Genome-Wide DNA Copy Number Analysis in Pancreatic Cancer Using High-Density Single Nucleotide Polymorphism Arrays
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Steroid-Dependent Regulation of the Oviduct: a Cross-Species Transcriptomal Analysis
University of Kentucky UKnowledge Theses and Dissertations--Animal and Food Sciences Animal and Food Sciences 2015 Steroid-dependent regulation of the oviduct: A cross-species transcriptomal analysis Katheryn L. Cerny University of Kentucky, [email protected] Right click to open a feedback form in a new tab to let us know how this document benefits ou.y Recommended Citation Cerny, Katheryn L., "Steroid-dependent regulation of the oviduct: A cross-species transcriptomal analysis" (2015). Theses and Dissertations--Animal and Food Sciences. 49. https://uknowledge.uky.edu/animalsci_etds/49 This Doctoral Dissertation is brought to you for free and open access by the Animal and Food Sciences at UKnowledge. It has been accepted for inclusion in Theses and Dissertations--Animal and Food Sciences by an authorized administrator of UKnowledge. For more information, please contact [email protected]. STUDENT AGREEMENT: I represent that my thesis or dissertation and abstract are my original work. Proper attribution has been given to all outside sources. I understand that I am solely responsible for obtaining any needed copyright permissions. I have obtained needed written permission statement(s) from the owner(s) of each third-party copyrighted matter to be included in my work, allowing electronic distribution (if such use is not permitted by the fair use doctrine) which will be submitted to UKnowledge as Additional File. I hereby grant to The University of Kentucky and its agents the irrevocable, non-exclusive, and royalty-free license to archive and make accessible my work in whole or in part in all forms of media, now or hereafter known. -

Supplemental Materials ZNF281 Enhances Cardiac Reprogramming
Supplemental Materials ZNF281 enhances cardiac reprogramming by modulating cardiac and inflammatory gene expression Huanyu Zhou, Maria Gabriela Morales, Hisayuki Hashimoto, Matthew E. Dickson, Kunhua Song, Wenduo Ye, Min S. Kim, Hanspeter Niederstrasser, Zhaoning Wang, Beibei Chen, Bruce A. Posner, Rhonda Bassel-Duby and Eric N. Olson Supplemental Table 1; related to Figure 1. Supplemental Table 2; related to Figure 1. Supplemental Table 3; related to the “quantitative mRNA measurement” in Materials and Methods section. Supplemental Table 4; related to the “ChIP-seq, gene ontology and pathway analysis” and “RNA-seq” and gene ontology analysis” in Materials and Methods section. Supplemental Figure S1; related to Figure 1. Supplemental Figure S2; related to Figure 2. Supplemental Figure S3; related to Figure 3. Supplemental Figure S4; related to Figure 4. Supplemental Figure S5; related to Figure 6. Supplemental Table S1. Genes included in human retroviral ORF cDNA library. Gene Gene Gene Gene Gene Gene Gene Gene Symbol Symbol Symbol Symbol Symbol Symbol Symbol Symbol AATF BMP8A CEBPE CTNNB1 ESR2 GDF3 HOXA5 IL17D ADIPOQ BRPF1 CEBPG CUX1 ESRRA GDF6 HOXA6 IL17F ADNP BRPF3 CERS1 CX3CL1 ETS1 GIN1 HOXA7 IL18 AEBP1 BUD31 CERS2 CXCL10 ETS2 GLIS3 HOXB1 IL19 AFF4 C17ORF77 CERS4 CXCL11 ETV3 GMEB1 HOXB13 IL1A AHR C1QTNF4 CFL2 CXCL12 ETV7 GPBP1 HOXB5 IL1B AIMP1 C21ORF66 CHIA CXCL13 FAM3B GPER HOXB6 IL1F3 ALS2CR8 CBFA2T2 CIR1 CXCL14 FAM3D GPI HOXB7 IL1F5 ALX1 CBFA2T3 CITED1 CXCL16 FASLG GREM1 HOXB9 IL1F6 ARGFX CBFB CITED2 CXCL3 FBLN1 GREM2 HOXC4 IL1F7 -

