Thesis Title Different from Above
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Evolution of Physical Demands of Australian Football League Matches from 2005 to 2017: a Systematic Review and Meta-Regression Samuel J
Janetzki et al. Sports Medicine - Open (2021) 7:28 https://doi.org/10.1186/s40798-021-00301-1 SYSTEMATIC REVIEW Open Access Evolution of Physical Demands of Australian Football League Matches from 2005 to 2017: A Systematic Review and Meta-Regression Samuel J. Janetzki1* , Pitre C. Bourdon1, Kevin I. Norton1, Jackson C. Lane1 and Clint R. Bellenger1,2 Abstract Background: There is extensive research investigating the match demands of players in the Australian Football League (AFL). Objective: This systematic literature review and meta-regression sought to analyse the evolution of in-game demands in AFL matches from 2005 to 2017, focusing on the relationship between volume and intensity. Methods: A systematic search of Ovid MEDLINE, Embase, Emcare, Scopus, SPORTDiscus, and Cochrane Library databases was conducted. Included studies examined the physical demands of AFL matches utilising global positioning system (GPS) technology. Meta-regression analysed the shift in reported volume (total distance and total match time) and intensity (metres per minute [m.min−1], sprint duration and acceleration) metrics for overall changes, across quarters and positional groups (forwards, nomadics and defenders) from 2005 to 2017 inclusive and for each year between 2005 and 2007, 2007 and 2010, 2010 and 2012, and 2012 and 2015/2017 breakpoints. Results: Distance (p = 0.094), m.min−1 (p = 0.494), match time (p = 0.591), time over 18 km·h−1 (p=0.271), and number of accelerations greater than 4 km·h−1 (p=0.498) and 10 km·h−1 (p=0.335) in 1 s did not change from 2005 to 2017. -

Melbourne Cricket Ground Trust
MELBOURNE CRICKET GROUND TRUST ANNUAL REPORT 2014/15 TRUSTEES OF THE MCG TRUST Mr. Robert N Herbert AM (Chairman) Mr. Ian Carson The Hon. Peter Costello AC Ms. Jane Fenton AM The Hon. Patrick McNamara Mr. Dale Monteith Mr. Paul O’Malley (Appointed October 2014) Ms. Kathryn (Kate) Palmer (Retired February 2015) Ms. Stephanie Reeves (Appointed October 2014) Mr. Anthony Stewart (Retired May 2014) CHAIRMAN’S REPORT WORLD CRICKET CUP – THE HIGHLIGHT OF THE YEAR It has been a successful year for the MCG, the highlight being the hosting of ICC Cricket World Cup matches including the final which Australia won against New Zealand in front of an Australian record attendance for a single day of cricket of 93,013. This was sweet revenge for Australia after our New Zealand World Cup co-hosts won the first encounter at Eden Park in a thrilling finish. It was an outstanding series all round with five matches at the MCG, including the competition opening game between Australia and England. Fourteen countries participated in 49 matches conducted around Australia and in New Zealand. Attendances exceeded expectations – just on 350,000 patrons filed through the MCG turnstiles. International audiences topped the one billion mark, with the attributes of the MCG and Melbourne on display to the cricketing world. Perhaps the most enthusiastic patrons of all were at the ‘G’ for the India V South Africa clash and Sri Lanka V Bangladesh, both games producing memorable and colourful scenes, charged with patriotism from the local and visiting fans. Having been completely resurfaced following the 2014 AFL season, the MCG playing surface was in outstanding shape for the commencement of cricket commitments in November extending through to the final ball of the World Cricket Cup tournament late in March. -

