Read Paper (In PDF)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Breaking Crypto Without Keys: Analyzing Data in Web Applications Chris Eng
Breaking Crypto Without Keys: Analyzing Data in Web Applications Chris Eng 1 Introduction – Chris Eng _ Director of Security Services, Veracode _ Former occupations . 2000-2006: Senior Consulting Services Technical Lead with Symantec Professional Services (@stake up until October 2004) . 1998-2000: US Department of Defense _ Primary areas of expertise . Web Application Penetration Testing . Network Penetration Testing . Product (COTS) Penetration Testing . Exploit Development (well, a long time ago...) _ Lead developer for @stake’s now-extinct WebProxy tool 2 Assumptions _ This talk is aimed primarily at penetration testers but should also be useful for developers to understand how your application might be vulnerable _ Assumes basic understanding of cryptographic terms but requires no understanding of the underlying math, etc. 3 Agenda 1 Problem Statement 2 Crypto Refresher 3 Analysis Techniques 4 Case Studies 5 Q & A 4 Problem Statement 5 Problem Statement _ What do you do when you encounter unknown data in web applications? . Cookies . Hidden fields . GET/POST parameters _ How can you tell if something is encrypted or trivially encoded? _ How much do I really have to know about cryptography in order to exploit implementation weaknesses? 6 Goals _ Understand some basic techniques for analyzing and breaking down unknown data _ Understand and recognize characteristics of bad crypto implementations _ Apply techniques to real-world penetration tests 7 Crypto Refresher 8 Types of Ciphers _ Block Cipher . Operates on fixed-length groups of bits, called blocks . Block sizes vary depending on the algorithm (most algorithms support several different block sizes) . Several different modes of operation for encrypting messages longer than the basic block size . -

SGX Secure Enclaves in Practice Security and Crypto Review
SGX Secure Enclaves in Practice Security and Crypto Review JP Aumasson, Luis Merino This talk ● First SGX review from real hardware and SDK ● Revealing undocumented parts of SGX ● Tool and application releases Props Victor Costan (MIT) Shay Gueron (Intel) Simon Johnson (Intel) Samuel Neves (Uni Coimbra) Joanna Rutkowska (Invisible Things Lab) Arrigo Triulzi Dan Zimmerman (Intel) Kudelski Security for supporting this research Agenda .theory What's SGX, how secure is it? .practice Developing for SGX on Windows and Linux .theory Cryptography schemes and implementations .practice Our projects: reencryption, metadata extraction What's SGX, how secure is it? New instruction set in Skylake Intel CPUs since autumn 2015 SGX as a reverse sandbox Protects enclaves of code/data from ● Operating System, or hypervisor ● BIOS, firmware, drivers ● System Management Mode (SMM) ○ aka ring -2 ○ Software “between BIOS and OS” ● Intel Management Engine (ME) ○ aka ring -3 ○ “CPU in the CPU” ● By extension, any remote attack = reverse sandbox Simplified workflow 1. Write enclave program (no secrets) 2. Get it attested (signed, bound to a CPU) 3. Provision secrets, from a remote client 4. Run enclave program in the CPU 5. Get the result, and a proof that it's the result of the intended computation Example: make reverse engineer impossible 1. Enclave generates a key pair a. Seals the private key b. Shares the public key with the authenticated client 2. Client sends code encrypted with the enclave's public key 3. CPU decrypts the code and executes it A trusted -

Astromist 2.2 User Guide
Astromist 2.2 User Guide Astromist 2.2 User Guide 1. Introduction.........................................................................................6 1.1. Objectives.................................................................................................................................. 6 1.2. Main features............................................................................................................................. 7 1.3. Limitations ................................................................................................................................. 9 1.3.1. Scope drives ................................................................................................................... 9 1.3.2. Photos............................................................................................................................. 9 2. Installation ........................................................................................10 2.1. Prerequisites ........................................................................................................................... 10 2.1.1. Operating system.......................................................................................................... 10 2.1.2. Hardware ...................................................................................................................... 10 2.1.3. Required “Plug-Ins”....................................................................................................... 10 2.2. Free and Registered -

