Cube Algebra: a Generic User-Centric Model and Query Language for OLAP Cubes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Observability of the Fibonacci and the Lucas Cubes
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Discrete Mathematics 255 (2002) 55–63 www.elsevier.com/locate/disc The observability of the Fibonacci and the Lucas cubes Ernesto DedÃo∗;1, Damiano Torri1, Norma Zagaglia Salvi1 Dipartimento di Matematica, Politecnico di Milano, Piazza Leonardo da Vinci 32, 20133 Milano, Italy Received 5 April 1999; received inrevised form 31 July 2000; accepted 8 January2001 Abstract The Fibonacci cube n is the graph whose vertices are binary strings of length n without two consecutive 1’s and two vertices are adjacent when their Hamming distance is exactly 1. If the binary strings do not contain two consecutive 1’s nora1intheÿrst and in the last position, we obtainthe Lucas cube Ln. We prove that the observability of n and Ln is n, where the observability of a graph G is the minimum number of colors to be assigned to the edges of G so that the coloring is proper and the vertices are distinguished by their color sets. c 2002 Elsevier Science B.V. All rights reserved. MSC: 05C15; 05A15 Keywords: Fibonacci cube; Fibonacci number; Lucas number; Observability 1. Introduction A Fibonacci string of order n is a binary string of length n without two con- secutive ones. Let and ÿ be binary strings; then ÿ denotes the string obtained by concatenating and ÿ. More generally, if S is a set of strings, then Sÿ = {ÿ: ∈ S}. If Cn denotes the set of the Fibonacci strings of order n, then Cn+2 =0Cn+1 +10Cn and |Cn| = Fn, where Fn is the nth Fibonacci number. -

On Hardy's Apology Numbers
ON HARDY’S APOLOGY NUMBERS HENK KOPPELAAR AND PEYMAN NASEHPOUR Abstract. Twelve well known ‘Recreational’ numbers are generalized and classified in three generalized types Hardy, Dudeney, and Wells. A novel proof method to limit the search for the numbers is exemplified for each of the types. Combinatorial operators are defined to ease programming the search. 0. Introduction “Recreational Mathematics” is a broad term that covers many different areas including games, puzzles, magic, art, and more [31]. Some may have the impres- sion that topics discussed in recreational mathematics in general and recreational number theory, in particular, are only for entertainment and may not have an ap- plication in mathematics, engineering, or science. As for the mathematics, even the simplest operation in this paper, i.e. the sum of digits function, has application outside number theory in the domain of combinatorics [13, 26, 27, 28, 34] and in a seemingly unrelated mathematical knowledge domain: topology [21, 23, 15]. Pa- pers about generalizations of the sum of digits function are discussed by Stolarsky [38]. It also is a surprise to see that another topic of this paper, i.e. Armstrong numbers, has applications in “data security” [16]. In number theory, functions are usually non-continuous. This inhibits solving equations, for instance, by application of the contraction mapping principle because the latter is normally for continuous functions. Based on this argument, questions about solving number-theoretic equations ramify to the following: (1) Are there any solutions to an equation? (2) If there are any solutions to an equation, then are finitely many solutions? (3) Can all solutions be found in theory? (4) Can one in practice compute a full list of solutions? arXiv:2008.08187v1 [math.NT] 18 Aug 2020 The main purpose of this paper is to investigate these constructive (or algorith- mic) problems by the fixed points of some special functions of the form f : N N. -

Figurate Numbers
Figurate Numbers by George Jelliss June 2008 with additions November 2008 Visualisation of Numbers The visual representation of the number of elements in a set by an array of small counters or other standard tally marks is still seen in the symbols on dominoes or playing cards, and in Roman numerals. The word "calculus" originally meant a small pebble used to calculate. Bear with me while we begin with a few elementary observations. Any number, n greater than 1, can be represented by a linear arrangement of n counters. The cases of 1 or 0 counters can be regarded as trivial or degenerate linear arrangements. The counters that make up a number m can alternatively be grouped in pairs instead of ones, and we find there are two cases, m = 2.n or 2.n + 1 (where the dot denotes multiplication). Numbers of these two forms are of course known as even and odd respectively. An even number is the sum of two equal numbers, n+n = 2.n. An odd number is the sum of two successive numbers 2.n + 1 = n + (n+1). The even and odd numbers alternate. Figure 1. Representation of numbers by rows of counters, and of even and odd numbers by various, mainly symmetric, formations. The right-angled (L-shaped) formation of the odd numbers is known as a gnomon. These do not of course exhaust the possibilities. 1 2 3 4 5 6 7 8 9 n 2 4 6 8 10 12 14 2.n 1 3 5 7 9 11 13 15 2.n + 1 Triples, Quadruples and Other Forms Generalising the divison into even and odd numbers, the counters making up a number can of course also be grouped in threes or fours or indeed any nonzero number k. -