What's Inside?
What’s Inside? 2017 YEARLY PLANNER PLAYERS EVERY ISSUE DAY ROUND EVENT GAME LOCATION TIME Sat, 18th Round 1 EFFC v CFC East Fremantle Oval 2.15pm MEET MESSAGE FROM Sat, 25th Round 2 CFC BYE 8 THE PLAYERS 4 THE PRESIDENT MARCH Sat, 1st Round 3 PFC v CFC Lathlain Park 1.40pm *7MATE WINMAR MAKING MESSAGE FROM 16 Fri, 7th Round 4 Fathering Project EPFC v CFC Leederville Oval 7.10pm 17 5 THE CEO HIS THIRD START Fri, 14th Round 5 Easter SFFC v CFC Fremantle Oval 4.15pm APRIL Laurie, the MESSAGE FROM HARRIS HAS THE MIDAS Sat, 22nd Round 6 ANZAC CFC v SFC East Fremantle Oval 2.15pm 18 drought buster 6 THE COACH TOUCH Sat, 29th Round 7 SDFC v CFC Steele Blue Oval 2.15pm LEE HAS EYES DISTRICT APRIL Sat, 6th Round 8 CFC v PTFC Fremantle Oval 2.15pm 19 ON A FLAG 24 SCHOOL CLINIC Sat, 13th Round 9 CFC v PFC Fremantle Oval 7.10pm MAY Sat, 20th Round 10 Men’s Health WPFC v CFC HBF Arena Joondalup 2.15pm CLAREMONT MORABITO HOPING 25 WOMEN’S Sat, 27th State Round CFC BYE 20 FOR A MAY START 13 FOOTBALL NEWS Sat, 3rd Round 11 WA Round CFC BYE Sat, 10th Opening Day 1.45pm LE FANU ABOUT OUR 21 CONTINUES HIS Sat, 10th Round 12 Count me in Round CFC v EFFC Claremont Oval 2.15pm 26 2017 SPONSORS FOOTBALL MURPHY REMAINS AT THE JUNE Sat, 17th Round 13 CFC v SDFC Claremont Oval 2.15pm JOURNEY HELM COACHES Sat, 24th Proudie’s Day Sat, 24th Round 14 CFC v WPFC Claremont Oval 2.15pm CLUB AWARDS BRADLEY’S Sat, 1st Round 15 PTFC v CFC Bendigo Bank Stadium 2.15pm 7 SAGE ADVICE Sat, 8th Round 16 NAIDOC Round CFC v SFFC Claremont Oval 1.40pm *7MATE ED & SHIRLEY Sat,15th Round 17 SFC v CFC Esperance 2.15pm JULY 23 HONOURED CONDON AND WHITE Sat, 22nd Round 18 CFC BYE 12 ARE ON BOARD 22 Sat, 29th Round 19 CFC v EPFC Claremont Oval 2.15pm KEN CASELLAS Sat, 5th Round 20 PFC v CFC Lathlain Park 2.15pm 14 TALKS TO THE CLAREMONT SALUTES A Sat, 12th CFC Ladies Day 1.40pm *7MATE COACHES. -

AFL Vic Record Week 2.Indd
TAC Cup Round 2 2 & 3 April 2016 $3.00 Season 2016 kicking into gear Wasn’t it great to have football back last weekend, both at AFL and TAC Cup level? While the next crop of future AFL talent was taking to the field in TAC Cup games throughout Victoria last weekend, it was a highlight of the Easter weekend to see eight draft ees debut in Round 1 of the AFL season – including 2015 Morrish Medal winner Clayton Oliver who claimed the first NAB AFL Rising Star nomination of the season aft er his 22-disposal debut for Melbourne. While the TAC Cup season started last weekend for the best U18 male talent across Victoria, last Monday saw the conclusion of a very successful Youth Girls Academy Challenge for the most promising U18 females across the state. Congratulations to the Dandenong Stingrays, who defeated the Sandringham Dragons in the finale to the month-long tournament. It is pleasing to see TAC support not only the next crop of elite U18 boys but also what will be the next crop of future female AFL footballers via the U18 Youth Girl Academies across eight regions. During the week we celebrated the launch of the Peter Jackson VFL and new VFL Women’s competition. With the launch of a national AFL women’s competition in 2017, it is exciting for AFL Victoria to launch the first VFL Women’s season this weekend. Also at the launch we looked back at the history of the TAC Cup competition, with last week signalling the beginning of its 25th season. -

