Gou, Zaiyong, Ph.D
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Political History of X Or How I Stopped Worrying and Learned to Love the GPL
A Political History of X or How I Stopped Worrying and Learned to Love the GPL Keith Packard SiFive [email protected] Unix in !"# ● $SD Everywhere – $'t not actually BS% ● )*+* want, to make Sy,tem V real – S'rely they still matter ● .o Free So/tware Anywhere The 0rigins of 1 ● $rian Reid and Pa'l Asente at Stan/ord – - kernel → VGTS → W window system – Ported to VS100 at Stan/ord ● $o4 Scheifler started hacking W→ X – Working on Argus with Barbara Liskov at LCS – 7ade it more Unix friendly (async9, renamed X -AXstation 00 (aka v, 339 Unix Workstation Market ● Unix wa, closed source ● Most vendors ,hipped a proprietary 0S 4ased on $SD #.x ● S'n: HP: Digita(: )po((o: *ektronix: I$7 ● ;congratu(ation,: yo'<re not running &'nice=. – Stil(: so many gratuito', di/ference, -AXstation II S'n >?@3 Early Unix Window Systems ● S'n-iew dominated (act'al commercial app,A De,ktop widget,A9 ● %igital had -WS/UIS (V7S on(y9 ● )pollo had %omain ● *ektronix demon,trating Sma((*alk 1 B1@ ● .onB/ree so/tware ● U,ed internally at MIT ● Shared with friend, in/ormally 1 3 ● )(mo,t u,able ● %elivered by Digital on V)1,tation, ● %i,trib'tion was not all free ,o/tware – Sun port relied on Sun-iew kernel API – %igital provided binary rendering code – IB7 PC?2T support act'ally complete (C9 Why 1 C ● 1 0 had wart, – rendering model was pretty terrible ● ,adly, X1 wa,n't m'ch better... – External window management witho't borders ● Get everyone involved – Well, at lea,t every workstation vendor willing to write big checks X as Corporate *ool ● Dim Gettys and Smokey -

MSU Extension Publication Archive Scroll Down to View
MSU Extension Publication Archive Archive copy of publication, do not use for current recommendations. Up-to-date information about many topics can be obtained from your local Extension office. Your Community and Township Zoning Michigan State University Agricultural Experiment Station Circular Bulletin Louis A. Wolfanger, Issued February 1945 49 pages The PDF file was provided courtesy of the Michigan State University Library Scroll down to view the publication. C IRCL' lAR BCllETI!': ltH FEBRCARY 194~ CLARE COUNTY COOPERf,T:VE E~;nT~SjON SERVI CE y our Comm~~~ty R~~d TOWNSHIP ZONING 13)' LOllis A.. Wolfanger " If yu u lIH' /J lulLlLin /S for OIlL' .\',,-'(0", .t.: l"OIl' gnAiu, J 1/ you aTe /) IUlIlIiug ior fl'n ycu rs, ISf'OW U"ees. I f yo u (0' (' ,,fnnn i ll ,\! [01" (l IllOlclTed :,\'ears, gl'OH' 1111'11. " - Cltillc.'.c Pr01 'CI'" MICHIGAN STATE COLLEGE:: AGRICULTURAL EXPERIMENT STATION SECTIONS OF SOIL SCIENCE AND CONSERVATION INSTITUTE FAST LANS I NC A \': Ollllll i u ('c l lf local leaders disc uss in!.!: ~'o ml11l1n i r \' L,nd-u!'l t" rrohlem ... ( l'hnt I1: .\ \ \ . ()ttcrht,iTI ,/c'ri,d l'I/ilIIJ.'fi" ,, /, 11 1111 1" ',1 /" I . , 1, 'ri,,1 , ', ,",,' 0/ UII !ll jl'idl li llr,,! " r,(i II Cli r (/ cily ill SIIIIIII!' rll .II !cit il/ull ill tit " /, r occs" ui iI"" 'I' /O/, III .'/ 11 ,\ (/ rllr(/I r cslilI'II(,( ('(lIIIIIIII II il\', Fit c silr/u(,' is 1f/lillIl" lill!/ III I/c ll tly r " lliliq . Fit,. /,roil II 1'1 i7'< ' .wi!. -

