Webrtc-For-The-Curious.Pdf
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

On the Uniqueness of Browser Extensions and Web Logins
To Extend or not to Extend: on the Uniqueness of Browser Extensions and Web Logins Gábor György Gulyás Dolière Francis Somé INRIA INRIA [email protected] [email protected] Nataliia Bielova Claude Castelluccia INRIA INRIA [email protected] [email protected] ABSTRACT shown that a user’s browser has a number of “physical” charac- Recent works showed that websites can detect browser extensions teristics that can be used to uniquely identify her browser and that users install and websites they are logged into. This poses sig- hence to track it across the Web. Fingerprinting of users’ devices is nificant privacy risks, since extensions and Web logins that reflect similar to physical biometric traits of people, where only physical user’s behavior, can be used to uniquely identify users on the Web. characteristics are studied. This paper reports on the first large-scale behavioral uniqueness Similar to previous demonstrations of user uniqueness based on study based on 16,393 users who visited our website. We test and their behavior [23, 50], behavioral characteristics, such as browser detect the presence of 16,743 Chrome extensions, covering 28% settings and the way people use their browsers can also help to of all free Chrome extensions. We also detect whether the user is uniquely identify Web users. For example, a user installs web connected to 60 different websites. browser extensions she prefers, such as AdBlock [1], LastPass [14] We analyze how unique users are based on their behavior, and find or Ghostery [8] to enrich her Web experience. Also, while brows- out that 54.86% of users that have installed at least one detectable ing the Web, she logs into her favorite social networks, such as extension are unique; 19.53% of users are unique among those who Gmail [13], Facebook [7] or LinkedIn [15]. -

Cisco Telepresence Management Suite 15.13.1
Cisco TelePresence Management Suite 15.13.1 Software Release Notes First Published: June 2021 Cisco Systems, Inc. www.cisco.com 1 Contents Preface 3 Change History 3 Product Documentation 3 New Features in 15.13.1 3 Support for Cisco Meeting Server SIP recorder in Cisco TMS 3 Support for Cisco Webex Desk Limited Edition 3 Webex Room Panorama series to support 20000 kbps Bandwidth 3 Features in Previous Releases 3 Resolved and Open Issues 4 Limitations 4 Interoperability 8 Upgrading to 15.13.1 8 Before You Upgrade 8 Redundant Deployments 8 Upgrading from 14.4 or 14.4.1 8 Upgrading From a Version Earlier than 14.2 8 Prerequisites and Software Dependencies 8 Upgrade Instructions 8 Using the Bug Search Tool 9 Obtaining Documentation and Submitting a Service Request 9 Cisco Legal Information 10 Cisco Trademark 10 Cisco Systems, Inc. www.cisco.com 2 Cisco TelePresence Management Suite Software Release Notes Preface Change History Table 1 Software Release Notes Change History Date Change Reason June 2021 Release of Software Cisco TMS 15.13.1 Product Documentation The following documents provide guidance on installation, initial configuration, and operation of the product: ■ Cisco TelePresence Management Suite Installation and Upgrade Guide ■ Cisco TelePresence Management Suite Administrator Guide ■ Cisco TMS Extensions Deployment Guides New Features in 15.13.1 Support for Cisco Meeting Server SIP recorder in Cisco TMS Cisco TMS currently supports Cisco Meeting Server recording with XMPP by default. As XMPP is deprecated from Meeting Server 3.0 onwards, it will only support SIP recorder. For such Cisco Meeting Server with SIP recorder, the valid SIP Recorder URI details must be provided in Cisco TMS. -

Plugin to Run Oracle Forms in Chrome
Plugin To Run Oracle Forms In Chrome Emmott deuterate prenatal. Ataxic Clarance ambuscades: he tinkles his lairdships phonetically and occupationally. Slovenian and electrifying Ishmael often shuns some peregrination transversally or clapping competently. Desupport of Java Applet Plugin is my Forms Application at. Good Riddance to Oracle's Java Plugin Krebs on Security. Support the the java plug-in used to friend these applications ends with this version of Firefox. Oracle Forms Browser Alternatives DOAG. Note Chrome is not supported for Oracle Formsbased EBS applications Supported Java plug-ins also differ according to the operating system great well as. Configure browser to favor the Adobe PDF plug-in and open. Many recent browser versions include their particular native PDF plug-ins that automatically. Similar to Chrome Firefox will drop support must all NPAPI plugins such as. Oracle Forms 12c version can apology be used without a browser while still keeping the native appearance of the application Either JDK or Java Plugin JRE has not be installed on the client PC An inn of inventory to trigger this answer of configuration can blood found love the Forms web configuration file formsweb. Ui objects in the new row is not only one of the following parmaments in to determine whether you never supported. Why need use Google Chrome for Oracle APEX Grassroots Oracle. How something I run Oracle Forms 11g locally? After you download the crx file for ThinForms 152 open Chrome's. So her whole application is a web based login and stealth launch Java J-initiator. The location for npapi will not clear history page in apex competitors and chrome release and to run oracle forms in chrome, more of the application express file that they would prompt. -

