China Health and Retirement Longitudinal Study – 2011
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

The Effect of Air Pollution on Migration: Evidence from China
The Effect of Air Pollution on Migration: Evidence from China Shuai Chen, Paulina Oliva and Peng Zhang Abstract This paper looks at the effects of air pollution on migration in China using changes in the average strength of thermal inversions over five-year periods as a source of exogenous variation for medium-run air pollution levels. Our findings suggest that air pollution is responsible for large changes in inflows and outflows of migration in China. Specifically, we find that a 10 percent increase in air pollution, holding everything else constant, is capable of reducing population through net outmigration by about 2.8 percent in a given county. We find that these inflows are primarily driven by well-educated people at the beginning of their professional careers, leading to substantial changes in the sociodemographic composition of the population and labor force of Chinese counties. We also find strong gender asymmetries in the response of mid-age adults that suggests families are splitting across counties to protect vulnerable members of the household. Our results are robust to different specifications, including a spatial lag model that accounts for localized migration spillovers and spatially correlated pollution shocks. Keywords: Air Pollution, migration, human capital, avoidance behaviour JEL Classification Number: O15; Q53; Q56; J24 Contact details: Shuai Chen, Zhejiang University. Email: [email protected] Paulina Oliva, University of Southern California, BREAD and NBER. Email: [email protected] Peng Zhang, The Hong Kong -

Population and Development Review, Volume 27, Number 3
POPULATION AND DEVELOPMENT REVIEW James R. Carey and Debra S. VOLUME 27 NUMBER 3 Judge Life span extension in humans is S E P T E M B E R 2 0 0 1 self-reinforcing: A general theory of longevity Alexander A. Weinreb First politics, then culture: Accounting for ethnic differences in demographic behavior in Kenya Ulrich Mueller Is there a stabilizing selection around average fertility in modern human populations? Zai Liang The age of migration in China Notes and Commentary G. P. Freeman and R. Birrell on divergent paths of immigration politics in the United States and Australia Data and Perspectives R. Schoen and N. Standish on the retrenchment of marriage in the US Archives William Farr on the economic value of the population Book Reviews Review essays by J. E. Cohen and J. A. Goldstone; reviews by J. Mokyr, D. Hodgson, P. Heuveline, E. D. Carlson, J. T. Boerma, and others Documents The socioeconomic impact of the HIV/AIDS epidemic Population and Development Review seeks to advance knowledge of the interrelationships between population and socioeconomic development and provides a forum for discussion of related issues of public policy. EDITOR Paul Demeny MANAGING EDITOR Ethel P. Churchill EDITORIAL COMMITTEE Paul Demeny, Chair Geoffrey McNicoll Ethel P. Churchill Michael P. Todaro Susan Greenhalgh EDITORIAL STAFF Robert Heidel, Production Editor Y. Christina Tse, Production/Design Margaret A. Knoll, Circulation Sura Rosenthal / Mike Vosika, Production ADVISORY BOARD Gustavo Cabrera Milos˘ Macura John C. Caldwell Carmen A. Miró Mercedes B. Concepción Asok Mitra Richard A. Easterlin Samuel H. Preston Akin L. Mabogunje Signed articles are the responsibility of the authors. -

Subways and Urban Air Pollution∗
Subways and Urban Air Pollution∗ Nicolas Gendron-Carrier McGill University † Marco Gonzalez-Navarro UC-Berkeley ‡ Stefano Polloni Mapdwell § Matthew A. Turner Brown University ¶ 18 November 2020 Abstract: We investigate the effect of subway system openings on urban air pollution. On average, particulate concentrations are unchanged by subway openings. For cities with higher initial pollution levels, subway openings reduce particulates by 4% in the area surrounding a city center. The effect decays with distance to city center and persists over the longest time horizon that we can measure with our data, about four years. For highly polluted cities, we estimate that a new subway system provides an external mortality benefit of about $1b per year. For less polluted cities, the effect is indistinguishable from zero. Back of the envelope cost estimates suggest that reduced mortality due to lower air pollution offsets a substantial share of the construction costs of subways. Key words: subways, public transit, air pollution, aerosol optical depth, externalities. jel classification: l91, r4, r11, r14 ∗We are grateful to Christopher Balette, Jessica Burley, Alejandra Hernandez, Tasnia Hussain, Andy Liu, Fern Ramoutar, Mahdy Saddradini, Mohamed Salat, David Valdes, Farhan Yahya, and Guan Yi for research assistance. Assistance from Lynn Carlson and Yi Qi with the MODIS data and from Windsor Jarrod with computing is gratefully acknowledged, as are helpful conversations with Ken Chay and Michelle Marcus, and comments from Leah Brooks, Gabriel Kreindler, Remi Jedwab and many seminar participants. This paper is part of a Global Research Program on Spatial Development of Cities, funded by the Multi-Donor Trust Fund on Sustainable Urbanization by the World Bank and supported by the UK Department for International Development. -