Redefining the Specificity of Phosphoinositide-Binding by Human
bioRxiv preprint doi: https://doi.org/10.1101/2020.06.20.163253; this version posted June 21, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC 4.0 International license. Redefining the specificity of phosphoinositide-binding by human PH domain-containing proteins Nilmani Singh1†, Adriana Reyes-Ordoñez1†, Michael A. Compagnone1, Jesus F. Moreno Castillo1, Benjamin J. Leslie2, Taekjip Ha2,3,4,5, Jie Chen1* 1Department of Cell & Developmental Biology, University of Illinois at Urbana-Champaign, Urbana, IL 61801; 2Department of Biophysics and Biophysical Chemistry, Johns Hopkins University School of Medicine, Baltimore, MD 21205; 3Department of Biophysics, Johns Hopkins University, Baltimore, MD 21218; 4Department of Biomedical Engineering, Johns Hopkins University, Baltimore, MD 21205; 5Howard Hughes Medical Institute, Baltimore, MD 21205, USA †These authors contributed equally to this work. *Correspondence: [email protected]. bioRxiv preprint doi: https://doi.org/10.1101/2020.06.20.163253; this version posted June 21, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC 4.0 International license. ABSTRACT Pleckstrin homology (PH) domains are presumed to bind phosphoinositides (PIPs), but specific interaction with and regulation by PIPs for most PH domain-containing proteins are unclear. Here we employed a single-molecule pulldown assay to study interactions of lipid vesicles with full-length proteins in mammalian whole cell lysates. -
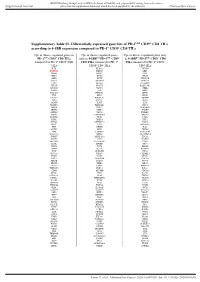
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al. -

Myopia in African Americans Is Significantly Linked to Chromosome 7P15.2-14.2
Genetics Myopia in African Americans Is Significantly Linked to Chromosome 7p15.2-14.2 Claire L. Simpson,1,2,* Anthony M. Musolf,2,* Roberto Y. Cordero,1 Jennifer B. Cordero,1 Laura Portas,2 Federico Murgia,2 Deyana D. Lewis,2 Candace D. Middlebrooks,2 Elise B. Ciner,3 Joan E. Bailey-Wilson,1,† and Dwight Stambolian4,† 1Department of Genetics, Genomics and Informatics and Department of Ophthalmology, University of Tennessee Health Science Center, Memphis, Tennessee, United States 2Computational and Statistical Genomics Branch, National Human Genome Research Institute, National Institutes of Health, Baltimore, Maryland, United States 3The Pennsylvania College of Optometry at Salus University, Elkins Park, Pennsylvania, United States 4Department of Ophthalmology, University of Pennsylvania, Philadelphia, Pennsylvania, United States Correspondence: Joan E. PURPOSE. The purpose of this study was to perform genetic linkage analysis and associ- Bailey-Wilson, NIH/NHGRI, 333 ation analysis on exome genotyping from highly aggregated African American families Cassell Drive, Suite 1200, Baltimore, with nonpathogenic myopia. African Americans are a particularly understudied popula- MD 21131, USA; tion with respect to myopia. [email protected]. METHODS. One hundred six African American families from the Philadelphia area with a CLS and AMM contributed equally to family history of myopia were genotyped using an Illumina ExomePlus array and merged this work and should be considered co-first authors. with previous microsatellite data. Myopia was initially measured in mean spherical equiv- JEB-W and DS contributed equally alent (MSE) and converted to a binary phenotype where individuals were identified as to this work and should be affected, unaffected, or unknown. -

