Vector Norms
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Parametrizations of K-Nonnegative Matrices
Parametrizations of k-Nonnegative Matrices Anna Brosowsky, Neeraja Kulkarni, Alex Mason, Joe Suk, Ewin Tang∗ October 2, 2017 Abstract Totally nonnegative (positive) matrices are matrices whose minors are all nonnegative (positive). We generalize the notion of total nonnegativity, as follows. A k-nonnegative (resp. k-positive) matrix has all minors of size k or less nonnegative (resp. positive). We give a generating set for the semigroup of k-nonnegative matrices, as well as relations for certain special cases, i.e. the k = n − 1 and k = n − 2 unitriangular cases. In the above two cases, we find that the set of k-nonnegative matrices can be partitioned into cells, analogous to the Bruhat cells of totally nonnegative matrices, based on their factorizations into generators. We will show that these cells, like the Bruhat cells, are homeomorphic to open balls, and we prove some results about the topological structure of the closure of these cells, and in fact, in the latter case, the cells form a Bruhat-like CW complex. We also give a family of minimal k-positivity tests which form sub-cluster algebras of the total positivity test cluster algebra. We describe ways to jump between these tests, and give an alternate description of some tests as double wiring diagrams. 1 Introduction A totally nonnegative (respectively totally positive) matrix is a matrix whose minors are all nonnegative (respectively positive). Total positivity and nonnegativity are well-studied phenomena and arise in areas such as planar networks, combinatorics, dynamics, statistics and probability. The study of total positivity and total nonnegativity admit many varied applications, some of which are explored in “Totally Nonnegative Matrices” by Fallat and Johnson [5]. -

C H a P T E R § Methods Related to the Norm Al Equations
¡ ¢ £ ¤ ¥ ¦ § ¨ © © © © ¨ ©! "# $% &('*),+-)(./+-)0.21434576/),+98,:%;<)>=,'41/? @%3*)BAC:D8E+%=B891GF*),+H;I?H1KJ2.21K8L1GMNAPO45Q5R)S;S+T? =RU ?H1*)>./+EAVOKAPM ;<),5 ?H1G;P8W.XAVO4575R)S;S+Y? =Z8L1*)/[%\Z1*)]AB3*=,'Q;<)B=,'41/? @%3*)RAP8LU F*)BA(;S'*)Z)>@%3/? F*.4U ),1G;^U ?H1*)>./+ APOKAP;_),5a`Rbc`^dfeg`Rbih,jk=>.4U U )Blm;B'*)n1K84+o5R.EUp)B@%3*.K;q? 8L1KA>[r\0:D;_),1Ejp;B'/? A2.4s4s/+t8/.,=,' b ? A7.KFK84? l4)>lu?H1vs,+D.*=S;q? =>)m6/)>=>.43KA<)W;B'*)w=B8E)IxW=K? ),1G;W5R.K;S+Y? yn` `z? AW5Q3*=,'|{}84+-A_) =B8L1*l9? ;I? 891*)>lX;B'*.41Q`7[r~k8K{i)IF*),+NjL;B'*)71K8E+o5R.4U4)>@%3*.G;I? 891KA0.4s4s/+t8.*=,'w5R.BOw6/)Z.,l4)IM @%3*.K;_)7?H17A_8L5R)QAI? ;S3*.K;q? 8L1KA>[p1*l4)>)>lj9;B'*),+-)Q./+-)Q)SF*),1.Es4s4U ? =>.K;q? 8L1KA(?H1Q{R'/? =,'W? ;R? A s/+-)S:Y),+o+D)Blm;_8|;B'*)W3KAB3*.4Urc+HO4U 8,F|AS346KABs*.,=B)Q;_)>=,'41/? @%3*)BAB[&('/? A]=*'*.EsG;_),+}=B8*F*),+tA7? ;PM ),+-.K;q? F*)75R)S;S'K8ElAi{^'/? =,'Z./+-)R)K? ;B'*),+pl9?+D)B=S;BU OR84+k?H5Qs4U ? =K? ;BU O2+-),U .G;<)Bl7;_82;S'*)Q1K84+o5R.EU )>@%3*.G;I? 891KA>[ mWX(fQ - uK In order to solve the linear system 7 when is nonsymmetric, we can solve the equivalent system b b [¥K¦ ¡¢ £N¤ which is Symmetric Positive Definite. This system is known as the system of the normal equations associated with the least-squares problem, [ ¦ £N¤ minimize §* R¨©7ª§*«9¬ Note that (8.1) is typically used to solve the least-squares problem (8.2) for over- ®°¯± ±²³® determined systems, i.e., when is a rectangular matrix of size , . -

