OSI Guide to IR Software Table-3Rd
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Measuring the Maturity of Open Source Software for Digital Libraries: a Case Study of Dspace
Measuring the Maturity of Open Source Software for Digital Libraries: a Case Study of DSpace A Thesis submitted to the Cochin University of Science and Technology for the award of the Degree of DOCTOR OF PHILOSOPHY In Library and Information Science Under the Faculty of Technology by Surendran Cherukodan (Reg.No. 3540) Under the supervision of Dr. Humayoon Kabir S. Department of Computer Applications Cochin University of Science and Technology Cochin-22, Kerala, India. April 2015 Certificate Certified that the study presented in this thesis entitled “Measuring the Maturity of Open Source Software for Digital Libraries: a Case Study of DSpace” is a bonafide work done by Mr.Surendran Cherukodan, under my guidance in the Department of Computer Applications, Cochin University of Science and Technology and this work has not been included in any other thesis submitted previously for the award of any degree. Also certified that all the relevant corrections and modifications suggested by the audience during the pre-synopsis Seminar and recommended by the Doctoral Committee of the candidate have been incorporated in the thesis. Kochi Dr.Humayoon Kabir S. April 7, 2015 (Supervising Guide) Declaration I, Surendran Cherukodan, hereby declare that the thesis entitled “Measuring the Maturity of Open Source Software for Digital Libraries: a Case Study of DSpace” is the outcome of the original work done by me under the guidance of Dr. Humayoon Kabir S., Associate Professor, Department of Library and Information Science, University of Kerala, and that the work did not form part of any dissertation submitted for the award of any degree, diploma, associateship, or any other title or recognition from any University/Institution. -

Natural Language Processing Technique for Information Extraction and Analysis
International Journal of Research Studies in Computer Science and Engineering (IJRSCSE) Volume 2, Issue 8, August 2015, PP 32-40 ISSN 2349-4840 (Print) & ISSN 2349-4859 (Online) www.arcjournals.org Natural Language Processing Technique for Information Extraction and Analysis T. Sri Sravya1, T. Sudha2, M. Soumya Harika3 1 M.Tech (C.S.E) Sri Padmavati Mahila Visvavidyalayam (Women’s University), School of Engineering and Technology, Tirupati. [email protected] 2 Head (I/C) of C.S.E & IT Sri Padmavati Mahila Visvavidyalayam (Women’s University), School of Engineering and Technology, Tirupati. [email protected] 3 M. Tech C.S.E, Assistant Professor, Sri Padmavati Mahila Visvavidyalayam (Women’s University), School of Engineering and Technology, Tirupati. [email protected] Abstract: In the current internet era, there are a large number of systems and sensors which generate data continuously and inform users about their status and the status of devices and surroundings they monitor. Examples include web cameras at traffic intersections, key government installations etc., seismic activity measurement sensors, tsunami early warning systems and many others. A Natural Language Processing based activity, the current project is aimed at extracting entities from data collected from various sources such as social media, internet news articles and other websites and integrating this data into contextual information, providing visualization of this data on a map and further performing co-reference analysis to establish linkage amongst the entities. Keywords: Apache Nutch, Solr, crawling, indexing 1. INTRODUCTION In today’s harsh global business arena, the pace of events has increased rapidly, with technological innovations occurring at ever-increasing speed and considerably shorter life cycles. -

