Comparison of Advance Tree Data Structures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tree-Combined Trie: a Compressed Data Structure for Fast IP Address Lookup
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 6, No. 12, 2015 Tree-Combined Trie: A Compressed Data Structure for Fast IP Address Lookup Muhammad Tahir Shakil Ahmed Department of Computer Engineering, Department of Computer Engineering, Sir Syed University of Engineering and Technology, Sir Syed University of Engineering and Technology, Karachi Karachi Abstract—For meeting the requirements of the high-speed impact their forwarding capacity. In order to resolve two main Internet and satisfying the Internet users, building fast routers issues there are two possible solutions one is IPv6 IP with high-speed IP address lookup engine is inevitable. addressing scheme and second is Classless Inter-domain Regarding the unpredictable variations occurred in the Routing or CIDR. forwarding information during the time and space, the IP lookup algorithm should be able to customize itself with temporal and Finding a high-speed, memory-efficient and scalable IP spatial conditions. This paper proposes a new dynamic data address lookup method has been a great challenge especially structure for fast IP address lookup. This novel data structure is in the last decade (i.e. after introducing Classless Inter- a dynamic mixture of trees and tries which is called Tree- Domain Routing, CIDR, in 1994). In this paper, we will Combined Trie or simply TC-Trie. Binary sorted trees are more discuss only CIDR. In addition to these desirable features, advantageous than tries for representing a sparse population reconfigurability is also of great importance; true because while multibit tries have better performance than trees when a different points of this huge heterogeneous structure of population is dense. -

Heaps a Heap Is a Complete Binary Tree. a Max-Heap Is A
Heaps Heaps 1 A heap is a complete binary tree. A max-heap is a complete binary tree in which the value in each internal node is greater than or equal to the values in the children of that node. A min-heap is defined similarly. 97 Mapping the elements of 93 84 a heap into an array is trivial: if a node is stored at 90 79 83 81 index k, then its left child is stored at index 42 55 73 21 83 2k+1 and its right child at index 2k+2 01234567891011 97 93 84 90 79 83 81 42 55 73 21 83 CS@VT Data Structures & Algorithms ©2000-2009 McQuain Building a Heap Heaps 2 The fact that a heap is a complete binary tree allows it to be efficiently represented using a simple array. Given an array of N values, a heap containing those values can be built, in situ, by simply “sifting” each internal node down to its proper location: - start with the last 73 73 internal node * - swap the current 74 81 74 * 93 internal node with its larger child, if 79 90 93 79 90 81 necessary - then follow the swapped node down 73 * 93 - continue until all * internal nodes are 90 93 90 73 done 79 74 81 79 74 81 CS@VT Data Structures & Algorithms ©2000-2009 McQuain Heap Class Interface Heaps 3 We will consider a somewhat minimal maxheap class: public class BinaryHeap<T extends Comparable<? super T>> { private static final int DEFCAP = 10; // default array size private int size; // # elems in array private T [] elems; // array of elems public BinaryHeap() { . -

Podcast Ch23a
Podcast Ch23a • Title: Bit Arrays • Description: Overview; bit operations in Java; BitArray class • Participants: Barry Kurtz (instructor); John Helfert and Tobie Williams (students) • Textbook: Data Structures for Java; William H. Ford and William R. Topp Bit Arrays • Applications such as compiler code generation and compression algorithms create data that includes specific sequences of bits. – Many applications, such as compilers, generate specific sequences of bits. Bit Arrays (continued) • Java binary bit handling operators |, &, and ^ act on pairs of bits and return the new value. The unary operator ~ inverts the bits of its operand. BitBit OperationsOperations x y ~x x | y x & y x ^ y 0 0 1 0 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 1 0 1 1 0 Bit Arrays (continued) Bit Arrays (continued) • Operator << shifts integer or char values to the left. Operators >> and >>> shift values to the right using signed or unsigned arithmetic, respectively. Assume x and y are 32-bit integers. x = 0...10110110 x << 2 = 0...1011011000 x = 101...11011100 x >> 3 = 111101...11011 x = 101...11011100 x >>> 3 = 000101...11011 Bit Arrays (continued) Before performing the bitwise operator |, &, or ^, Java performs binary numeric promotion on the operands. The type of the bitwise operator expression is the promoted type of the operands. The rules of promotion are as follows: • If either operand is of type long, the other is converted to long. • Otherwise, both operands are converted to type int. In the case of the unary operator ~, Java converts a byte, char, short to int before applying the operator, and the resulting value is an int. -

