In Support of the AEGIS Weapon System (AWS)
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

2014 Ships and Submarines of the United States Navy
AIRCRAFT CARRIER DDG 1000 AMPHIBIOUS Multi-Purpose Aircraft Carrier (Nuclear-Propulsion) THE U.S. NAvy’s next-GENERATION MULTI-MISSION DESTROYER Amphibious Assault Ship Gerald R. Ford Class CVN Tarawa Class LHA Gerald R. Ford CVN-78 USS Peleliu LHA-5 John F. Kennedy CVN-79 Enterprise CVN-80 Nimitz Class CVN Wasp Class LHD USS Wasp LHD-1 USS Bataan LHD-5 USS Nimitz CVN-68 USS Abraham Lincoln CVN-72 USS Harry S. Truman CVN-75 USS Essex LHD-2 USS Bonhomme Richard LHD-6 USS Dwight D. Eisenhower CVN-69 USS George Washington CVN-73 USS Ronald Reagan CVN-76 USS Kearsarge LHD-3 USS Iwo Jima LHD-7 USS Carl Vinson CVN-70 USS John C. Stennis CVN-74 USS George H.W. Bush CVN-77 USS Boxer LHD-4 USS Makin Island LHD-8 USS Theodore Roosevelt CVN-71 SUBMARINE Submarine (Nuclear-Powered) America Class LHA America LHA-6 SURFACE COMBATANT Los Angeles Class SSN Tripoli LHA-7 USS Bremerton SSN-698 USS Pittsburgh SSN-720 USS Albany SSN-753 USS Santa Fe SSN-763 Guided Missile Cruiser USS Jacksonville SSN-699 USS Chicago SSN-721 USS Topeka SSN-754 USS Boise SSN-764 USS Dallas SSN-700 USS Key West SSN-722 USS Scranton SSN-756 USS Montpelier SSN-765 USS La Jolla SSN-701 USS Oklahoma City SSN-723 USS Alexandria SSN-757 USS Charlotte SSN-766 Ticonderoga Class CG USS City of Corpus Christi SSN-705 USS Louisville SSN-724 USS Asheville SSN-758 USS Hampton SSN-767 USS Albuquerque SSN-706 USS Helena SSN-725 USS Jefferson City SSN-759 USS Hartford SSN-768 USS Bunker Hill CG-52 USS Princeton CG-59 USS Gettysburg CG-64 USS Lake Erie CG-70 USS San Francisco SSN-711 USS Newport News SSN-750 USS Annapolis SSN-760 USS Toledo SSN-769 USS Mobile Bay CG-53 USS Normandy CG-60 USS Chosin CG-65 USS Cape St. -

Fy15 Table of Contents Fy16 Table of Contents
FY15FY16 TABLE OF CONTENTS DOT&E Activity and Oversight FY16 Activity Summary 1 Program Oversight 7 Problem Discovery Affecting OT&E 13 DOD Programs Major Automated Information System (MAIS) Best Practices 23 Defense Agencies Initiative (DAI) 29 Defensive Medical Information Exchange (DMIX) 33 Defense Readiness Reporting System – Strategic (DRRS-S) 37 Department of Defense (DOD) Teleport 41 DOD Healthcare Management System Modernization (DHMSM) 43 F-35 Joint Strike Fighter 47 Global Command and Control System – Joint (GCCS-J) 107 Joint Information Environment (JIE) 111 Joint Warning and Reporting Network (JWARN) 115 Key Management Infrastructure (KMI) Increment 2 117 Next Generation Diagnostic System (NGDS) Increment 1 121 Public Key Infrastructure (PKI) Increment 2 123 Theater Medical Information Program – Joint (TMIP-J) 127 Army Programs Army Network Modernization 131 Network Integration Evaluation (NIE) 135 Abrams M1A2 System Enhancement Program (SEP) Main Battle Tank (MBT) 139 AH-64E Apache 141 Army Integrated Air & Missile Defense (IAMD) 143 Chemical Demilitarization Program – Assembled Chemical Weapons Alternatives (CHEM DEMIL-ACWA) 145 Command Web 147 Distributed Common Ground System – Army (DCGS-A) 149 HELLFIRE Romeo and Longbow 151 Javelin Close Combat Missile System – Medium 153 Joint Light Tactical Vehicle (JLTV) Family of Vehicles (FoV) 155 Joint Tactical Networks (JTN) Joint Enterprise Network Manager (JENM) 157 Logistics Modernization Program (LMP) 161 M109A7 Family of Vehicles (FoV) Paladin Integrated Management (PIM) 165 -