Xview Developer's Notes
XView Developer’s Notes 2550 Garcia Avenue Mountain View, CA 94043 U.S.A. A Sun Microsystems, Inc. Business 1994 Sun Microsystems, Inc. 2550 Garcia Avenue, Mountain View, California 94043-1100 U.S.A. All rights reserved. This product and related documentation are protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or related documentation may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Portions of this product may be derived from the UNIX® and Berkeley 4.3 BSD systems, licensed from UNIX System Laboratories, Inc., a wholly owned subsidiary of Novell, Inc., and the University of California, respectively. Third-party font software in this product is protected by copyright and licensed from Sun’s font suppliers. RESTRICTED RIGHTS LEGEND: Use, duplication, or disclosure by the United States Government is subject to the restrictions set forth in DFARS 252.227-7013 (c)(1)(ii) and FAR 52.227-19. The product described in this manual may be protected by one or more U.S. patents, foreign patents, or pending applications. TRADEMARKS Sun, the Sun logo, Sun Microsystems, Sun Microsystems Computer Corporation, SunSoft, the SunSoft logo, Solaris, SunOS, OpenWindows, DeskSet, ONC, ONC+, and NFS are trademarks or registered trademarks of Sun Microsystems, Inc. in the U.S. and certain other countries. UNIX is a registered trademark of Novell, Inc., in the United States and other countries; X/Open Company, Ltd., is the exclusive licensor of such trademark. OPEN LOOK® is a registered trademark of Novell, Inc. -
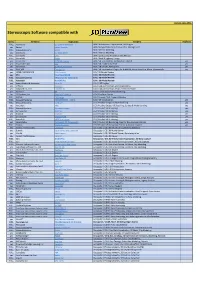
Stereo Software List
Version: June 2021 Stereoscopic Software compatible with Stereo Company Application Category Duplicate FULL Xeometric ELITECAD Architecture BIM / Architecture, Construction, CAD Engine yes Bexcel Bexcel Manager BIM / Design, Data, Project & Facilities Management FULL Dassault Systems 3DVIA BIM / Interior Modeling yes Xeometric ELITECAD Styler BIM / Interior Modeling FULL SierraSoft Land BIM / Land Survey Restitution and Analysis FULL SierraSoft Roads BIM / Road & Highway Design yes Xeometric ELITECAD Lumion BIM / VR Visualization, Architecture Models yes yes Fraunhofer IAO Vrfx BIM / VR enabled, for Revit yes yes Xeometric ELITECAD ViewerPRO BIM / VR Viewer, Free Option yes yes ENSCAPE Enscape 2.8 BIM / VR Visualization Plug-In for ArchiCAD, Revit, SketchUp, Rhino, Vectorworks yes yes OPEN CASCADE CAD CAD Assistant CAx / 3D Model Review yes PTC Creo View MCAD CAx / 3D Model Review FULL Dassault Systems eDrawings for Solidworks CAx / 3D Model Review FULL Autodesk NavisWorks CAx / 3D Model Review yes Robert McNeel & Associates. Rhino (5) CAx / CAD Engine yes Softvise Cadmium CAx / CAD, Architecture, BIM Visualization yes Gstarsoft Co., Ltd HaoChen 3D CAx / CAD, Architecture, HVAC, Electric & Power yes Siemens NX CAx / Construction & Manufacturing Yes 3D Systems, Inc. Geomagic Freeform CAx / Freeform Design FULL AVEVA E3D Design CAx / Process Plant, Power & Marine FULL Dassault Systems 3DEXPERIENCE - CATIA CAx / VR Visualization yes FULL Dassault Systems ICEM Surf CGI / Product Design, Surface Modeling yes yes Autodesk Alias CGI / Product -