Fibonacci's Perfect Spiral
Middle School Fibonacci's Perfect Spiral This l esson was created to combine math history, math, critical thinking, and art. Students will l earn about Fibonacci, the code he created, and how the Fibonacci sequence relates to real l ife and the perfect spiral. Students will practice drawing perfect spirals and l earn how patterns are a mathematical concept that surrounds us i n real l ife. This l esson i s designed to take 3 to 4 class periods of 45 minutes each, depending on the students’ focus and depth of detail i n the assignments. Common Core CCSS.MATH.CONTENT.HSF.IF.A.3 Recognize that Standards: sequences are functions, sometimes defined recursively, whose domain i s a subset of the i ntegers. For example, the Fibonacci sequence i s defined recursively by f(0) = f(1) = 1, f(n+1) = f(n) + f(n1) for n ≥ 1. CCSS.MATH.CONTENT.7.EE.B.4 Use variables to represent quantities i n a realworld or mathematical problem, and construct simple equations and inequalities to solve problems by reasoning about the quantities. CCSS.MATH.CONTENT.7.G.A.1 Solve problems involving scale drawings of geometric figures, i ncluding computing actual l engths and areas from a scale drawing and reproducing a scale drawing at a different scale. CCSS.MATH.CONTENT.7.G.A.2 Draw (freehand, with ruler and protractor, and with technology) geometric shapes with given conditions. CCSS.MATH.CONTENT.8.G.A.2 Understand that a twodimensional figure i s congruent to another i f the second can be obtained from the first by a sequence of rotations, reflections, and translations; given two congruent figures, describe a sequence that exhibits the congruence between them. -

Student Task Statements (8.7.B.3)
GRADE 8 MATHEMATICS BY NAME DATE PERIOD Unit 7, Lesson 3: Powers of Powers of 10 Let's look at powers of powers of 10. 3.1: Big Cube What is the volume of a giant cube that measures 10,000 km on each side? 3.2: Taking Powers of Powers of 10 1. a. Complete the table to explore patterns in the exponents when raising a power of 10 to a power. You may skip a single box in the table, but if you do, be prepared to explain why you skipped it. expression expanded single power of 10 b. If you chose to skip one entry in the table, which entry did you skip? Why? 2. Use the patterns you found in the table to rewrite as an equivalent expression with a single exponent, like . GRADE 8 MATHEMATICS BY NAME DATE PERIOD 3. If you took the amount of oil consumed in 2 months in 2013 worldwide, you could make a cube of oil that measures meters on each side. How many cubic meters of oil is this? Do you think this would be enough to fill a pond, a lake, or an ocean? 3.3: How Do the Rules Work? Andre and Elena want to write with a single exponent. • Andre says, “When you multiply powers with the same base, it just means you add the exponents, so .” • Elena says, “ is multiplied by itself 3 times, so .” Do you agree with either of them? Explain your reasoning. Are you ready for more? . How many other whole numbers can you raise to a power and get 4,096? Explain or show your reasoning. -
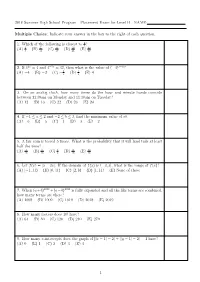
2018 Summer High School Program Placement Exam for Level B NAME
2018 Summer High School Program Placement Exam for Level B NAME: Multiple Choice: Indicate your answer in the box to the right of each question. 1 1. Which of the following is closest to 2 ? 2 7 9 10 23 (A) 3 (B) 13 (C) 19 (D) 21 (E) 48 2. If 42x = 4 and 4−5y = 32, then what is the value of (−4)x−y? 1 1 (A) −4 (B) −2 (C) − 4 (D) 4 (E) 4 3. On an analog clock, how many times do the hour and minute hands coincide between 11:30am on Monday and 11:30am on Tuesday? (A) 12 (B) 13 (C) 22 (D) 23 (E) 24 4. If −1 ≤ a ≤ 2 and −2 ≤ b ≤ 3, find the minimum value of ab. (A) −6 (B) −5 (C) −4 (D) −3 (E) −2 5. A fair coin is tossed 5 times. What is the probability that it will land tails at least half the time? 3 5 1 11 13 (A) 16 (B) 16 (C) 2 (D) 16 (E) 16 6. Let f(x) = j5 − 2xj. If the domain of f(x) is (−3; 3], what is the range of f(x)? (A) [−1; 11) (B) [0; 11) (C) [2; 8) (D) [1; 11) (E) None of these 7. When (a+b)2018 +(a−b)2018 is fully expanded and all the like terms are combined, how many terms are there? (A) 1008 (B) 1009 (C) 1010 (D) 2018 (E) 2019 8. How many factors does 10! have? (A) 64 (B) 80 (C) 120 (D) 240 (E) 270 9. -