Different Preservation Levels: the Case of Scholarly Digital Editions
Oltmanns, E, et al. 2019. Different Preservation Levels: The Case of Scholarly Digital Editions. Data Science Journal, 18: 51, pp. 1–9. DOI: https://doi.org/10.5334/dsj-2019-051 RESEARCH PAPER Different Preservation Levels: The Case of Scholarly Digital Editions Elias Oltmanns, Tim Hasler, Wolfgang Peters-Kottig and Heinz-Günter Kuper Department Scientific Information, Konrad-Zuse-Zentrum für Informationstechnik Berlin, DE Corresponding author: Elias Oltmanns ([email protected]) Ensuring the long-term availability of research data forms an integral part of data management services. Where OAIS compliant digital preservation has been established in recent years, in almost all cases the services aim at the preservation of file-based objects. In the Digital Human- ities, research data is often represented in highly structured aggregations, such as Scholarly Digital Editions. Naturally, scholars would like their editions to remain functionally complete as long as possible. Besides standard components like webservers, the presentation typically relies on project specific code interacting with client software like webbrowsers. Especially the latter being subject to rapid change over time invariably makes such environments awkward to maintain once funding has ended. Pragmatic approaches have to be found in order to balance the curation effort and the maintainability of access to research data over time. A sketch of four potential service levels aiming at the long-term availability of research data in the humanities is outlined: (1) Continuous Maintenance, (2) Application Conservation, (3) Application Data Preservation, and (4) Bitstream Preservation. The first being too costly and the last hardly satisfactory in general, we suggest that the implementation of services by an infrastructure provider should concentrate on service levels 2 and 3. -

United States Patent (19) 11 Patent Number: 6,094,649 Bowen Et Al
US006094649A United States Patent (19) 11 Patent Number: 6,094,649 Bowen et al. (45) Date of Patent: Jul. 25, 2000 54) KEYWORD SEARCHES OF STRUCTURED “Charles Schwab Broadens Deployment of Fulcrum-Based DATABASES Corporate Knowledge Library Application', Uknown, Full 75 Inventors: Stephen J Bowen, Sandy; Don R crum Technologies Inc., Mar. 3, 1997, pp. 1-3. Brown, Salt Lake City, both of Utah (List continued on next page.) 73 Assignee: PartNet, Inc., Salt Lake City, Utah 21 Appl. No.: 08/995,700 Primary Examiner-Hosain T. Alam 22 Filed: Dec. 22, 1997 Assistant Examiner Thuy Pardo Attorney, Agent, or Firm-Computer Law---- (51) Int. Cl." ...................................................... G06F 17/30 52 U.S. Cl. ......................................... 707/3; 707/5; 707/4 (57 ABSTRACT 58 Field of Search .................................... 707/1, 2, 3, 4, 707/5, 531, 532,500 Methods and Systems are provided for Supporting keyword Searches of data items in a structured database, Such as a 56) References Cited relational database. Selected data items are retrieved using U.S. PATENT DOCUMENTS an SQL query or other mechanism. The retrieved data values 5,375,235 12/1994 Berry et al. ................................. is are documented using a markup language such as HTML. 5,469,354 11/1995 Hatakeyama et al. ... 707/3 The documents are indexed using a web crawler or other 5,546,578 8/1996 Takada ................. ... 707/5 indexing agent. Data items may be Selected for indexing by 5,685,003 11/1997 Peltonen et al. .. ... 707/531 5,787.295 7/1998 Nakao ........... ... 707/500 identifying them in a data dictionary. The indexing agent 5,787,421 7/1998 Nomiyama .. -

1.3.4 Web Technologies Concise Notes
OCR Computer Science A Level 1.3.4 Web Technologies Concise Notes www.pmt.education Specification 1.3.4 a) ● HTML ● CSS ● JavaScript 1.3.4 b) ● Search engine indexing 1.3.4 c) ● PageRank algorithm 1.3.4 d) ● Server and Client side processing www.pmt.education Web Development HTML ● HTML is the language/script that web pages are written in, ● It allows a browser to interpret and render a webpage for the viewer by describing the structure and order of the webpage. ● The language uses tags written in angle brackets (<tag>, </tag>) there are two sections of a webpage, a body and head. HTML Tags ● <html> : all code written within these tags is interpreted as HTML, ● <body> :Defines the content in the main browser content area, ● <link> :this is used to link to a css stylesheet (explained later in the notes) ● <head> :Defines the browser tab or window heading area, ● <title> :Defines the text that appears with the tab or window heading area, ● <h1>, <h2>, <h3> :Heading styles in decreasing sizes, ● <p> :A paragraph separated with a line space above and below ● <img> :Self closing image with parameters (img src = location, height=x, width = y) ● <a> : Anchor tag defining a hyperlink with location parameters (<a href= location> link text </a>) ● <ol> :Defines an ordered list, ● <ul> :Defines an unordered list, ● <li> :defines an individual list item ● <div> :creates a division of a page into separate areas each which can be referred to uniquely by name, (<div id= “page”>) Classes and Identifiers ● Class and identifier selectors are the names which you style, this means groups of items can be styled, the selectors for html are usually the div tags. -