Binary Search Tree
ADT Binary Search Tree! Ellen Walker! CPSC 201 Data Structures! Hiram College! Binary Search Tree! •" Value-based storage of information! –" Data is stored in order! –" Data can be retrieved by value efficiently! •" Is a binary tree! –" Everything in left subtree is < root! –" Everything in right subtree is >root! –" Both left and right subtrees are also BST#s! Operations on BST! •" Some can be inherited from binary tree! –" Constructor (for empty tree)! –" Inorder, Preorder, and Postorder traversal! •" Some must be defined ! –" Insert item! –" Delete item! –" Retrieve item! The Node<E> Class! •" Just as for a linked list, a node consists of a data part and links to successor nodes! •" The data part is a reference to type E! •" A binary tree node must have links to both its left and right subtrees! The BinaryTree<E> Class! The BinaryTree<E> Class (continued)! Overview of a Binary Search Tree! •" Binary search tree definition! –" A set of nodes T is a binary search tree if either of the following is true! •" T is empty! •" Its root has two subtrees such that each is a binary search tree and the value in the root is greater than all values of the left subtree but less than all values in the right subtree! Overview of a Binary Search Tree (continued)! Searching a Binary Tree! Class TreeSet and Interface Search Tree! BinarySearchTree Class! BST Algorithms! •" Search! •" Insert! •" Delete! •" Print values in order! –" We already know this, it#s inorder traversal! –" That#s why it#s called “in order”! Searching the Binary Tree! •" If the tree is -

Binary Index Trees a Cumulative Frequency Array Allows Us To
Binary Index Trees A cumulative frequency array allows us to calculate the sum of the range of values in O(1), as long as there are no changes to the data once the queries start. But consider situations where we might change the value at an index in an array, then query for the sum of a range of values in the array, followed by some more changes and more queries. In this sort of situation, a cumulative frequency array would still give us O(1) query times, but it would take O(n) time to update after each change!!! (Basically, if we change one index in a cumulative frequency array, all other indexes above it would have to have this value added to it as well.) Here is a quick illustration: Current cumulative frequency array: Index 0 1 2 3 4 5 6 7 8 Value 2 4 4 4 6 8 11 13 17 Now, consider adding the value 2 to the data, recalling that index i stores the number of values less than or equal to i. The adjusted array is: Index 0 1 2 3 4 5 6 7 8 Value 2 4 5 5 7 9 12 14 18 We had to edit each index 2 or greater, which would take O(n) for a cumulative frequency array of size n. Thus, we want a new arrangement where both the query AND the update are relatively fast. The creative insight here is that perhaps if we store data in a different way, perhaps we can reduce the update time by quite a bit while incurring only a modest increase in query time. -

Arxiv:Submit/0396732
Dynamic 3-sided Planar Range Queries with Expected Doubly Logarithmic Time⋆ Gerth Stølting Brodal1, Alexis C. Kaporis2, Apostolos N. Papadopoulos4, Spyros Sioutas3, Konstantinos Tsakalidis1, Kostas Tsichlas4 1 MADALGO⋆⋆, Department of Computer Science, Aarhus University, Denmark gerth,tsakalid @madalgo.au.dk 2 { } Computer Engineering and Informatics Department, University of Patras, Greece [email protected] 3 Department of Informatics, Ionian University, Corfu, Greece [email protected] 4 Department of Informatics, Aristotle University of Thessaloniki, Greece [email protected] Abstract. This work studies the problem of 2-dimensional searching for the 3-sided range query of the form [a,b] ( , c] in both main × −∞ and external memory, by considering a variety of input distributions. We present three sets of solutions each of which examines the 3-sided problem in both RAM and I/O model respectively. The presented data structures are deterministic and the expectation is with respect to the input distribution: (1) Under continuous µ-random distributions of the x and y coordinates, we present a dynamic linear main memory solution, which answers 3- sided queries in O(log n + t) worst case time and scales with O(log log n) expected with high probability update time, where n is the current num- ber of stored points and t is the size of the query output. We external- ize this solution, gaining O(logB n + t/B) worst case and O(logB logn) amortized expected with high probability I/Os for query and update operations respectively, where B is the disk block size. (2)Then, we assume that the inserted points have their x-coordinates drawn from a class of smooth distributions, whereas the y-coordinates are arbitrarily distributed. -