Virtualremembrance Day
JANUARY 2021 YEARin REVIEW A look back at 2020 Admiral’s Commentary The new year ahead VirtualRemembrance Day WalkMLK Jr. Day Observance On the Cover: USS Chung-Hoon Underway File photo by MC1 Devin Langer PHOTO OF THE MONTH Your Navy Team in Hawaii CONTENTS Welcome Commander, Navy Region Hawaii oversees two installations: Joint Base Pearl Harbor-Hickam on Oahu and Pacific Missile Range Facility, Barking Sands, on Kauai. As Naval Surface Group Middle Home Pacific, we provide oversight for the ten surface ships homeported at JBPHH. Navy aircraft squadrons are also co-located at Marine Corps Special Edition USS William P. Lawrence Base Hawaii, Kaneohe, Oahu, and training is sometimes also conducted on other islands, but most Navy assets are located at JBPHH and PMRF. These two installations serve fleet, fighter and family under the direction of Commander, Navy Installations Command. A guided-missile cruiser and destroyers of Commander, Naval Surface Force Pacific deploy Commander independently or as part of a group for Commander, Navy Region Hawaii and U.S. Third Fleet and in the Seventh Fleet and Fifth Naval Surface Group Middle Pacifi c Fleet areas of responsibility. The Navy, including in your Navy team in Hawaii, builds partnerships and REAR ADM. ROBB CHADWICK strengthens interoperability in the Pacific. Each YEAR year, Navy ships, submarines and aircraft from Hawaii participate in various training exercises with allies and friends in the Pacific and Indian Oceans to strengthen interoperability. Navy service members and civilians conduct humanitarian assistance and disaster response missions in the South Pacific and in Asia. Working with the U.S. -

Alternative Naval Force Structure
Alternative Naval Force Structure A compendium by CIMSEC Articles By Steve Wills · Javier Gonzalez · Tom Meyer · Bob Hein · Eric Beaty Chuck Hill · Jan Musil · Wayne P. Hughes Jr. Edited By Dmitry Filipoff · David Van Dyk · John Stryker 1 Contents Preface ................................................................................................................................ 3 The Perils of Alternative Force Structure ................................................... 4 By Steve Wills UnmannedCentric Force Structure ............................................................... 8 By Javier Gonzalez Proposing A Modern High Speed Transport – The Long Range Patrol Vessel ................................................................................................... 11 By Tom Meyer No Time To Spare: Drawing on History to Inspire Capability Innovation in Today’s Navy ................................................................................. 15 By Bob Hein Enhancing Existing Force Structure by Optimizing Maritime Service Specialization .............................................................................................. 18 By Eric Beaty Augment Naval Force Structure By Upgunning The Coast Guard .......................................................................................................... 21 By Chuck Hill A Fleet Plan for 2045: The Navy the U.S. Ought to be Building ..... 25 By Jan Musil Closing Remarks on Changing Naval Force Structure ....................... 31 By Wayne P. Hughes Jr. CIMSEC 22 www.cimsec.org -

US COLD WAR AIRCRAFT CARRIERS Forrestal, Kitty Hawk and Enterprise Classes
US COLD WAR AIRCRAFT CARRIERS Forrestal, Kitty Hawk and Enterprise Classes BRAD ELWARD ILLUSTRATED BY PAUL WRIGHT © Osprey Publishing • www.ospreypublishing.com NEW VANGUARD 211 US COLD WAR AIRCRAFT CARRIERS Forrestal, Kitty Hawk and Enterprise Classes BRAD ELWARD ILLUSTRATED BY PAUL WRIGHT © Osprey Publishing • www.ospreypublishing.com CONTENTS INTRODUCTION 4 ORIGINS OF THE CARRIER AND THE SUPERCARRIER 5 t World War II Carriers t Post-World War II Carrier Developments t United States (CVA-58) THE FORRESTAL CLASS 11 FORRESTAL AS BUILT 14 t Carrier Structures t The Flight Deck and Hangar Bay t Launch and Recovery Operations t Stores t Defensive Systems t Electronic Systems and Radar t Propulsion THE FORRESTAL CARRIERS 20 t USS Forrestal (CVA-59) t USS Saratoga (CVA-60) t USS Ranger (CVA-61) t USS Independence (CVA-62) THE KITTY HAWK CLASS 26 t Major Differences from the Forrestal Class t Defensive Armament t Dimensions and Displacement t Propulsion t Electronics and Radars t USS America, CVA-66 – Improved Kitty Hawk t USS John F. Kennedy, CVA-67 – A Singular Class THE KITTY HAWK AND JOHN F. KENNEDY CARRIERS 34 t USS Kitty Hawk (CVA-63) t USS Constellation (CVA-64) t USS America (CVA-66) t USS John F. Kennedy (CVA-67) THE ENTERPRISE CLASS 40 t Propulsion t Stores t Flight Deck and Island t Defensive Armament t USS Enterprise (CVAN-65) BIBLIOGRAPHY 47 INDEX 48 © Osprey Publishing • www.ospreypublishing.com US COLD WAR AIRCRAFT CARRIERS FORRESTAL, KITTY HAWK AND ENTERPRISE CLASSES INTRODUCTION The Forrestal-class aircraft carriers were the world’s first true supercarriers and served in the United States Navy for the majority of America’s Cold War with the Soviet Union. -