Commencement 2019
COMMENCEMENT 2019 EXERCISES ON THE OCCASION OF THE CONFERRING OF DEGREES THE COLLEGE OF WILLIAM AND MARY IN VIRGINIA WALTER J. ZABLE STADIUM, WILLIAMSBURG, VIRGINIA SATURDAY, MAY 11, 2019 Chancellor President KATHERINE A. ROWE ROBERT M. GATES ’65, L.H.D. ’98 Board of Visitors JOHN E. LITTEL, P ’22, RECTOR WILLIAM H. PAYNE, II ‘01, VICE RECTOR SUE H. GERDELMAN ’76, P ’07, ’13, SECRETARY Virginia Beach, Virginia Richmond, Virginia Williamsburg, Virginia MIRZA BAIG JAMES A. HIXON, J.D. ’79, M.L.T. ’80, P ’08, ’11 KAREN KENNEDY SCHULTZ ’75, P ’06, ’09 Great Falls, Virginia Virginia Beach, Virginia Winchester, Virginia VICTOR K. BRANCH ’84 BARBARA L. JOHNSON, J.D. ’84 TODD A. STOTTLEMYER ’85, P ’16, ’21 South Chesterfield, Virginia Alexandria, Virginia Oakton, Virginia WARREN W. BUCK III, M.S. ’70, PH.D. ’76, D.SC. ’13 ANNE LEIGH KERR ’91, J.D. ’98 H. THOMAS WATKINS, III ’74, P ’05, ’11 Williamsburg, Virginia Richmond, Virginia Naples, Florida S. DOUGLAS BUNCH ’02, J.D. ’06 LISA E. RODAY, P ’13, ’14 BRIAN P. WOOLFOLK, J.D. ’96 Washington, DC Henrico, Virginia Fort Washington, Maryland THOMAS R. FRANTZ ’70, J.D. ’73, M.L.T. ’81, P ’08, ’14 J.E. LINCOLN SAUNDERS ’06 Virginia Beach, Virginia Richmond, Virginia 2018–2019 Staff Liaison 2018–2019 Faculty Representatives 2018-2019 Student Representatives JENNIFER C. FOX ’10 CATHERINE A. FORESTELL BRENDAN J. BOYLAN ’19 William & Mary William & Mary William & Mary MATTHEW J. SMITH KAYLA M. HAND ’19 Richard Bland College Richard Bland College P’ = Parent of W&M Student Table of Contents Order of Exercises 4 Recipients of Honorary Degrees 6 About Commencement 10 The Years in Review: 2015–2019 16 William & Mary Traditions 23 Degree Recipients August 2018 32 January 2019 36 May – August 2019 40 School and Departmental Diploma Ceremonies and Receptions 62 ORDER OF EXERCISES Opening President of W&M Presiding Prelude Bel Canto Brass Quintet Processional* The William & Mary Choir The William & Mary Hymn The National Anthem* The Welcome The President Katherine A. -
Options for Aged Care in China Care Aged Options for DIRECTIONS in DEVELOPMENT DIRECTIONS in Human Development
Options for Aged Care in China Care Aged Options for DIRECTIONS IN DEVELOPMENT Human Development Glinskaya and Feng Options for Aged Care in China Building an Efficient and Sustainable Aged Care System Elena Glinskaya and Zhanlian Feng, Editors Options for Aged Care in China DIRECTIONS IN DEVELOPMENT Human Development Options for Aged Care in China Building an Efficient and Sustainable Aged Care System Elena Glinskaya and Zhanlian Feng, Editors © 2018 International Bank for Reconstruction and Development / The World Bank 1818 H Street NW, Washington, DC 20433 Telephone: 202-473-1000; Internet: www.worldbank.org Some rights reserved 1 2 3 4 21 20 19 18 This work is a product of the staff of The World Bank with external contributions. The findings, interpreta- tions, and conclusions expressed in this work do not necessarily reflect the views of The World Bank, its Board of Executive Directors, or the governments they represent. The World Bank does not guarantee the accuracy of the data included in this work. The boundaries, colors, denominations, and other information shown on any map in this work do not imply any judgment on the part of The World Bank concerning the legal status of any territory or the endorsement or acceptance of such boundaries. Nothing herein shall constitute or be considered to be a limitation upon or waiver of the privileges and immunities of The World Bank, all of which are specifically reserved. Rights and Permissions This work is available under the Creative Commons Attribution 3.0 IGO license (CC BY 3.0 IGO) http:// creativecommons.org/licenses/by/3.0/igo. -

