Regression Analysis: an Evaluation of the Influences Behind the Pricing of Beer Regressionsanalys: En Utv¨Arderingav Influenserna Bakom Priss¨Attningen Av ¨Ol
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nordic Alcohol Policy in Europe: the Adaptation of Finland's, Sweden's and Norway's Alcohol
Thomas Karlsson Thomas Karlsson Thomas Karlsson Nordic Alcohol Policy Nordic Alcohol Policy in Europe in Europe The Adaptation of Finland’s, Sweden’s and Norway’s Alcohol Policies to a New Policy Framework, 1994–2013 The Adaptation of Finland’s, Sweden’s and Norway’s Alcohol Policies to a New Policy Framework, 1994–2013 Nordic Alcohol Policy in Europe Policy Alcohol Nordic To what extent have Finland, Sweden and Norway adapted their alcohol policies to the framework imposed on them by the European Union and the European Economic Area since the mid-1990s? How has alcohol policies in the Nordic countries evolved between 1994 and 2013 and how strict are their alcohol policies in comparison with the rest of Europe? These are some of the main research questions in this study. Besides alcohol policies, the analyses comprise the development of alcohol consumption and cross-border trade with alcohol. In addition to a qualitative analysis, a RESEARCH quantitative scale constructed to measure the strictness of alcohol policies is RESEARCH utilised. The results from the study clearly corroborate earlier findings on the significance of Europeanisation and the Single Market for the development of Nordic alcohol policy. All in all, alcohol policies in the Nordic countries are more liberal in 2013 than they were in 1994. The restrictive Nordic policy tradition has, however, still a solid evidence base and nothing prevents it from being the base for alcohol policy in the Nordic countries also in the future. National Institute for Health and Welfare P.O. -

The Swedish Alcohol Monopoly: a Bottleneck for Microbrewers in Sweden?
Cogent Social Sciences ISSN: (Print) (Online) Journal homepage: https://www.tandfonline.com/loi/oass20 The Swedish alcohol monopoly: A bottleneck for microbrewers in Sweden? Wilhelm Skoglund & John Selander | To cite this article: Wilhelm Skoglund & John Selander | (2021) The Swedish alcohol monopoly: A bottleneck for microbrewers in Sweden?, Cogent Social Sciences, 7:1, 1953769, DOI: 10.1080/23311886.2021.1953769 To link to this article: https://doi.org/10.1080/23311886.2021.1953769 © 2021 The Author(s). This open access article is distributed under a Creative Commons Attribution (CC-BY) 4.0 license. Published online: 03 Aug 2021. Submit your article to this journal Article views: 25 View related articles View Crossmark data Full Terms & Conditions of access and use can be found at https://www.tandfonline.com/action/journalInformation?journalCode=oass20 Skoglund & Selander, Cogent Social Sciences (2021), 7: 1953769 https://doi.org/10.1080/23311886.2021.1953769 LEISURE & TOURISM | RESEARCH ARTICLE The Swedish alcohol monopoly: A bottleneck for microbrewers in Sweden? Wilhelm Skoglund1* and John Selander1 Abstract: The evolution of the craft beer sector has been gaining traction around Received: 27 November 2020 Accepted: 06 July 2021 the world since the 1980s, developing from factors such as an increased demand *Corresponding author: Wilhelm for alternative and locally distinct flavours in beer, increased interest in pairing food Skoglund, Department of Economics, with the right type of beer, and increased income levels. Meanwhile, the economic Geography, Law and Tourism at Mid Sweden University, Sweden and political contexts for establishing and running craft breweries differ between E-mail: [email protected] cities, regions, and nations. -

Issues Review
Brewers Association 1327 Spruce Street Boulder, Colorado Export Development Program 80302 USA 303.447.0816 BrewersAssociation.org ® ISSUES REVIEW USDA Awards EDP Additional Grant Funding The United States Department of Agriculture (USDA) has awarded the EDP a $45,000 export assistance grant OCTOBER 2014 through its Emerging Markets Program. Funding may be used to conduct research on the Mexican beer market INSIDE THIS ISSUE and prepare a study for EDP members. The BA conducted a similar study in 2008. However, the Mexican market has developed significantly since that time, which has necessitated an update of the study. • USDA Awards EDP Additional Grant Funding This grant can be used through June 2015 and supplements funding that the EDP receives through USDA’s • EDP Participates in Market Access Program (MAP). MAP awards for 2015 have not yet been announced, but the BA expects that its Mexican Trade Mission allocation will be similar to 2014 ($600,895). • EDP Expands Craft Beer Awareness in China EDP Participates in Mexican Trade Mission In June, Mark Snyder joined representatives from nine breweries for a craft beer trade mission organized by • Great British Beer Festival USDA’s Agricultural Trade Office (ATO) in Mexico City. The trade mission was designed to educate breweries Highlighted by Beer Lunch about export opportunities in Mexico and introduce them to key retailers, buyers, and distributors. Over the course of three days, participants visited 10 on- and off-premise craft beer retailers and met with over a dozen • EDP’s 10th Anniversary importers and distributors. at the Stockholm Beer & Whiskey Festival Mexico is a promising market for American craft brewers, but there are significant issues with grey market imports and storage and handling practices. -