Bias in the LEVIATHAN Stream Cipher
Bias in the LEVIATHAN Stream Cipher Paul Crowley1? and Stefan Lucks2?? 1 cryptolabs Amsterdam [email protected] 2 University of Mannheim [email protected] Abstract. We show two methods of distinguishing the LEVIATHAN stream cipher from a random stream using 236 bytes of output and pro- portional effort; both arise from compression within the cipher. The first models the cipher as two random functions in sequence, and shows that the probability of a collision in 64-bit output blocks is doubled as a re- sult; the second shows artifacts where the same inputs are presented to the key-dependent S-boxes in the final stage of the cipher for two suc- cessive outputs. Both distinguishers are demonstrated with experiments on a reduced variant of the cipher. 1 Introduction LEVIATHAN [5] is a stream cipher proposed by David McGrew and Scott Fluhrer for the NESSIE project [6]. Like most stream ciphers, it maps a key onto a pseudorandom keystream that can be XORed with the plaintext to generate the ciphertext. But it is unusual in that the keystream need not be generated in strict order from byte 0 onwards; arbitrary ranges of the keystream may be generated efficiently without the cost of generating and discarding all prior val- ues. In other words, the keystream is “seekable”. This property allows data from any part of a large encrypted file to be retrieved efficiently, without decrypting the whole file prior to the desired point; it is also useful for applications such as IPsec [2]. Other stream ciphers with this property include block ciphers in CTR mode [3]. -

RC4-2S: RC4 Stream Cipher with Two State Tables
RC4-2S: RC4 Stream Cipher with Two State Tables Maytham M. Hammood, Kenji Yoshigoe and Ali M. Sagheer Abstract One of the most important symmetric cryptographic algorithms is Rivest Cipher 4 (RC4) stream cipher which can be applied to many security applications in real time security. However, RC4 cipher shows some weaknesses including a correlation problem between the public known outputs of the internal state. We propose RC4 stream cipher with two state tables (RC4-2S) as an enhancement to RC4. RC4-2S stream cipher system solves the correlation problem between the public known outputs of the internal state using permutation between state 1 (S1) and state 2 (S2). Furthermore, key generation time of the RC4-2S is faster than that of the original RC4 due to less number of operations per a key generation required by the former. The experimental results confirm that the output streams generated by the RC4-2S are more random than that generated by RC4 while requiring less time than RC4. Moreover, RC4-2S’s high resistivity protects against many attacks vulnerable to RC4 and solves several weaknesses of RC4 such as distinguishing attack. Keywords Stream cipher Á RC4 Á Pseudo-random number generator This work is based in part, upon research supported by the National Science Foundation (under Grant Nos. CNS-0855248 and EPS-0918970). Any opinions, findings and conclusions or recommendations expressed in this material are those of the author (s) and do not necessarily reflect the views of the funding agencies or those of the employers. M. M. Hammood Applied Science, University of Arkansas at Little Rock, Little Rock, USA e-mail: [email protected] K. -

