Hacking Exposed 5Th Edition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Locating Exploits and Finding Targets
452_Google_2e_06.qxd 10/5/07 12:52 PM Page 223 Chapter 6 Locating Exploits and Finding Targets Solutions in this chapter: ■ Locating Exploit Code ■ Locating Vulnerable Targets ■ Links to Sites Summary Solutions Fast Track Frequently Asked Questions 223 452_Google_2e_06.qxd 10/5/07 12:52 PM Page 224 224 Chapter 6 • Locating Exploits and Finding Targets Introduction Exploits, are tools of the hacker trade. Designed to penetrate a target, most hackers have many different exploits at their disposal. Some exploits, termed zero day or 0day, remain underground for some period of time, eventually becoming public, posted to newsgroups or Web sites for the world to share. With so many Web sites dedicated to the distribution of exploit code, it’s fairly simple to harness the power of Google to locate these tools. It can be a slightly more difficult exercise to locate potential targets, even though many modern Web application security advisories include a Google search designed to locate potential targets. In this chapter we’ll explore methods of locating exploit code and potentially vulnerable targets.These are not strictly “dark side” exercises, since security professionals often use public exploit code during a vulnerability assessment. However, only black hats use those tools against systems without prior consent. Locating Exploit Code Untold hundreds and thousands of Web sites are dedicated to providing exploits to the gen- eral public. Black hats generally provide exploits to aid fellow black hats in the hacking community.White hats provide exploits as a way of eliminating false positives from auto- mated tools during an assessment. Simple searches such as remote exploit and vulnerable exploit locate exploit sites by focusing on common lingo used by the security community. -
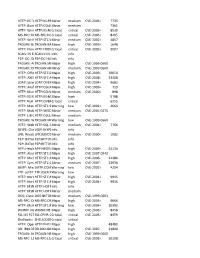
HTTP: IIS "Propfind" Rem HTTP:IIS:PROPFIND Minor Medium
HTTP: IIS "propfind"HTTP:IIS:PROPFIND RemoteMinor DoS medium CVE-2003-0226 7735 HTTP: IkonboardHTTP:CGI:IKONBOARD-BADCOOKIE IllegalMinor Cookie Languagemedium 7361 HTTP: WindowsHTTP:IIS:NSIISLOG-OF Media CriticalServices NSIISlog.DLLcritical BufferCVE-2003-0349 Overflow 8035 MS-RPC: DCOMMS-RPC:DCOM:EXPLOIT ExploitCritical critical CVE-2003-0352 8205 HTTP: WinHelp32.exeHTTP:STC:WINHELP32-OF2 RemoteMinor Buffermedium Overrun CVE-2002-0823(2) 4857 TROJAN: BackTROJAN:BACKORIFICE:BO2K-CONNECT Orifice 2000Major Client Connectionhigh CVE-1999-0660 1648 HTTP: FrontpageHTTP:FRONTPAGE:FP30REG.DLL-OF fp30reg.dllCritical Overflowcritical CVE-2003-0822 9007 SCAN: IIS EnumerationSCAN:II:IIS-ISAPI-ENUMInfo info P2P: DC: DirectP2P:DC:HUB-LOGIN ConnectInfo Plus Plus Clientinfo Hub Login TROJAN: AOLTROJAN:MISC:AOLADMIN-SRV-RESP Admin ServerMajor Responsehigh CVE-1999-0660 TROJAN: DigitalTROJAN:MISC:ROOTBEER-CLIENT RootbeerMinor Client Connectmedium CVE-1999-0660 HTTP: OfficeHTTP:STC:DL:OFFICEART-PROP Art PropertyMajor Table Bufferhigh OverflowCVE-2009-2528 36650 HTTP: AXIS CommunicationsHTTP:STC:ACTIVEX:AXIS-CAMERAMajor Camerahigh Control (AxisCamControl.ocx)CVE-2008-5260 33408 Unsafe ActiveX Control LDAP: IpswitchLDAP:OVERFLOW:IMAIL-ASN1 IMail LDAPMajor Daemonhigh Remote BufferCVE-2004-0297 Overflow 9682 HTTP: AnyformHTTP:CGI:ANYFORM-SEMICOLON SemicolonMajor high CVE-1999-0066 719 HTTP: Mini HTTP:CGI:W3-MSQL-FILE-DISCLSRSQL w3-msqlMinor File View mediumDisclosure CVE-2000-0012 898 HTTP: IIS MFCHTTP:IIS:MFC-EXT-OF ISAPI FrameworkMajor Overflowhigh (via -

Funding by Source Fiscal Year Ending 2019 (Period: 1 July 2018 - 30 June 2019) ICANN Operations (Excluding New Gtld)
