Parser-Directed Fuzzing
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Improving System Security Through TCB Reduction
Improving System Security Through TCB Reduction Bernhard Kauer March 31, 2015 Dissertation vorgelegt an der Technischen Universität Dresden Fakultät Informatik zur Erlangung des akademischen Grades Doktoringenieur (Dr.-Ing.) Erstgutachter Prof. Dr. rer. nat. Hermann Härtig Technische Universität Dresden Zweitgutachter Prof. Dr. Paulo Esteves Veríssimo University of Luxembourg Verteidigung 15.12.2014 Abstract The OS (operating system) is the primary target of todays attacks. A single exploitable defect can be sufficient to break the security of the system and give fully control over all the software on the machine. Because current operating systems are too large to be defect free, the best approach to improve the system security is to reduce their code to more manageable levels. This work shows how the security-critical part of theOS, the so called TCB (Trusted Computing Base), can be reduced from millions to less than hundred thousand lines of code to achieve these security goals. Shrinking the software stack by more than an order of magnitude is an open challenge since no single technique can currently achieve this. We therefore followed a holistic approach and improved the design as well as implementation of several system layers starting with a newOS called NOVA. NOVA provides a small TCB for both newly written applications but also for legacy code running inside virtual machines. Virtualization is thereby the key technique to ensure that compatibility requirements will not increase the minimal TCB of our system. The main contribution of this work is to show how the virtual machine monitor for NOVA was implemented with significantly less lines of code without affecting the per- formance of its guest OS. -

User's Manual
rBOX610 Linux Software User’s Manual Disclaimers This manual has been carefully checked and believed to contain accurate information. Axiomtek Co., Ltd. assumes no responsibility for any infringements of patents or any third party’s rights, and any liability arising from such use. Axiomtek does not warrant or assume any legal liability or responsibility for the accuracy, completeness or usefulness of any information in this document. Axiomtek does not make any commitment to update the information in this manual. Axiomtek reserves the right to change or revise this document and/or product at any time without notice. No part of this document may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of Axiomtek Co., Ltd. Trademarks Acknowledgments Axiomtek is a trademark of Axiomtek Co., Ltd. ® Windows is a trademark of Microsoft Corporation. Other brand names and trademarks are the properties and registered brands of their respective owners. Copyright 2014 Axiomtek Co., Ltd. All Rights Reserved February 2014, Version A2 Printed in Taiwan ii Table of Contents Disclaimers ..................................................................................................... ii Chapter 1 Introduction ............................................. 1 1.1 Specifications ...................................................................................... 2 Chapter 2 Getting Started ...................................... -

Compiler for Tiny Register Machine
COMPILER FOR TINY REGISTER MACHINE An Undergraduate Research Scholars Thesis by SIDIAN WU Submitted to Honors and Undergraduate Research Texas A&M University in partial fulfillment of the requirements for the designation as an UNDERGRADUATE RESEARCH SCHOLAR Approved by Research Advisor: Dr. Riccardo Bettati May 2015 Major: Computer Science TABLE OF CONTENTS Page ABSTRACT .................................................................................................................................. 1 CHAPTER I INTRODUCTION ................................................................................................ 2 II BACKGROUND .................................................................................................. 5 Tiny Register Machine .......................................................................................... 5 Computer Language syntax .................................................................................. 6 Compiler ............................................................................................................... 7 III COMPILER DESIGN ......................................................................................... 12 Symbol Table ...................................................................................................... 12 Memory Layout .................................................................................................. 12 Recursive Descent Parsing .................................................................................. 13 IV CONCLUSIONS -

An ECMA-55 Minimal BASIC Compiler for X86-64 Linux®
Computers 2014, 3, 69-116; doi:10.3390/computers3030069 OPEN ACCESS computers ISSN 2073-431X www.mdpi.com/journal/computers Article An ECMA-55 Minimal BASIC Compiler for x86-64 Linux® John Gatewood Ham Burapha University, Faculty of Informatics, 169 Bangsaen Road, Tambon Saensuk, Amphur Muang, Changwat Chonburi 20131, Thailand; E-mail: [email protected] Received: 24 July 2014; in revised form: 17 September 2014 / Accepted: 1 October 2014 / Published: 1 October 2014 Abstract: This paper describes a new non-optimizing compiler for the ECMA-55 Minimal BASIC language that generates x86-64 assembler code for use on the x86-64 Linux® [1] 3.x platform. The compiler was implemented in C99 and the generated assembly language is in the AT&T style and is for the GNU assembler. The generated code is stand-alone and does not require any shared libraries to run, since it makes system calls to the Linux® kernel directly. The floating point math uses the Single Instruction Multiple Data (SIMD) instructions and the compiler fully implements all of the floating point exception handling required by the ECMA-55 standard. This compiler is designed to be small, simple, and easy to understand for people who want to study a compiler that actually implements full error checking on floating point on x86-64 CPUs even if those people have little programming experience. The generated assembly code is also designed to be simple to read. Keywords: BASIC; compiler; AMD64; INTEL64; EM64T; x86-64; assembly 1. Introduction The Beginner’s All-purpose Symbolic Instruction Code (BASIC) language was invented by John G. -

