBerry OS Bada Symbian Others 4 Worldwide Smartphone Sales to End …… Users by Operating System (Q2 2013) Android 79,0% Others 0,2% Symbian 0,3% Bada 0,4% BlackBerry OS 2,7% Windows 3,3% iOS 14,2% [Gartner2013] . Android iOS Windows BlackBerry OS Bada Symbian Others 5 Worldwide Smartphone Sales to End …… Users by Operating System (Q2 2014) Android 84,7% Others 0,6% BlackBerry OS 0,5% Windows 2,5% iOS 11,7% . Android iOS Windows BlackBerryBlackBerry OS Symbian Bada Others [Statista 2014a] 6 Worldwide Smartphone Sales to End …… Users by Operating System (Q2 2015) Android 82,8% Others 0,4% BlackBerry OS 0,3% Windows 2,6% iOS 13,9% . -

Fastcpu V.3.0
FastCPU v.3.0 Megasoft2000 Ltd 1999 - 2002 Palm Software Division (PSD) Platform: Palm OS 3.5, 4.0, 4.1 FastCPU program is designed to control your device speed parameters. Using this program you are enable not only to multiply the speed of your applications performance by nearly 2 but also to save the system energy understating data bus and central processing unit (CPU) clock rate. Subconsciously comprehensive and simple control will allow you to run your system comfortably. Note! 1. Before installation make sure the date on your Palm device is valid (use the Preferences application). 2. Some frequency values may lead to unstable beam receiving (depending on hardware). 3. On some Palm m505 devices problems with digitizer sensitivity may occur at very high frequencies. 4. On some Palm IIIc devices incorrect graphics display may happen at increased frequencies. Should this happen, you must select the optimal frequency for your device (by trial and error) which allows it to display the information on the screen without image distortion. 5. This program is free to use for a 14 - day trial period. Please purchase this program only after ensuring that it works properly on your device. Installation. To install this game you should synchronize the "FastCPU_xxx.prc" application to your device. Files can be installed by using the Desktop S/W or just any other application. • FastCPU_ Color_HR_SZ.prc For color device (320x320, 16 Bits): Sony Clie` PEG-T650/665/675, NR-70/70V, ... • FastCPU_ Color_HR.prc For color device (320x320, 8 Bits): Sony Clie` PEG-N760, N610, T615, T625, .. -

Forensic Analysis of Digital Evidence from Palm Personal Digital Assistants
Graduate Theses, Dissertations, and Problem Reports 2004 Forensic analysis of digital evidence from Palm Personal Digital Assistants Christopher M. McNemar West Virginia University Follow this and additional works at: https://researchrepository.wvu.edu/etd Recommended Citation McNemar, Christopher M., "Forensic analysis of digital evidence from Palm Personal Digital Assistants" (2004). Graduate Theses, Dissertations, and Problem Reports. 1550. https://researchrepository.wvu.edu/etd/1550 This Thesis is protected by copyright and/or related rights. It has been brought to you by the The Research Repository @ WVU with permission from the rights-holder(s). You are free to use this Thesis in any way that is permitted by the copyright and related rights legislation that applies to your use. For other uses you must obtain permission from the rights-holder(s) directly, unless additional rights are indicated by a Creative Commons license in the record and/ or on the work itself. This Thesis has been accepted for inclusion in WVU Graduate Theses, Dissertations, and Problem Reports collection by an authorized administrator of The Research Repository @ WVU. For more information, please contact [email protected]. Forensic Analysis of Digital Evidence from Palm Personal Digital Assistants Christopher M. McNemar Thesis submitted to the College of Engineering and Mineral Resources at West Virginia University in partial fulfillment of the requirements for the degree of Master of Science In Computer Science With Emphasis On Computer Forensics Roy S. Nutter, Jr., Ph.D., Chair John M. Atkins, Ph.D. Bojan Cukic, Ph.D. Lane Department of Computer Science and Electrical Engineering Morgantown, West Virginia 2004 Keywords: PDA Forensics, Palm Forensics, Digital Forensics, Digital Image Analysis, Digital Evidence Copyright 2004 Christopher M. -

