11 Inverse Functions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Inverse of Exponential Functions Are Logarithmic Functions
Math Instructional Framework Full Name Math III Unit 3 Lesson 2 Time Frame Unit Name Logarithmic Functions as Inverses of Exponential Functions Learning Task/Topics/ Task 2: How long Does It Take? Themes Task 3: The Population of Exponentia Task 4: Modeling Natural Phenomena on Earth Culminating Task: Traveling to Exponentia Standards and Elements MM3A2. Students will explore logarithmic functions as inverses of exponential functions. c. Define logarithmic functions as inverses of exponential functions. Lesson Essential Questions How can you graph the inverse of an exponential function? Activator PROBLEM 2.Task 3: The Population of Exponentia (Problem 1 could be completed prior) Work Session Inverse of Exponential Functions are Logarithmic Functions A Graph the inverse of exponential functions. B Graph logarithmic functions. See Notes Below. VOCABULARY Asymptote: A line or curve that describes the end behavior of the graph. A graph never crosses a vertical asymptote but it may cross a horizontal or oblique asymptote. Common logarithm: A logarithm with a base of 10. A common logarithm is the power, a, such that 10a = b. The common logarithm of x is written log x. For example, log 100 = 2 because 102 = 100. Exponential functions: A function of the form y = a·bx where a > 0 and either 0 < b < 1 or b > 1. Logarithmic functions: A function of the form y = logbx, with b 1 and b and x both positive. A logarithmic x function is the inverse of an exponential function. The inverse of y = b is y = logbx. Logarithm: The logarithm base b of a number x, logbx, is the power to which b must be raised to equal x. -

IVC Factsheet Functions Comp Inverse
Imperial Valley College Math Lab Functions: Composition and Inverse Functions FUNCTION COMPOSITION In order to perform a composition of functions, it is essential to be familiar with function notation. If you see something of the form “푓(푥) = [expression in terms of x]”, this means that whatever you see in the parentheses following f should be substituted for x in the expression. This can include numbers, variables, other expressions, and even other functions. EXAMPLE: 푓(푥) = 4푥2 − 13푥 푓(2) = 4 ∙ 22 − 13(2) 푓(−9) = 4(−9)2 − 13(−9) 푓(푎) = 4푎2 − 13푎 푓(푐3) = 4(푐3)2 − 13푐3 푓(ℎ + 5) = 4(ℎ + 5)2 − 13(ℎ + 5) Etc. A composition of functions occurs when one function is “plugged into” another function. The notation (푓 ○푔)(푥) is pronounced “푓 of 푔 of 푥”, and it literally means 푓(푔(푥)). In other words, you “plug” the 푔(푥) function into the 푓(푥) function. Similarly, (푔 ○푓)(푥) is pronounced “푔 of 푓 of 푥”, and it literally means 푔(푓(푥)). In other words, you “plug” the 푓(푥) function into the 푔(푥) function. WARNING: Be careful not to confuse (푓 ○푔)(푥) with (푓 ∙ 푔)(푥), which means 푓(푥) ∙ 푔(푥) . EXAMPLES: 푓(푥) = 4푥2 − 13푥 푔(푥) = 2푥 + 1 a. (푓 ○푔)(푥) = 푓(푔(푥)) = 4[푔(푥)]2 − 13 ∙ 푔(푥) = 4(2푥 + 1)2 − 13(2푥 + 1) = [푠푚푝푙푓푦] … = 16푥2 − 10푥 − 9 b. (푔 ○푓)(푥) = 푔(푓(푥)) = 2 ∙ 푓(푥) + 1 = 2(4푥2 − 13푥) + 1 = 8푥2 − 26푥 + 1 A function can even be “composed” with itself: c. -