Evaluation of Three Open Source Software in Terms of Managing Repositories of Electronic Theses and Dissertations: a Comparison Study
ISSN 2090-4304 J. Basic. Appl. Sci. Res., 2(11)10843-10852, 2012 Journal of Basic and Applied © 2012, TextRoad Publication Scientific Research www.textroad.com Evaluation of Three Open Source Software in Terms of Managing Repositories of Electronic Theses and Dissertations: A Comparison Study Mohamad Noorman Masrek1, Hesamedin Hakimjavadi2 1 Accounting Research Institute and Faculty of Information Management, Universiti Teknologi MARA (UiTM), Shah Alam, Malaysia 2Faculty of Information Management, Universiti Teknologi MARA (UiTM), Shah Alam, Malaysia ABSTRACT Electronic Theses and Dissertations (ETDs), as a new generation of scholarship resources, are gradually increasing in number and quality at higher academic institutions. Meanwhile, by introducing various types of software solutions for managing Institutional Repositories (IRs), selection of appropriate solutions has become a time- consuming process for institutions. The goal of this paper was to appraise 59 features of three widely utilized open source IR solutions (DSpace, EPrints, Fedora) from the perspective of managing ETDs, via an in-depth evaluation of their important functionalities in this regard. For this purpose, all applications were installed and the features were tested in a test-bed environment (a benchmark machine) with a predefined set of ETD collections and registered users. Findings related to assessment of each feature were presented in the tabular format. Our comparison indicated that, although all three solutions are capable of managing ETD systems, in most of the comparative areas that are vital for an ETD repository DSpace was ahead of EPrints and Fedora. KEY WORDS: Institutional Repository, DSpace, EPrints, Fedora, Open-source software assessment. INTRODUCTION Nowadays, there is a broad consensus on the vital importance of openness and dissemination of scientific information resources over the Web. -

Exploring Search Engine Optimization (SEO) Techniques for Dynamic Websites
Master Thesis Computer Science Thesis no: MCS-2011-10 March, 2011 __________________________________________________________________________ Exploring Search Engine Optimization (SEO) Techniques for Dynamic Websites Wasfa Kanwal School of Computing Blekinge Institute of Technology SE – 371 39 Karlskrona Sweden This thesis is submitted to the School of Computing at Blekinge Institute of Technology in partial fulfillment of the requirements for the degree of Master of Science in Computer Science. The thesis is equivalent to 20 weeks of full time studies. ___________________________________________________________________________________ Contact Information: Author: Wasfa Kanwal E-mail: [email protected] University advisor: Martin Boldt, PhD. School of Computing School of Computing Internet : www.bth.se/com Blekinge Institute of Technology Phone : +46 455 38 50 00 SE – 371 39 Karlskrona Fax : +46 455 38 50 57 Sweden ii ABSTRACT Context: With growing number of online businesses, Search Engine Optimization (SEO) has become vital to capitalize a business because SEO is key factor for marketing an online business. SEO is the process to optimize a website so that it ranks well on Search Engine Result Pages (SERPs). Dynamic websites are commonly used for e-commerce because they are easier to update and expand; however they are subjected to indexing related problems. Objectives: This research aims to examine and address dynamic websites indexing related issues. To achieve aims and objectives of this research I intend to explore dynamic websites indexing considerations, investigate SEO tools to carry SEO campaign in three major search engines (Google, Yahoo and Bing), experiment SEO techniques, and determine to what extent dynamic websites can be made search engine friendly on these major search engines. -