ABC for American Craft Beer
American Cra Beers in Sweden MICHEL JAMAIS Chef, sommelier and food & beverage manager 1980-1997. Wine, beer and spirit educator and restaurant consultant since 1992. Author of 14 books on wine, beer, spirits and food. Wine and beer writer since 1995. Beer teacher at Stockholm Beer & Whisky FesKval since 2005. • A brief background to Swedish beer culture • The knowledge about beer in Sweden • The success of fine wine – what can we learn? • Geng into the restaurants – how? • Reaching media and new consumers • Ideas how to market American craE beers A brief background • 1900 – approximately 1 200 small breweries all over Sweden • 1922 – strong beer (above 2.25% by volume) is prohibited – approximately 800 small breweries all over Sweden • 1955 – our state alcohol monopoly is established – 9 groups of breweries in Sweden • 1977 – our ”mellanöl” (3.50% by volume) is prohibited – only 4 groups of breweries survives • 1990s – the modern Swedish cra beer culture is born – around 20-25 breweries all over Sweden • 2000s – cra beers becomes a natural part of the Swedish beer culture – around 60-70 breweries and pub breweries all over Sweden Influences for Swedish beers • 1900-1990 – mainly Germany • lager beers • 1990s – mainly Great Britain • pale ales, bier ales – to a smaller extent Belgium and United States • slightly more flavorful and stronger beers – beers stronger than 6.00% by volume allowed only since 1997 • 2000s – the most important influences comes from United States • American pale ales, india pale ales, porters – richer, aromac and hoppy -

Non-Alcoholic Malt Beverage, 21 Entries Gold
Category 1: Non-Alcoholic Malt Beverage, 21 entries Category 25: Dortmunder/European Style Export or German-Style Gold: Radegast Birell, Plze ský Prazdroj a.s., Pilsen, Czech Republic Oktoberfest/Wiesen (Meadow), 48 entries Silver: Hefeweizen alkoholfrei, Alpirsbacher Klosterbräu Glauner GmbH & Co. KG, Gold: Luksus, JSC Aldaris, Riga, Latvia Alpirsbach, Germany Silver: Mariestads Export, Spendrups Brewery, Varby, Sweden Bronze: Organic Saps-Fit Sparkling Malt Drink, Neumarkter Lammsbräu Gebr. Ehrnsperger Bronze: Llano Lager, SandLot Brewery, Denver, CO e.K., Neumarkt, Germany Category 26: Vienna-Style Lager, 25 entries Category 2: American-Style Cream Ale or Lager, 23 entries Gold: Vienna Lager, The Covey Restaurant & Brewery, Fort Worth, TX Gold: Special Export, Pabst Brewing Co., Woodridge, IL Silver: Vienna Red Lager, Iron Hill Brewery & Restaurant, Wilmington, DE Silver: Lone Star, Pabst Brewing Co., Woodridge, IL Bronze: Lochsa Lager, Ram Restaurant & Brewery - Boise, Boise, ID Bronze: Nide Beer - The Ale, Baird Brewing Co., Numazu, Japan Category 27: German-Style Märzen, 28 entries Category 3: American-Style Wheat Beer, 14 entries Gold: Goss Märzen, Brauerei Goss, Deuerling, Germany Gold: Crystal Wheat Ale, Pyramid Breweries Inc., Seattle, WA Silver: Weltenburger Kloster Anno 1050, Klosterbrauerei Weltenburg GmbH, Kelheim, Germany Silver: Shiner Dunkelweizen, The Spoetzl Brewery, Shiner, TX Bronze: Latvijas Sevikais, JSC Aldaris, Riga, Latvia Bronze: Spanish Peaks Crystal Weiss, Spanish Peaks Brewing Co., Polson, MT Category 28: European-Style Dark/Münchner Dunkel, 38 entries Category 4: American-Style Hefeweizen, 34 entries Gold: Weltenburger Kloster Barock Dunkel, Klosterbrauerei Weltenburg GmbH, Kelheim, Gold: Widmer Hefeweizen, Widmer Brothers Brewing Co., Portland, OR Germany Silver: UFO Hefeweizen, Harpoon Brewery, Boston, MA Silver: Munich Dunkel, C.H. -