Variables in Mathematics Education
Variables in Mathematics Education Susanna S. Epp DePaul University, Department of Mathematical Sciences, Chicago, IL 60614, USA http://www.springer.com/lncs Abstract. This paper suggests that consistently referring to variables as placeholders is an effective countermeasure for addressing a number of the difficulties students’ encounter in learning mathematics. The sug- gestion is supported by examples discussing ways in which variables are used to express unknown quantities, define functions and express other universal statements, and serve as generic elements in mathematical dis- course. In addition, making greater use of the term “dummy variable” and phrasing statements both with and without variables may help stu- dents avoid mistakes that result from misinterpreting the scope of a bound variable. Keywords: variable, bound variable, mathematics education, placeholder. 1 Introduction Variables are of critical importance in mathematics. For instance, Felix Klein wrote in 1908 that “one may well declare that real mathematics begins with operations with letters,”[3] and Alfred Tarski wrote in 1941 that “the invention of variables constitutes a turning point in the history of mathematics.”[5] In 1911, A. N. Whitehead expressly linked the concepts of variables and quantification to their expressions in informal English when he wrote: “The ideas of ‘any’ and ‘some’ are introduced to algebra by the use of letters. it was not till within the last few years that it has been realized how fundamental any and some are to the very nature of mathematics.”[6] There is a question, however, about how to describe the use of variables in mathematics instruction and even what word to use for them. -

Vectors, Matrices and Coordinate Transformations
S. Widnall 16.07 Dynamics Fall 2009 Lecture notes based on J. Peraire Version 2.0 Lecture L3 - Vectors, Matrices and Coordinate Transformations By using vectors and defining appropriate operations between them, physical laws can often be written in a simple form. Since we will making extensive use of vectors in Dynamics, we will summarize some of their important properties. Vectors For our purposes we will think of a vector as a mathematical representation of a physical entity which has both magnitude and direction in a 3D space. Examples of physical vectors are forces, moments, and velocities. Geometrically, a vector can be represented as arrows. The length of the arrow represents its magnitude. Unless indicated otherwise, we shall assume that parallel translation does not change a vector, and we shall call the vectors satisfying this property, free vectors. Thus, two vectors are equal if and only if they are parallel, point in the same direction, and have equal length. Vectors are usually typed in boldface and scalar quantities appear in lightface italic type, e.g. the vector quantity A has magnitude, or modulus, A = |A|. In handwritten text, vectors are often expressed using the −→ arrow, or underbar notation, e.g. A , A. Vector Algebra Here, we introduce a few useful operations which are defined for free vectors. Multiplication by a scalar If we multiply a vector A by a scalar α, the result is a vector B = αA, which has magnitude B = |α|A. The vector B, is parallel to A and points in the same direction if α > 0. -
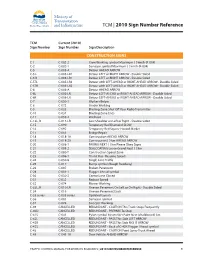
2010 Sign Number Reference for Traffic Control Manual
TCM | 2010 Sign Number Reference TCM Current (2010) Sign Number Sign Number Sign Description CONSTRUCTION SIGNS C-1 C-002-2 Crew Working symbol Maximum ( ) km/h (R-004) C-2 C-002-1 Surveyor symbol Maximum ( ) km/h (R-004) C-5 C-005-A Detour AHEAD ARROW C-5 L C-005-LR1 Detour LEFT or RIGHT ARROW - Double Sided C-5 R C-005-LR1 Detour LEFT or RIGHT ARROW - Double Sided C-5TL C-005-LR2 Detour with LEFT-AHEAD or RIGHT-AHEAD ARROW - Double Sided C-5TR C-005-LR2 Detour with LEFT-AHEAD or RIGHT-AHEAD ARROW - Double Sided C-6 C-006-A Detour AHEAD ARROW C-6L C-006-LR Detour LEFT-AHEAD or RIGHT-AHEAD ARROW - Double Sided C-6R C-006-LR Detour LEFT-AHEAD or RIGHT-AHEAD ARROW - Double Sided C-7 C-050-1 Workers Below C-8 C-072 Grader Working C-9 C-033 Blasting Zone Shut Off Your Radio Transmitter C-10 C-034 Blasting Zone Ends C-11 C-059-2 Washout C-13L, R C-013-LR Low Shoulder on Left or Right - Double Sided C-15 C-090 Temporary Red Diamond SLOW C-16 C-092 Temporary Red Square Hazard Marker C-17 C-051 Bridge Repair C-18 C-018-1A Construction AHEAD ARROW C-19 C-018-2A Construction ( ) km AHEAD ARROW C-20 C-008-1 PAVING NEXT ( ) km Please Obey Signs C-21 C-008-2 SEALCOATING Loose Gravel Next ( ) km C-22 C-080-T Construction Speed Zone C-23 C-086-1 Thank You - Resume Speed C-24 C-030-8 Single Lane Traffic C-25 C-017 Bump symbol (Rough Roadway) C-26 C-007 Broken Pavement C-28 C-001-1 Flagger Ahead symbol C-30 C-030-2 Centre Lane Closed C-31 C-032 Reduce Speed C-32 C-074 Mower Working C-33L, R C-010-LR Uneven Pavement On Left or On Right - Double Sided C-34 -