Funding by Source Fiscal Year Ending 2019 (Period: 1 July 2018 - 30 June 2019) ICANN Operations (excluding New gTLD) This report summarizes the total amount of revenue by customer as it pertains to ICANN's fiscal year 2019 Customer Class Customer Name Country Total RAR Network Solutions, LLC United States $ 1,257,347 RAR Register.com, Inc. United States $ 304,520 RAR Arq Group Limited DBA Melbourne IT Australia $ 33,115 RAR ORANGE France $ 8,258 RAR COREhub, S.R.L. Spain $ 35,581 RAR NameSecure L.L.C. United States $ 19,773 RAR eNom, LLC United States $ 1,064,684 RAR GMO Internet, Inc. d/b/a Onamae.com Japan $ 883,849 RAR DeluXe Small Business Sales, Inc. d/b/a Aplus.net Canada $ 27,589 RAR Advanced Internet Technologies, Inc. (AIT) United States $ 13,424 RAR Domain Registration Services, Inc. dba dotEarth.com United States $ 6,840 RAR DomainPeople, Inc. United States $ 47,812 RAR Enameco, LLC United States $ 6,144 RAR NordNet SA France $ 14,382 RAR Tucows Domains Inc. Canada $ 1,699,112 RAR Ports Group AB Sweden $ 10,454 RAR Online SAS France $ 31,923 RAR Nominalia Internet S.L. Spain $ 25,947 RAR PSI-Japan, Inc. Japan $ 7,615 RAR Easyspace Limited United Kingdom $ 23,645 RAR Gandi SAS France $ 229,652 RAR OnlineNIC, Inc. China $ 126,419 RAR 1&1 IONOS SE Germany $ 892,999 RAR 1&1 Internet SE Germany $ 667 RAR UK-2 Limited Gibraltar $ 5,303 RAR EPAG Domainservices GmbH Germany $ 41,066 RAR TierraNet Inc. d/b/a DomainDiscover United States $ 39,531 RAR HANGANG Systems, Inc. -

Blockchain Onder De Loep
INNOVATIE IN DE OPSPORING: BLOCKCHAIN ONDER DE LOEP Masterproef neergelegd tot het behalen van de graad van Master in de Criminologische Wetenschappen door (01511852) Vrolix Thomas Academiejaar 2018-2019 Promotor: Commissaris: Prof. dr. Verhage Antoinette Slabbekoorn Geert “Every once in a while, a new technology, an old problem, and a big idea turn into an innovation.” Dean Kamen Executive summary DOEL – Een bijdrage leveren aan de kennisontwikkeling omtrent de inzet en toepassing van de blockchaintechnologie binnen de geïntegreerde politie en de impact ervan op criminaliteit, door de kansen en bedreigingen van blockchain in kaart te brengen. RELEVANTIE – Blockchaintechnologie wordt beschouwd als een disruptieve technologie die een grote impact zal hebben in tal van sectoren en die zich leent tot tal van toepassingen. Daarnaast omarmen ook criminelen blockchain. Het Nationaal Politioneel Veiligheidsbeeld toont aan dat criminelen vaak ‘first adopters’ zijn van de nieuwe technologische mogelijkheden. Daarnaast experimenteren vele overheden en ondernemingen met blockchaintechnologie. Het antwoord op de vraag of blockchaintechnologie ook kansen kan bieden voor de geïntegreerde politie, is zeer relevant. BENADERING – In een eerste stap werd nagegaan wat de barrières en hinderpalen zijn bij het digitaal forensisch onderzoek. De grote opsporingsvraagstukken vandaag de dag liggen immers vooral op het terrein van één van de belangrijkste misdaadproblemen van het huidige tijdsgewricht: high-tech crime. In een volgende stap werd nagegaan wat de basiseigenschappen zijn van blockchaintechnologie. Met deze basiseigenschappen in het achterhoofd werd vervolgens eerst gekeken naar de mogelijkheden die ze bieden binnen de criminele wereld, om te begrijpen waarom politiediensten aandacht moeten hebben voor deze technologie. Daaropvolgend werden de basiseigenschappen van blockchain afgetoetst aan de barrières en hinderpalen bij het digitaal forensisch onderzoek en de (werk)processen binnen de geïntegreerde politie. -

First Quarter 2009
EURID’S QUARTERLY PROGRESS REPORT First Quarter 2009 www.eurid.eu View over Prague 2 EURID’S QUARTERLY PROGRESS REPORT Table of Contents 4 UPDATE 5 FROM THE GENERAL MANAGER 6 ABOUT EURID AND .EU 7 INTERNATIONAL 8 THE .EU DOMAIN 12 THE REGISTRANTS 15 THE REGISTRARS 17 HUMAN RESOURCES 18 THE MANAGEMENT TEAM 19 THE BOARD AND STRATEGIC COMMITTEE FIRST QUARTER 2009 3 Update The .eu top-level domain and its registry, EURid, saw a variety of • Internet Expo, 17-18 February, Stockholm, Sweden developments over the first quarter of 2009. These include the • Innovact, 24-25 March, Reims, France items highlighted below. • 7th European Business Summit, 24-25 March, Brussels, Belgium. New programme launched The Flexible Promo Credit Programme began automatically on 1 Innovative communication January. The programme is similar to a pilot programme which During the first quarter of the year, EURid continued to explore ran last year. Registrars earn one credit for each .eu domain new forms of communication, including a video tutorial and chat name registered during a credit-earning period. Each credit can line. then be used to register one .eu domain name free of charge during a follow-up cash-in period. Registrars choose when The video tutorial was created to help registrars make the most they want a cash-in period to occur, which is what makes the of the new Flexible Promo Credit Programme. The four-minute programme flexible. streaming video included guidelines to help registrars decide which cash-in period might be best for their companies as well Global traveller as the terms and conditions of the programme. -