2004 Winners List
BREWERS ASSOCIATION PRESENTS World Beer Cup® 2004 Winners List Category: 1 Non-Alcoholic Malt Tonic, 3 Entries Category: 24 European-Style Dark/Münchner Dunkel, 29 Entries Silver: Power Malt Vanilla, The Danish Brewery Group, Inc., Miami, FL Gold: Weltenburger Kloster Barock Dunkel, Klosterbrauerei Weltenburg GmbH, Bronze: Xtra Malt, Samba Brewing Co., Trinidad, West Indies Kelheim, Germany Silver: Münchner Dunkel, Privatbrauerei Hofmühl, Eichstätt, Germany Category: 2 Non-Alcoholic (Beer) Malt Beverage, 18 Entries Bronze: Winter Brew, Sprecher Brewing Co., Glendale, WI Gold: Clausthaler Lager, Radeberger-Gruppe AG, Frankfurt am Main, Germany Silver: O’Doul’s Amber, Anheuser-Busch, Saint Louis, MO Category: 25 German-Style Schwarzbier, 22 Entries Bronze: Kirner Frei, Kirner Privatbrauerei, Kirn, Germany Gold: Schwarzbier, Hereford and Hops Steakhouse and Brewpub, Wausau, WI Silver: Black Forest Schwarzbier, Squatters Pub Brewery, Salt Lake City, UT Category: 3 American Lager/Ale or Cream Ale, 11 Entries Bronze: Black Bear, Thirsty Bear Brewing Co., San Francisco, CA Silver: Extreme Cream, Terrapin Beer Co., Athens, GA Bronze: Lightning Bold Gold, Hops Grillhouse and Brewery, Tampa, FL Category: 26 Traditional German-Style Bock, 16 Entries Silver: Brick Anniversary Bock, Brick Brewing Co. Ltd., Waterloo, Canada Category: 4 American-Style Wheat Beer, 11 Entries Bronze: Bock Lager, Elk Grove Brewery & Restaurant, Elk Grove, CA Gold: Shiner Winter Ale, The Spoetzl Brewery, San Antonio, TX Silver: Leinenkugel’s Honey Weiss, Jacob Leinenkugel -

The Tin Can and the Increased Competition Between the Swedish and Danish Brewing Industries Since the 1950S
The pressure of new innovations on transnational cartels and trade organisations: the tin can and the increased competition between the Swedish and Danish brewing industries since the 1950s Peter Sandberg Introduction strong national cartels was threatened by de-regulations and a more liberal In the following article, I will discuss the legislation, whose main purpose was to new opportunities that followed the increase competition and to rationalise institutional changes after the World the structure of the economy. In theory, War II. To be more precise, my aim is to the new institutional framework should create a better understanding of how create more competitive and efficient and why new innovations and innovation companies that in the end would lead to systems threatened the stability of increased competition and raise the national and international cartel agree- industrial output and productivity. In the ments and distribution systems. I shall perspective of Alfred Chandler, the focus on the market integration between development that followed the de- the Danish and the Swedish brewing cartelisation was often characterised by industry during the 1950s until the mid the formation of managerial controlled 1970s, and how a new innovation - the hierarchical combines, which in most tin can - challenged the market stability sectors replaced the old family controlled and opened up alternative means for enterprises.2 However, the new legisla- both production and distribution of bever- tive framework also opened up new ages across the borders. possibilities for innovators and entrepre- neurs who saw new opportunities in a In the aftermath of the war, a new institu- deregulated market. -

