Dbpedia Commons: Structured Multimedia Metadata from the Wikimedia Commons
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Wikipedia's Economic Value
WIKIPEDIA’S ECONOMIC VALUE Jonathan Band and Jonathan Gerafi policybandwidth In the copyright policy debate, proponents of strong copyright protection tend to be dismissive of the quality of freely available content. In response to counter- examples such as open access scholarly publications and advertising-supported business models (e.g., newspaper websites and the over-the-air television broadcasts viewed by 50 million Americans), the strong copyright proponents center their attack on amateur content. In this narrative, YouTube is for cat videos and Wikipedia is a wildly unreliable source of information. Recent studies, however, indicate that the volunteer-written and -edited Wikipedia is no less reliable than professionally edited encyclopedias such as the Encyclopedia Britannica.1 Moreover, Wikipedia has far broader coverage. Britannica, which discontinued its print edition in 2012 and now appears only online, contains 120,000 articles, all in English. Wikipedia, by contrast, has 4.3 million articles in English and a total of 22 million articles in 285 languages. Wikipedia attracts more than 470 million unique visitors a month who view over 19 billion pages.2 According to Alexa, it is the sixth most visited website in the world.3 Wikipedia, therefore, is a shining example of valuable content created by non- professionals. Is there a way to measure the economic value of this content? Because Wikipedia is created by volunteers, is administered by a non-profit foundation, and is distributed for free, the normal means of measuring value— such as revenue, market capitalization, and book value—do not directly apply. Nonetheless, there are a variety of methods for estimating its value in terms of its market value, its replacement cost, and the value it creates for its users. -

Position Description Addenda
POSITION DESCRIPTION January 2014 Wikimedia Foundation Executive Director - Addenda The Wikimedia Foundation is a radically transparent organization, and much information can be found at www.wikimediafoundation.org . That said, certain information might be particularly useful to nominators and prospective candidates, including: Announcements pertaining to the Wikimedia Foundation Executive Director Search Kicking off the search for our next Executive Director by Former Wikimedia Foundation Board Chair Kat Walsh An announcement from Wikimedia Foundation ED Sue Gardner by Wikimedia Executive Director Sue Gardner Video Interviews on the Wikimedia Community and Foundation and Its History Some of the values and experiences of the Wikimedia Community are best described directly by those who have been intimately involved in the organization’s dramatic expansion. The following interviews are available for viewing though mOppenheim.TV . • 2013 Interview with Former Wikimedia Board Chair Kat Walsh • 2013 Interview with Wikimedia Executive Director Sue Gardner • 2009 Interview with Wikimedia Executive Director Sue Gardner Guiding Principles of the Wikimedia Foundation and the Wikimedia Community The following article by Sue Gardner, the current Executive Director of the Wikimedia Foundation, has received broad distribution and summarizes some of the core cultural values shared by Wikimedia’s staff, board and community. Topics covered include: • Freedom and open source • Serving every human being • Transparency • Accountability • Stewardship • Shared power • Internationalism • Free speech • Independence More information can be found at: https://meta.wikimedia.org/wiki/User:Sue_Gardner/Wikimedia_Foundation_Guiding_Principles Wikimedia Policies The Wikimedia Foundation has an extensive list of policies and procedures available online at: http://wikimediafoundation.org/wiki/Policies Wikimedia Projects All major projects of the Wikimedia Foundation are collaboratively developed by users around the world using the MediaWiki software. -