Solve the Rubik's Cube Using Proc
Solve the Rubik’s Cube using Proc IML Jeremy Hamm Cancer Surveillance & Outcomes (CSO) Population Oncology BC Cancer Agency Overview Rubik’s Cube basics Translating the cube into linear algebra Steps to solving the cube using proc IML Proc IML examples The Rubik’s Cube 3x3x3 cube invented in 1974 by Hungarian Erno Rubik – Most popular in the 80’s – Still has popularity with speed-cubers 43x1018 permutations of the Rubik’s Cube – Quintillion Interested in discovering moves that lead to permutations of interest – or generalized permutations Generalized permutations can help solve the puzzle The Rubik’s Cube Made up of Edges and corners Pieces can permute – Squares called facets Edges can flip Corners can rotate Rubik’s Cube Basics Each move can be defined as a combination of Basic Movement Generators – each face rotated a quarter turn clockwise Eg. – Movement of front face ¼ turn clockwise is labeled as move F – ¼ turn counter clockwise is F-1 – 2 quarter turns would be F*F or F2 Relation to Linear Algebra The Rubik’s cube can represented by a Vector, numbering each facet 1-48 (excl centres). Permutations occur through matrix algebra where the basic movements are represented by Matrices Ax=b Relation to Linear Algebra Certain facets are connected and will always move together Facets will always move in a predictable fashion – Can be written as: F= (17,19,24,22) (18,21,23,20) (6,25,43,16) (7,28,42,13) (8,30,41,11) Relation to Linear Algebra Therefore, if you can keep track of which numbers are edges and which are corners, you can use a program such as SAS to mathematically determine moves which are useful in solving the puzzle – Moves that only permute or flip a few pieces at a time such that it is easy to predict what will happen Useful Group Theory Notes: – All moves of the Rubik’s cube are cyclical where the order is the number of moves needed to return to the original Eg. -

The Mathematical Beauty of Triangular Numbers
2015 HAWAII UNIVERSITY INTERNATIONAL CONFERENCES S.T.E.A.M. & EDUCATION JUNE 13 - 15, 2015 ALA MOANA HOTEL, HONOLULU, HAWAII S.T.E.A.M & EDUCATION PUBLICATION: ISSN 2333-4916 (CD-ROM) ISSN 2333-4908 (ONLINE) THE MATHEMATICAL BEAUTY OF TRIANGULAR NUMBERS MULATU, LEMMA & ET AL SAVANNAH STATE UNIVERSITY, GEORGIA DEPARTMENT OF MATHEMATICS The Mathematical Beauty Of Triangular Numbers Mulatu Lemma, Jonathan Lambright and Brittany Epps Savannah State University Savannah, GA 31404 USA Hawaii University International Conference Abstract: The triangular numbers are formed by partial sum of the series 1+2+3+4+5+6+7….+n [2]. In other words, triangular numbers are those counting numbers that can be written as Tn = 1+2+3+…+ n. So, T1= 1 T2= 1+2=3 T3= 1+2+3=6 T4= 1+2+3+4=10 T5= 1+2+3+4+5=15 T6= 1+2+3+4+5+6= 21 T7= 1+2+3+4+5+6+7= 28 T8= 1+2+3+4+5+6+7+8= 36 T9=1+2+3+4+5+6+7+8+9=45 T10 =1+2+3+4+5+6+7+8+9+10=55 In this paper we investigate some important properties of triangular numbers. Some important results dealing with the mathematical concept of triangular numbers will be proved. We try our best to give short and readable proofs. Most of the results are supplemented with examples. Key Words: Triangular numbers , Perfect square, Pascal Triangles, and perfect numbers. 1. Introduction : The sequence 1, 3, 6, 10, 15, …, n(n + 1)/2, … shows up in many places of mathematics[1] . -