Introduction Into Quaternions for Spacecraft Attitude Representation
Introduction into quaternions for spacecraft attitude representation Dipl. -Ing. Karsten Groÿekatthöfer, Dr. -Ing. Zizung Yoon Technical University of Berlin Department of Astronautics and Aeronautics Berlin, Germany May 31, 2012 Abstract The purpose of this paper is to provide a straight-forward and practical introduction to quaternion operation and calculation for rigid-body attitude representation. Therefore the basic quaternion denition as well as transformation rules and conversion rules to or from other attitude representation parameters are summarized. The quaternion computation rules are supported by practical examples to make each step comprehensible. 1 Introduction Quaternions are widely used as attitude represenation parameter of rigid bodies such as space- crafts. This is due to the fact that quaternion inherently come along with some advantages such as no singularity and computationally less intense compared to other attitude parameters such as Euler angles or a direction cosine matrix. Mainly, quaternions are used to • Parameterize a spacecraft's attitude with respect to reference coordinate system, • Propagate the attitude from one moment to the next by integrating the spacecraft equa- tions of motion, • Perform a coordinate transformation: e.g. calculate a vector in body xed frame from a (by measurement) known vector in inertial frame. However, dierent references use several notations and rules to represent and handle attitude in terms of quaternions, which might be confusing for newcomers [5], [4]. Therefore this article gives a straight-forward and clearly notated introduction into the subject of quaternions for attitude representation. The attitude of a spacecraft is its rotational orientation in space relative to a dened reference coordinate system. -

Kind of Quantity’
NIST Technical Note 2034 Defning ‘kind of quantity’ David Flater This publication is available free of charge from: https://doi.org/10.6028/NIST.TN.2034 NIST Technical Note 2034 Defning ‘kind of quantity’ David Flater Software and Systems Division Information Technology Laboratory This publication is available free of charge from: https://doi.org/10.6028/NIST.TN.2034 February 2019 U.S. Department of Commerce Wilbur L. Ross, Jr., Secretary National Institute of Standards and Technology Walter Copan, NIST Director and Undersecretary of Commerce for Standards and Technology Certain commercial entities, equipment, or materials may be identifed in this document in order to describe an experimental procedure or concept adequately. Such identifcation is not intended to imply recommendation or endorsement by the National Institute of Standards and Technology, nor is it intended to imply that the entities, materials, or equipment are necessarily the best available for the purpose. National Institute of Standards and Technology Technical Note 2034 Natl. Inst. Stand. Technol. Tech. Note 2034, 7 pages (February 2019) CODEN: NTNOEF This publication is available free of charge from: https://doi.org/10.6028/NIST.TN.2034 NIST Technical Note 2034 1 Defning ‘kind of quantity’ David Flater 2019-02-06 This publication is available free of charge from: https://doi.org/10.6028/NIST.TN.2034 Abstract The defnition of ‘kind of quantity’ given in the International Vocabulary of Metrology (VIM), 3rd edition, does not cover the historical meaning of the term as it is most commonly used in metrology. Most of its historical meaning has been merged into ‘quantity,’ which is polysemic across two layers of abstraction. -