Check out Our Initial Report Example Here
CGAIN CITATION BUILDING SERVICE CLIENT INFORMATION SHEET REQUIRED BUSINESS INFORMATION BUSINESS NAME : CGain Web Design & SEO BUSINESS OWNER'S NAME : Chris Giles BUSINESS ADDRESS 1 : Millennium House BUSINESS ADDRESS 2 : 161 Mowbray Drive CITY : Blackpool STATEPROVINCE : Lancashire ZIPPOSTAL CODE : FY3 7UN COUNTRY : United Kingdom MAIN PHONE # : 01253 675593 WEBSITE URL : hPps://www.cgain.co.uk BUSINESS EMAIL : [email protected] OTHER BUSINESS INFORMATION TOLL FREE PHONE # : MOBILE # : 07518 931616 FAX # : BUSINESS HOURS : 7 days, 9am to 10pm PAYMENT ACCEPTED : Cash, BACS, Paypal, Visa, Mastercard BUSINESS CATEGORY : Web & SEO Agency SERVICE AREA : United Kingdom KEYWORD(s) : seo, web design, website design, search engine op[misa[on SERVICES : Web design, web development, seo PRODUCT(s) : LOGO URL : hPps://www.cgain.co.uk/wp-content/uploads/2019/10/650x520.jpg hPps://www.cgain.co.uk/wp-content/uploads/2020/06/owllegal-website.jpg, hPps:// www.cgain.co.uk/wp-content/uploads/2020/06/weelz_.jpg,hPps://www.cgain.co.uk/wp- content/uploads/2020/06/mobility-scooters-blackpool.jpg,hPps://www.cgain.co.uk/wp- IMAGE URL(s) : content/uploads/2020/06/quickcrepesburnley.jpg,hPps://www.cgain.co.uk/wp-content/ uploads/2019/03/fleet-equestrian-website-2018.jpg,https://www.cgain.co.uk/ wp-content/uploads/2019/03/magellan.jpg SHORT BUSINESS BIO : CGain Web Design Blackpool provide class-leading, mobile-friendly, responsive and fully op[mised websites for clients of all sizes. We have been developing successful websites since 1995. Our work has covered websites for small local businesses right up to interna[onal human rights organisa[ons. Every website is different, honed to reflect our clients’ exis[ng branding or designed from scratch. -

How Does Google Work?
With Genealogy Links: http://www.ci.oswego.or.us/library/genealogy-presentation How does Google work? Google’s Computers: Google utilizes many computers known as “servers” to administer (serve) Google services. Google likely has around one million servers for different functions including analyzing search queries and delivering search results. One of their largest “server farms” is located in the Dalles, Oregon. Google is very secretive about how many servers it actually has. When you run a search with Google, you’ll notice that Google brags that brings back your results in a fraction of a second —For example: About 11,700,000 results (0.27 seconds), this is the result of many of Google’s servers working together on your search together. Indexing the Web: Google browses the visible web and creates and re-creates an index of the websites it browses. When you run a Google search you aren’t searching the Web itself, but instead Google’s index of sites with links to live pages that it created when it last indexed the web. Google has the largest index of web pages of any search engine, indexing over 55 billion web pages! When Google indexes the web it makes a copy of the site for its “cache”. When you search with Google and come across a website which is currently down, you can mouseover a site in the search results, then the double arrows and then click on “cached” to see what the site recently looked like when it was last indexed or before it went down. Useful for find- ing information that “was just there yesterday!”. -