Navy Aegis Ballistic Missile Defense (BMD) Program: Background and Issues for Congress
Navy Aegis Ballistic Missile Defense (BMD) Program: Background and Issues for Congress Updated September 30, 2021 Congressional Research Service https://crsreports.congress.gov RL33745 SUMMARY RL33745 Navy Aegis Ballistic Missile Defense (BMD) September 30, 2021 Program: Background and Issues for Congress Ronald O'Rourke The Aegis ballistic missile defense (BMD) program, which is carried out by the Missile Defense Specialist in Naval Affairs Agency (MDA) and the Navy, gives Navy Aegis cruisers and destroyers a capability for conducting BMD operations. BMD-capable Aegis ships operate in European waters to defend Europe from potential ballistic missile attacks from countries such as Iran, and in in the Western Pacific and the Persian Gulf to provide regional defense against potential ballistic missile attacks from countries such as North Korea and Iran. MDA’s FY2022 budget submission states that “by the end of FY 2022 there will be 48 total BMDS [BMD system] capable ships requiring maintenance support.” The Aegis BMD program is funded mostly through MDA’s budget. The Navy’s budget provides additional funding for BMD-related efforts. MDA’s proposed FY2021 budget requested a total of $1,647.9 million (i.e., about $1.6 billion) in procurement and research and development funding for Aegis BMD efforts, including funding for two Aegis Ashore sites in Poland and Romania. MDA’s budget also includes operations and maintenance (O&M) and military construction (MilCon) funding for the Aegis BMD program. Issues for Congress regarding the Aegis BMD program include the following: whether to approve, reject, or modify MDA’s annual procurement and research and development funding requests for the program; the impact of the COVID-19 pandemic on the execution of Aegis BMD program efforts; what role, if any, the Aegis BMD program should play in defending the U.S. -

Ballistic-Missile Defense
Copyright © 2013, Proceedings, U.S. Naval Institute, Annapolis, Maryland (410) 268-6110 www.usni.org Leading the Way in Ballistic-Missile Defense By Captain George Galdorisi, U.S. Navy (Retired), and Scott C. Truver For the U.S. Navy and a growing number of its partners, the key word is ‘Aegis.’ 32 • December 2013 www.usni.org he United States has put in place an inte- An Indispensable Element grated—if still embryonic—national-level The first priority of the BMD implementation strategy–– ballistic-missile defense system (BMDS). establishing a limited defensive capability against North All elements of the land, sea, air, and Korean ballistic missiles––has largely been achieved with Tspace system are linked together to provide the best Patriot Advanced Capability-3 batteries, the Ground-based affordable defense against a growing threat of bal- Mid-course Defense (GMD) system, the forward-deployed listic missiles, some armed with weapons of mass AN/TPY-2 radar, and Aegis BMD long-range search, cue- destruction (WMD). The U.S. Navy’s contribution is ing, and engagement warships. Aegis BMD interoperates based on the Aegis weapon system and has been on with other assets, including the Terminal High-Altitude Area patrol in guided-missile cruisers and destroyers since Defense (THAAD) system, as well as ground-, air-, and 2004. Aegis BMD has grown in importance based space-based sensors. on its proven performance as well as its long-term Good enough, to be sure. But in his 2009 Proceedings 1 potential. Indeed, at this time Aegis BMD may well article, Commander Denny argued for Aegis to serve as a be the first among equals based on its multimission primary national BMD asset: capabilities as well as its ability to integrate with the emerging BMD capabilities of allied and partner The United States should place a higher priority on its sea- nations. -