Functional Analysis 1 Winter Semester 2013-14
Functional analysis 1 Winter semester 2013-14 1. Topological vector spaces Basic notions. Notation. (a) The symbol F stands for the set of all reals or for the set of all complex numbers. (b) Let (X; τ) be a topological space and x 2 X. An open set G containing x is called neigh- borhood of x. We denote τ(x) = fG 2 τ; x 2 Gg. Definition. Suppose that τ is a topology on a vector space X over F such that • (X; τ) is T1, i.e., fxg is a closed set for every x 2 X, and • the vector space operations are continuous with respect to τ, i.e., +: X × X ! X and ·: F × X ! X are continuous. Under these conditions, τ is said to be a vector topology on X and (X; +; ·; τ) is a topological vector space (TVS). Remark. Let X be a TVS. (a) For every a 2 X the mapping x 7! x + a is a homeomorphism of X onto X. (b) For every λ 2 F n f0g the mapping x 7! λx is a homeomorphism of X onto X. Definition. Let X be a vector space over F. We say that A ⊂ X is • balanced if for every α 2 F, jαj ≤ 1, we have αA ⊂ A, • absorbing if for every x 2 X there exists t 2 R; t > 0; such that x 2 tA, • symmetric if A = −A. Definition. Let X be a TVS and A ⊂ X. We say that A is bounded if for every V 2 τ(0) there exists s > 0 such that for every t > s we have A ⊂ tV . -

Glossary of Linear Algebra Terms
INNER PRODUCT SPACES AND THE GRAM-SCHMIDT PROCESS A. HAVENS 1. The Dot Product and Orthogonality 1.1. Review of the Dot Product. We first recall the notion of the dot product, which gives us a familiar example of an inner product structure on the real vector spaces Rn. This product is connected to the Euclidean geometry of Rn, via lengths and angles measured in Rn. Later, we will introduce inner product spaces in general, and use their structure to define general notions of length and angle on other vector spaces. Definition 1.1. The dot product of real n-vectors in the Euclidean vector space Rn is the scalar product · : Rn × Rn ! R given by the rule n n ! n X X X (u; v) = uiei; viei 7! uivi : i=1 i=1 i n Here BS := (e1;:::; en) is the standard basis of R . With respect to our conventions on basis and matrix multiplication, we may also express the dot product as the matrix-vector product 2 3 v1 6 7 t î ó 6 . 7 u v = u1 : : : un 6 . 7 : 4 5 vn It is a good exercise to verify the following proposition. Proposition 1.1. Let u; v; w 2 Rn be any real n-vectors, and s; t 2 R be any scalars. The Euclidean dot product (u; v) 7! u · v satisfies the following properties. (i:) The dot product is symmetric: u · v = v · u. (ii:) The dot product is bilinear: • (su) · v = s(u · v) = u · (sv), • (u + v) · w = u · w + v · w. -