Paravirtualizing Linux in a Real-Time Hypervisor
Paravirtualizing Linux in a real-time hypervisor Vincent Legout and Matthieu Lemerre CEA, LIST, Embedded Real Time Systems Laboratory Point courrier 172, F-91191 Gif-sur-Yvette, FRANCE {vincent.legout,matthieu.lemerre}@cea.fr ABSTRACT applications written for a fully-featured operating system This paper describes a new hypervisor built to run Linux in a such as Linux. The Anaxagoros design prevent non real- virtual machine. This hypervisor is built inside Anaxagoros, time tasks to interfere with real-time tasks, thus providing a real-time microkernel designed to execute safely hard real- the security foundation to build a hypervisor to run existing time and non real-time tasks. This allows the execution of non real-time applications. This allows current applications hard real-time tasks in parallel with Linux virtual machines to run on Anaxagoros systems without any porting effort, without interfering with the execution of the real-time tasks. opening the access to a wide range of applications. We implemented this hypervisor and compared perfor- Furthermore, modern computers are powerful enough to mances with other virtualization techniques. Our hypervisor use virtualization, even embedded processors. Virtualiza- does not yet provide high performance but gives correct re- tion has become a trendy topic of computer science, with sults and we believe the design is solid enough to guarantee its advantages like scalability or security. Thus we believe solid performances with its future implementation. that building a real-time system with guaranteed real-time performances and dense non real-time tasks is an important topic for the future of real-time systems. -

Laboratory Experiment #1
x86 and C refresher Lab Background: The x86 is a very widely used microprocessor, it is in Windows and Macintosh personal computers. It is important to be familiar with Intel Architecture, IA. In this lab we will be come familiar with the Intel Architecture using debuggers, assemblers, un-assemblers, and hand assembly. These tools will allow us to enter programs, assemble, execute, debug, and modify programs. Tools and techniques develop in this lab will prepare for using microcontrollers in later labs. C programs in this lab are to refresh C programming knowledge and explore C programming used in microprocessors. Also, this x86 – C refresher Lab will be preparation for using the C programming language to program microcontrollers. Objectives: To be come familiar with how microprocessors operate. To be come familiar with programming microprocessors using machine language, assembly language, and C language. To be come proficient in the use microprocessor debugging tools and techniques. To be come familiar with assemblers and their use in programming microprocessors. To understand how to hand assemble instructions for microprocessors. To understand the program development cycle (program-test-debug- modify-test-debug-repeat until done). To use tracing charts, break points, to verify and debug programs. To develop a program from a flow chart. To write documented code with flow chart and commented code. EEE174 CpE185 Laboratory S Summer 2015 X86 Lab Part 1: Introduction to Debug and C refresher Intro to DEBUG: Debug Monitor, Machine Language, and Assembly Language, Machine Instructions: MOV, SUB, ADD, JGE, INT 20h, and Debug Commands: d, e, u, r, and t Introduction: In this section, you will begin familiarizing yourself with the laboratory equipment. -

Linux Target Image Builder Is a Tool Created by Freescale, That Is Used to Build Linux Target Images, Composed of a Set of Packages
LLinux TTarget IImage BBuilder Based on ltib 6.4.1 ($Revision: 1.8 $ sv) Peter Van Ackeren – [email protected] Sr. Software FAE – Freescale Semiconductor Inc. TM Freescale™ and the Freescale logo are trademarks of Freescale Semiconductor, Inc. All other product or service names are the property of their respective owners. © Freescale Semiconductor, Inc. 2006. LTIB Topics ► ... Philosophy ►... Command Line Options ► ... on the Intranet/Internet ►... BSP Configuration / Build ► ... Package pools ►... Configurations and Build Commands ► ... Policies ►... Working with Individual Packages ► ... Host Support ►... Patch Generation ► ... Installation ►... Publishing a BSP ► ... Directory Structure ►... Tips and Tricks ► ... Commands ►... References indicates advanced material or links for power users Freescale™ and the Freescale logo are trademarks of Freescale Semiconductor, Inc. All other product or service names are TM the property of their respective owners. © Freescale Semiconductor, Inc. 2006. LTIB Philosophy ► Freescale GNU/Linux Target Image Builder is a tool created by Freescale, that is used to build Linux target images, composed of a set of packages ► LTIB has been released under the terms of the GNU General Public License (GPL) ► LTIB BSPs draw packages from a common pool. All that needs to be provided for an LTIB BSP is: 1. cross compiler 2. boot loader sources 3. kernel sources 4. kernel configuration 5. top level config file ... main.lkc 6. BSP config file ... defconfig Freescale™ and the Freescale logo are trademarks -