1 Star Trac Pro Partner – Training Partner Operations Manual Table of Contents I. Introduction II. Selecting Workout Partner
Star Trac Pro Partner – Training Partner Operations Manual Table of Contents I. Introduction II. Selecting Workout Partner a. Creating a Custom Workout III. Creating a Pro or Elite Treadmill Custom Workout a. Naming Your Workout b. Entering Weight/Time c. Designing Your Incline Profile d. Designing Your Speed Profile IV. Creating a Pro Bike Custom Workout a. Naming Your Workout b. Entering Weight/Time c. Designing Your Resistance Profile V. Accessing a Custom Workout VI. Beaming a Custom Workout a. Beaming to a Pro or Elite Treadmill b. Beaming to a Pro Bike c. Beaming to a PDA Device VII. Editing a Custom Workout VIII. Deleting a Custom Workout IX. Reviewing a Completed Workout X. Collecting an Existing Workout from a Pro or Elite Treadmill or Pro Bike XI. Appendix A: List of PDAs Compatible with Pro Partner 1 I. Introduction Thank you for choosing Star Trac for your fitness needs. Are you ready to take your clients’ workout to a new level? The Star Trac Pro Partner software program will make your Palm-powered PDA (Personal Digital Assistant) an integral part of your personal training experience when using a Star Trac Pro or Elite Treadmill or Pro Bike. Personalized workouts and tracking client workout data are now all in the palm of your hand! In this manual you will learn how to use the Training Partner application to design custom workouts and track workout information for your clients for a more personal approach. It’s simple! Just follow the steps in this user manual and you’re one step closer to making your personal training more efficient. -
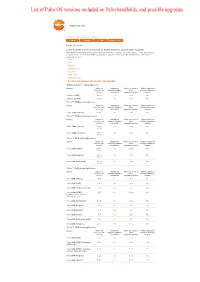
List of Palm OS Versions Included on Palm Handhelds, and Possible Upgrades
List of Palm OS versions included on Palm handhelds, and possible upgrades www.palm.com < Home < Support < Knowledge Library Article ID: 10714 List of Palm OS versions included on Palm handhelds, and possible upgrades Palm OS® is the operating system that drives Palm devices. In some cases, it may be possible to update your device with ROM upgrades or patches. Find your device below to see what's available for you: Centro Treo LifeDrive Tungsten, T|X Zire, Z22 Palm (older) Handspring Visor Questions & Answers about Palm OS upgrades Palm Centro™ smartphone Device Palm OS Handheld Palm OS version Palm Desktop & version (out- Upgrade/Update after HotSync Manager of-box) available? upgrade/update update Centro (AT&T) 5.4.9 No N/A No Centro (Sprint) 5.4.9 No N/A No Treo™ 755p smartphone Device Palm OS Handheld Palm OS version Palm Desktop & version (out- Upgrade/Update after HotSync Manager of-box) available? upgrade/update update Treo 755p (Sprint) 5.4.9 No N/A No Treo™ 700p smartphones Device Palm OS Handheld Palm OS version Palm Desktop & version (out- Upgrade/Update after HotSync Manager of-box) available? upgrade/update update Treo 700p (Sprint) Garnet Yes N/A No 5.4.9 Treo 700p (Verizon) Garnet No N/A No 5.4.9 Treo™ 680 smartphones Device Palm OS Handheld Palm OS version Palm Desktop & version (out- Upgrade/Update after HotSync Manager of-box) available? upgrade/update update Treo 680 (AT&T) Garnet Yes 5.4.9 No 5.4.9 Treo 680 (Rogers) Garnet No N/A No 5.4.9 Treo 680 (Unlocked) Garnet No N/A No 5.4.9 Treo™ 650 smartphones Device Palm OS -

Hart Pocket Configurator for Palm Organizer Features
HART POCKET CONFIGURATOR FOR PALM ORGANIZER The HPC301 Hart Pocket Configurator is a new HPC301- HART® Configurator Screen Configurator Software from Smar for HART® protocol Instruments and systems. This has been developed to work with a Palm Organizer. The configurator consists of HPC301 (the software), HPI311 (the interface) and acessories to configure and calibrate HART® equipment. This packageconfigures Series 301 products from Smar and many others wich have the HART® protocol and where a portable configurator is needed. It therefore can be used to configure field devices. Interface HPI311 V-HART® PalmVx Handheld FEATURES üThis configuration tool supports various commercial üIt can support various devices from different types of handheld based on Palm O.S. vendors. (The generic configuration tool üMuch faster than other handheld solutions. version is always available) üProduct User's Guide and Device Information üOnly one software application can configure could be provided online. (Online Help) various field devices. (No need datapacks or memory modules for every device type). üRechargeable battery. (The interface power üSynchronize data with the PC. Configuration supply can recharge both handheld and interface). files can be exchanged with PC applications. üEasy to upgrade on site. üOther useful programs could be installed in the handheld. (For example Unit Converter, History üEasy Interface Connection Reports, E-mail, etc.). üBattery Status Indicator üLight and slim. It really fits in a pocket. üStandard modem D11 smar ORDERING CODE DESCRIPTION CODE Description Palm-VX Palm Vx handheld Palm-IIIC Palm IIIc handheld HPI311-V HART Pocket Interface for Palm V handhelds (includes HPC301 software) HPI311-III HART Pocket Interface for Palm III handhelds (includes HPC301 software) D12 smar. -