HYPERCYCLIC SUBSPACES in FRÉCHET SPACES 1. Introduction
PROCEEDINGS OF THE AMERICAN MATHEMATICAL SOCIETY Volume 134, Number 7, Pages 1955–1961 S 0002-9939(05)08242-0 Article electronically published on December 16, 2005 HYPERCYCLIC SUBSPACES IN FRECHET´ SPACES L. BERNAL-GONZALEZ´ (Communicated by N. Tomczak-Jaegermann) Dedicated to the memory of Professor Miguel de Guzm´an, who died in April 2004 Abstract. In this note, we show that every infinite-dimensional separable Fr´echet space admitting a continuous norm supports an operator for which there is an infinite-dimensional closed subspace consisting, except for zero, of hypercyclic vectors. The family of such operators is even dense in the space of bounded operators when endowed with the strong operator topology. This completes the earlier work of several authors. 1. Introduction and notation Throughout this paper, the following standard notation will be used: N is the set of positive integers, R is the real line, and C is the complex plane. The symbols (mk), (nk) will stand for strictly increasing sequences in N.IfX, Y are (Hausdorff) topological vector spaces (TVSs) over the same field K = R or C,thenL(X, Y ) will denote the space of continuous linear mappings from X into Y , while L(X)isthe class of operators on X,thatis,L(X)=L(X, X). The strong operator topology (SOT) in L(X) is the one where the convergence is defined as pointwise convergence at every x ∈ X. A sequence (Tn) ⊂ L(X, Y )issaidtobeuniversal or hypercyclic provided there exists some vector x0 ∈ X—called hypercyclic for the sequence (Tn)—such that its orbit {Tnx0 : n ∈ N} under (Tn)isdenseinY . -

The Column and Row Hilbert Operator Spaces
The Column and Row Hilbert Operator Spaces Roy M. Araiza Department of Mathematics Purdue University Abstract Given a Hilbert space H we present the construction and some properties of the column and row Hilbert operator spaces Hc and Hr, respectively. The main proof of the survey is showing that CB(Hc; Kc) is completely isometric to B(H ; K ); in other words, the completely bounded maps be- tween the corresponding column Hilbert operator spaces is completely isometric to the bounded operators between the Hilbert spaces. A similar theorem for the row Hilbert operator spaces follows via duality of the operator spaces. In particular there exists a natural duality between the column and row Hilbert operator spaces which we also show. The presentation and proofs are due to Effros and Ruan [1]. 1 The Column Hilbert Operator Space Given a Hilbert space H , we define the column isometry C : H −! B(C; H ) given by ξ 7! C(ξ)α := αξ; α 2 C: Then given any n 2 N; we define the nth-matrix norm on Mn(H ); by (n) kξkc;n = C (ξ) ; ξ 2 Mn(H ): These are indeed operator space matrix norms by Ruan's Representation theorem and thus we define the column Hilbert operator space as n o Hc = H ; k·kc;n : n2N It follows that given ξ 2 Mn(H ) we have that the adjoint operator of C(ξ) is given by ∗ C(ξ) : H −! C; ζ 7! (ζj ξ) : Suppose C(ξ)∗(ζ) = d; c 2 C: Then we see that cd = (cj C(ξ)∗(ζ)) = (cξj ζ) = c(ζj ξ) = (cj (ζj ξ)) : We are also able to compute the matrix norms on rectangular matrices. -

Section 2.4–2.5 Partitioned Matrices and LU Factorization
Section 2.4{2.5 Partitioned Matrices and LU Factorization Gexin Yu [email protected] College of William and Mary Gexin Yu [email protected] Section 2.4{2.5 Partitioned Matrices and LU Factorization One approach to simplify the computation is to partition a matrix into blocks. 2 3 0 −1 5 9 −2 3 Ex: A = 4 −5 2 4 0 −3 1 5. −8 −6 3 1 7 −4 This partition can also be written as the following 2 × 3 block matrix: A A A A = 11 12 13 A21 A22 A23 3 0 −1 In the block form, we have blocks A = and so on. 11 −5 2 4 partition matrices into blocks In real world problems, systems can have huge numbers of equations and un-knowns. Standard computation techniques are inefficient in such cases, so we need to develop techniques which exploit the internal structure of the matrices. In most cases, the matrices of interest have lots of zeros. Gexin Yu [email protected] Section 2.4{2.5 Partitioned Matrices and LU Factorization 2 3 0 −1 5 9 −2 3 Ex: A = 4 −5 2 4 0 −3 1 5. −8 −6 3 1 7 −4 This partition can also be written as the following 2 × 3 block matrix: A A A A = 11 12 13 A21 A22 A23 3 0 −1 In the block form, we have blocks A = and so on. 11 −5 2 4 partition matrices into blocks In real world problems, systems can have huge numbers of equations and un-knowns.