2016 Jetstream April.Pdf
WESTERN JETS FOOTBALL CLUB Western Jets Football Club Developing Young Men in the West to be the best they can be Western Jets Sponsors Directory Developing young men in the west to meet their full potential 1 Mason St Newport, 3015 MAJOR SPONSOR Postal Address: P.O Box 3170 Newport, 3015 Phone: (03) 9391 0309 Fax: (03) 9391 5497 Shane Sexton: [email protected] Jordan Doyle: [email protected] Website: www.westernjets.aflvic.com.au Facebook: Western Jets FC MAJOR ASSOCIATE SPONSORS April, 2016 Twitter: WesternJetsFC Jetstream University Founded on Principle of Opportunity for All This year Victoria University celebrates its Centenary Year. Footscray Tech began in 1916 when Antarctic explorer Arch Hoadley had a vision of creating opportunities for young men in the western suburbs. Today that school is Victoria University. As an engineer himself he dreamed of developing a skilled workforce of highly educated young men. In short, Footscray Tech students were told to regard an education as the door of opportunity and to strive for the highest standards of personal performance regardless of their backgrounds. Victoria University and the Western Jets TAC Cup Club have embraced the same principles and have been in partnership for almost 20 years. Victoria University are now recognised as a major national sporting university and the Western Jets are developing young people in the TAC Cup so they can reach their full potential. Both organisations benefit significantly of this enduring partnership and in the words of Arch Hoadley are working extremely hard on this original principle ‘opportunity for all’. -
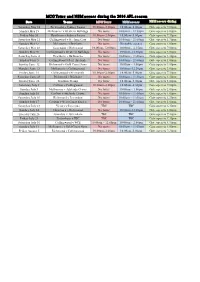
MCG Tours and NSM Access During the 2016 AFL Season
MCG Tours and NSM access during the 2016 AFL season Date Teams MCG Tours NSM access NSM access during event Saturday May 14 Richmond v Sydney Swans 10.00am-2.00pm 10.00am-5.00pm Gate open to 7.00pm Sunday May 15 Melbourne v Western Bulldogs No tours 10.00am - 12.30pm Gate open to 3.00pm Friday May 20 Hawthorn v Sydney Swans 10.00am-2.00pm 10.00am-5.00pm Gate open to 7.30pm Saturday May 21 Collingwood v Geelong Cats No tours 10.00am - 11.00am Gate open to 1.30pm Sunday May 22 Melbourne v Brisbane No tours No public access Gate open to 1.00pm Saturday May 28 Essendon v Richmond 10.00am-12.00pm 10.00am - 2.15pm Gate open to 7.00pm Sunday May 29 Collingwood v Western Bulldogs No tours 10.00am-12.30pm Gate open to 3.00pm Saturday June 4 Hawthorn v Melbourne No tours 10.00am - 11.00am Gate open to 1.30pm Sunday June 5 Collingwood v Port Adelaide No tours 10.00am - 11.00am Gate open to 1.00pm Sunday June 12 Richmond v Gold Coast Suns No tours 10.00am - 1.00pm Gate open to 3.00pm Monday June 13 Melbourne v Collingwood No tours 10.00am-12.30pm Gate open to 3.00pm Friday June 24 Collingwood v Fremantle 10.00am-2.00pm 10.00am-5.00pm Gate open to 7.30pm Saturday June 25 Richmond v Brisbane No tours 10.00am - 11.30am Gate open to 1.30pm Sunday June 26 Stadium Stomp No tours 10.00am-5.00pm Gate open to 5.00pm Saturday July 2 Carlton v Collingwood 10.00am-2.00pm 10.00am-4.30pm Gate open to 7.00pm Sunday July 3 Melbourne v Adelaide Crows No tours 10.00am - 1.00pm Gate open to 3.00pm Sunday July 10 Carlton v Adelaide Crows No tours 10.00am - 11.00am Gate -

AFL on Seven Lines up in 2014
12 March 2014 AFL on Seven lines up in 2014 Sunday Night footy, more Thursday nights, extended Friday Night previews, the return of Talking Footy and three boom new recruits headline the changes for AFL on Seven in 2014. The 2014 AFL season kicks off this week with Seven delivering more blockbuster footy on more nights than ever before as recruits Wayne Carey, Jude Bolton and comedian Mick Molloy join the biggest names in football on Seven’s expanded commentary team. Seven’s coverage launches on Friday Night with an extended match preview starting at the all-new time of 7pm AEDT on 7mate. In Victoria and South Australia the coverage moves to Channel 7 at 7.30pm AEDT. All-time great Wayne Carey features throughout the night as an expert analyst. On Saturdays, comedian Mick Molloy takes a seat on the panel for the Saturday Night Footy pregame show to add a ‘voice from the outer’ with his sharp and irreverent look at the AFL. Swans champion and dual premiership star Jude Bolton also joins the team on Saturday and Sunday afternoons as a field commentator. Throughout the season, Sunday Night Football also comes to primetime on Seven for the first time with two blockbuster matches – the Round 3 clash between Essendon and Carlton, and the Round 15 battle between Carlton and arch enemies Collingwood. There will be more Thursday Night Football in 2014 too, with five matches on Seven, up from three last year. Off the field, Seven’s weekly line-up of AFL programs will also include the return of fan favourites Talking Footy, AFL Game Day and Footy Flashbacks. -