The Regulation of Abusive Activity and Content: a Study of Registries' Terms
INTERNET POLICY REVIEW Journal on internet regulation Volume 9 | Issue 1 The regulation of abusive activity and content: a study of registries’ terms of service Sebastian Felix Schwemer Centre for Information and Innovation Law (CIIR), University of Copenhagen, Denmark, [email protected] Published on 31 Jan 2020 | DOI: 10.14763/2020.1.1448 Abstract: This paper studies the role of domain registries in relation to unlawful or unwanted use of a domain name or the underlying website content. It is an empirical and conceptual contribution to the online content regulation debate, with specific focus on European country code top-level (ccTLD) domain name registries. An analysis of the terms of service of 30 European ccTLD registries shows that one third of the registries contain some use-related provision, which corresponds to approximately 47% of registered domains. The analysis also turns towards examples of notice-and-takedown mechanisms, the emergence of proactive screening and the practice of data validation. Based on the analysis, it calls for more clarity and transparency regarding domain registries’ role in content- or use-related takedowns. Keywords: Content regulation, Domain names, Terms of Service (TOS), Takedown, Abuse Article information Received: 17 Jul 2019 Reviewed: 10 Oct 2019 Published: 31 Jan 2020 Licence: Creative Commons Attribution 3.0 Germany Funding: This article is the result of a research project that has been funded by the Innovation Fund Denmark and the Danish Internet Forum (DIFO). Competing interests: The author has declared that no competing interests exist that have influenced the text. URL: http://policyreview.info/articles/analysis/regulation-abusive-activity-content-study-registries-terms-se rvice Citation: Schwemer, S. -

PHP Programming Language
PHP Programming Language PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Thu, 17 Jun 2010 01:34:21 UTC Contents Articles Active Agenda 1 Active Calendar 2 Adminer 8 Aigaion 10 Aiki Framework 12 Asido 13 Associate- O- Matic 16 AutoTheme 18 Avactis 19 BakeSale 22 Beehive Forum 23 bitcart 25 BlueErp 29 BuddyPress 30 ccHost 32 Claroline 34 Comparison of knowledge base management software 36 concrete5 42 Coppermine Photo Gallery 44 Croogo 46 DBG 47 Delphi for PHP 47 Doctrine (PHP) 49 Dokeos 52 dotProject 55 User:Drietsch/ pimcore 57 DynPG 58 eAccelerator 59 Elgg (software) 60 EpesiBIM 62 Flash Gallery 64 Flash MP3 Player 66 FluxBB 68 Frog CMS 71 Gallery Project 73 Gamboo Web Suite 75 Gateway Anti- Virus 77 GoogleTap 78 Group- Office 79 Habari 81 Horde (software) 85 HuMo- gen 86 IPBWI 89 Icy Phoenix 91 Ingo (software) 94 Injader 95 Intelestream 96 Internet Messaging Program 98 Invision Power Board 99 ionCube 101 Joomla 103 Joomsef 106 KnowledgeBase Manager Pro 108 List of PHP accelerators 109 List of PHP libraries 112 Magic quotes 113 Mambo (software) 115 Merlintalk 120 MetaBB 122 MiaCMS 123 Midgard (software) 125 Midgard Lite 129 MindTouch Deki 130 Monkey Boards 134 Moodle 135 Moxietype 140 MyBB 141 NETSOFTWARE 144 net2ftp 146 User:Nichescript/ Affiliate Niche Sript 147 Ning (website) 148 NolaPro 152 ORMer 154 ocPortal 155 Open Realty 158 OpenBiblio 159 Opus (content management system) 161 osCommerce 163 PEAR 166 PHP accelerator 167 PHP syntax and semantics 168 PHP/ -
Funding by Source Fiscal Year Ending 2018 (Period: July 1, 2017 - June 30, 2018) ICANN Operations (Excluding New Gtld)