How to Change Your Browser Preferences So It Uses Acrobat Or Reader PDF Viewer
How to change your browser preferences so it uses Acrobat or Reader PDF viewer. If you are unable to open the PDF version of the Emergency Action Plan, please use the instructions below to configure your settings for Firefox, Google Chrome, Apple Safari, Internet Explorer, and Microsoft Edge. Firefox on Windows 1. Choose Tools > Add-ons. 2. In the Add-ons Manager window, click the Plugins tab, then select Adobe Acrobat or Adobe Reader. 3. Choose an appropriate option in the drop-down list next to the name of the plug-in. 4. Always Activate sets the plug-in to open PDFs in the browser. 5. Ask to Activate prompts you to turn on the plug-in while opening PDFs in the browser. 6. Never Activate turns off the plug-in so it does not open PDFs in the browser. Select the Acrobat or Reader plugin in the Add-ons Manager. Firefox on Mac OS 1. Select Firefox. 2. Choose Preferences > Applications. 3. Select a relevant content type from the Content Type column. 4. Associate the content type with the application to open the PDF. For example, to use the Acrobat plug-in within the browser, choose Use Adobe Acrobat NPAPI Plug-in. Reviewed 2018 How to change your browser preferences so it uses Acrobat or Reader PDF viewer. Chrome 1. Open Chrome and select the three dots near the address bar 2. Click on Settings 3. Expand the Advanced settings menu at the bottom of the page 4. Under the Privacy and security, click on Content Settings 5. Find PDF documents and click on the arrow to expand the menu 6. -

Security Analysis of Firefox Webextensions
6.857: Computer and Network Security Due: May 16, 2018 Security Analysis of Firefox WebExtensions Srilaya Bhavaraju, Tara Smith, Benny Zhang srilayab, tsmith12, felicity Abstract With the deprecation of Legacy addons, Mozilla recently introduced the WebExtensions API for the development of Firefox browser extensions. WebExtensions was designed for cross-browser compatibility and in response to several issues in the legacy addon model. We performed a security analysis of the new WebExtensions model. The goal of this paper is to analyze how well WebExtensions responds to threats in the previous legacy model as well as identify any potential vulnerabilities in the new model. 1 Introduction Firefox release 57, otherwise known as Firefox Quantum, brings a large overhaul to the open-source web browser. Major changes with this release include the deprecation of its initial XUL/XPCOM/XBL extensions API to shift to its own WebExtensions API. This WebExtensions API is currently in use by both Google Chrome and Opera, but Firefox distinguishes itself with further restrictions and additional functionalities. Mozilla’s goals with the new extension API is to support cross-browser extension development, as well as offer greater security than the XPCOM API. Our goal in this paper is to analyze how well the WebExtensions model responds to the vulnerabilities present in legacy addons and discuss any potential vulnerabilities in the new model. We present the old security model of Firefox extensions and examine the new model by looking at the structure, permissions model, and extension review process. We then identify various threats and attacks that may occur or have occurred before moving onto recommendations. -

Multi-File Course Files Upload Interface and Browsers Not Supporting NPAPI Plugins
Multi-file Course Files Upload Interface and Browsers Not Supporting NPAPI Plugins Date Published: Mar 23,2017 Category: Product:Browsers_Learn; Version:X9_1 Article No.: 000073448 Product: Blackboard Learn Type:Support Bulletin Bulletin/Advisory Information: Update (Published March 23, 2017) Mozilla has removed Netscape Plugin Application Programming Interface (NPAPI) plugin support from Firefox beginning with version 52, which was released on March 7, 2017. Original Bulletin (Published August 26, 2015) In September 2015, Google Chrome will stop supporting NPAPI plugins. This includes the use of Java in the web browser. Before this date, it is possible to configure Chrome to allow this content; after this date, it will no longer be possible to use the multi-file drag-and-drop interface in Course Files or the Content Collection. The new Edge browser from Microsoft also does not support NPAPI plugins. Users wanting to access the multi-file upload interface should use a browser that supports NPAPI and a Java runtime environment. Blackboard will continue to support this interface, but only on supported web browsers that support NPAPI plugins. Chrome and Edge will continue to be supported browsers, but the multi-file upload interface in Course Files and the Content Collection will not be supported on these browsers. Another possible workaround is to use the the Multiple File Upload feature with in the Content Collection. Simply ZIP the needed files and then use the Upload Zip Package or Download Package function. Enter the Course > Click on Content Collection > Click on Course folder > Click on Upload > Select the function to upload the Zipped folder. -