6.172 Lecture 19 : Cache-Oblivious B-Tree (Tokudb)
How TokuDB Fractal TreeTM Indexes Work Bradley C. Kuszmaul Guest Lecture in MIT 6.172 Performance Engineering, 18 November 2010. 6.172 —How Fractal Trees Work 1 My Background • I’m an MIT alum: MIT Degrees = 2 × S.B + S.M. + Ph.D. • I was a principal architect of the Connection Machine CM-5 super computer at Thinking Machines. • I was Assistant Professor at Yale. • I was Akamai working on network mapping and billing. • I am research faculty in the SuperTech group, working with Charles. 6.172 —How Fractal Trees Work 2 Tokutek A few years ago I started collaborating with Michael Bender and Martin Farach-Colton on how to store data on disk to achieve high performance. We started Tokutek to commercialize the research. 6.172 —How Fractal Trees Work 3 I/O is a Big Bottleneck Sensor Query Systems include Sensor Disk Query sensors and Sensor storage, and Query want to perform Millions of data elements arrive queries on per second Query recently arrived data using indexes. recent data. Sensor 6.172 —How Fractal Trees Work 4 The Data Indexing Problem • Data arrives in one order (say, sorted by the time of the observation). • Data is queried in another order (say, by URL or location). Sensor Query Sensor Disk Query Sensor Query Millions of data elements arrive per second Query recently arrived data using indexes. Sensor 6.172 —How Fractal Trees Work 5 Why Not Simply Sort? • This is what data Data Sorted by Time warehouses do. • The problem is that you Sort must wait to sort the data before querying it: Data Sorted by URL typically an overnight delay. -

B-Bit Sketch Trie: Scalable Similarity Search on Integer Sketches
b-Bit Sketch Trie: Scalable Similarity Search on Integer Sketches Shunsuke Kanda Yasuo Tabei RIKEN Center for Advanced Intelligence Project RIKEN Center for Advanced Intelligence Project Tokyo, Japan Tokyo, Japan [email protected] [email protected] Abstract—Recently, randomly mapping vectorial data to algorithms intending to build sketches of non-negative inte- strings of discrete symbols (i.e., sketches) for fast and space- gers (i.e., b-bit sketches) have been proposed for efficiently efficient similarity searches has become popular. Such random approximating various similarity measures. Examples are b-bit mapping is called similarity-preserving hashing and approximates a similarity metric by using the Hamming distance. Although minwise hashing (minhash) [12]–[14] for Jaccard similarity, many efficient similarity searches have been proposed, most of 0-bit consistent weighted sampling (CWS) for min-max ker- them are designed for binary sketches. Similarity searches on nel [15], and 0-bit CWS for generalized min-max kernel [16]. integer sketches are in their infancy. In this paper, we present Thus, developing scalable similarity search methods for b-bit a novel space-efficient trie named b-bit sketch trie on integer sketches is a key issue in large-scale applications of similarity sketches for scalable similarity searches by leveraging the idea behind succinct data structures (i.e., space-efficient data structures search. while supporting various data operations in the compressed Similarity searches on binary sketches are classified -

Compact Fenwick Trees for Dynamic Ranking and Selection
Compact Fenwick trees for dynamic ranking and selection Stefano Marchini Sebastiano Vigna Dipartimento di Informatica, Universit`adegli Studi di Milano, Italy October 15, 2019 Abstract The Fenwick tree [3] is a classical implicit data structure that stores an array in such a way that modifying an element, accessing an element, computing a prefix sum and performing a predecessor search on prefix sums all take logarithmic time. We introduce a number of variants which improve the classical implementation of the tree: in particular, we can reduce its size when an upper bound on the array element is known, and we can perform much faster predecessor searches. Our aim is to use our variants to implement an efficient dynamic bit vector: our structure is able to perform updates, ranking and selection in logarithmic time, with a space overhead in the order of a few percents, outperforming existing data structures with the same purpose. Along the way, we highlight the pernicious interplay between the arithmetic behind the Fenwick tree and the structure of current CPU caches, suggesting simple solutions that improve performance significantly. 1 Introduction The problem of building static data structures which perform rank and select operations on vectors of n bits in constant time using additional o(n) bits has received a great deal of attention in the last two decades starting form Jacobson's seminal work on succinct data structures. [7] The rank operator takes a position in the bit vector and returns the number of preceding ones. The select operation returns the position of the k-th one in the vector, given k. -
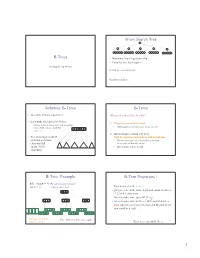
B-Trees M-Ary Search Tree Solution
M-ary Search Tree B-Trees • Maximum branching factor of M • Complete tree has height = Section 4.7 in Weiss # disk accesses for find : Runtime of find : 2 Solution: B-Trees B-Trees • specialized M-ary search trees What makes them disk-friendly? • Each node has (up to) M-1 keys: 1. Many keys stored in a node – subtree between two keys x and y contains leaves with values v such that • All brought to memory/cache in one access! 3 7 12 21 x ≤ v < y 2. Internal nodes contain only keys; • Pick branching factor M Only leaf nodes contain keys and actual data such that each node • The tree structure can be loaded into memory takes one full irrespective of data object size {page, block } x<3 3≤x<7 7≤x<12 12 ≤x<21 21 ≤x • Data actually resides in disk of memory 3 4 B-Tree: Example B-Tree Properties ‡ B-Tree with M = 4 (# pointers in internal node) and L = 4 (# data items in leaf) – Data is stored at the leaves – All leaves are at the same depth and contain between 10 40 L/2 and L data items – Internal nodes store up to M-1 keys 3 15 20 30 50 – Internal nodes have between M/2 and M children – Root (special case) has between 2 and M children (or root could be a leaf) 1 2 10 11 12 20 25 26 40 42 AB xG 3 5 6 9 15 17 30 32 33 36 50 60 70 Data objects, that I’ll Note: All leaves at the same depth! ignore in slides 5 ‡These are technically B +-Trees 6 1 Example, Again B-trees vs. -