Palm OS Cobalt 6.1 in February 2004 6.1 in February Cobalt Palm OS Release: Last 11.2 Ios Release: Latest
…… Lecture 11 Market Overview of Mobile Operating Systems and Security Aspects Mobile Business I (WS 2017/18) Prof. Dr. Kai Rannenberg . Deutsche Telekom Chair of Mobile Business & Multilateral Security . Johann Wolfgang Goethe University Frankfurt a. M. Overview …… . The market for mobile devices and mobile OS . Mobile OS unavailable to other device manufacturers . Overview . Palm OS . Apple iOS (Unix-based) . Manufacturer-independent mobile OS . Overview . Symbian platform (by Symbian Foundation) . Embedded Linux . Android (by Open Handset Alliance) . Microsoft Windows CE, Pocket PC, Pocket PC Phone Edition, Mobile . Microsoft Windows Phone 10 . Firefox OS . Attacks and Attacks and security features of selected . mobile OS 2 100% 20% 40% 60% 80% 0% Q1 '09 Q2 '09 Q3 '09 Q1 '10 Android Q2 '10 Q3 '10 Q4 '10 u Q1 '11 sers by operating sers by operating iOS Q2 '11 Worldwide smartphone Worldwide smartphone Q3 '11 Q4 '11 Microsoft Q1 '12 Q2 '12 Q3 '12 OS Q4 '12 RIM Q1 '13 Q2 '13 Q3 '13 Bada Q4' 13** Q1 '14 Q2 '14 s ystem ystem (2009 Q3 '14 Symbian Q4 '14 Q1 '15 [ Q2 '15 Statista2017a] Q3 '15 s ales ales to end Others Q4 '15 Q1 '16 Q2 '16 Q3 '16 - 2017) Q4 '16 Q1 '17 Q2 '17 3 . …… Worldwide smartphone sales to end …… users by operating system (Q2 2013) Android 79,0% Others 0,2% Symbian 0,3% Bada 0,4% BlackBerry OS 2,7% Windows 3,3% iOS 14,2% [Gartner2013] . Android iOS Windows BlackBerry OS Bada Symbian Others 4 Worldwide smartphone sales to end …… users by operating system (Q2 2014) Android 84,7% Others 0,6% BlackBerry OS 0,5% Windows 2,5% iOS 11,7% . -

A Software-Optimized Encryption Algorithm
To app ear in J of CryptologyFull version of Last revised Septemb er A SoftwareOptimized Encryption Algorithm Phillip Rogaway and Don Copp ersmith Department of Computer Science Engineering I I Buildin g University of California Davis CA USA rogawaycsucdavisedu IBM TJ Watson ResearchCenter PO Box Yorktown Heights NY USA copp erwatsonibmcom Abstract We describ e a softwareecient encryption algorithm named SEAL Computational cost on a mo dern bit pro cessor is ab out clo ck cycles p er byte of text The cipher is a pseudorandom function family under control of a key rst prepro cessed into an internal table it stretches a bit p osition index into a long pseudorandom string This string can b e used as the keystream of a Vernam cipher Key words Cryptography Encryption Fast encryption Pseudoran dom function family Software encryption Stream cipher Intro duction Encrypting Fast In Software Encryption must often b e p erformed at high data rates a requirement sometimes met with the help of supp orting crypto graphic hardware Unfortunately cryptographic hardware is often absent and data condentiality is sacriced b ecause the cost of software cryptographyis deemed to b e excessive The computational cost of software cryptography is a function of the under y of its implementation But regardless of imple lying algorithm and the qualit mentation a cryptographic algorithm designed to run well in hardware will not p erform in software as well as an algorithm optimized for software execution The hardwareoriented Data Encryption Algorithm DES -