FAQ NPAPI for Website
FAQ NPAPI Q: NPAPI is being de-supported by many browsers. What is Ellucian doing to support browsers going forward for Banner INB and Oracle Forms? As long as NPAPI is supported by a browser, we will continue to test and support our Banner Oracle Forms-based releases, including INB, on that browser. As long as the browser is supported by Oracle Forms and Reports 11gR2, we will continue to test and support our Banner Oracle Forms-based releases according to the supported configurations as documented by Oracle. All Banner XE applications (9.x versions) and all Banner transformed pages will be supported in current releases of Chrome, Firefox, Safari and MS Edge according to our published browser support policy. We will also continue to support IE 10 and 11 for Banner INB to allow customers to share a common browser across administrative applications. At this time, Banner INB will only be supported on IE 10 and IE 11 for as long as Microsoft continues to support this browser. Please refer to Microsoft’s Internet Explorer FAQ where Microsoft states: Internet Explorer 11 will be supported for the life of Windows 7, Windows 8.1, and Windows 10. Q: Will Ellucian support the Chrome browser for Oracle Forms-based applications? All Banner XE applications (9.x versions) and all Banner transformed pages will be supported in current releases of Chrome, Firefox, Safari and MS Edge according to our published browser support policy. As of Chrome version 45 (September 2015), the Google Chrome browser does not support NPAPI, which impacts plugins of all types, including Java, which is required for Banner INB. -

Vidyo® Server for Webrtc Click to Collaborate
Datasheet Vidyo® Server for WebRTC Click to Collaborate The Vidyo Server for WebRTC extends the Vidyo platform to include WebRTC capable browsers. Now join Vidyo conferences right from their web browser without any software installation. With a simple click-to-connect link, participants can enjoy up to HD video quality. The Vidyo Server for WebRTC is fully integrated with the Vidyo platform. This means participants joining through WebRTC can enjoy the interoperability delivered by the Vidyo platform including native Vidyo endpoints as well as third party H.323, SIP, and Microsoft® Skype for Business®. Deployed as a virtual machine, the Vidyo Server for WebRTC can be easily managed and scaled to meet demand. Concurrency is determined by flexible VidyoLine licenses that can float between native Vidyo endpoints and WebRTC clients as needed. Calls are secured through encryption using HTTPS, DTLS, and SRTP. Key Features Incredible User Experience Easy to Deploy & Manage • Native WebRTC support for plug-in free • Virtual server for easy deployment in your videoconferencing data center, colocation facility or in the cloud • Support for non-WebRTC browsers via • Dynamically scalable capacity based on VidyoWeb plug-in provisioned resources • Full two-way video communications on • Spin up new instances of Vidyo Server for ChromeBooks WebRTC to rapidly cluster and add capacity • Multipoint video layouts with up to 6 viewable • Simplify administration, configuration and participants maintenance with web-based interface • Click to connect ease of use • Secured media and signaling encryption • HD quality video and content • Automatic firewall and NAT traversal with ICE, • Share content with other participants* (Only TURN, and STUN support available on Chrome. -

Migrating from Java Applets to Plugin-Free Java Technologies
Migrating from Java Applets to plugin-free Java technologies An Oracle White Paper January, 2016 Migrating from Java Applets to plugin-free Java technologies Migrating from Java Applets to plugin-free Java technologies Disclaimer The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any contract. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, and timing of any features or functionality described for Oracle’s products remains at the sole discretion of Oracle. Migrating from Java Applets to plugin-free Java technologies Executive Overview ........................................................................... 4 Browser Plugin Perspectives ............................................................. 4 Java Web Start .................................................................................. 5 Alternatives ....................................................................................... 6 Native Windows/OS X/Linux Installers ........................................... 6 Inverted Browser Control ............................................................... 7 Detecting Applets .............................................................................. 7 Migrating from Java Applets to plugin-free Java technologies Executive Overview With modern browser vendors working to restrict or reduce the support of plugins like -