Thoughts on 1000 Beers
TThhoouugghhttss OOnn 11000000 BBeeeerrss DDaavviidd GGooooddyy Thoughts On 1000 Beers David Goody With thanks to: Friends, family, brewers, bar staff and most of all to Katherine Shaw Contents Introduction 3 Belgium 85 Britain 90 Order of Merit 5 Czech Republic 94 Denmark 97 Beer Styles 19 France 101 Pale Lager 20 Germany 104 Dark Lager 25 Iceland 109 Dark Ale 29 Netherlands 111 Stout 36 New Zealand 116 Pale Ale 41 Norway 121 Strong Ale 47 Sweden 124 Abbey/Belgian 53 Wheat Beer 59 Notable Breweries 127 Lambic 64 Cantillon 128 Other Beer 69 Guinness 131 Westvleteren 133 Beer Tourism 77 Australia 78 Full Beer List 137 Austria 83 Introduction This book began with a clear purpose. I was enjoying Friday night trips to Whitefriars Ale House in Coventry with their ever changing selection of guest ales. However I could never really remember which beers or breweries I’d enjoyed most a few months later. The nearby Inspire Café Bar provided a different challenge with its range of European beers that were often only differentiated by their number – was it the 6, 8 or 10 that I liked? So I started to make notes on the beers to improve my powers of selection. Now, over three years on, that simple list has grown into the book you hold. As well as straightforward likes and dislikes, the book contains what I have learnt about the many styles of beer and the history of brewing in countries across the world. It reflects the diverse beers that are being produced today and the differing attitudes to it. -

Craft Beer Box of Chocolates ___Unified Beerworks
FREE january/february 2019 Vol. 3 #1 Craft Beer box of chocolates ______ Unified beerworks ______ a day with Iron heart mobile canning ______ craft your super sunday party rawpixel,com CRAFT BEER + SPORTS TRIVIA Wednesday Nights 41 112th St. North Troy 235-4141 GET YOUR TICKETS TODAY! Come visit for our Taproom Only releases, 3 Barrel Pilot Batch brews - Strawberry Milkshake IPA, Double Sunrise IPA PLUS: Sierra Nevada Resilience IPA 100% of proceeds to be donated to the Camp Fire relief. Advertise with True Brew Magazine! [email protected] Monday thru Wednesday 1130am-midnight Trivia every Wednesday Closed Monday and Tuesday Thursday & Friday 1130am-2am Industry night Wednesday & Thursday 4pm to 12am Saturday 12pm- 2am Outdoor Patio Friday and Saturday 2pm Sunday 4pm Sunday 10am-11pm Open Everyday 6pm-4am Weekends-Brunch Saturday and Sunday Trivia every Wednesday True neighborhood pub! Outdoor Patio, Craft beer web: mcaddyspub.com web: susiespub.com/secretsusies/ Serving breakfast and lunch all day @McAddyspub @SusiesPub @SusiesCafe217 @mcaddyspub @susiespub @cafe_217 JOIN US FOR GREAT FOOD & SPIRITS! F KENT TA O V N ER A N M MOK 16 130 Draughts Bottles OPEN 7 days 11AM 4452 NY Rt. 7 View our menu at Hoosick Falls, NY MANOFKENTTAVERN.COM (518) 686-9917 Advertise with True Brew Magazine! [email protected] 5 Table of Contents: Unified Beerworks-Brewed With Passion 10 Iron Heart-Canning a Revolution 16 Craft Your Super Sunday Party 20 Calendar of Events 22-23 Published by Collar City Craft Media LLC. Beer of -

