TASKING VX-Toolset for Tricore User Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Linkers and Loaders Hui Chen Department of Computer & Information Science CUNY Brooklyn College
CISC 3320 MW3 Linkers and Loaders Hui Chen Department of Computer & Information Science CUNY Brooklyn College CUNY | Brooklyn College: CISC 3320 9/11/2019 1 OS Acknowledgement • These slides are a revision of the slides by the authors of the textbook CUNY | Brooklyn College: CISC 3320 9/11/2019 2 OS Outline • Linkers and linking • Loaders and loading • Object and executable files CUNY | Brooklyn College: CISC 3320 9/11/2019 3 OS Authoring and Running a Program • A programmer writes a program in a programming language (the source code) • The program resides on disk as a binary executable file translated from the source code of the program • e.g., a.out or prog.exe • To run the program on a CPU • the program must be brought into memory, and • create a process for it • A multi-step process CUNY | Brooklyn College: CISC 3320 9/11/2019 4 OS CUNY | Brooklyn College: CISC 3320 9/11/2019 5 OS Compilation • Source files are compiled into object files • The object files are designed to be loaded into any physical memory location, a format known as an relocatable object file. CUNY | Brooklyn College: CISC 3320 9/11/2019 6 OS Relocatable Object File • Object code: formatted machine code, but typically non-executable • Many formats • The Executable and Linkable Format (ELF) • The Common Object File Format (COFF) CUNY | Brooklyn College: CISC 3320 9/11/2019 7 OS Examining an Object File • In Linux/UNIX, $ file main.o main.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped $ nm main.o • Also use objdump, readelf, elfutils, hexedit • You may need # apt-get install hexedit # apt-get install elfutils CUNY | Brooklyn College: CISC 3320 9/11/2019 8 OS Linking • During the linking phase, other object files or libraries may be included as well • Example: $ g++ -o main -lm main.o sumsine.o • A program consists of one or more object files. -

6 Boot Loader
BootBoot LoaderLoader 66 6.1 INTRODUCTION The Boot Loader is a utility program supplied with the ADSP-21000 Family Development Software. The loader converts an ADSP-21xxx executable program, generated by the linker, into a format which can be used to boot a target hardware system and initialize its memory. The loader’s invocation command is LDR21K. The boot loader replaces the MEM21K memory initializer used with the ADSP-21020 processor. Any executable file to be processed with the LDR21K boot loader must not be processed by MEM21K. The -nomem switch of the C compiler should be used when compiling any C source files—this switch prevents the compiler from running MEM21K. The following naming conventions are used throughout this chapter: The loader refers to LDR21K contained in the software release. The boot loader refers to the executable file that performs the memory initialization on the target. The boot file refers to the output of the loader that contains the boot loader and the formatted system configurations. Booting refers to the process of loading the boot loader, initialization system memory, and starting the application on the target. Memory is referred to as being either data memory, program memory, or internal memory. Remember that the ADSP-21020 processor has separate external program and data memories, but does not have any internal memory. The ADSP-2106x SHARC has both internal and external memory. 6 – 1 66 BootBoot LoaderLoader To use the loader, you should be familiar with the hardware requirements of booting an ADSP-21000 target. See Chapter 11 of the ADSP-2106x SHARC User’s Manual or Chapter 9 of the ADSP-21020 User’s Manual for further information. -

Virtual Table Hijacking Protection Enhancement for CFG
Liberation Guard: Virtual Table Hijacking Protection Enhancement for CFG Eyal Itkin [email protected] eyalitkin.wordpress.com Abstract—Control Flow Guard (CFG) is an advanced defense mechanism by Microsoft, that aims to mitigate exploiting tech- niques using control flow integrity checks. In this paper we1 present a proposed enhancement of CFG, that adds virtual table integrity checks which will mitigate most virtual table hijacking exploits. The proposed defense creates a strong differentiation between ordinary and virtual functions, thus significantly nar- rowing the exploit options available when controlling an indirect virtual call. This differentiation will impose strong restrictions over current virtual table hijacking exploits, thus significantly raising the protection CFG can offer to protected programs2. I. PRELIMINARIES Fig. 1. Example of address translation for an unaligned address (at the top) and an aligned address (at the bottom). A. Control Flow Guard Overview Control Flow Guard (CFG) is an advanced control flow integrity (CFI) defense mechanism introduced by Microsoft in In order to use this CFI knowledge, the compiler adds Windows 8.1 and Windows 10 [4]. CFG aims to significantly a validation check prior to each indirect call (only call restrict the allowed control flow in the cases of indirect calls, assembly opcode, and not jump opcodes). This function is and is supported in Visual Studio 2015. stored in ntdll.dll, and exported to the rest of the DLLs. This defense mechanism is based on the fact that during The function verifies the requested address against the stored compilation time the compiler ”learns” where ”legitimate” bitmap, while acting as a NOP in case the bit is ”1” and crashes functions start, and records these addresses in the compiled the program in case the bit is ”0”. -