The Cardinality of a Finite Set
1 Math 300 Introduction to Mathematical Reasoning Fall 2018 Handout 12: More About Finite Sets Please read this handout after Section 9.1 in the textbook. The Cardinality of a Finite Set Our textbook defines a set A to be finite if either A is empty or A ≈ Nk for some natural number k, where Nk = {1,...,k} (see page 455). It then goes on to say that A has cardinality k if A ≈ Nk, and the empty set has cardinality 0. These are standard definitions. But there is one important point that the book left out: Before we can say that the cardinality of a finite set is a well-defined number, we have to ensure that it is not possible for the same set A to be equivalent to Nn and Nm for two different natural numbers m and n. This may seem obvious, but it turns out to be a little trickier to prove than you might expect. The purpose of this handout is to prove that fact. The crux of the proof is the following lemma about subsets of the natural numbers. Lemma 1. Suppose m and n are natural numbers. If there exists an injective function from Nm to Nn, then m ≤ n. Proof. For each natural number n, let P (n) be the following statement: For every m ∈ N, if there is an injective function from Nm to Nn, then m ≤ n. We will prove by induction on n that P (n) is true for every natural number n. We begin with the base case, n = 1. -

5.7 Inverses and Radical Functions Finding the Inverse Of
SECTION 5.7 iNverses ANd rAdicAl fuNctioNs 435 leARnIng ObjeCTIveS In this section, you will: • Find the inverse of an invertible polynomial function. • Restrict the domain to find the inverse of a polynomial function. 5.7 InveRSeS And RAdICAl FUnCTIOnS A mound of gravel is in the shape of a cone with the height equal to twice the radius. Figure 1 The volume is found using a formula from elementary geometry. __1 V = πr 2 h 3 __1 = πr 2(2r) 3 __2 = πr 3 3 We have written the volume V in terms of the radius r. However, in some cases, we may start out with the volume and want to find the radius. For example: A customer purchases 100 cubic feet of gravel to construct a cone shape mound with a height twice the radius. What are the radius and height of the new cone? To answer this question, we use the formula ____ 3 3V r = ___ √ 2π This function is the inverse of the formula for V in terms of r. In this section, we will explore the inverses of polynomial and rational functions and in particular the radical functions we encounter in the process. Finding the Inverse of a Polynomial Function Two functions f and g are inverse functions if for every coordinate pair in f, (a, b), there exists a corresponding coordinate pair in the inverse function, g, (b, a). In other words, the coordinate pairs of the inverse functions have the input and output interchanged. Only one-to-one functions have inverses. Recall that a one-to-one function has a unique output value for each input value and passes the horizontal line test. -

Inverse Trigonometric Functions
Chapter 2 INVERSE TRIGONOMETRIC FUNCTIONS vMathematics, in general, is fundamentally the science of self-evident things. — FELIX KLEIN v 2.1 Introduction In Chapter 1, we have studied that the inverse of a function f, denoted by f–1, exists if f is one-one and onto. There are many functions which are not one-one, onto or both and hence we can not talk of their inverses. In Class XI, we studied that trigonometric functions are not one-one and onto over their natural domains and ranges and hence their inverses do not exist. In this chapter, we shall study about the restrictions on domains and ranges of trigonometric functions which ensure the existence of their inverses and observe their behaviour through graphical representations. Besides, some elementary properties will also be discussed. The inverse trigonometric functions play an important Aryabhata role in calculus for they serve to define many integrals. (476-550 A. D.) The concepts of inverse trigonometric functions is also used in science and engineering. 2.2 Basic Concepts In Class XI, we have studied trigonometric functions, which are defined as follows: sine function, i.e., sine : R → [– 1, 1] cosine function, i.e., cos : R → [– 1, 1] π tangent function, i.e., tan : R – { x : x = (2n + 1) , n ∈ Z} → R 2 cotangent function, i.e., cot : R – { x : x = nπ, n ∈ Z} → R π secant function, i.e., sec : R – { x : x = (2n + 1) , n ∈ Z} → R – (– 1, 1) 2 cosecant function, i.e., cosec : R – { x : x = nπ, n ∈ Z} → R – (– 1, 1) 2021-22 34 MATHEMATICS We have also learnt in Chapter 1 that if f : X→Y such that f(x) = y is one-one and onto, then we can define a unique function g : Y→X such that g(y) = x, where x ∈ X and y = f(x), y ∈ Y. -