Users Guide for Palm OS
Fourth Printing, May 2002 warranty information LandWare, Inc. warrants this product against defects in materials and workmanship for a period of ONE (1) YEAR from the date of original retail purchase. If you discover a defect and notify LandWare of the same during the warranty period, LandWare will, at its option, repair, replace, or refund the purchase price of the product to you at no charge. THE WARRANTY AND REMEDIES SET FORTH ABOVE ARE EXCLUSIVE. LANDWARE DISCLAIMS ALL OTHER WARRANTIES, EXPRESS OR IMPLIED, INCLUDING WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. LANDWARE IS users guide NOT RESPONSIBLE FOR SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES ARISING FROM ANY BREACH OF WARRANTY OR UNDER ANY OTHER LEGAL THEORY. Because some jurisdictions do for Palm OS not permit the exclusion or limitations set forth above, they may not apply in all cases. copyright information The GoType! software is copyright 1998-2002 with all rights reserved by LandWare, Inc. The GoType! hardware design is PATENT PENDING by Sicon/Parallel Design. LandWare, GoType!, GoType is a regis- tered trademark and the slogan “Innovation for the Mobile Age” is a trademark of LandWare, Inc. All other product and brand names are trademarks of their respective owners. care and maintenance GoType!’s robust design stands up well to the harsh environment of mobile users— there are no complex moving parts so except for the points below no particular care is necessary. • Keep your keyboard away from extreme heat (for example, storage inside an automobile). • Don’t leave your keyboard any place that is extremely dusty, damp or wet. -

Emergence Innovation Expansion Perspectives
8-1/2" 8-1/2" New name. New magazine. Winter 2003 Issue 1 $4.95 Emergence Palm/Handspring into action as one. Page 3 Innovation NEW! Treo ™ 600 smartphone No compromises. Page 4 11" New products. New solutions. Same great value. palmOne® Presorted Standard 400 N. McCarthy Blvd. U.S. Postage Mail Stop 4209 PAID Milpitas, CA 95035 Sacramento, CA Expansion Permit No. 333 NEW! Tungsten™ T3 handheld Promo Code: PMAG1 Stretches viewpoints. John Sample Page 6 123 Main Street Anytown, ST 99999-9999 John Sample, s1234512345s Tepad be kelag diroplay ryepe espad a Perspectives nolonipy rediopy a sowdy. Lyepe espad a NEW! Zire™ 71 handheld nolonipy kelag in sowd rediopy a espay. Tepad be kelag diroplay ryepe espad a Capture the highlights. nolonipy rediopy a sowdy. Page 14 17" CRT-302 • PALM • PALMONE CATALOG FLAT SIZE 17" X 8-1/2" • FOLD SIZE 8-1/2" X 11" FRONT/BACK SPREAD • crt302_catalog.qxd 8-1/2" 8-1/2" palmOne magazine Which handheld is right for you? 12 We’ll help you decide. Winter 2003 Issue 1 Compare the features. Choose one. Or several. We have suggestions for upgrading, too. In this Issue Now from palmOne. 14 You’ll always have a camera – Phone or handheld? Get both in one. any time you need it. 4 Meet the new Treo™ 600 smartphone – small, Snap: It’s a digital camera. Share: It’s an organizer. ™ simple to use with a built-in QWERTY keyboard, It’s called the Zire 71 handheld. plus wireless communications. 16 The gift that’s as easy to use as it is to give. -

Read Paper (In PDF)
The Performance Measurement of Cryptographic Primitives on Palm Devices £ Duncan S. Wong, Hector Ho Fuentes and Agnes H. Chan College of Computer Science Northeastern University Boston, MA 02115, USA g fswong, hhofuent, ahchan @ccs.neu.edu Abstract which take only a few milliseconds or less and are widely used in securing data, performing authentication and in- We developed and evaluated several cryptographic sys- tegrity check on desktop machines, may spend seconds or tem libraries for Palm OS Ö which include stream and even minutes to carry out on a PalmPilot. Furthermore, the block ciphers, hash functions and multiple-precision integer memory space on low-power handheld devices are usually arithmetic operations. We noted that the encryption speed limited which may also introduce new challenges on the im- of SSC2 outperforms both ARC4 (Alleged RC4) and SEAL plementation of cryptosystems. Hence it is critical for users 3.0 if the plaintext is small. On the other hand, SEAL 3.0 to choose appropriate algorithms for the implementation of almost doubles the speed of SSC2 when the plaintext is con- cryptosystems on low-power devices. siderably large. We also observed that the optimized Rijn- We developed several cryptographic system libraries for dael with 8KB of lookup tables is 4 times faster than DES. Palm OS which include the following algorithms: In addition, our results show that implementing the cryp- tographic algorithms as system libraries does not degrade Stream Ciphers We tested the encryption speed of three their performance significantly. Instead, they provide great stream ciphers: SSC2 [11], ARC4 (Alleged RC4)1 and flexibility and code management to the algorithms.