Targeting PH Domain Proteins for Cancer Therapy
The Texas Medical Center Library DigitalCommons@TMC The University of Texas MD Anderson Cancer Center UTHealth Graduate School of The University of Texas MD Anderson Cancer Biomedical Sciences Dissertations and Theses Center UTHealth Graduate School of (Open Access) Biomedical Sciences 12-2018 Targeting PH domain proteins for cancer therapy Zhi Tan Follow this and additional works at: https://digitalcommons.library.tmc.edu/utgsbs_dissertations Part of the Bioinformatics Commons, Medicinal Chemistry and Pharmaceutics Commons, Neoplasms Commons, and the Pharmacology Commons Recommended Citation Tan, Zhi, "Targeting PH domain proteins for cancer therapy" (2018). The University of Texas MD Anderson Cancer Center UTHealth Graduate School of Biomedical Sciences Dissertations and Theses (Open Access). 910. https://digitalcommons.library.tmc.edu/utgsbs_dissertations/910 This Dissertation (PhD) is brought to you for free and open access by the The University of Texas MD Anderson Cancer Center UTHealth Graduate School of Biomedical Sciences at DigitalCommons@TMC. It has been accepted for inclusion in The University of Texas MD Anderson Cancer Center UTHealth Graduate School of Biomedical Sciences Dissertations and Theses (Open Access) by an authorized administrator of DigitalCommons@TMC. For more information, please contact [email protected]. TARGETING PH DOMAIN PROTEINS FOR CANCER THERAPY by Zhi Tan Approval page APPROVED: _____________________________________________ Advisory Professor, Shuxing Zhang, Ph.D. _____________________________________________ -

Regulation and Function of the NFE2L3 (NRF3) Transcription Factor
Regulation and function of the NFE2L3 (NRF3) transcription factor in hematopoietic cells Joo Yeoun Park Department of Medicine Division of Experimental Medicine McGill University, Montreal August 2018 A thesis submitted to McGill University in partial fulfillment of the requirements of the degree of Master of Science Ó Joo Yeoun Park 2018 ABSTRACT Cap’n’collar (CNC) basic leucine zipper transcription factors are essential for regulating the activity of antioxidant and detoxification enzymes. Of particular interest is the last member of the family to be identified, NFE2L3 (Nuclear Factor, Erythroid 2 Like 3), also known as NRF3. Accumulating evidence suggests that NFE2L3 may play a role in cellular processes other than stress responses such as differentiation, inflammation and cell cycle control. Moreover, NFE2L3 expression is upregulated in many cancers, including hematopoietic malignancies. However, the function and the regulation of NFE2L3 in hematopoietic cells still remain elusive. In the first part of the thesis, we addressed the question of whether NFE2L3 plays an oncogenic or a tumor suppressive role in hematopoietic cells by examining the mutations found in diffuse large B cell lymphoma (DLBCL) patient samples, one of the cancers in which NFE2L3 is highly expressed. We showed that the mutations found in DLBCL do not alter the transactivation capacity of NFE2L3 but database analysis suggests it would be worthwhile to examine the effect of NFE2L3 overexpression in cancer. We also investigated the role of NFE2L3 in hematopoiesis using a Nfe2l3-deficient (Nfe2l3-/-) mouse model. Examination of fully differentiated hematopoietic cells between the knockout and the wildtype mice revealed that the absence of NFE2L3 does not lead to major abnormalities, yet some minimal differences in erythroid-related parameters are noted. -

Human Induced Pluripotent Stem Cell–Derived Podocytes Mature Into Vascularized Glomeruli Upon Experimental Transplantation
BASIC RESEARCH www.jasn.org Human Induced Pluripotent Stem Cell–Derived Podocytes Mature into Vascularized Glomeruli upon Experimental Transplantation † Sazia Sharmin,* Atsuhiro Taguchi,* Yusuke Kaku,* Yasuhiro Yoshimura,* Tomoko Ohmori,* ‡ † ‡ Tetsushi Sakuma, Masashi Mukoyama, Takashi Yamamoto, Hidetake Kurihara,§ and | Ryuichi Nishinakamura* *Department of Kidney Development, Institute of Molecular Embryology and Genetics, and †Department of Nephrology, Faculty of Life Sciences, Kumamoto University, Kumamoto, Japan; ‡Department of Mathematical and Life Sciences, Graduate School of Science, Hiroshima University, Hiroshima, Japan; §Division of Anatomy, Juntendo University School of Medicine, Tokyo, Japan; and |Japan Science and Technology Agency, CREST, Kumamoto, Japan ABSTRACT Glomerular podocytes express proteins, such as nephrin, that constitute the slit diaphragm, thereby contributing to the filtration process in the kidney. Glomerular development has been analyzed mainly in mice, whereas analysis of human kidney development has been minimal because of limited access to embryonic kidneys. We previously reported the induction of three-dimensional primordial glomeruli from human induced pluripotent stem (iPS) cells. Here, using transcription activator–like effector nuclease-mediated homologous recombination, we generated human iPS cell lines that express green fluorescent protein (GFP) in the NPHS1 locus, which encodes nephrin, and we show that GFP expression facilitated accurate visualization of nephrin-positive podocyte formation in -