Wikimedia Conferentie Nederland 2012 Conferentieboek
http://www.wikimediaconferentie.nl WCN 2012 Conferentieboek CC-BY-SA 9:30–9:40 Opening 9:45–10:30 Lydia Pintscher: Introduction to Wikidata — the next big thing for Wikipedia and the world Wikipedia in het onderwijs Technische kant van wiki’s Wiki-gemeenschappen 10:45–11:30 Jos Punie Ralf Lämmel Sarah Morassi & Ziko van Dijk Het gebruik van Wikimedia Commons en Wikibooks in Community and ontology support for the Wikimedia Nederland, wat is dat precies? interactieve onderwijsvormen voor het secundaire onderwijs 101wiki 11:45–12:30 Tim Ruijters Sandra Fauconnier Een passie voor leren, de Nederlandse wikiversiteit Projecten van Wikimedia Nederland in 2012 en verder Bliksemsessie …+discussie …+vragensessie Lunch 13:15–14:15 Jimmy Wales 14:30–14:50 Wim Muskee Amit Bronner Lotte Belice Baltussen Wikipedia in Edurep Bridging the Gap of Multilingual Diversity Open Cultuur Data: Een bottom-up initiatief vanuit de erfgoedsector 14:55–15:15 Teun Lucassen Gerard Kuys Finne Boonen Scholieren op Wikipedia Onderwerpen vinden met DBpedia Blijf je of ga je weg? 15:30–15:50 Laura van Broekhoven & Jan Auke Brink Jeroen De Dauw Jan-Bart de Vreede 15:55–16:15 Wetenschappelijke stagiairs vertalen onderzoek naar Structured Data in MediaWiki Wikiwijs in vergelijking tot Wikiversity en Wikibooks Wikipedia–lemma 16:20–17:15 Prijsuitreiking van Wiki Loves Monuments Nederland 17:20–17:30 Afsluiting 17:30–18:30 Borrel Inhoudsopgave Organisatie 2 Voorwoord 3 09:45{10:30: Lydia Pintscher 4 13:15{14:15: Jimmy Wales 4 Wikipedia in het onderwijs 5 11:00{11:45: Jos Punie -

Wikibase Knowledge Graphs for Data Management & Data Science
Business and Economics Research Data Center https://www.berd-bw.de Baden-Württemberg Wikibase knowledge graphs for data management & data science Dr. Renat Shigapov 23.06.2021 @shigapov @_shigapov DATA Motivation MANAGEMENT 1. people DATA SCIENCE knowledg! 2. processes information linking 3. technology data things KNOWLEDGE GRAPHS 2 DATA Flow MANAGEMENT Definitions DATA Wikidata & Tools SCIENCE Local Wikibase Wikibase Ecosystem Summary KNOWLEDGE GRAPHS 29.10.2012 2030 2021 3 DATA Example: Named Entity Linking SCIENCE https://commons.wikimedia.org/wiki/File:Entity_Linking_-_Short_Example.png Rule#$as!d problems Machine Learning De!' Learning Learn data science at https://www.kaggle.com 4 https://commons.wikimedia.org/wiki/File:Data_visualization_process_v1.png DATA Example: general MANAGEMENT research data silos data fabric data mesh data space data marketplace data lake data swamp Research data lifecycle https://www.reading.ac.uk/research-services/research-data-management/ 5 https://www.dama.org/cpages/body-of-knowledge about-research-data-management/the-research-data-lifecycle KNOWLEDGE ONTOLOG( + GRAPH = + THINGS https://www.mediawiki.org https://www.wikiba.se ✔ “Things, not strings” by Google, 2012 + ✔ A knowledge graph links things in different datasets https://mariadb.org https://blazegraph.com ✔ A knowledge graph can link people & relational database graph database processes and enhance technologies The main example: “THE KNOWLEDGE GRAPH COOKBOOK RECIPES THAT WORK” by ANDREAS BLUMAUER & HELMUT NAGY, 2020. https://www.wikidata.org -