NEMBC EB Autumn Winter 2016
Autumn/WinterSummer/Autumn 2016 2015 Edition Edition – Journal – Journal of the of the National National Ethnic Ethnic & Multicultural & Multicultural Broadcasters’ Broadcasters’ Council Council The National Ethnic and Multicultural Broadcasters’ Council (NEMBC) is a national peak body that advocates for ethnic community broadcasting: promoting multiculturalism, addressing racism and contributing to media diversity. Contents NEMBC Executive Committee President’s Pen ............................................. 1 President: Tangi Steen SA Treasurer: Joe De Luca NT Why Australia Needs a Multicultural Act . 2 Secretary: Luigi Romanelli TAS Australia’s Multicultural Story ................. 3 Nick Dmyterko QLD Cristina Descalzi SA Back Towards a Balanced Language Policy 4 Osai Faiva NSW George Salloum VIC Diversity in the Media .................................. 6 Irene Tavutavu QLD Curtis Ho TAS The Role of the Media in Citizenship .......... 7 Werner Albrecht ACT Manuel Rodrigues WA New Media in Perspective ............................ 8 Abdul Ghannoum NSW Effects of New Media .................................... 9 NEMBC Staff How to Ditch Internalised Racism Executive and Policy Officer: Russell Anderson and Imposter Syndrome ............................ 10 Operations Officer: Fiv Antoniou Project Officer: Tara Egan Public Hysteria Not the Answer ................ 12 Administration Officer: Sarita Yadav Bookkeeper: Rod Borlase Racism. It Stops With Me Campaign ....... 13 The Ethnic Broadcaster Everyday Racism App ............................... -

It's Not ALL About Winning: a Modern Sporting Example to Achieve
It’s not ALL about winning: A modern sporting example to achieve program outcomes Stephen O'Brien Performance coach course: Final Task It’s not ALL about winning: A modern sporting example to achieve program outcomes. PURPOSE: Every coach and player wants to win. This is the one common outcome that all programs have, whether playing at a community rugby level or at the elite performance level of the game. So the question must be asked, if everyone shares winning as a common goal, why is it always at the top of the priorities? Winning is the culmination of culture, core skill and execution. In my years in rugby development, most coaches have emphasised winning often neglecting the process it takes to become winners. In this paper, I will endeavour to use a current sporting example of where placing the emphasis on something other than winning is so much more beneficial - not only to the culture of the environment but also the long term success of the program. INTRODUCTION: Where do we start? The Chicken or Egg scenario… What comes first? Do you design and implement a program to your coaching strengths / strategy and then develop players accordingly OR do you develop your players to be able to adapt to any strategy or style of play required? If we look through a different lens we can potentially open up another world of opportunities for coaches and players. Referencing the Hawthorn Hawks and Alastair Clarkson example, I will demonstrate the possibilities of looking through a different lens in terms of HOW WE DRIVE OUR PROGRAM OUTCOMES. -

Commentating on Cometti… Let’S Go Travelling One Sport
’Normal’ life is returning and our SINGLE? wonderful sitters are FREE We have your partner ready to care for your MONTHLY fur family + home when Providing you can’t be there! personal introductions on a ‘one to one’ basis since 1995 NO COMPUTER NEEDED! 9371 0380 See Friend to Friend page for www.houseandpetsitters.com.au Solutions Contacts Column www.solutionsmatchmaking.com.au LIFESTYLE OPTIONS FOR THE MATURE WESTERN AUSTRALIAN PRINT POST 100022543 VOLUME 29 NO. 11 ISSUE NO. 340 JULY 2020 IN THIS ISSUE Commentating on Cometti… Let’s go travelling one sport. - wander out yonder in WA But he is far from sitting at home every day with his wife Velia. Dennis can still be heard on radio call- Have a Go News’ ing AFL games played in Josephine Allison speaks Western Australia. with Helen Baker Displaying the gentle- manly qualities his voice can’t hide, he unsel shly stayed until the end of the Frank Smith’s interview 2016 AFL season before with 90 plus WA scientist hanging up his micro- Loisette Marsh phone at Channel 7. “Had I got out earlier, it would have been very Food & Wine diffi cult for the network to - Recipes and ideas nd another commentator - Brunch with T and who wasn’t contracted to Dining Divas reviews return someone else,” he said. “I think I could have stopped cold turkey; I Healthy Living don’t think that would - stay well, healthy and keep have been a problem. active “At the same time, half of my problem had been xed by my retirement. -