Florentin Smarandache
FLORENTIN SMARANDACHE SEQUENCES OF NUMBERS INVOLVED IN UNSOLVED PROBLEMS 1 141 1 1 1 8 1 1 8 40 8 1 1 8 1 1 1 1 12 1 1 12 108 12 1 1 12 108 540 108 12 1 1 12 108 12 1 1 12 1 1 1 1 16 1 1 16 208 16 1 1 16 208 1872 208 16 1 1 16 208 1872 9360 1872 208 16 1 1 16 208 1872 208 16 1 1 16 208 16 1 1 16 1 1 2006 Introduction Over 300 sequences and many unsolved problems and conjectures related to them are presented herein. These notions, definitions, unsolved problems, questions, theorems corollaries, formulae, conjectures, examples, mathematical criteria, etc. ( on integer sequences, numbers, quotients, residues, exponents, sieves, pseudo-primes/squares/cubes/factorials, almost primes, mobile periodicals, functions, tables, prime/square/factorial bases, generalized factorials, generalized palindromes, etc. ) have been extracted from the Archives of American Mathematics (University of Texas at Austin) and Arizona State University (Tempe): "The Florentin Smarandache papers" special collections, University of Craiova Library, and Arhivele Statului (Filiala Vâlcea, Romania). It is based on the old article “Properties of Numbers” (1975), updated many times. Special thanks to C. Dumitrescu & V. Seleacu from the University of Craiova (see their edited book "Some Notions and Questions in Number Theory", Erhus Univ. Press, Glendale, 1994), M. Perez, J. Castillo, M. Bencze, L. Tutescu, E, Burton who helped in collecting and editing this material. The Author 1 Sequences of Numbers Involved in Unsolved Problems Here it is a long list of sequences, functions, unsolved problems, conjectures, theorems, relationships, operations, etc. -

The TI-30X IIS Calculator and Exponents
The TI-30X IIS Calculator and Exponents 2nd ARROWS ^ 2 x PARENTHESIS Squaring a number can be done easily using a x2 key. Cubing a number or raising it to any power can be achieved by using ^ key followed by number 3. Ø Squaring: input the number and then x2 =, 42 is found by inputting: 4 x2 = You screen will look like: 42 16 ➢ Cubing or raising a number to the third power: input the number and then ^3 =, 43 is found by inputting: 4 ^3 = You screen will look like: 4^3 64 ➢ Raising a number to a power greater than 3: input the number and then ^ (the power desired) =, (-3)4 is found by inputting: ( (-)3 ) ^ 4 = You screen will look like: (-3)^4 81 Note: if you did not put the -3 in parentheses, the orders of operation raises the 3 to the fourth power and then makes it negative, hence the answer will be -81. Be careful that you always put negative numbers in parentheses when raising them to powers. ➢ You can also take values to fractional exponents: 82/3 can be found by inputting: 8 ^ (2 ÷3) = You screen will look like: 8 ^ (2 / 3) 4 Taking a root can be done easily using √ option, which is achieved by pressing 2nd x2. Any other root (n-root), can be calculated by pressing (the root desired) 2nd ^. 2 ➢ Square root: √ the number =, is found by inputting: 2nd x 36 = You screen will look like: √(36 6 ➢ Cube root: ∛the number =, is found by inputting: 3 2nd ^ 64 = You screen will look like: 3 x√64 4 ➢ Taking a root higher than a cube root: (the root desired) 2nd ^ (the value) =, is found by inputting: 4 2nd ^ 1296 = You screen will look like: 4 x√1296 6 Since the root symbol works like a grouping symbol, there is no need to use parentheses for negative values. -