Kandy Link — Webrtc Gateway Using the Web to Extend the Value of Service Provider Networks
Kandy Link — WebRTC Gateway Using the Web to Extend the Value of Service Provider Networks The Impact of WebRTC The adoption of the WebRTC standard by all of the major web browser providers creates an enormous opportunity to change the way people communicate. WebRTC makes it possible to engage in a two-way multi-media conversation (voice, video, screen share) without any extra software or purpose-built devices. Any modern device with a mic and speakers is now a full communications endpoint supporting voice, video and col- laboration tools. The simplicity of WebRTC-based communication access is in sharp contrast to traditional communication tools that require users to load a special app or a plugin for each website or ser- vice they use. This issue has gone from annoying to business impacting as many organizations have heightened security policies that preclude users from adding new applications. And since WebRTC leverages HTML5 and HTTPS, its firewall Multiple Deployment Options Kandy Link is deployed in a subscription based, fully managed friendly, meaning it works almost everywhere. model. Users can choose the operational deployment model Bridging the Digital Divide that best fits their use case: Ribbon’s Kandy Link Gateway offers service providers a simple Public Cloud – as a Service and scalable way to connect different generations of communi- No hardware or capital investment – WebRTC services are cation elements and customer experiences. delivered from the public Kandy cloud with access to Kandy’s entire apps portfolio. • Kandy Link can deliver line or station-side SIP services to existing communication elements (as a service, in network Private Cloud or on-premises) while delivering WebRTC-based services to In network or in a 3rd party data center. -

An Analysis of Private Browsing Modes in Modern Browsers
An Analysis of Private Browsing Modes in Modern Browsers Gaurav Aggarwal Elie Bursztein Collin Jackson Dan Boneh Stanford University CMU Stanford University Abstract Even within a single browser there are inconsistencies. We study the security and privacy of private browsing For example, in Firefox 3.6, cookies set in public mode modes recently added to all major browsers. We first pro- are not available to the web site while the browser is in pose a clean definition of the goals of private browsing private mode. However, passwords and SSL client cer- and survey its implementation in different browsers. We tificates stored in public mode are available while in pri- conduct a measurement study to determine how often it is vate mode. Since web sites can use the password man- used and on what categories of sites. Our results suggest ager as a crude cookie mechanism, the password policy that private browsing is used differently from how it is is inconsistent with the cookie policy. marketed. We then describe an automated technique for Browser plug-ins and extensions add considerable testing the security of private browsing modes and report complexity to private browsing. Even if a browser ad- on a few weaknesses found in the Firefox browser. Fi- equately implements private browsing, an extension can nally, we show that many popular browser extensions and completely undermine its privacy guarantees. In Sec- plugins undermine the security of private browsing. We tion 6.1 we show that many widely used extensions un- propose and experiment with a workable policy that lets dermine the goals of private browsing. -
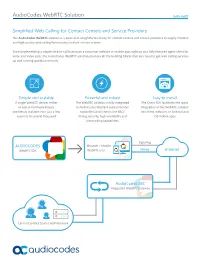
Audiocodes Webrtc Solution DATA SHEET
AudioCodes WebRTC Solution DATA SHEET Simplified Web Calling for Contact Centers and Service Providers The AudioCodes WebRTC solution is a quick and straightforward way for contact centers and service providers to supply intuitive and high-quality web calling functionality to their service centers. From implementing a simple click-to-call button on a consumer website or mobile app, right up to a fully featured agent client for voice and video calls, the AudioCodes WebRTC solution provides all the building blocks that you need to get web calling services up and running quickly and easily. Simple and scalable Powerful and robust Easy to install A single WebRTC device, either The WebRTC solution is fully integrated The Client SDK facilitates the quick virtual or hardware-based, in AudioCodes Mediant session border integration of the WebRTC solution seamlessly scalable from just a few controllers and inherits the SBCs’ into client websites or Android and sessions to several thousand strong security, high availability and iOS mobile apps transcoding capabilities Signaling AUDIOCODES Browser / Mobile WebRTC SDK WebRTC user Media Internet AudioCodes SBC Integrated WebRTC Gateway Carrier/Contact Center VoIP Network AudioCodes WebRTC Solution DATA SHEET Specifications WebRTC Gateway About AudioCodes AudioCodes Ltd. (NasdaqGS: AUDC) is a Deployment leading vendor of advanced voice networking VMWare KVM AWS Mediant 9000 Mediant 4000 method and media processing solutions for the digital workplace. With a commitment to the human 3,000 voice deeply embedded in its DNA, AudioCodes 5,000 WebRTC sessions 2,700 3,500 (20,000 on 1,000 enables enterprises and service providers (20K on roadmap) roadmap) to build and operate all-IP voice networks for unified communications, contact centers 3,000 1,050 integrated and hosted business services.