Wiki-Reliability: a Large Scale Dataset for Content Reliability on Wikipedia
Wiki-Reliability: A Large Scale Dataset for Content Reliability on Wikipedia KayYen Wong∗ Miriam Redi Diego Saez-Trumper Outreachy Wikimedia Foundation Wikimedia Foundation Kuala Lumpur, Malaysia London, United Kingdom Barcelona, Spain [email protected] [email protected] [email protected] ABSTRACT Wikipedia is the largest online encyclopedia, used by algorithms and web users as a central hub of reliable information on the web. The quality and reliability of Wikipedia content is maintained by a community of volunteer editors. Machine learning and information retrieval algorithms could help scale up editors’ manual efforts around Wikipedia content reliability. However, there is a lack of large-scale data to support the development of such research. To fill this gap, in this paper, we propose Wiki-Reliability, the first dataset of English Wikipedia articles annotated with a wide set of content reliability issues. To build this dataset, we rely on Wikipedia “templates”. Tem- plates are tags used by expert Wikipedia editors to indicate con- Figure 1: Example of an English Wikipedia page with several tent issues, such as the presence of “non-neutral point of view” template messages describing reliability issues. or “contradictory articles”, and serve as a strong signal for detect- ing reliability issues in a revision. We select the 10 most popular 1 INTRODUCTION reliability-related templates on Wikipedia, and propose an effective method to label almost 1M samples of Wikipedia article revisions Wikipedia is one the largest and most widely used knowledge as positive or negative with respect to each template. Each posi- repositories in the world. People use Wikipedia for studying, fact tive/negative example in the dataset comes with the full article checking and a wide set of different information needs [11]. -

Towards a Korean Dbpedia and an Approach for Complementing the Korean Wikipedia Based on Dbpedia
Towards a Korean DBpedia and an Approach for Complementing the Korean Wikipedia based on DBpedia Eun-kyung Kim1, Matthias Weidl2, Key-Sun Choi1, S¨orenAuer2 1 Semantic Web Research Center, CS Department, KAIST, Korea, 305-701 2 Universit¨at Leipzig, Department of Computer Science, Johannisgasse 26, D-04103 Leipzig, Germany [email protected], [email protected] [email protected], [email protected] Abstract. In the first part of this paper we report about experiences when applying the DBpedia extraction framework to the Korean Wikipedia. We improved the extraction of non-Latin characters and extended the framework with pluggable internationalization components in order to fa- cilitate the extraction of localized information. With these improvements we almost doubled the amount of extracted triples. We also will present the results of the extraction for Korean. In the second part, we present a conceptual study aimed at understanding the impact of international resource synchronization in DBpedia. In the absence of any informa- tion synchronization, each country would construct its own datasets and manage it from its users. Moreover the cooperation across the various countries is adversely affected. Keywords: Synchronization, Wikipedia, DBpedia, Multi-lingual 1 Introduction Wikipedia is the largest encyclopedia of mankind and is written collaboratively by people all around the world. Everybody can access this knowledge as well as add and edit articles. Right now Wikipedia is available in 260 languages and the quality of the articles reached a high level [1]. However, Wikipedia only offers full-text search for this textual information. For that reason, different projects have been started to convert this information into structured knowledge, which can be used by Semantic Web technologies to ask sophisticated queries against Wikipedia. -
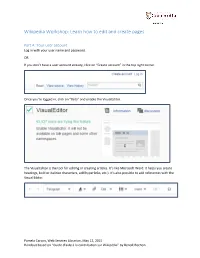
Wikipedia Workshop: Learn How to Edit and Create Pages
Wikipedia Workshop: Learn how to edit and create pages Part A: Your user account Log in with your user name and password. OR If you don’t have a user account already, click on “Create account” in the top right corner. Once you’re logged in, click on “Beta” and enable the VisualEditor. The VisualEditor is the tool for editing or creating articles. It’s like Microsoft Word: it helps you create headings, bold or italicize characters, add hyperlinks, etc.). It’s also possible to add references with the Visual Editor. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part B: Write a sentence or two about yourself Click on your username. This will lead you to your user page. The URL will be: https://en.wikipedia.org/wiki/User:[your user name] Exercise: Click on “Edit source” and write about yourself, then enter a description of your change in the “Edit summary” box and click “Save page”. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part C: Edit an existing article To edit a Wikipedia article, click on the tab “Edit” or “Edit source” (for more advanced users) available at the top of any page. These tabs are also available beside any section title within an article. Editing an entire page Editing just a section Need help? https://en.wikipedia.org/wiki/Wikipedia:Tutorial/Editing Exercise: Go to http://www.statcan.gc.ca/ and find a statistic that interests you. -