Funding by Source Fiscal Year Ending 2018 (Period: July 1, 2017 - June 30, 2018) ICANN Operations (excluding New gTLD) THIS REPORT SUMMARIZES THE TOTAL AMOUNT OF REVENUE BY CUSTOMER AS IT PERTAINS TO ICANN'S FISCAL YEAR 2018 Customer Name Total Country Class ! #1 Host Australia, Inc. $5,875 United States RAR ! #1 Host Canada, Inc. $5,890 United States RAR ! #1 Host China, Inc. $5,893 United States RAR ! #1 Host Germany, Inc. $5,922 United States RAR ! #1 Host Israel, Inc. $6,681 China RAR ! #1 Host Japan, Inc. $5,884 United States RAR ! #1 Host Korea, Inc. $5,885 United States RAR #1 Internet Services International, Inc. dba 1ISI $667 United States RAR $$$ Private Label Internet Service Kiosk, Inc. (dba "PLISK.com") $5,083 United States RAR .BOX INC. $27,765 Hong Kong RYN .CLUB DOMAINS, LLC $295,296 United States RYN .CO Internet SAS $138,100 Colombia RYC .hr Registry $500 Croatia RYC .TOP Registry $730,692 China RYN 007Names, Inc. $6,346 United States RAR 0101 Internet, Inc. $5,070 Hong Kong RAR 1&1 Internet SE $948,101 Germany RAR 1&1 Mail & Media GmbH $25,015 Germany RYN 101domain Discovery Limited $2,000 Ireland RAR 101domain GRS Limited $27,332 United States RAR 10dencehispahard, S.L. $28,427 Spain RAR 123domainrenewals, LLC $5,520 United States RAR 123-Reg Limited $151,261 United Kingdom RAR 1800-website, LLC $5,513 United States RAR 1API GmbH $140,269 Germany RAR 1st-for-domain-names, LLC $5,513 United States RAR 2030138 Ontario Inc. dba NamesBeyond.com and dba GoodLuckDomain.com -$87 United States RAR 22net, Inc. -

FINFISHER: Basic IT Intrusion 2.0 Fintraining Program Purpose of This Course 2
1 FINFISHER: Basic IT Intrusion 2.0 FinTraining Program Purpose of this course 2 • Get an overview of existing up-to-date Tools and Techniques for different scenarios • Understand the terms and processes of “hacking” • Understand common attack methods Out of Scope 3 • You won’t get a magic-potion to break into environments • You won’t learn how to use automated security scanners • but you will understand their functionality • You won't become an expert on the presented techniques Requirenments 4 • PC/Notebook running BackTrack 5 • Basic TCP/IP networking knowledge • Basic Windows and UNIX/Linux knowledge • Creativity, Intelligence and Motivation(!) Table of Content – Complete Overview 5 1. Overview 2. Footprinting 3. Server Intrusion 4. Client-Side Intrusion 5. Wireless Intrusion 6. Wired Intrusion 7. Web Application 8. Miscellaneous Attacks Table of Content 6 • Overview • History • Scene • Recent Cases History 7 1971 Cap‘n Crunch aka. John Draper Pioneer of Phone Phreaking / Hacking Whistle out of cereal box emulates 2600Hz (AT&T phone system) Free Phone calls History 8 1983 Movie „War Games“ released Introduces „Hacking“ to the public Showing that everyone could possibly break in everywhere History 9 1984 Hacker `Zine „2600“ Followed by „Phrack“ one year later – http://www.phrack.org Regularly publishes content for hacker and phreaker History 10 1988 The Morris Worm Robert T. Morris, Jr – Son of a NSA scientist Self-replicating worm in the ARPAnet 6000 UNIX computers of universities and government were infected History 11 1995 Kevin -

Domain Registration Agreement
Domain Registration Agreement This Domain Registration Agreement ("Registration Agreement") is between Bhosting Solutions ("we," "us," or "Bhosting Solutions"), as the sponsoring registrar, or acting as reseller for the sponsoring registrar identified in the WHOIS record which may be retrieved here, and you, the person or entity registering a domain or domains through Bhosting Solutions. By using Bhosting Solutions' domain registration services (the "Services"), you agree to be bound by this Registration Agreement. Please read this agreement carefully. We may modify, add, or delete portions of this Registration Agreement at any time. In such event, we will post a notice that we have made significant changes to this Registration Agreement on the Bhosting Solutions website for at least 30 days after the changes are posted and will indicate at the bottom of this Registration Agreement the date these terms were last revised. Any revisions to this Registration Agreement will become effective