BUCCANEER BATTALION Naval Reserve Officer Training Corps Unit UNIVERSITY of SOUTH FLORIDA 4202 E
BUCCANEER BATTALION Naval Reserve Officer Training Corps Unit UNIVERSITY OF SOUTH FLORIDA 4202 E. FOWLER AVENUE TAMPA, FL 33620-8480 30 May 2018 SUBJ: BATTALION KNOWLEDGE PACKET 1. Purpose. To establish a set of knowledge that Midshipman will be accounted for during inspection. 2. Background. In the coming weeks a series of personnel inspections and a written military knowledge test are scheduled. The following is a list of potential knowledge topics that Battalion members should familiarize themselves with them. Inspectors are at liberty to ask any questions, but this should be used as a basic guide to inspection preparation. 3. Chain of Command: The President of the United States The Honorable Donald J. Trump The Secretary of Defense The Honorable James Mattis The Secretary of the Navy The Honorable Richard V. Spencer Chief of Naval Operations ADM John M. Richardson, USN Commandant of the Marine Corps Gen Robert B. Neller, USMC Commander, Naval Education and Training Command RADM Kyle J. Cozad, USN Commanding Officer, NROTCU USF CAPT John R. Schmidt, USN Commanding Officer, Battalion MIDN 1/C Alexander Walker 4. Orders to the Sentry: 1. Take charge of this post and all government property in view. 2. Walk my post in a military manner, keep always on the alert and reporting everything that takes place within site or hearing. 3. Report all violations of orders I am instructed to enforce. 4. Repeat all calls from post more distant from the guardhouse (quarter-deck) than my own. 5. Quit my post only when properly relieved. 6. Receive, obey, and pass on the sentry who relieves me, all orders from the Commanding Officer, Command Duty Officer, Officer of the Day, Officer of the Deck, and Officers and Petty Officers of the watch only. -

American Naval Policy, Strategy, Plans and Operations in the Second Decade of the Twenty- First Century Peter M
American Naval Policy, Strategy, Plans and Operations in the Second Decade of the Twenty- first Century Peter M. Swartz January 2017 Select a caveat DISTRIBUTION STATEMENT A. Approved for public release: distribution unlimited. CNA’s Occasional Paper series is published by CNA, but the opinions expressed are those of the author(s) and do not necessarily reflect the views of CNA or the Department of the Navy. Distribution DISTRIBUTION STATEMENT A. Approved for public release: distribution unlimited. PUBLIC RELEASE. 1/31/2017 Other requests for this document shall be referred to CNA Document Center at [email protected]. Photography Credit: A SM-6 Dual I fired from USS John Paul Jones (DDG 53) during a Dec. 14, 2016 MDA BMD test. MDA Photo. Approved by: January 2017 Eric V. Thompson, Director Center for Strategic Studies This work was performed under Federal Government Contract No. N00014-16-D-5003. Copyright © 2017 CNA Abstract This paper provides a brief overview of U.S. Navy policy, strategy, plans and operations. It discusses some basic fundamentals and the Navy’s three major operational activities: peacetime engagement, crisis response, and wartime combat. It concludes with a general discussion of U.S. naval forces. It was originally written as a contribution to an international conference on maritime strategy and security, and originally published as a chapter in a Routledge handbook in 2015. The author is a longtime contributor to, advisor on, and observer of US Navy strategy and policy, and the paper represents his personal but well-informed views. The paper was written while the Navy (and Marine Corps and Coast Guard) were revising their tri- service strategy document A Cooperative Strategy for 21st Century Seapower, finally signed and published in March 2015, and includes suggestions made by the author to the drafters during that time. -

Aircraft Collection
A, AIR & SPA ID SE CE MU REP SEU INT M AIRCRAFT COLLECTION From the Avenger torpedo bomber, a stalwart from Intrepid’s World War II service, to the A-12, the spy plane from the Cold War, this collection reflects some of the GREATEST ACHIEVEMENTS IN MILITARY AVIATION. Photo: Liam Marshall TABLE OF CONTENTS Bombers / Attack Fighters Multirole Helicopters Reconnaissance / Surveillance Trainers OV-101 Enterprise Concorde Aircraft Restoration Hangar Photo: Liam Marshall BOMBERS/ATTACK The basic mission of the aircraft carrier is to project the U.S. Navy’s military strength far beyond our shores. These warships are primarily deployed to deter aggression and protect American strategic interests. Should deterrence fail, the carrier’s bombers and attack aircraft engage in vital operations to support other forces. The collection includes the 1940-designed Grumman TBM Avenger of World War II. Also on display is the Douglas A-1 Skyraider, a true workhorse of the 1950s and ‘60s, as well as the Douglas A-4 Skyhawk and Grumman A-6 Intruder, stalwarts of the Vietnam War. Photo: Collection of the Intrepid Sea, Air & Space Museum GRUMMAN / EASTERNGRUMMAN AIRCRAFT AVENGER TBM-3E GRUMMAN/EASTERN AIRCRAFT TBM-3E AVENGER TORPEDO BOMBER First flown in 1941 and introduced operationally in June 1942, the Avenger became the U.S. Navy’s standard torpedo bomber throughout World War II, with more than 9,836 constructed. Originally built as the TBF by Grumman Aircraft Engineering Corporation, they were affectionately nicknamed “Turkeys” for their somewhat ungainly appearance. Bomber Torpedo In 1943 Grumman was tasked to build the F6F Hellcat fighter for the Navy. -