Makerbot in the Classroom
COMPILED BY MAKERBOT EDUCATION Copyright © 2015 by MakerBot® www.makerbot.com All rights reserved. No part of this publication may be reproduced, distributed, or transmitted in any form or by any means, including photocopying, recording, or other electronic or mechanical methods, without the prior written permission of the publisher, except in the case of brief quotations embodied in critical reviews and certain other noncommercial uses permitted by copyright law. The information in this document concerning non-MakerBot products or services was obtained from the suppliers of those products or services or from their published announcements. Specific questions on the capabilities of non-MakerBot products and services should be addressed to the suppliers of those products and services. ISBN: 978-1-4951-6175-9 Printed in the United States of America First Edition 10 9 8 7 6 5 4 3 2 1 Compiled by MakerBot Education MakerBot Publishing • Brooklyn, NY TABLE OF CONTENTS 06 INTRODUCTION TO 3D PRINTING IN THE CLASSROOM 08 LESSON 1: INTRODUCTION TO 3D PRINTING 11 MakerBot Stories: Education 12 MakerBot Stories: Medical 13 MakerBot Stories: Business 14 MakerBot Stories: Post-Processing 15 MakerBot Stories: Design 16 LESSON 2: USING A 3D PRINTER 24 LESSON 3: PREPARING FILES FOR PRINTING 35 THREE WAYS TO MAKE 36 WAYS TO DOWNLOAD 40 WAYS TO SCAN 46 WAYS TO DESIGN 51 PROJECTS AND DESIGN SOFTWARE 52 PROJECT: PRIMITIVE MODELING WITH TINKERCAD 53 Make Your Own Country 55 Explore: Modeling with Tinkercad 59 Investigate: Geography and Climates 60 Create: -

Open Windows Version 3 Installation and Start-Up Guide E 1991 by Sun Microsystems, Inc.-Printed in USA
Open Windows Version 3 Installation and Start-Up Guide e 1991 by Sun Microsystems, Inc.-Printed in USA. 2550 Garcia Avenue, Mountain View, California 94043-1100 All rights reserved. No part of this work covered by copyright may be reproduced in any form or by any means-graphic, electronic or mechanical, including photocopying, recording, taping, or storage in an information retrieval system- without prior written permission of the copyright owner. The OPEN LOOK and the Sun Graphical User Interfaces were developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the com puter industry. Sun holds a non-exclusive license from Xerox to the Xerox Graphical User Interface, which license also covers Sun's licensees. RESTRICTED RIGHTS LEGEND: Use, duplication, or disclosure by the government is subject to restrictions as set forth in subparagraph (c)(1)(ii) of the Rights in Technical Data and Computer Software clause at DFARS 252.227-7013 (October 1988) and FAR 52.227-19 Oune 1987). The product described in this manual may be protected by one or more U.s. patents, foreign patents, and/or pending applications. TRADEMARKS Sun Logo, Sun Microsystems, NeWS, and NFS are registered trademarks, and SunSoft, SunSoft logo, SunOS, SunView, Sun-2, Sun-3, Sun-4, XGL, SunPHIGS, SunGKS, and OpenWindows are trademarks of SunMicrosystems, Inc. licensed to SunSoft, Inc. UNIX and OPEN LOOK are registered trademarks of UNIX System Laboratories, Inc. PostScript is a registered trademark of Adobe Systems Incorporated. -

Introduction
1 Introduction The X Window System was originally developed in the early 1980’s, and encompassed from the beginning many of the windowing capabilities that we now take for granted. While in a number of ways X was (and still is) command-line oriented, the capability of moving away from the command line was inherent from the very beginning in the architecture of the system. The advent of the desktop graphical user interface (GUI) didn’t require a major redesignof the X Window System. Figure 1-1 illustrates what an X desktop might have looked like in the early days. Figure 1-1: X desktop in the early days using twm But times have changed. Shown in Figure 1-2 is what a modern X desktop can now look like. This example uses the KDE Desktop Environment described later in Chapter 9, Using KDE. Figure 1-2: Modern X desktop using KDE Quite different in appearance--the more modern example has a fancier desktop and is visually more appealing--but technically there’s little difference between these examples. The X server still communicates with the X client via the X protocol over a network, and a window manager is still being used to manage the client application windows. The basics haven’t changed, just the frills. Part I of this book describes the underlying features of X that make it such a versatile and enduring system; Part II takes a look at some of the modern window managers and the two major desktop environments, GNOME and KDE; and Part III puts the theory, which sometimes needs configuration help and effort, into practice. -