Calculus Formulas and Theorems
Formulas and Theorems for Reference I. Tbigonometric Formulas l. sin2d+c,cis2d:1 sec2d l*cot20:<:sc:20 +.I sin(-d) : -sitt0 t,rs(-//) = t r1sl/ : -tallH 7. sin(A* B) :sitrAcosB*silBcosA 8. : siri A cos B - siu B <:os,;l 9. cos(A+ B) - cos,4cos B - siuA siriB 10. cos(A- B) : cosA cosB + silrA sirrB 11. 2 sirrd t:osd 12. <'os20- coS2(i - siu20 : 2<'os2o - I - 1 - 2sin20 I 13. tan d : <.rft0 (:ost/ I 14. <:ol0 : sirrd tattH 1 15. (:OS I/ 1 16. cscd - ri" 6i /F tl r(. cos[I ^ -el : sitt d \l 18. -01 : COSA 215 216 Formulas and Theorems II. Differentiation Formulas !(r") - trr:"-1 Q,:I' ]tra-fg'+gf' gJ'-,f g' - * (i) ,l' ,I - (tt(.r))9'(.,') ,i;.[tyt.rt) l'' d, \ (sttt rrJ .* ('oqI' .7, tJ, \ . ./ stll lr dr. l('os J { 1a,,,t,:r) - .,' o.t "11'2 1(<,ot.r') - (,.(,2.r' Q:T rl , (sc'c:.r'J: sPl'.r tall 11 ,7, d, - (<:s<t.r,; - (ls(].]'(rot;.r fr("'),t -.'' ,1 - fr(u") o,'ltrc ,l ,, 1 ' tlll ri - (l.t' .f d,^ --: I -iAl'CSllLl'l t!.r' J1 - rz 1(Arcsi' r) : oT Il12 Formulas and Theorems 2I7 III. Integration Formulas 1. ,f "or:artC 2. [\0,-trrlrl *(' .t "r 3. [,' ,t.,: r^x| (' ,I 4. In' a,,: lL , ,' .l 111Q 5. In., a.r: .rhr.r' .r r (' ,l f 6. sirr.r d.r' - ( os.r'-t C ./ 7. /.,,.r' dr : sitr.i'| (' .t 8. tl:r:hr sec,rl+ C or ln Jccrsrl+ C ,f'r^rr f 9. -

Monomorphism - Wikipedia, the Free Encyclopedia
Monomorphism - Wikipedia, the free encyclopedia http://en.wikipedia.org/wiki/Monomorphism Monomorphism From Wikipedia, the free encyclopedia In the context of abstract algebra or universal algebra, a monomorphism is an injective homomorphism. A monomorphism from X to Y is often denoted with the notation . In the more general setting of category theory, a monomorphism (also called a monic morphism or a mono) is a left-cancellative morphism, that is, an arrow f : X → Y such that, for all morphisms g1, g2 : Z → X, Monomorphisms are a categorical generalization of injective functions (also called "one-to-one functions"); in some categories the notions coincide, but monomorphisms are more general, as in the examples below. The categorical dual of a monomorphism is an epimorphism, i.e. a monomorphism in a category C is an epimorphism in the dual category Cop. Every section is a monomorphism, and every retraction is an epimorphism. Contents 1 Relation to invertibility 2 Examples 3 Properties 4 Related concepts 5 Terminology 6 See also 7 References Relation to invertibility Left invertible morphisms are necessarily monic: if l is a left inverse for f (meaning l is a morphism and ), then f is monic, as A left invertible morphism is called a split mono. However, a monomorphism need not be left-invertible. For example, in the category Group of all groups and group morphisms among them, if H is a subgroup of G then the inclusion f : H → G is always a monomorphism; but f has a left inverse in the category if and only if H has a normal complement in G. -