Chaudron: Extending Dbpedia with Measurement Julien Subercaze
Chaudron: Extending DBpedia with measurement Julien Subercaze To cite this version: Julien Subercaze. Chaudron: Extending DBpedia with measurement. 14th European Semantic Web Conference, Eva Blomqvist, Diana Maynard, Aldo Gangemi, May 2017, Portoroz, Slovenia. hal- 01477214 HAL Id: hal-01477214 https://hal.archives-ouvertes.fr/hal-01477214 Submitted on 27 Feb 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Chaudron: Extending DBpedia with measurement Julien Subercaze1 Univ Lyon, UJM-Saint-Etienne, CNRS Laboratoire Hubert Curien UMR 5516, F-42023, SAINT-ETIENNE, France [email protected] Abstract. Wikipedia is the largest collaborative encyclopedia and is used as the source for DBpedia, a central dataset of the LOD cloud. Wikipedia contains numerous numerical measures on the entities it describes, as per the general character of the data it encompasses. The DBpedia In- formation Extraction Framework transforms semi-structured data from Wikipedia into structured RDF. However this extraction framework of- fers a limited support to handle measurement in Wikipedia. In this paper, we describe the automated process that enables the creation of the Chaudron dataset. We propose an alternative extraction to the tra- ditional mapping creation from Wikipedia dump, by also using the ren- dered HTML to avoid the template transclusion issue. -

Wiki-Metasemantik: a Wikipedia-Derived Query Expansion Approach Based on Network Properties
Wiki-MetaSemantik: A Wikipedia-derived Query Expansion Approach based on Network Properties D. Puspitaningrum1, G. Yulianti2, I.S.W.B. Prasetya3 1,2Department of Computer Science, The University of Bengkulu WR Supratman St., Kandang Limun, Bengkulu 38371, Indonesia 3Department of Information and Computing Sciences, Utrecht University PO Box 80.089, 3508 TB Utrecht, The Netherlands E-mails: [email protected], [email protected], [email protected] Pseudo-Relevance Feedback (PRF) query expansions suffer Abstract- This paper discusses the use of Wikipedia for building from several drawbacks such as query-topic drift [8][10] and semantic ontologies to do Query Expansion (QE) in order to inefficiency [21]. Al-Shboul and Myaeng [1] proposed a improve the search results of search engines. In this technique, technique to alleviate topic drift caused by words ambiguity selecting related Wikipedia concepts becomes important. We and synonymous uses of words by utilizing semantic propose the use of network properties (degree, closeness, and pageRank) to build an ontology graph of user query concept annotations in Wikipedia pages, and enrich queries with which is derived directly from Wikipedia structures. The context disambiguating phrases. Also, in order to avoid resulting expansion system is called Wiki-MetaSemantik. We expansion of mistranslated words, a query expansion method tested this system against other online thesauruses and ontology using link texts of a Wikipedia page has been proposed [9]. based QE in both individual and meta-search engines setups. Furthermore, since not all hyperlinks are helpful for QE task Despite that our system has to build a Wikipedia ontology graph though (e.g. -
Building a Visual Editor for Wikipedia
Building a Visual Editor for Wikipedia Trevor Parscal and Roan Kattouw Wikimania D.C. 2012 (Introduce yourself) (Introduce yourself) We’d like to talk to you about how we’ve been building a visual editor for Wikipedia Trevor Parscal Roan Kattouw Rob Moen Lead Designer and Engineer Data Model Engineer User Interface Engineer Wikimedia Wikimedia Wikimedia Inez Korczynski Christian Williams James Forrester Edit Surface Engineer Edit Surface Engineer Product Analyst Wikia Wikia Wikimedia The People Wikimania D.C. 2012 We are only 2/6ths of the VisualEditor team Our team includes 2 engineers from Wikia - they also use MediaWiki They also fight crime in their of time Parsoid Team Gabriel Wicke Subbu Sastry Lead Parser Engineer Parser Engineer Wikimedia Wikimedia The People Wikimania D.C. 2012 There’s also two remote people working on a new parser This parser makes what we are doing with the VisualEditor possible The Project Wikimania D.C. 2012 You might recognize this, it’s a Wikipedia article You should edit it! Seems simple enough, just hit the edit button and be on your way... The Complexity Problem Wikimania D.C. 2012 Or not... What is all this nonsense you may ask? Well, it’s called Wikitext! Even really smart people who have a lot to contribute to Wikipedia find it confusing The truth is, Wikitext is a lousy IQ test, and it’s holding Wikipedia back, severely Active Editors 20k 0 2001 2007 Today Growth Stagnation The Complexity Problem Wikimania D.C. 2012 The internet has normal people on it now, not just geeks and weirdoes Normal people like simple things, and simple things are growing fast We must make editing Wikipedia easier to use, not just to grow, but even just to stay alive The Complexity Problem Wikimania D.C. -