Identification of Expression Qtls Targeting Candidate Genes For
ISSN: 2378-3648 Salleh et al. J Genet Genome Res 2018, 5:035 DOI: 10.23937/2378-3648/1410035 Volume 5 | Issue 1 Journal of Open Access Genetics and Genome Research RESEARCH ARTICLE Identification of Expression QTLs Targeting Candidate Genes for Residual Feed Intake in Dairy Cattle Using Systems Genomics Salleh MS1,2, Mazzoni G2, Nielsen MO1, Løvendahl P3 and Kadarmideen HN2,4* 1Department of Veterinary and Animal Sciences, Faculty of Health and Medical Sciences, University of Copenhagen, Denmark Check for 2Department of Bio and Health Informatics, Technical University of Denmark, Lyngby, Denmark updates 3Department of Molecular Biology and Genetics-Center for Quantitative Genetics and Genomics, Aarhus University, AU Foulum, Tjele, Denmark 4Department of Applied Mathematics and Computer Science, Technical University of Denmark, Lyngby, Denmark *Corresponding author: Kadarmideen HN, Department of Applied Mathematics and Computer Science, Technical University of Denmark, DK-2800, Kgs. Lyngby, Denmark, E-mail: [email protected] Abstract body weight gain and net merit). The eQTLs and biological pathways identified in this study improve our understanding Background: Residual feed intake (RFI) is the difference of the complex biological and genetic mechanisms that de- between actual and predicted feed intake and an important termine FE traits in dairy cattle. The identified eQTLs/genet- factor determining feed efficiency (FE). Recently, 170 can- ic variants can potentially be used in new genomic selection didate genes were associated with RFI, but no expression methods that include biological/functional information on quantitative trait loci (eQTL) mapping has hitherto been per- SNPs. formed on FE related genes in dairy cows. In this study, an integrative systems genetics approach was applied to map Keywords eQTLs in Holstein and Jersey cows fed two different diets to eQTL, RNA-seq, Genotype, Data integration, Systems improve identification of candidate genes for FE. -

Three-Dimensional Regulation of HOXA Cluster Genes by a Cis-Element in Hematopoietic Stem Cell and Leukemia
bioRxiv preprint doi: https://doi.org/10.1101/2020.04.16.017533; this version posted April 18, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Three-dimensional regulation of HOXA cluster genes by a cis-element in hematopoietic stem cell and leukemia. Xue Qing David Wang1, Haley Gore1, Pamela Himadewi1, Fan Feng2, Lu Yang3, Wanding Zhou1,5, Yushuai Liu1, Xinyu Wang4, Chun-wei Chen3, Jianzhong Su4, Jie Liu2, Gerd Pfeifer1,*, Xiaotian Zhang1,* 1. Center for Epigenetics, Van Andel Research Institute, Grand Rapids, Michigan 2. Department of Computational Medicine and Bioinformatics, University of Michigan, Ann Arbor, Michigan. 3. Department of System Biology, City of Hope Cancer Center, California 4. Institute of Biomedical Big Data, Wenzhou Medical University, Wenzhou, China 5. Current address: Children Hospital of Philadelphia, University of Pennsylvania *. These authors jointly supervise this project Correspondence should be addressed to Xiaotian Zhang: [email protected] bioRxiv preprint doi: https://doi.org/10.1101/2020.04.16.017533; this version posted April 18, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Abstract: Proper gene regulation is crucial for cellular differentiation, and dysregulation of key genes can lead to diseased states such as cancer. The HOX transcription factors play such a role during hematopoiesis, and aberrant expression of certain HOXA genes is found in certain acute myeloid leukemias (AMLs). -