The UNIX Time- Sharing System
1. Introduction There have been three versions of UNIX. The earliest version (circa 1969–70) ran on the Digital Equipment Cor- poration PDP-7 and -9 computers. The second version ran on the unprotected PDP-11/20 computer. This paper describes only the PDP-11/40 and /45 [l] system since it is The UNIX Time- more modern and many of the differences between it and older UNIX systems result from redesign of features found Sharing System to be deficient or lacking. Since PDP-11 UNIX became operational in February Dennis M. Ritchie and Ken Thompson 1971, about 40 installations have been put into service; they Bell Laboratories are generally smaller than the system described here. Most of them are engaged in applications such as the preparation and formatting of patent applications and other textual material, the collection and processing of trouble data from various switching machines within the Bell System, and recording and checking telephone service orders. Our own installation is used mainly for research in operating sys- tems, languages, computer networks, and other topics in computer science, and also for document preparation. UNIX is a general-purpose, multi-user, interactive Perhaps the most important achievement of UNIX is to operating system for the Digital Equipment Corpora- demonstrate that a powerful operating system for interac- tion PDP-11/40 and 11/45 computers. It offers a number tive use need not be expensive either in equipment or in of features seldom found even in larger operating sys- human effort: UNIX can run on hardware costing as little as tems, including: (1) a hierarchical file system incorpo- $40,000, and less than two man years were spent on the rating demountable volumes; (2) compatible file, device, main system software. -

Symbol Table Relocation Table Object File Format Where Are We Now
inst.eecs.berkeley.edu/~cs61c UCB CS61C : Machine Structures Symbol Table Lecture 19 – Running a Program II . List of “items” in this file that may be used by other files. (Compiling, Assembling, Linking, Loading) Hello to . What are they? Lecturer SOE 2008-03-05 Neil Sharma Labels: function calling Dan Garcia from the 3rd row! Data: anything in the .data section; variables which may be accessed across files Researchers at Princeton have developed a flexible electricity-producing sheet of rubber that can use body movements into electricity. Breathing generates 1 W, walking around the room generates 70 W. Shoes may be the best place, to power/recharge cell phones & iPods. www.nytimes.com/2010/03/02/science/02obribbon.html CS61C L19 : Running a Progam II … Compiling, Assembling, Linking, and Loading (3) Garcia, Spring 2010 © UCB Relocation Table Object File Format . List of “items” this file needs the address later. object file header: size and position of the other . What are they? pieces of the object file Any label jumped to: j or jal . text segment: the machine code internal . data segment: binary representation of the data in external (including lib files) the source file Any piece of data connected with an address . relocation information: identifies lines of code that such as the la instruction need to be “handled” . symbol table: list of this file’s labels and data that can be referenced . debugging information . A standard format is ELF (except MS) http://www.skyfree.org/linux/references/ELF_Format.pdf CS61C L19 : Running a Progam II … Compiling, Assembling, Linking, and Loading (4) Garcia, Spring 2010 © UCB CS61C L19 : Running a Progam II … Compiling, Assembling, Linking, and Loading (5) Garcia, Spring 2010 © UCB Where Are We Now? Linker (1/3) . -