On CCZ-Equivalence of the Inverse Function
1 On CCZ-equivalence of the inverse function Lukas K¨olsch −1 Abstract—The inverse function x 7→ x on F2n is one of the graph of F , denoted by G = (x, F (x)): x F n , to 1 F1 { 1 ∈ 2 } most studied functions in cryptography due to its widespread the graph of F2. use as an S-box in block ciphers like AES. In this paper, we show that, if n ≥ 5, every function that is CCZ-equivalent It is obvious that two functions that are affine equivalent are to the inverse function is already EA-equivalent to it. This also EA-equivalent. Furthermore, two EA-equivalent func- confirms a conjecture by Budaghyan, Calderini and Villa. We tions are also CCZ-equivalent. In general, the concepts of also prove that every permutation that is CCZ-equivalent to the inverse function is already affine equivalent to it. The majority CCZ-equivalence and EA equivalence do differ, for example of the paper is devoted to proving that there is no permutation a bijective function is always CCZ-equivalent to its compo- −1 polynomial of the form L1(x )+ L2(x) over F2n if n ≥ 5, sitional inverse, which is not the case for EA-equivalence. where L1, L2 are nonzero linear functions. In the proof, we Note also that the size of the image set is invariant under combine Kloosterman sums, quadratic forms and tools from affine equivalence, which is generally not the case for the additive combinatorics. other two more general notions. Index Terms —Inverse function, CCZ-equivalence, EA- Particularly well studied are APN monomials, a list of all equivalence, S-boxes, permutation polynomials. -
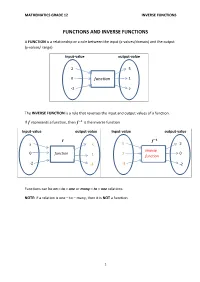
Grade 12 Mathematics Inverse Functions
MATHEMATICS GRADE 12 INVERSE FUNCTIONS FUNCTIONS AND INVERSE FUNCTIONS A FUNCTION is a relationship or a rule between the input (x-values/domain) and the output (y-values/ range) Input-value output-value 2 5 0 function 1 -2 2 The INVERSE FUNCTION is a rule that reverses the input and output values of a function. If represents a function, then is the inverse function. Input-value output-value Input-value output-value 풇 풇 ퟏ 2 5 5 2 Inverse 0 function 1 0 1 function -2 -3 -3 -2 Functions can be on – to – one or many – to – one relations. NOTE: if a relation is one – to – many, then it is NOT a function. 1 MATHEMATICS GRADE 12 INVERSE FUNCTIONS HOW TO DETERMINE WHETHER THE GRAPH IS A FUNCTION OR NOT i. Vertical – line test: The vertical –line test is used to determine whether a graph is a function or not a function. To determine whether a graph is a function, draw a vertical line parallel to the y-axis or perpendicular to the x- axis. If the line intersects the graph once then graph is a function. If the line intersects the graph more than once then the relation is not a function of x. Because functions are single-valued relations and a particular x-value is mapped onto one and only one y-value. Function not a function (one to many relation) TEST FOR ONE –TO– ONE FUNCTION ii. Horizontal – line test The horizontal – line test is used to determine whether a function is a one-to-one function. -
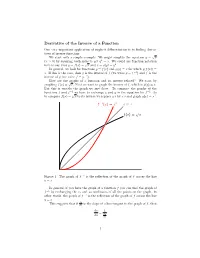
Derivative of the Inverse of a Function One Very Important Application of Implicit Differentiation Is to finding Deriva Tives of Inverse Functions
Derivative of the Inverse of a Function One very important application of implicit differentiation is to finding deriva tives of inverse functions. We start with a simple example. We might simplify the equation y = px (x > 0) by squaring both sides to get y2 = x. We could use function notation here to say that y = f(x) = px and x = g(y) = y2. In general, we look for functions y = f(x) and g(y) = x for which g(f(x)) = x. If this is the case, then g is the inverse of f (we write g = f −1) and f is the inverse of g (we write f = g−1). How are the graphs of a function and its inverse related? We start by graphing f(x) = px. Next we want to graph the inverse of f, which is g(y) = x. But this is exactly the graph we just drew. To compare the graphs of the functions f and f −1 we have to exchange x and y in the equation for f −1 . So to compare f(x) = px to its inverse we replace y’s by x’s and graph g(x) = x2. 1 2 f − (x)=x y = x f(x)=√x −1 Figure 1: The graph of f is the reflection of the graph of f across the line y = x In general, if you have the graph of a function f you can find the graph of −1 f by exchanging the x- and y-coordinates of all the points on the graph. -