Dust3d Documentation Release 1.0.0-Rc.1
dust3d Documentation Release 1.0.0-rc.1 Jeremyi HU Aug 10, 2021 Contents: 1 Getting Started 1 1.1 Download and Install Dust3D......................................1 1.2 Dust3D Interface Overview.......................................2 1.3 Menu Bar.................................................3 1.4 Parts Tree Panel.............................................7 1.5 Script Panel................................................ 10 1.6 Dust3D Shortcuts & Hotkey Guide................................... 11 1.7 Dust3D Script Reference......................................... 12 2 Dust3D Modeling Examples 23 2.1 Modeling Ant using Dust3D....................................... 23 2.2 Make a 3D model from scratch using Dust3D.............................. 26 2.3 Modeling Camel using Dust3D..................................... 26 2.4 Modeling Horse using Dust3D...................................... 27 3 For Developers 29 3.1 Building Dust3D............................................. 29 3.2 Write a 3D modeling software from scratch............................... 32 4 Indices and tables 41 i ii CHAPTER 1 Getting Started 1.1 Download and Install Dust3D • For Windows (64 Bit): https://github.com/huxingyi/dust3d/releases/download/1.0.0-rc.6/dust3d-1.0.0-rc.6.zip No need to install, unzip and run the exe. • For Windows (32 Bit): https://github.com/huxingyi/dust3d/releases/download/1.0.0-rc.6/dust3d-1.0.0-rc.6-x86.zip No need to install, unzip and run the exe. • For Mac OS X: https://github.com/huxingyi/dust3d/releases/download/1.0.0-rc.6/dust3d-1.0.0-rc.6.dmg If “The following disk images couldn’t be opened” popped up, that means the downloaded file was broken, please retry. If “can’t be opened because its integrity cannot be verified” popped up, please follow ni_kush’s answer in this reddit post. -

3D Computer Graphics Compiled By: H
animation Charge-coupled device Charts on SO(3) chemistry chirality chromatic aberration chrominance Cinema 4D cinematography CinePaint Circle circumference ClanLib Class of the Titans clean room design Clifford algebra Clip Mapping Clipping (computer graphics) Clipping_(computer_graphics) Cocoa (API) CODE V collinear collision detection color color buffer comic book Comm. ACM Command & Conquer: Tiberian series Commutative operation Compact disc Comparison of Direct3D and OpenGL compiler Compiz complement (set theory) complex analysis complex number complex polygon Component Object Model composite pattern compositing Compression artifacts computationReverse computational Catmull-Clark fluid dynamics computational geometry subdivision Computational_geometry computed surface axial tomography Cel-shaded Computed tomography computer animation Computer Aided Design computerCg andprogramming video games Computer animation computer cluster computer display computer file computer game computer games computer generated image computer graphics Computer hardware Computer History Museum Computer keyboard Computer mouse computer program Computer programming computer science computer software computer storage Computer-aided design Computer-aided design#Capabilities computer-aided manufacturing computer-generated imagery concave cone (solid)language Cone tracing Conjugacy_class#Conjugacy_as_group_action Clipmap COLLADA consortium constraints Comparison Constructive solid geometry of continuous Direct3D function contrast ratioand conversion OpenGL between -

1.1 X Client/Server
เดสกทอปลินุกซ เทพพิทักษ การุญบุญญานันท 2 สารบัญ 1 ระบบ X Window 5 1.1 ระบบ X Client/Server . 5 1.2 Window Manager . 6 1.3 Desktop Environment . 7 2 การปรับแตง GNOME 11 2.1 การติดตั้งฟอนต . 11 2.2 GConf . 12 2.3 การแสดงตัวอักษร . 13 2.4 พื้นหลัง . 15 2.5 Theme . 16 2.6 เมนู/ทูลบาร . 17 2.7 แปนพิมพ . 18 2.8 เมาส . 20 3 4 บทที่ 1 ระบบ X Window ระบบ GUI ที่อยูคูกับยูนิกซมมานานคือระบบ X Window ซึ่งพัฒนาโดยโครงการ Athena ที่ MIT รวมกับบริษัท Digital Equipment Corporation และบริษัทเอกชนจำนวนหนึ่ง ปจจุบัน X Window ดูแลโดย Open Group เปนระบบที่เปดทั้งในเรื่องโปรโตคอลและซอรสโคด ขณะที่เขียนเอกสารฉบับนี้ เวอรชันลาสุดของ X Window คือ เวอรชัน 11 รีลีส 6.6 (เรียกสั้นๆ วา X11R6.6) สำหรับลินุกซและระบบปฏิบัติการในตระกูลยูนิกซที่ทำงานบน PC ระบบ X Window ที่ใชจะมาจาก โครงการ XFree86 ซึ่งพัฒนาไดรเวอรสำหรับอุปกรณกราฟกตางๆ ที่ใชกับเครื่อง PC รุนลาสุดขณะที่ เขียนเอกสารนี้คือ 4.3.0 1.1 ระบบ X Client/Server X Window เปนระบบที่ทำงานผานระบบเครือขาย โดยแยกเปนสวน X client และ X server สื่อสาร กันผาน X protocol ดังนั้น โปรแกรมที่ทำงานบน X Window จะสามารถแสดงผลบนระบบปฏิบัติการ ที่ตางชนิดกันก็ได ตราบใดที่ระบบนั้นสามารถใหบริการผาน X protocol ได X client ไดแกโปรแกรมประยุกตตางๆ ที่จะขอใชบริการจาก X server ในการติดตอกับฮารดแวร เชน จอภาพ แปนพิมพ เมาส ฯลฯ ดังนั้น X server จึงทำงานอยูบนเครื่องที่อยูใกลผูใชเสมอ ในขณะที่ X client อาจอยูในเครื่องเดียวกันหรืออยูในเครื่องใดเครื่องหนึ่งในระบบเครือขายก็ได X client จะติดตอกับ X server ดวยการเรียก X library (เรียกสั้นๆ วา Xlib) API ตางๆ ใน Xlib มีหนาที่แปลงการเรียกฟงกชันแตละครั้งใหเปน request ในรูปของ X protocol เพื่อสงไปยัง X server -