Linkers and Loaders Do?
Linkers & Loaders by John R. Levine Table of Contents 1 Table of Contents Chapter 0: Front Matter ........................................................ 1 Dedication .............................................................................................. 1 Introduction ............................................................................................ 1 Who is this book for? ......................................................................... 2 Chapter summaries ............................................................................. 3 The project ......................................................................................... 4 Acknowledgements ............................................................................ 5 Contact us ........................................................................................... 6 Chapter 1: Linking and Loading ........................................... 7 What do linkers and loaders do? ............................................................ 7 Address binding: a historical perspective .............................................. 7 Linking vs. loading .............................................................................. 10 Tw o-pass linking .............................................................................. 12 Object code libraries ........................................................................ 15 Relocation and code modification .................................................... 17 Compiler Drivers ................................................................................. -
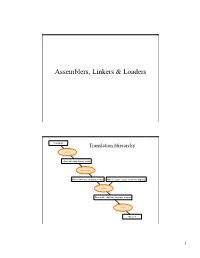
Assemblers, Linkers & Loaders
Assemblers, Linkers & Loaders C program Translation Hierarchy Compiler Assembly language program Assembler Object: Machine language module Object: Library routine (machine language) Linker Executable: Machine language program Loader Memory 1 Translation Hierarchy • Compiler – Translates high-level language program into assembly language (CS 440) • Assembler – Converts assembly language programs into object files • Object files contain a combination of machine instructions, data, and information needed to place instructions properly in memory Assemblers • Assemblers need to – translate assembly instructions and pseudo-instructions into machine instructions – Convert decimal numbers, etc. specified by programmer into binary • Typically, assemblers make two passes over the assembly file – First pass: reads each line and records labels in a symbol table – Second pass: use info in symbol table to produce actual machine code for each line 2 Object file format Object file Text Data Relocation Symbol Debugging header segment segment information table information • Object file header describes the size and position of the other pieces of the file • Text segment contains the machine instructions • Data segment contains binary representation of data in assembly file • Relocation info identifies instructions and data that depend on absolute addresses • Symbol table associates addresses with external labels and lists unresolved references • Debugging info Process for producing an executable file Source Object Assembler file file Source Object Executable Assembler file file Linker file Source Object Program Assembler file file library 3 Object file sub: · Object file · Executable file · Instructions main: main: jal ??? jal printf · · · · · · jal ??? jal sub printf: call, sub Linker · Relocation call, printf · records · sub: · C library · · print: · · · Linker • Tool that merges the object files produced by separate compilation or assembly and creates an executable file • Three tasks – Searches the program to find library routines used by program, e.g. -

An Evil Copy: How the Loader Betrays You
An Evil Copy: How the Loader Betrays You Xinyang Ge Mathias Payer Trent Jaeger Microsoft Research Purdue University The Pennsylvania State University [email protected] [email protected] [email protected] Abstract—Dynamic loading is a core feature used on current the value that is being written. Despite significant investment in systems to (i) enable modularity and reuse, (ii) reduce memory bug finding techniques, memory corruption is still an important footprint by sharing code pages of libraries and executables problem, as 745 individual CVEs for 2015 and 692 CVEs for among processes, and (iii) simplify update procedures by elim- 2016 are reported. While not all these vulnerabilities allow an inating the need to recompile executables when a library is attacker to compromise a system with arbitrary code execution, updated. The Executable and Linkable Format (ELF) is a generic many do. specification that describes how executable programs are stitched together from object files produced from source code to libraries Without any defense, attackers inject and execute code to and executables. Programming languages allow fine-grained con- trol over variables, including access and memory protections, so take control of a system through memory corruption vulner- programmers may write defense mechanisms assuming that the abilities. Over the past decade, a set of defense mechanisms permissions specified at the source and/or compiler level will hold have been deployed on commodity systems. Data execution at runtime. prevention [5] is a common defense that enforces code in- tegrity. Code integrity prohibits an attacker from injecting new Unfortunately, information about memory protection is lost code into a running process and is usually enforced by hard- during compilation. -

Assemblers, Linkers, and Loaders Hakim Weatherspoon CS 3410 Computer Science Cornell University
Assemblers, Linkers, and Loaders Hakim Weatherspoon CS 3410 Computer Science Cornell University [Weatherspoon, Bala, Bracy, and Sirer] Big Picture: Where are we going? C int x = 10; compiler x = 2 * x + 15; x0 = 0 x5 = x0 + 10 RISC‐V addi x5, x0, 10 muli x5, x5, 2 x5 = x5<<1 #x5 = x5 * 2 assembly addi x5, x5, 15 x5 = x15 + 15 assembler 10 r0 r5 op = addi 00000000101000000000001010010011 machine 00000000001000101000001010000000 code 00000000111100101000001010010011 15 r5 r5 op = addi CPU op = r-type x5 shamt=1 x5 func=sll Circuits 32 RF 32 Gates A B Transistors Silicon 2 Big Picture: Where are we going? C int x = 10; x = 2 * x + 15; compiler High Level RISC‐V addi x5, x0, 10 Languages muli x5, x5, 2 assembly addi x5, x5, 15 assembler 00000000101000000000001010010011 machine 00000000001000101000001010000000 code 00000000111100101000001010010011 Instruction Set CPU Architecture (ISA) Circuits Gates Transistors Silicon 3 From Writing to Running Compiler Assembler Linker gcc -S gcc -c gcc -o executable sum.c sum.s sum.o program C source assembly sum files obj files exists on files disk loader “It’s alive!” When most people say Executing “compile” they mean in the entire process: Memory compile + assemble + link process 4 Example: sum.c • Compiler output is assembly files • Assembler output is obj files • Linker joins object files into one executable • Loader brings it into memory and starts execution Example: sum.c #include <stdio.h> int n = 100; int main (int argc, char* argv[ ]) { int i; int m = n; int sum = 0; for (i = 1; i <= m; i++) { sum += i; } printf ("Sum 1 to %d is %d\n", n, sum); } 6 Compiler Input: Code File (.c) • Source code • #includes, function declarations & definitions, global variables, etc. -