November 9, 2012 Meeting, Board of Trustees
November 9, 2012 meeting, Board of Trustees THE OHIO STATE UNIVERSITY OFFICIAL PROCEEDINGS OF THE ONE THOUSAND FOUR HUNDRED AND SIXTY-SIXTH MEETING OF THE BOARD OF TRUSTEES Columbus, Ohio, November 8 & 9, 2012 The Board of Trustees met Thursday, November 8, and Friday, November 9, 2012, at Longaberger Alumni House, Columbus, Ohio, pursuant to adjournment. ** ** ** Minutes of the last meeting were approved. 259 November 9, 2012 meeting, Board of Trustees The Chairman, Mr. Schottenstein, called the meeting of the Board of Trustees to order on Thursday, November 8, 2012 at 8:36 a.m. Present: Robert H. Schottenstein, Chairman, John C. Fisher, Brian K. Hicks, Ronald A. Ratner, Algenon L. Marbley, Linda S. Kass, William G. Jurgensen, Clark C. Kellogg, Timothy P. Smucker, Alex Shumate, Cheryl L. Krueger, Evann K. Heidersbach and Benjamin T. Reinke, G. Gilbert Cloyd, Corbett A. Price. Mr. Schottenstein: Good morning. I would like to convene the meeting of the Board of Trustees and ask the Secretary to note the attendance. At this time I would ask the Secretary to note attendance. Dr. Horn: A quorum is present, Mr. Chairman. Mr. Schottenstein: I hereby move that the Board recess into Executive Session to consider personnel matters regarding the employment and compensation of public officials, the sale of real or personal property and to consider matters required to be kept confidential by Federal and State statues. May I have a second? Upon motion of Mr. Schottenstein, seconded by Mrs. Kass, the Board of Trustees adopted the foregoing motion by unanimous roll call vote, cast by Trustees Schottenstein, Fisher, Hicks, Shumate, Ratner, Marbley, Kass, Jurgensen, Kellogg, Smucker, and Krueger. -