C Compiler for the VERSAT Reconfigurable Processor
1 C Compiler for the VERSAT Reconfigurable Processor Gonc¸alo R. Santos Tecnico´ Lisboa University of Lisbon Email: [email protected] Abstract—This paper describes de development of a C lan- programmable in assembly using the picoVersat instruction set. guage compiler for picoVersat. picoVersat is the hardware con- The assembler program available for program development is troller for Versat, coarse grain reconfigurable array. The compiler a cumbersome form to port existing algorithms to the Versat is developed as a back-end for the lcc retargetable compiler. The back-end uses a code selection tool for most operations, while platform, most of them written in C or C++. A compiler is some where manually coded. Assembly inline support was added essential for the test and assessement of the Versat platform to the front-end since it was missing from lcc. The compiler capabilities. A first prototype compiler, developed by Rui was integrated into a compilation framework and extensive Santiago [5], exists and was used for the development of some testing was performed. Finally, some limitations were highlighted, examples. However, the compiler is not only not very practical relating to the compiler and picoVersat usage, and some efficiency considerations were addressed. still, but also quite primitive. It supports a limited subset of the C language with C++ alike method invocation, with no Index Terms—Versat, CGRA, picoVersat, C-compiler, lcc back- variables, functions or strucutures. All programming uses the end. picoVersat register names to hold values. Furthermore, the only C++ syntax used is the method invocation from object I. -

Understanding GCC Builtins to Develop Better Tools
Understanding GCC Builtins to Develop Better Tools Manuel Rigger Stefan Marr Johannes Kepler University Linz University of Kent Austria United Kingdom [email protected] [email protected] Bram Adams Hanspeter Mössenböck Polytechnique Montréal Johannes Kepler University Linz Canada Austria [email protected] [email protected] ABSTRACT 1 INTRODUCTION C programs can use compiler builtins to provide functionality that Most C programs consist not only of C code, but also of other the C language lacks. On Linux, GCC provides several thousands elements, such as preprocessor directives, freestanding assembly of builtins that are also supported by other mature compilers, such code files, inline assembly, compiler pragmas, and compiler builtins. as Clang and ICC. Maintainers of other tools lack guidance on While recent studies have highlighted the role of linker scripts [20] whether and which builtins should be implemented to support pop- and inline assembly [53], compiler builtins have so far attracted ular projects. To assist tool developers who want to support GCC little attention. Builtins resemble functions or macros; however, builtins, we analyzed builtin use in 4,913 C projects from GitHub. they are not provided by libc, but are directly implemented in the We found that 37% of these projects relied on at least one builtin. compiler. The following code fragment shows the usage of a GCC Supporting an increasing proportion of projects requires support builtin that returns the number of leading zeros in an integer’s of an exponentially increasing number of builtins; however, imple- binary representation: menting only 10 builtins already covers over 30% of the projects. -