A Study in Maritime Piracy
A Study in Maritime Piracy A Report Submitted to the Faculty Of the WORCESTER POLYTECHNIC INSTITUTE In partial fulfillment of the requirements for the Degrees of Bachelor of Science By Laura Barry Benjamin Staver Major: Economic Science Major: System Dynamics MQP MQP Advised by Professor Oleg Pavlov May 7th, 2009 Abstract This MQP evaluated four policies aiming to eliminate piracy off the Somali coast. The rise in piracy caused global concern; in 2009, more than 20 warships from several nations were deployed on anti-piracy missions. The Pirate Fisherman Model was built using system dynamics, and allowed for simulating, testing, and comparison of the four policies. ii Table of Contents Chapter 1: Introduction ............................................................................................................................... 1 Chapter 2: Background ................................................................................................................................ 2 2.1 History of Piracy ................................................................................................................................. 2 2.1.1 Additional terms .......................................................................................................................... 2 2.1.2 Famous pirates ............................................................................................................................ 3 2.2 Modern Piracy ................................................................................................................................... -
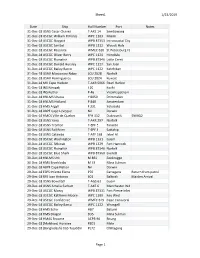
1/23/2019 Sheet1 Page 1 Date Ship Hull Number Port Notes 31-Dec
Sheet1 1/23/2019 Date Ship Hull Number Port Notes 31-Dec-18 USNS Cesar Chavez T-AKE 14 Sembawang 31-Dec-18 USCGC William R Flores WPC 1103 Miami 31-Dec-18 USCGC Skipjack WPB 87353 Intracoastal City 31-Dec-18 USCGC Sanibel WPB 1312 Woods Hole 31-Dec-18 USCGC Resolute WMEC 620 St Petersburg FL 31-Dec-18 USCGC Oliver Berry WPC 1124 Honolulu 31-Dec-18 USCGC Flyingfish WPB 87346 Little Creek 31-Dec-18 USCGC Donald Horsley WPC 1127 San Juan 31-Dec-18 USCGC Bailey Barco WPC 1122 Ketchikan 31-Dec-18 USAV Missionary Ridge LCU 2028 Norfolk 31-Dec-18 USAV Hormigueros LCU 2024 Kuwait 31-Dec-18 MV Cape Hudson T-AKR 5066 Pearl Harbor 31-Dec-18 INS Nirupak J 20 Kochi 31-Dec-18 INS Kuthar P 46 Visakhapatnam 31-Dec-18 HNLMS Urania Y 8050 Drimmelen 31-Dec-18 HNLMS Holland P 840 Amsterdam 31-Dec-18 HMS Argyll F 231 Yokosuka 31-Dec-18 ABPF Cape Leveque Nil Darwin 30-Dec-18 HMCS Ville de Quebec FFH 332 Dubrovnik SNMG2 30-Dec-18 USNS Yano T-AKR 297 Norfolk 30-Dec-18 USNS Trenton T-EPF 5 Taranto 30-Dec-18 USNS Fall River T-EPF 4 Sattahip 30-Dec-18 USNS Catawba T-ATF 168 Jebel Ali 30-Dec-18 USCGC Washington WPB 1331 Guam 30-Dec-18 USCGC Sitkinak WPB 1329 Fort Hancock 30-Dec-18 USCGC Flyingfish WPB 87346 Norfolk 30-Dec-18 USCGC Blue Shark WPB 87360 Everett 30-Dec-18 HNLMS Urk M 861 Zeebrugge 30-Dec-18 HMS Brocklesby M 33 Mina Sulman 30-Dec-18 ABPF Cape Nelson Nil Darwin 29-Dec-18 ESPS Infanta Elena P76 Cartagena Return from patrol 29-Dec-18 RFS Ivan Antonov 601 Baltiysk Maiden Arrival 29-Dec-18 USNS Bowditch T-AGS 62 Guam 29-Dec-18 USNS Amelia Earhart T-AKE 6