Download This Publication
THE SWEDISH RETAIL INSTITUTE August 2009 SWEDISH ALCOHOL POLICY - AN EFFECTIVE POLICY? Foreword In this report, commissioned by The Brewers of Europe, the Swedish Retail Institute, HUI, has analysed the success and failures of Swedish alcohol policy. The Swedish Retail Institute, HUI, was founded in 1968 and is owned by The Swedish Trade Federation. Through market and customer analysis on different levels, our consultants help our clients make better business by improving their understanding of consumers, consumer behaviour and marketplaces. Our consultants also deal with issues on a social-economic level, business cycle analysis as well as procurement and processing of retail related data. HUI is the leading organisation for research regarding the retail and wholesale industry and the publications of our researchers can be found in numerous international scientific journals. HUI conducts its research activity together with several external researchers and in cooperation with a number of Swedish universities. HUI is well-known in the Swedish society for its seriousity, integrity and independence. The Brewers of Europe, founded in 1958 and based in Brussels, is the voice of the European brewing sector to the European institutions and international organisations. Current members are the national brewers’ associations from EU Member States, plus Norway, Switzerland and Turkey. This report is written by Jonas Arnberg and Sofie Lord, both economists at The Swedish Retail Institute, HUI. Questions about the report will be answered by Jonas Arnberg, HUI +46-8-7627290, [email protected] TABLE OF CONTENTS 1 INTRODUCTION ............................................................................................................................................. 8 2 BACKGROUND ON THE SWEDISH ALCOHOL SITUATION ............................................................................. 9 3 ALCOHOL CONSUMPTION IN SWEDEN...................................................................................................... -
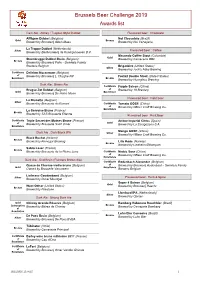
Brussels Beer Challenge 2019 Awards List
Brussels Beer Challenge 2019 Awards list Dark Ale : Abbey / Trappist Style Dubbel Flavoured beer : Chocolate Affligem Dubbel (Belgium) Noi Cioccolato (Brazil) Gold Bronze Brewed by Brouwerij Alken-Maes Brewed by Noi Cervejaria La Trappe Dubbel (Netherlands) Silver Flavoured beer : Coffee Brewed by Bierbrouwerij de Koningshoeven B.V. Macondo Coffee Stout (Colombia) Gold Steenbrugge Dubbel Bruin (Belgium) Brewed by Cervecería BBC Bronze Brewed by Brouwerij Palm - Swinkels Family Brewers Belgium Brigadeiro (United States) Silver Brewed by Jack's Abby Brewing Certificate Delirium Nocturnum (Belgium) of Brewed by Brouwerij L. Huyghe NV Foxtail Double Stout (United States) Bronze Excellence Brewed by Hourglass Brewing Dark Ale : Brown Ale Certificate Purple Saison (China) Brugse Zot Dubbel (Belgium) of Brewed by 18 Brewery Gold Brewed by Brouwerij De Halve Maan Excellence Flavoured beer : Field beer La Brunette (Belgium) Silver Brewed by Brasserie du Renard Certificate Tomato GOSE (China) of Brewed by NBeer Craft Brewing Co. La Gervoise Brune (France) Excellence Bronze Brewed by SAS Brasserie Etienne Flavoured beer : Fruit Beer Certificate Triple Secret des Moines Brune (France) Ambar Imperial Citrus (Spain) Gold of Brewed by Brasserie Saint Omer Brewed by La Zaragozana S.A. Excellence Mango GOSE (China) Dark Ale : Dark/Black IPA Silver Brewed by NBeer Craft Brewing Co. Black Bucket (Ireland) Bronze Brewed by Kinnegar Brewing Lille Røde (Norway) Bronze Brewed by Lindheim Ølkompani Sabro Laser (France) Bronze Brewed by Brasserie de la Pleine -

How Do Craft Beer Brands Negotiate Authenticity Using Retro Branding?
How Do Craft Beer Brands Negotiate Authenticity Using Retro Branding? Master’s Degree Project in Marketing and Consumption Authors: Rasmus Pihl - 96062-8172 School of Business, Economics and Law, University of Gothenburg Alexander Svensson - 940620-3217 School of Business, Economics and Law, University of Gothenburg Supervisor: Benjamin Hartmann Graduate School How Do Craft Beer Brands Negotiate Authenticity Using Retro Branding? A Consumer Culture Theory Study on Craft Beer Brands Rasmus Pihl & Alexander Svensson Abstract: Craft beer brands are booming. However, many craft beer brands employ exceedingly similar retro-evocative techniques to negotiate authenticity with consumers. This article explores how craft beer brands systematically use retro marketing as a tool to negotiate authenticity with customers, through a consumer culture theory (CCT) lens. Moreover, the article seeks to examine potential implications of this largely homogenous use of discursive retro branding and faux heritage practices among craft beer brands, in the context of consumer authenticity and enchantment. The article finds that the current largely homogenous discursive retro branding practices risk eroding authenticity and enchantment. As these branding practices entangle brand connotations in the minds of consumers, this article finds craft beer firms should employ further marketing activities beyond these retro branding initiatives to remain relevant. Furthermore, the findings also suggest that the forced point-of-sale for craft beers in a Swedish setting - Systembolaget - exerts a negative impact on craft brands’ ability to negotiate brand authenticity. Keywords: Retro branding, craft beer brands, authenticity, enchantment, consumer culture theory (CCT) 1. Introduction This article explores the concept of craft beer marketing and how craft beer brands employ retro branding to appeal to consumers.