Improving Knowledge Base Construction from Robust Infobox Extraction
Improving Knowledge Base Construction from Robust Infobox Extraction Boya Peng∗ Yejin Huh Xiao Ling Michele Banko∗ Apple Inc. 1 Apple Park Way Sentropy Technologies Cupertino, CA, USA {yejin.huh,xiaoling}@apple.com {emma,mbanko}@sentropy.io∗ Abstract knowledge graph created largely by human edi- tors. Only 46% of person entities in Wikidata A capable, automatic Question Answering have birth places available 1. An estimate of 584 (QA) system can provide more complete million facts are maintained in Wikipedia, not in and accurate answers using a comprehen- Wikidata (Hellmann, 2018). A downstream appli- sive knowledge base (KB). One important cation such as Question Answering (QA) will suf- approach to constructing a comprehensive knowledge base is to extract information from fer from this incompleteness, and fail to answer Wikipedia infobox tables to populate an ex- certain questions or even provide an incorrect an- isting KB. Despite previous successes in the swer especially for a question about a list of enti- Infobox Extraction (IBE) problem (e.g., DB- ties due to a closed-world assumption. Previous pedia), three major challenges remain: 1) De- work on enriching and growing existing knowl- terministic extraction patterns used in DBpe- edge bases includes relation extraction on nat- dia are vulnerable to template changes; 2) ural language text (Wu and Weld, 2007; Mintz Over-trusting Wikipedia anchor links can lead to entity disambiguation errors; 3) Heuristic- et al., 2009; Hoffmann et al., 2011; Surdeanu et al., based extraction of unlinkable entities yields 2012; Koch et al., 2014), knowledge base reason- low precision, hurting both accuracy and com- ing from existing facts (Lao et al., 2011; Guu et al., pleteness of the final KB. -

Navigating Dbpedia by Topic Tanguy Raynaud, Julien Subercaze, Delphine Boucard, Vincent Battu, Frederique Laforest
Fouilla: Navigating DBpedia by Topic Tanguy Raynaud, Julien Subercaze, Delphine Boucard, Vincent Battu, Frederique Laforest To cite this version: Tanguy Raynaud, Julien Subercaze, Delphine Boucard, Vincent Battu, Frederique Laforest. Fouilla: Navigating DBpedia by Topic. CIKM 2018, Oct 2018, Turin, Italy. hal-01860672 HAL Id: hal-01860672 https://hal.archives-ouvertes.fr/hal-01860672 Submitted on 23 Aug 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Fouilla: Navigating DBpedia by Topic Tanguy Raynaud, Julien Subercaze, Delphine Boucard, Vincent Battu, Frédérique Laforest Univ Lyon, UJM Saint-Etienne, CNRS, Laboratoire Hubert Curien UMR 5516 Saint-Etienne, France [email protected] ABSTRACT only the triples that concern this topic. For example, a user is inter- Navigating large knowledge bases made of billions of triples is very ested in Italy through the prism of Sports while another through the challenging. In this demonstration, we showcase Fouilla, a topical prism of Word War II. For each of these topics, the relevant triples Knowledge Base browser that offers a seamless navigational expe- of the Italy entity differ. In such circumstances, faceted browsing rience of DBpedia. We propose an original approach that leverages offers no solution to retrieve the entities relative to a defined topic both structural and semantic contents of Wikipedia to enable a if the knowledge graph does not explicitly contain an adequate topic-oriented filter on DBpedia entities.