the earlier of (i) the end of such 30-day period or (ii) the first time you access or use the Services after such changes. If you do not agree to abide by this Registration Agreement, you are not authorized to use or access the Services. You acknowledge and agree that Bhosting Solutions may modify this Registration Agreement with or without notice in order to comply with any terms and conditions set forth by ICANN ("Internet Corporation for Assigned Names and Numbers") and/or the applicable registry administrators ("Registry Administrators") for the top level domains ("TLD") or country code top level domains ("ccTLD"). 1. Our Services Your domain registration will be effective upon occurrence of all of the following: a. -

Internet Policy Review
The regulation of abusive activity and content: a study of registries’ terms of service Schwemer, Sebastian Felix Published in: Internet Policy Review DOI: 10.14763/2020.1.1448 Publication date: 2020 Document version Publisher's PDF, also known as Version of record Document license: CC BY Citation for published version (APA): Schwemer, S. F. (2020). The regulation of abusive activity and content: a study of registries’ terms of service. Internet Policy Review, 9(1). https://doi.org/10.14763/2020.1.1448 Download date: 25. sep.. 2021 INTERNET POLICY REVIEW Journal on internet regulation Volume 9 | Issue 1 The regulation of abusive activity and content: a study of registries’ terms of service Sebastian Felix Schwemer Centre for Information and Innovation Law (CIIR), University of Copenhagen, Denmark, [email protected] Published on 31 Jan 2020 | DOI: 10.14763/2020.1.1448 Abstract: This paper studies the role of domain registries in relation to unlawful or unwanted use of a domain name or the underlying website content. It is an empirical and conceptual contribution to the online content regulation debate, with specific focus on European country code top-level (ccTLD) domain name registries. An analysis of the terms of service of 30 European ccTLD registries shows that one third of the registries contain some use-related provision, which corresponds to approximately 47% of registered domains. The analysis also turns towards examples of notice-and-takedown mechanisms, the emergence of proactive screening and the practice of data validation. Based on the analysis, it calls for more clarity and transparency regarding domain registries’ role in content- or use-related takedowns. -
Registration Agreement
REGISTRATION AND SERVICES AGREEMENT This Registration and Services Agreement (together with any Exhibits and Appendices hereto the “Agreement”) is made and entered into by and between you or the entity on behalf of which you are acting, as applicable (referred to herein, interchangeably, as “You,” “Registrant,” or “Customer”), and (i) PSI-USA, Inc., a Nevada corporation or (ii), in the event that You are directly transacting with a Reseller (as defined herein), solely such Reseller (PSI-USA, Inc. or such Reseller, as applicable, are referred to herein as “Provider”). BY SIGNING THIS AGREEMENT OR BY CLICKING THE “I ACCEPT” BUTTON LOCATED AT THE BOTTOM OF THIS PAGE OR SUBMITTING A REQUEST TO REGISTER, RENEW, OR TRANSFER A DOMAIN NAME, YOU AGREE TO BE BOUND BY THIS AGREEMENT. IF YOU DO NOT AGREE TO BE BOUND BY THIS AGREEMENT, PLEASE CLICK THE “I DO NOT ACCEPT” BUTTON. IF YOU DO NOT ACCEPT THIS AGREEMENT, YOUR REQUEST FOR REGISTRATION AND RELATED SERVICES WILL NOT BE PROCESSED AND PROVIDER SHALL HAVE NO OBLIGATION OR LIABILITY TO YOU WHATSOEVER. 1. Definitions All capitalized terms shall have the meaning ascribed to them in this Section 1 or elsewhere in this Agreement. 1.1. “Agreement” is defined in the Preamble. 1.2. “Beneficiary” is defined in Section 4.4. 1.3. “Board” is defined in Section 1.45. 1.4. “Change of Registrant” is defined in Section 4.2. 1.5. “Consensus Policy” has the meaning set forth in the Consensus Policies and Temporary Policies Specification (or any amended or replacement Policy), the current version of which is currently available at https://www.icann.org/resources/pages/approved-with-specs-2013-09-17-en#consensus- temporary.