Metadata Statistics for a Large Web Corpus
Metadata Statistics for a Large Web Corpus Peter Mika Tim Potter Yahoo! Research Yahoo! Research Diagonal 177 Diagonal 177 Barcelona, Spain Barcelona, Spain [email protected] [email protected] ABSTRACT are a number of factors that complicate the comparison of We provide an analysis of the adoption of metadata stan- results. First, different studies use different web corpora. dards on the Web based a large crawl of the Web. In par- Our earlier study used a corpus collected by Yahoo!'s web ticular, we look at what forms of syntax and vocabularies crawler, while the current study uses a dataset collected by publishers are using to mark up data inside HTML pages. the Bing crawler. Bizer et al. analyze the data collected by We also describe the process that we have followed and the http://www.commoncrawl.org, which has the obvious ad- difficulties involved in web data extraction. vantage that it is publicly available. Second, the extraction methods may differ. For example, there are a multitude of microformats (one for each object type) and although most 1. INTRODUCTION search engines and extraction libraries support the popular Embedding metadata inside HTML pages is one of the ones, different processors may recognize a different subset. ways to publish structured data on the Web, often pre- Unlike the specifications of microdata and RDFa published ferred by publishers and consumers over other methods of by the RDFa, the microformat specifications are also rather exposing structured data, such as publishing data feeds, informal and thus different processors may extract different SPARQL endpoints or RDF/XML documents. -
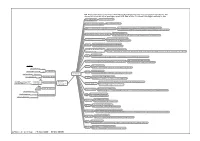
Software B-W.Mmap - 27/04/2009 - ALMA SWAN
N.B. These examples are the most commonly-used packages for Open Access research repositories, but there are many more minor packages. OpenDOAR lists around 70 software packages currently in use. ArchivalWare (PTFS) http://www.ptfs-europe.com/ Archimede (University of Laval) http://archimede.bibl.ulaval.ca http://www.uba.uva.nl/projecten/object.cfm/1A103F4F-A900-4FCF-9BA16965AAE3D75E ARNO (Academic Research in the Netherlands Online Software developed by the ARNO Project: partners were the universities of Amsterdam, Twente and Tilburg http://www.bepress.com/ir/ bepress (Berkeley Electronic Press software) Software on which the Berkeley Electronic Press's Digital Commons (hosted repository service) is run http://cdsware.cern.ch/invenio/index.html CDS Invenio (was CDSware: CERN) A suite of applications for digital library systems http://www.exlibrisgroup.com/category/DigiToolOverview DigiTool Proprietary software from library automation supplier, ExLibris DiVA (Academic Archive Online) http://www.diva-portal.org/about.xsql Publishing System Developed at Uppsala University. A number of Swedish universities run this software and there is a common interface for searching these repositories - the DiVA Portal http://dlibra.psnc.pl dLibra The most popular digital library software in Poland. Over 30 deployments. Sold for a one-time fee of around 250 euros. http://sourceforge.net/projects/doksproject DoKS (Document and Knowledge Sharing application: Sourceforge.net) Digital library software for storing, searching, publishing Examples http://www.dspace.org/ -

Open Access Repository
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by UNL | Libraries University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Library Philosophy and Practice (e-journal) Libraries at University of Nebraska-Lincoln Spring 2-22-2019 Open Access Repository: A Comparative study of Germany, Switzerland and Austria Ramani Ranjan Sahu Indian Institute of Public Health Gandhinagar, [email protected] Lambodara Parabhoi Indian Institute of Advanced Study, Shimla, [email protected] Follow this and additional works at: https://digitalcommons.unl.edu/libphilprac Part of the Library and Information Science Commons Sahu, Ramani Ranjan and Parabhoi, Lambodara, "Open Access Repository: A Comparative study of Germany, Switzerland and Austria" (2019). Library Philosophy and Practice (e-journal). 2511. https://digitalcommons.unl.edu/libphilprac/2511 Open Access Repository: A Comparative study of Germany, Switzerland and Austria By Ramani Ranjan Sahu [email protected] Assistant Librarian cum Documentation Officer Indian Institute of Public Health, Gandhinagar & Lambodara Parabhoi [email protected] Professional Assistant Indian Institute of Advanced Study, Shimla Abstract - Open access movement has been changed dramatically in recent past years. And it has been supported by individual researchers, institutes, organizations and publishers too. The current paper is a comparative study of Open Access Repositories (OARSs) among three European countries Austria Germany, Switzerland registered in Open Access Repository Ranking (OARSR) (http://repositoryranking.org. ) website. It is also discuss and highlights about open access repositories, operational status, top ten repositories by collection wise and policy etc.. The study found that 181 unique open access repositories in three countries where as most of the open access repositories found from Germany160 (88.40 %) repositories.