UNM Branch Colleges
!e University of New Mexico Los Alamos CATALOG 2012-2013 Table of Contents Welcome ......................................7 Graduation Requirements......................35 Associate Degrees . 35 Academic Calendar ............................9 Certi"cates . 35 Second Certi"cate/Associate Degree. 35 Policies ......................................13 Extension and Independent Study . 35 Applicability . 13 Cooperative Education and Internships . 36 Anti-Harassment. 13 Catalog Requirements . 36 Equal Education Policy . 13 Readmission . 36 ADA Compliance and Reasonable Accommodation. 13 Responsibility for Requirements . 36 Non-Discrimination . 13 Commencement . 36 Dean’s List. 36 General Information ..........................15 New Mexico/WICHE . 37 Role and Function of UNM Branch Colleges . 15 Mission, Vision, Values, and Strategic Goals . 15 Student Services Information ...................39 Educational Programs . 16 Records . 39 Operating Agreement and Funding . 18 Residency . 43 Accreditation . 18 Mandatory Academic Advisement . 44 Student Outcomes Assessment . 18 Schedule of Classes . 44 History of UNM–Los Alamos . 18 Registration Procedures . 44 Location. 19 Finding Out About UNM–LA . 47 Faculty. 19 Facilities. 20 General Academic Regulations..................49 Student Housing . 20 Class Hours and Credit Hours . 49 Bookstore . 20 Course Numbering System . 49 Library . 20 Grades. 49 Accelerate Technical Training Program . 21 Academic Renewal Policy . 53 Classroom Conduct . 54 Admissions...................................23 Dishonesty in -

Next Versus Sun: a Comparison of Development Tools August 1992
NeXT versus Sun: a Comparison of Development Tools August 1992 NeXT versus Sun: a I. Introduction: Development Comparison of Architectures Several common elements exist in all modern Development Tools programming environments that are used to develop applications with graphical user interfaces (GUI): a Executive Summary window system, a toolkit, and a layout tool. Window System core functionality required to The tools used for developing applications on NeXT! and Sun" systems appear on the surface to be sim- display graphics on the screen ilar. Sun has many tools that serve roles similar to their and receive events from the NeXTstep! counterparts. On closer inspection, however, mouse and keyboard. the Sun tools are quite different. Toolkit precompiled user interface ele- Developers using both platforms have found that ments, including windows, Sun tools lack essential, timesaving features. NeXT pro- buttons and sliders. vides many features that can be used by applications with no additional work. Examples of these include standard Layout Tool a program that allows the de- dialogs, imaging, color and printer support, and a host of veloper to prototype the user others. On the Sun these features are difficult (or, in some interface graphically. The pro- cases, impossible) to implement. totype is then written in a form Finally, and perhaps most importantly, Sun’s tools are that the real application can be not object oriented. None of the toolkits are designed to built without writing the code work with an object oriented version of C. Customization that places the windows and of Sun’s tools is not done using any known Object-Ori- buttons on the screen.