A Multilevel Screening Strategy Defines a Molecular Fingerprint Of
11116 • The Journal of Neuroscience, July 3, 2013 • 33(27):11116–11135 Development/Plasticity/Repair A Multilevel Screening Strategy Defines a Molecular Fingerprint of Proregenerative Olfactory Ensheathing Cells and Identifies SCARB2, a Protein That Improves Regenerative Sprouting of Injured Sensory Spinal Axons Kasper C. D. Roet,1* Elske H. P. Franssen,1* Frederik M. de Bree,1 Anke H. W. Essing,1 Sjirk-Jan J. Zijlstra,1 Nitish D. Fagoe,1 Hannah M. Eggink,1 Ruben Eggers,1 August B. Smit,2 Ronald E. van Kesteren,2 and Joost Verhaagen1,2 1Department of Neuroregeneration, Netherlands Institute for Neuroscience, An Institute of the Royal Netherlands Academy of Arts and Sciences, 1105 BA Amsterdam, The Netherlands, and 2Department of Molecular and Cellular Neurobiology, Center for Neurogenomics and Cognitive Research, Neuroscience Campus Amsterdam, VU University, 1081 HV Amsterdam, The Netherlands Olfactory ensheathing cells (OECs) have neuro-restorative properties in animal models for spinal cord injury, stroke, and amyotrophic lateral sclerosis. Here we used a multistep screening approach to discover genes specifically contributing to the regeneration-promoting properties of OECs. Microarray screening of the injured olfactory pathway and of cultured OECs identified 102 genes that were subse- quently functionally characterized in cocultures of OECs and primary dorsal root ganglion (DRG) neurons. Selective siRNA-mediated knockdown of 16 genes in OECs (ADAMTS1, BM385941, FZD1, GFRA1, LEPRE1, NCAM1, NID2, NRP1, MSLN, RND1, S100A9, SCARB2, SERPINI1, SERPINF1, TGFB2, and VAV1) significantly reduced outgrowth of cocultured DRG neurons, indicating that endogenous expression of these genes in OECs supports neurite extension of DRG neurons. In a gain-of-function screen for 18 genes, six (CX3CL1, FZD1, LEPRE1, S100A9, SCARB2, and SERPINI1) enhanced and one (TIMP2) inhibited neurite growth. -

A TBR1-K228E Mutation Induces Tbr1 Upregulation, Altered Cortical
ORIGINAL RESEARCH published: 09 October 2019 doi: 10.3389/fnmol.2019.00241 A TBR1-K228E Mutation Induces Tbr1 Upregulation, Altered Cortical Distribution of Interneurons, Increased Inhibitory Synaptic Transmission, and Autistic-Like Behavioral Deficits in Mice Chaehyun Yook 1, Kyungdeok Kim 1, Doyoun Kim 2, Hyojin Kang 3, Sun-Gyun Kim 2, Eunjoon Kim 1,2* and Soo Young Kim 4* 1Department of Biological Sciences, Korea Advanced Institute for Science and Technology (KAIST), Daejeon, South Korea, 2Center for Synaptic Brain Dysfunctions, Institute for Basic Science (IBS), Daejeon, South Korea, 3Division of National 4 Edited by: Supercomputing, Korea Institute of Science and Technology Information (KISTI), Daejeon, South Korea, College of Se-Young Choi, Pharmacy, Yeongnam University, Gyeongsan, South Korea Seoul National University, South Korea Mutations in Tbr1, a high-confidence ASD (autism spectrum disorder)-risk gene Reviewed by: encoding the transcriptional regulator TBR1, have been shown to induce diverse Carlo Sala, Institute of Neuroscience (CNR), Italy ASD-related molecular, synaptic, neuronal, and behavioral dysfunctions in mice. Lin Mei, However, whether Tbr1 mutations derived from autistic individuals cause similar Department of Neuroscience, School of Medicine, Case Western Reserve dysfunctions in mice remains unclear. Here we generated and characterized mice University, United States carrying the TBR1-K228E de novo mutation identified in human ASD and identified *Correspondence: various ASD-related phenotypes. In heterozygous mice carrying this mutation Eunjoon Kim =K228E (Tbr1C mice), levels of the TBR1-K228E protein, which is unable to bind target [email protected] =K228E Soo Young Kim DNA, were strongly increased. RNA-Seq analysis of the Tbr1C embryonic brain [email protected] indicated significant changes in the expression of genes associated with neurons, =K228E astrocytes, ribosomes, neuronal synapses, and ASD risk.