AVL Trees and Rotations
/ AVL trees and rotations Q1 Operations (insert, delete, search) are O(height) Tree height is O(log n) if perfectly balanced ◦ But maintaining perfect balance is O(n) Height-balanced trees are still O(log n) ◦ For T with height h, N(T) ≤ Fib(h+3) – 1 ◦ So H < 1.44 log (N+2) – 1.328 * AVL (Adelson-Velskii and Landis) trees maintain height-balance using rotations Are rotations O(log n)? We’ll see… / or = or \ Different representations for / = \ : Just two bits in a low-level language Enum in a higher-level language / Assume tree is height-balanced before insertion Insert as usual for a BST Move up from the newly inserted node to the lowest “unbalanced” node (if any) ◦ Use the balance code to detect unbalance - how? Do an appropriate rotation to balance the sub-tree rooted at this unbalanced node For example, a single left rotation: Two basic cases ◦ “See saw” case: Too-tall sub-tree is on the outside So tip the see saw so it’s level ◦ “Suck in your gut” case: Too-tall sub-tree is in the middle Pull its root up a level Q2-3 Unbalanced node Middle sub-tree attaches to lower node of the “see saw” Diagrams are from Data Structures by E.M. Reingold and W.J. Hansen Q4-5 Unbalanced node Pulled up Split between the nodes pushed down Weiss calls this “right-left double rotation” Q6 Write the method: static BalancedBinaryNode singleRotateLeft ( BalancedBinaryNode parent, /* A */ BalancedBinaryNode child /* B */ ) { } Returns a reference to the new root of this subtree. -

Exponential Structures for Efficient Cache-Oblivious Algorithms
Exponential Structures for Efficient Cache-Oblivious Algorithms Michael A. Bender1, Richard Cole2, and Rajeev Raman3 1 Computer Science Department, SUNY Stony Brook, Stony Brook, NY 11794, USA. [email protected]. 2 Computer Science Department, Courant Institute, New York University, New York, NY 10012, USA. [email protected]. 3 Department of Mathematics and Computer Science, University of Leicester, Leicester LE1 7RH, UK. [email protected] Abstract. We present cache-oblivious data structures based upon exponential structures. These data structures perform well on a hierarchical memory but do not depend on any parameters of the hierarchy, including the block sizes and number of blocks at each level. The problems we consider are searching, partial persistence and planar point location. On a hierarchical memory where data is transferred in blocks of size B, some of the results we achieve are: – We give a linear-space data structure for dynamic searching that supports searches and updates in optimal O(logB N) worst-case I/Os, eliminating amortization from the result of Bender, Demaine, and Farach-Colton (FOCS ’00). We also consider finger searches and updates and batched searches. – We support partially-persistent operations on an ordered set, namely, we allow searches in any previous version of the set and updates to the latest version of the set (an update creates a new version of the set). All operations take an optimal O(logB (m+N)) amortized I/Os, where N is the size of the version being searched/updated, and m is the number of versions. – We solve the planar point location problem in linear space, taking optimal O(logB N) I/Os for point location queries, where N is the number of line segments specifying the partition of the plane.