SRM Firmware Howto SRM Firmware Howto
SRM Firmware Howto SRM Firmware Howto Table of Contents SRM Firmware Howto.......................................................................................................................................1 David Mosberger and Rich Payne...........................................................................................................1 1.What is SRM?.......................................................................................................................................1 2.The Raw Loader....................................................................................................................................1 3.The aboot Loader..................................................................................................................................1 4.Sharing a Disk With DEC Unix............................................................................................................2 5.Document History.................................................................................................................................2 1. What is SRM?......................................................................................................................................2 1.1 How Does SRM Boot an OS?............................................................................................................2 1.2 Loading The Secondary Bootstrap Loader........................................................................................2 2. The Raw Loader...................................................................................................................................3 -

Improved Architectures for Secure Intra-Process Isolation
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Doctoral Dissertations Graduate School 8-2021 Improved Architectures for Secure Intra-process Isolation Richard J. Connor III University of Tennessee, Knoxville, [email protected] Follow this and additional works at: https://trace.tennessee.edu/utk_graddiss Recommended Citation Connor, Richard J. III, "Improved Architectures for Secure Intra-process Isolation. " PhD diss., University of Tennessee, 2021. https://trace.tennessee.edu/utk_graddiss/6533 This Dissertation is brought to you for free and open access by the Graduate School at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Doctoral Dissertations by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. To the Graduate Council: I am submitting herewith a dissertation written by Richard J. Connor III entitled "Improved Architectures for Secure Intra-process Isolation." I have examined the final electronic copy of this dissertation for form and content and recommend that it be accepted in partial fulfillment of the requirements for the degree of Doctor of Philosophy, with a major in Computer Science. Austin Z. Henley, Major Professor We have read this dissertation and recommend its acceptance: Max Schuchard, Austin Henley, Michael Jantz, Scott Ruoti, Matthew Van Gundy Accepted for the Council: Dixie L. Thompson Vice Provost and Dean of the Graduate School (Original signatures are on file with official studentecor r ds.) Improved Architectures for Secure Intra-process Isolation A Dissertation Presented for the Doctor of Philosophy Degree The University of Tennessee, Knoxville Richard Joseph Connor August 2021 Table of Contents Chapter 1: Introduction1 1.1 Evaluating the Security of PKU-based Sandboxes.............. -

About Unix Shellcodes
Shellcode Generation Shellcode Encoding Examples About Unix Shellcodes Philippe BIONDI [email protected] / [email protected] EADS Corporate Research Center SSI Department Suresnes, FRANCE SyScAN 2004, Dec 16-17, 2004 Philippe BIONDI About Unix Shellcodes Shellcode Generation Shellcode Encoding Examples Outline 1 Introduction 2 Shellcode Generation Theory Practice 3 Shellcode Encoding Theory Practice 4 Examples Simple examples Advanced examples 5 Conclusion Philippe BIONDI About Unix Shellcodes Shellcode Generation Shellcode Encoding Examples Outline 1 Introduction 2 Shellcode Generation Theory Practice 3 Shellcode Encoding Theory Practice 4 Examples Simple examples Advanced examples 5 Conclusion Philippe BIONDI About Unix Shellcodes Shellcode Generation Shellcode Encoding Examples Shellcode, this strange animal... De¯nition of a shellcode (or egg) Executable that is used as a payload Usually out of any structure (ELF, PE, . ) Used to inject a raw set of instructions Usually spawns a shell Philippe BIONDI About Unix Shellcodes Shellcode Generation Shellcode Encoding Examples Injection vs Redirection Injection is easy (does not need any flaw) from an input (login, password, command, parameter, . ) from data read on disk from environment variables from shared memory injected with ptrace() (or other debug mechanism) injected by kernel . Execution flow redirection is hard (need a flaw to gain sth) bu®er overflow, format string, integer overflow, . debug privileges (ptrace(), . ), kernel Philippe BIONDI About Unix Shellcodes Shellcode Generation