Running a C Program
Running a C Program Kurt Schmidt Dept. of Computer Science, Drexel University April 26, 2021 Kurt Schmidt (Dept. of Computer Science, Drexel University)Running a C Program April 26, 2021 1 / 31 Objectives • Be introduced to the processes that turn C source code into a native executable, and run it • Use this knowledge to better understand errors Kurt Schmidt (Dept. of Computer Science, Drexel University)Running a C Program April 26, 2021 2 / 31 Intro Kurt Schmidt (Dept. of Computer Science, Drexel University)Running a C Program April 26, 2021 3 / 31 Running a C/C++ Program In an IDE, when you push the "Run" button, a number of things happen: 1 Dirty flags are checked on open editor windows 1 Saves, or prompts to save 2 Source code is run through the precompiler 3 The output is then compiled 4 The linker makes the various object files into an executable 5 The loader reads your program from disk and runs it • Or, the debugger performs a similar task Kurt Schmidt (Dept. of Computer Science, Drexel University)Running a C Program April 26, 2021 4 / 31 The gcc Compiler For this lecture I will use the Gnu C Compiler gcc (Ubuntu 7.4.0-1ubuntu1 18.04.1) 7.4.0 • As previously noted, we can compile a C program like this: gcc f1.c f2.c ... fn.c -o exe_name • gcc is actually a wrapper • gcc either performs these functions, or calls another program to do so: 1 Precompile 2 Compile 3 Assemble 4 Link • Note, gcc (like most compilers) is not strictly ISO/ANSI Kurt Schmidt (Dept. -
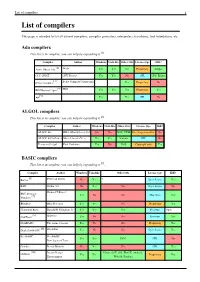
List of Compilers 1 List of Compilers
List of compilers 1 List of compilers This page is intended to list all current compilers, compiler generators, interpreters, translators, tool foundations, etc. Ada compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [2] Aonix Object Ada Atego Yes Yes Yes Proprietary Eclipse GCC GNAT GNU Project Yes Yes No GPL GPS, Eclipse [3] Irvine Compiler Irvine Compiler Corporation Yes Proprietary No [4] IBM Rational Apex IBM Yes Yes Yes Proprietary Yes [5] A# Yes Yes GPL No ALGOL compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? ALGOL 60 RHA (Minisystems) Ltd No No DOS, CP/M Free for personal use No ALGOL 68G (Genie) Marcel van der Veer Yes Yes Various GPL No Persistent S-algol Paul Cockshott Yes No DOS Copyright only Yes BASIC compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [6] BaCon Peter van Eerten No Yes ? Open Source Yes BAIL Studio 403 No Yes No Open Source No BBC Basic for Richard T Russel [7] Yes No No Shareware Yes Windows BlitzMax Blitz Research Yes Yes No Proprietary Yes Chipmunk Basic Ronald H. Nicholson, Jr. Yes Yes Yes Freeware Open [8] CoolBasic Spywave Yes No No Freeware Yes DarkBASIC The Game Creators Yes No No Proprietary Yes [9] DoyleSoft BASIC DoyleSoft Yes No No Open Source Yes FreeBASIC FreeBASIC Yes Yes DOS GPL No Development Team Gambas Benoît Minisini No Yes No GPL Yes [10] Dream Design Linux, OSX, iOS, WinCE, Android, GLBasic Yes Yes Proprietary Yes Entertainment WebOS, Pandora List of compilers 2 [11] Just BASIC Shoptalk Systems Yes No No Freeware Yes [12] KBasic KBasic Software Yes Yes No Open source Yes Liberty BASIC Shoptalk Systems Yes No No Proprietary Yes [13] [14] Creative Maximite MMBasic Geoff Graham Yes No Maximite,PIC32 Commons EDIT [15] NBasic SylvaWare Yes No No Freeware No PowerBASIC PowerBASIC, Inc. -
Compiler Validation Via Equivalence Modulo Inputs
Compiler Validation via Equivalence Modulo Inputs Vu Le Mehrdad Afshari Zhendong Su Department of Computer Science, University of California, Davis, USA {vmle, mafshari, su}@ucdavis.edu Abstract Besides traditional manual code review and testing, the main We introduce equivalence modulo inputs (EMI), a simple, widely compiler validation techniques include testing against popular va- applicable methodology for validating optimizing compilers. Our lidation suites (such as Plum Hall [21] and SuperTest [1]), veri- key insight is to exploit the close interplay between (1) dynamically fication [12, 13], translation validation [20, 22], and random test- executing a program on some test inputs and (2) statically compiling ing [28]. These approaches have complementary benefits. For exam- the program to work on all possible inputs. Indeed, the test inputs ple, CompCert [12, 13] is a formally verified optimizing compiler induce a natural collection of the original program’s EMI variants, for a subset of C, targeting the embedded software domain. It is an which can help differentially test any compiler and specifically target ambitious project, but much work remains to have a fully verified the difficult-to-find miscompilations. production compiler that is correct end-to-end. Another good exam- To create a practical implementation of EMI for validating C ple is Csmith [28], a recent work that generates random C programs compilers, we profile a program’s test executions and stochastically to stress-test compilers. To date, it has found a few hundred bugs prune its unexecuted code. Our extensive testing in eleven months in GCC and LLVM, and helped improve the quality of the most has led to 147 confirmed, unique bug reports for GCC and LLVM widely-used C compilers.