Quartus Handheld Software: Discussion Forum: General
This document holds all the Quartus Handheld Software discussion forum messages from March 17, 2000 to 6:31pm, December 17, 2000. The links in the document all work -- but please don't try and post new messages to the Forum via the buttons in this document, as the subject threads may eventually be archived from the web site. Enjoy! Neal Bridges Quartus Handheld Software http://www.quartus.net Discussion Forum General December 17 - 06:31 pm [236] Quartus Forth (PalmOS version) December 17 - 04:20 pm [2833] Questions and discussion about the Quartus Forth on-board compiler for Palm/Visor/WorkPad handhelds. Quartus Forth (Royal daVinci version) April 11 - 09:15 pm [19] Questions and discussion about the Royal daVinci version of the Quartus Forth on-board compiler. Other Quartus Products December 17 - 02:12 pm [25] All other (non-Forth) Quartus products. Everything else! December 5 - 02:37 pm [105] Anything you'd like to talk about! Back to the Quartus Home Page NOTE: When posting Forth source code, to preserve indentation, format it using the "\pre{}" tag like this: \pre{ : hello \ A simple message: ." Hello World!" 10 0 do i . loop cr ; } If you wish to include a } character, enter it as: \} General Quartus Handheld Software: Discussion Forum: General ● Archive of the forum 12/17 06:31pm [2] ● Manual in Doc or TealDoc format 12/14 04:23pm [3] ● Starting New Project 12/10 06:59am [2] ● PalmSource 2000 12/14 12:38am [8] ● Easy Data Input From Paper 12/12 03:56pm [11] ● IBM Palm Devices 12/7 03:44am [3] ● Message Archives temporarily unavailable -

Mobile OS and Security Aspects
…… Lecture 11 Market Overview of Mobile Operating Systems and Security Aspects Mobile Business I (WS 2015/16) Prof. Dr. Kai Rannenberg . Deutsche Telekom Chair of Mobile Business & Multilateral Security . Johann Wolfgang Goethe University Frankfurt a. M. Overview - Market Overview of Mobile Operating …… Systems and Security Aspects § The Market for mobile devices and mobile OS § Mobile OS unavailable to other device manufacturers § Overview § Palm OS § Apple iOS (Unix-based) § Manufacturer-independent mobile OS § Overview § Symbian platform (by Symbian Foundation) § Embedded Linux § Android (by Open Handset Alliance) § Microsoft Windows CE, Pocket PC, Pocket PC Phone Edition, Mobile § Microsoft Windows Phone 10 . § Firefox OS . § Security features of selected mobile OS . 2 Worldwide Smartphone Sales to End …… Users by Operating System (2009-2015) Market share Market . OS [Statista 2015a] 3 Worldwide Smartphone Sales to End …… Users by Operating System (Q2 2012) Android 64,2% Others 0,6% Symbian 5,9% Bada 2,7% BlackBerry OS 5,2% [Gartner2013] Windows 2,6% . iOS 18,8% . Android iOS Windows BlackBerry OS Bada Symbian Others 4 Worldwide Smartphone Sales to End …… Users by Operating System (Q2 2013) Android 79,0% Others 0,2% Symbian 0,3% Bada 0,4% BlackBerry OS 2,7% Windows 3,3% iOS 14,2% [Gartner2013] . Android iOS Windows BlackBerry OS Bada Symbian Others 5 Worldwide Smartphone Sales to End …… Users by Operating System (Q2 2014) Android 84,7% Others 0,6% BlackBerry OS 0,5% Windows 2,5% iOS 11,7% . Android iOS Windows BlackBerryBlackBerry OS Symbian Bada Others [Statista 2014a] 6 Worldwide Smartphone Sales to End …… Users by Operating System (Q2 2015) Android 82,8% Others 0,4% BlackBerry OS 0,3% Windows 2,6% iOS 13,9% .