Noncrossing Partitions Rodica Simion ∗ Department of Mathematics, the George Washington University, Washington, DC 20052, USA
View metadata, citation and similar papers at core.ac.ukDiscrete Mathematics 217 (2000) 367–409 brought to you by CORE www.elsevier.com/locate/disc provided by Elsevier - Publisher Connector Noncrossing partitions Rodica Simion ∗ Department of Mathematics, The George Washington University, Washington, DC 20052, USA Received 8 September 1998; revised 5 November 1998; accepted 11 June 1999 Abstract In a 1972 paper, Germain Kreweras investigated noncrossing partitions under the reÿnement order relation. His paper set the stage both for a wealth of further enumerative results, and for new connections between noncrossing partitions, the combinatorics of partially ordered sets, and algebraic combinatorics. Without attempting to give an exhaustive account, this article illustrates aspects of enumerative and algebraic combinatorics supported by the lattice of noncrossing par- titions, re ecting developments since Germain Kreweras’ paper. The sample of topics includes instances when noncrossing partitions arise in the context of algebraic combinatorics, geometric combinatorics, in relation to topological problems, questions in probability theory and mathe- matical biology. c 2000 Elsevier Science B.V. All rights reserved. RÃesumÃe Dans un article paru en 1972, Germain Kreweras ÿt uneetude à des partitions noncroisÃees en tant qu’ensemble ordonnÃe. Cet article crÃea le cadre ou, depuis lors, on a dÃeveloppÃe une multitude de rÃesultats supplÃementaires ainsi que des nouveaux liens entre les partitions noncroisÃees, la combinatoire des ensembles ordonnÃes et la combinatoire algÃebrique. Sans ta ˆcher d’en donner un traitement au complet, l’article prÃesent exempliÿe quelques aspectsenumà à eratifs et de combi- natoire algÃebrique ou interviennent les partitions noncroisÃees. Ceux-ci mettent enevidence à des dÃeveloppements survenus depuis la publication de l’article de Germain Kreweras et qui portent sur des problÂemes en combinatoire algÃebrique et gÃeomÃetrique, ainsi que sur des questions reliÃees a la topologie, aux probabilitÃes eta  la biologie mathÃematique. -

MTJPAM Lucas Cube Vs Zeckendorf's Lucas Code
Montes Taurus J. Pure Appl. Math. 3 (2), 47–50, 2021 MTJPAM ISSN: 2687-4814 Lucas Cube vs Zeckendorf’s Lucas Code Sadjia Abbad ID a, Hacene` Belbachir ID b, Ryma Ould-Mohamed ID c aUSTHB, Faculty of Mathematics, RECITS Laboratory, BP 32 El-Alia, Bab-Ezzouar 16111, Algiers, Algeria. Saad Dahlab University, BP 270, Route de Soumaa, Blida, Algeria bUSTHB, Faculty of Mathematics, RECITS Laboratory, BP 32 El-Alia, Bab-Ezzouar 16111, Algiers, Algeria cUSTHB, Faculty of Mathematics, RECITS Laboratory, BP 32 El-Alia, Bab-Ezzouar 16111, Algiers, Algeria. University of Algiers 1, 2 Rue Didouche Mourad, Alger Ctre 16000, Algiers, Algeria Abstract The theorem of Zeckendorf states that every positive integer n can be uniquely decomposed as a sum of non consecutive Lucas P numbers in the form n = i biLi, where bi 2 f0; 1g and satisfy b0b2 = 0. The Lucas string is a binary string that do not contain two consecutive 1’s in a circular way. In this note, we derive a bijection between the set of Zeckendorf’s Lucas codes and the set of vertices of the Lucas’ strings. Keywords: Fibonacci numbers, Lucas numbers, Fibonacci cube, Lucas cube 2010 MSC: 11B39, 05C99 1. Introduction The Fibonacci numbers (Fn)n≥0 given by F0 = 0; F1 = 1 and Fn+1 = Fn + Fn−1; n ≥ 1; constitute a basis element of the binary Fibonacci numeration system, see for instance [11]. Every integer 0 ≤ N < Fn+1 has a unique binary representation a2a3 ··· an, such that Xn N = aiFi; i=2 with ai 2 f0; 1g and aiai+1 = 0; for 2 ≤ i ≤ n − 1: The binary string a2 ··· an is called a Zeckendorf’s Fibonacci code.