Big Bash Derby MCG Gets an Brings Record Crowd Security Upgrade ANDY WARHOL the Perfect Style of POP ART Sunglasses for You COBURG ISSUE 12 - January 2016 $1 GST INC
Genzebe Dibaba Crowned 2015 IAAF World Athlete of the Year Big Bash derby MCG gets an brings record crowd security upgrade ANDY WARHOL The Perfect Style of POP ART Sunglasses For You COBURG ISSUE 12 - January 2016 $1 GST INC. 1 CONTENT 3 Sport News: Big Bash Derby brings Record Crowd 5 Archeology: China Ancient Game Board Discovery 4 6 ART: A day out at the NGV with the Kids 10 Cover Story: Genzebe Dibaba crowned Theatre: Broadway musical 2015 IAAF World Athlete of the year Fiddler on the Roof is returning to the Princess Theatre in Melbourne 11 Recreation: Get on your Bike 12 - 13 Relationship: He’s maybe not that interested in you, if you see these ten signs 14 Fashion: Yellow Fashion 15 Fashion: The perfect style of Sunglasses for you ART: Andy Warhol Art 7 Exhibition in National Gallery of Victoria 16 - 17 Computer Game: Runescape Review Part 2 18 New Year’s Resolutions, how to keep it 8-9 19 Computer Game: Five Nights at Freddy’s 20 Crossword & Puzzle: Movie & Word Search SPORT: Melbourne Cricket Ground 21 Cooking: A Friends Halal Trifle (MCG) gets an Enhanced Security 22 Dessert Recipes: Watermelon Six Ways 23 Crossword & Puzzle Answers Upgrade 24 Melbourne Major Events January 2016 CONTRIBUTORS Editor: Khalid Osman Researcher/Writer: Rodney Mouawad Correspondence Supervisor: Anthony Cook Writer: Fonda Makris Part 1 McDonald Street Layout Editor: Shahrzad Jahangirian Writer: Mishaan Magan (MiSH9) Coburg North VIC 3058 Writer: Tania Coleman 2 WOMEN’S DIARY COBURG JANUARY 2016 ISSUE 12 Sport News Inaugural women’s Big Bash derby brings record crowd by: Rodney Mouawad The inaugural women’s Big Bash derby between the Melbourne Renegades and Melbourne Stars drew a domestic and world record crowd. -

MCG Annual Report 2017
ANNUAL REPORT 2016/17 MELBOURNE CRICKET GROUND TRUST TRUSTEES OF THE MCG TRUST 2017 saw the retirement of two very significant members of the MCG Team. Mr RN (Bob) Herbert AM retired as Chair of the Trust in May 2017 and Mr Stephen Gough retired as CEO of the MCC in March. L to R: Ben Foskett (Executive Officer of the Trust), Stuart Fox (The new CEO of the MCC), Stephanie Reeves, Dale Monteith, Stephen Gough (Retired CEO of the MCC), Bob Herbert AM (Retired Chair of the Trust), Hon Pat McNamara, Paul O’Malley, Hon Peter Costello AC, Jane Fenton AM, Ian Carson AM (Absent: Siobhan McKenna & new Trust Chairman, Hon Steve Bracks AC) CHAIRMAN’S REPORT I am delighted to be reporting to MCG stakeholders as the newly appointed Chair of the Melbourne Cricket Ground Trust (the Trust). Since my appointment in late May 2017 l have been tremendously encouraged by the briefings that l’ve received that confirm in my own mind that the MCG continues to meet its objective to be The People’s Ground. This ground has been the site of so many memorable events and activities throughout its history. But it is not so much “the event” that is important, it’s the people’s participation and engagement that make the MCG such a special place. And whilst The G is an iconic and integral part of Melbourne’s and Victoria’s infrastructure, it is also an equally important piece of Australia’s sporting infrastructure….it’s a special place for all Melburnians, all Victorians and all Australians.