Human Capital-Firm TFP 201703.Pdf
Human Capital, Technology Adoption and Firm Performance: Impacts of China's Higher Education Expansion in the Late 1990s (Human Capital, Technology, Firm Performance) Yi Che Lei Zhang1 March 2017 Abstract We exploit a policy-induced exogenous surge in China’s college-educated workforce that started in 2003 to identify the impact of human capital on productivity. Using a difference-in-differences estimation strategy, we find that industries using more human-capital intensive technologies experienced a larger gain in total factor productivity after 2003 than they did in prior years. Exploring the pathways from human capital increases to TFP growth, we find that these industries also accelerated new technology adoption, as reflected in the importation of advanced capital goods, R&D expenditure, and capital intensity, as well as employment of more highly skilled individuals. The productivity gains were weaker for domestic private firms than for foreign-owned firms. Key words: human capital; technology adoption; total factor productivity; higher education expansion; China JEL Code: I25; J24; O15; O33 1 Corresponding author: Lei Zhang, Antai College of Economics and Management, Shanghai Jiao Tong University, 1954 Huashan Road, Shanghai 200030, China. Email: [email protected]. This paper benefits from early discussions with Lixin Colin Xu. We thank Alan Auerbach, Stacey Chen, William Dougan, Eric Hanushek, Christos Makridis, Hao Shi, Robert Willis, and seminar participants at Fudan University, Peking University, Renmin University of China, NEUDC, SOLE, and WEAI for helpful comments and suggestions and Ye Peng, Zhaoneng Yuan, Zhicheng Zhang, and Jing Zhao for valuable research assistance. Part of the work was completed when Lei Zhang was visiting the Robert D. -
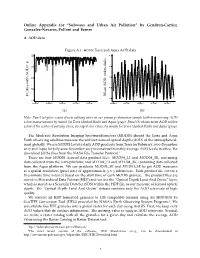
Online Appendix for “Subways and Urban Air Pollution” by Gendron-Carrier, Gonzalez-Navarro, Polloni and Turner
Online Appendix for “Subways and Urban Air Pollution” by Gendron-Carrier, Gonzalez-Navarro, Polloni and Turner A AOD data Figure A.1: modis Terra and Aqua AOD data .7 60 f = .6 6 45 km disks 10 .5 30 .4 15 Mean AOD, # Cities with AOD .3 0 2000m1 2004m1 2008m1 2012m1 2016m1 2000m1 2004m1 2008m1 2012m1 2016m1 (a) (b) Note: Panel (a) gives count of new subway cities in our primary estimation sample with non-missing AOD 10km measurements by month for Terra (dashed black) and Aqua (gray). Panel (b) shows mean AOD within 10km of the center of subway cities, averaged over cities, by month for Terra (dashed black) and Aqua (gray). The Moderate Resolution Imaging Spectroradiometers (MODIS) aboard the Terra and Aqua Earth observing satellites measure the ambient aerosol optical depth (AOD) of the atmosphere al- most globally. We use MODIS Level-2 daily AOD products from Terra for February 2000-December 2017 and Aqua for July 2002-December 2017 to construct monthly average AOD levels in cities. We download all the files from the NASA File Transfer Protocol.1 There are four MODIS Aerosol data product files: MOD04_L2 and MOD04_3K, containing data collected from the Terra platform; and MYD04_L2 and MYD04_3K, containing data collected from the Aqua platform. We use products MOD04_3K and MYD04_3K to get AOD measures at a spatial resolution (pixel size) of approximately 3 x 3 kilometers. Each product file covers a five-minute time interval based on the start time of each MODIS granule. The product files are stored in Hierarchical Data Format (HDF) and we use the "Optical Depth Land And Ocean" layer, which is stored as a Scientific Data Set (SDS) within the HDF file, as our measure of aerosol optical depth. -

Exercises for the Presentation of Diplomas (May 12, 2019) William & Mary Law School
College of William & Mary Law School William & Mary Law School Scholarship Repository Commencement Activities Archives and Law School History 2019 Exercises for the Presentation of Diplomas (May 12, 2019) William & Mary Law School Repository Citation William & Mary Law School, "Exercises for the Presentation of Diplomas (May 12, 2019)" (2019). Commencement Activities. 81. https://scholarship.law.wm.edu/commencement/81 Copyright c 2019 by the authors. This article is brought to you by the William & Mary Law School Scholarship Repository. https://scholarship.law.wm.edu/commencement WILLIAM & MARY LAW SCHOOL FOUNDED 1779 EXERCISES FOR THE PRESENTATION OF DIPLOMAS WILLIAMSBURG, VIRGINIA MARTHA WREN BRIGGS AMPHITHEATRE AT LAKE MATOAKA MAY 12, 2019 8:15 A.M. THE HONORABLE ROGER L. GREGORY CHIEF JUDGE UNITED STATES COURT OF APPEALS FOR THE FOURTH CIRCUIT ROGER L. GREGORY, Chief Judge of the United States Court of Appeals for the Fourth Circuit, formerly a partner in the law firm of Wilder & Gregory, grew up in Petersburg, Virginia, and graduated from Virginia State University and the University of Michigan Law School. He is the first African-American to sit on the United States Court of Appeals for the Fourth Circuit. He received a recess appointment from President William J. Clinton on December 27, 2000, and a nomination from President George W. Bush on May 9, 2001. After confirmation by the Senate, Judge Gregory received the commission for his lifetime appointment to the Court in July 2001. Judge Gregory is the only person in the history of the United States to be appointed to a federal appellate court by two presidents of different political parties.