A New Characterization of Injective and Surjective Functions and Group Homomorphisms
A new characterization of injective and surjective functions and group homomorphisms ANDREI TIBERIU PANTEA* Abstract. A model of a function f between two non-empty sets is defined to be a factorization f ¼ i, where ¼ is a surjective function and i is an injective Æ ± function. In this note we shall prove that a function f is injective (respectively surjective) if and only if it has a final (respectively initial) model. A similar result, for groups, is also proven. Keywords: factorization of morphisms, injective/surjective maps, initial/final objects MSC: Primary 03E20; Secondary 20A99 1 Introduction and preliminary remarks In this paper we consider the sets taken into account to be non-empty and groups denoted differently to be disjoint. For basic concepts on sets and functions see [1]. It is a well known fact that any function f : A B can be written as the composition of a surjective function ! followed by an injective function. Indeed, f f 0 id , where f 0 : A Im(f ) is the restriction Æ ± B ! of f to Im(f ) is one such factorization. Moreover, it is an elementary exercise to prove that this factorization is unique up to an isomorphism: i.e. if f i ¼, i : A X , ¼: X B is 1 ¡ Æ ±¢ ! 1 ! another factorization for f , then we easily see that X i ¡ Im(f ) and that ¼ i ¡ f 0. The Æ Æ ± purpose of this note is to study the dual problem. Let f : A B be a function. We shall define ! a model of the function f to be a triple (X ,i,¼) made up of a set X , an injective function i : A X and a surjective function ¼: X B such that f ¼ i, that is, the following diagram ! ! Æ ± is commutative. -

Functions-Handoutnonotes.Pdf
Introduction Functions Slides by Christopher M. Bourke You’ve already encountered functions throughout your education. Instructor: Berthe Y. Choueiry f(x, y) = x + y f(x) = x f(x) = sin x Spring 2006 Here, however, we will study functions on discrete domains and ranges. Moreover, we generalize functions to mappings. Thus, there may not always be a “nice” way of writing functions like Computer Science & Engineering 235 above. Introduction to Discrete Mathematics Sections 1.8 of Rosen [email protected] Definition Definitions Function Terminology Definition A function f from a set A to a set B is an assignment of exactly Definition one element of B to each element of A. We write f(a) = b if b is Let f : A → B and let f(a) = b. Then we use the following the unique element of B assigned by the function f to the element terminology: a ∈ A. If f is a function from A to B, we write I A is the domain of f, denoted dom(f). f : A → B I B is the codomain of f. This can be read as “f maps A to B”. I b is the image of a. I a is the preimage of b. Note the subtlety: I The range of f is the set of all images of elements of A, denoted rng(f). I Each and every element in A has a single mapping. I Each element in B may be mapped to by several elements in A or not at all. Definitions Definition I Visualization More Definitions Preimage Range Image, f(a) = b Definition f Let f1 and f2 be functions from a set A to R.