Competitive Programmer's Handbook
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Parallel Prefix Sum (Scan) with CUDA
Parallel Prefix Sum (Scan) with CUDA Mark Harris [email protected] April 2007 Document Change History Version Date Responsible Reason for Change February 14, Mark Harris Initial release 2007 April 2007 ii Abstract Parallel prefix sum, also known as parallel Scan, is a useful building block for many parallel algorithms including sorting and building data structures. In this document we introduce Scan and describe step-by-step how it can be implemented efficiently in NVIDIA CUDA. We start with a basic naïve algorithm and proceed through more advanced techniques to obtain best performance. We then explain how to scan arrays of arbitrary size that cannot be processed with a single block of threads. Month 2007 1 Parallel Prefix Sum (Scan) with CUDA Table of Contents Abstract.............................................................................................................. 1 Table of Contents............................................................................................... 2 Introduction....................................................................................................... 3 Inclusive and Exclusive Scan .........................................................................................................................3 Sequential Scan.................................................................................................................................................4 A Naïve Parallel Scan ......................................................................................... 4 A Work-Efficient -

Compact Fenwick Trees for Dynamic Ranking and Selection
Compact Fenwick trees for dynamic ranking and selection Stefano Marchini Sebastiano Vigna Dipartimento di Informatica, Universit`adegli Studi di Milano, Italy October 15, 2019 Abstract The Fenwick tree [3] is a classical implicit data structure that stores an array in such a way that modifying an element, accessing an element, computing a prefix sum and performing a predecessor search on prefix sums all take logarithmic time. We introduce a number of variants which improve the classical implementation of the tree: in particular, we can reduce its size when an upper bound on the array element is known, and we can perform much faster predecessor searches. Our aim is to use our variants to implement an efficient dynamic bit vector: our structure is able to perform updates, ranking and selection in logarithmic time, with a space overhead in the order of a few percents, outperforming existing data structures with the same purpose. Along the way, we highlight the pernicious interplay between the arithmetic behind the Fenwick tree and the structure of current CPU caches, suggesting simple solutions that improve performance significantly. 1 Introduction The problem of building static data structures which perform rank and select operations on vectors of n bits in constant time using additional o(n) bits has received a great deal of attention in the last two decades starting form Jacobson's seminal work on succinct data structures. [7] The rank operator takes a position in the bit vector and returns the number of preceding ones. The select operation returns the position of the k-th one in the vector, given k. -

List of Algorithms
List of Algorithms Swiss Olympiad in Informatics September 13, 2012 This list contains a few algorithms that may prove useful when solving SOI or IOI related tasks. The current IOI Syllabus can be found here: http://people.ksp.sk/~misof/ioi-syllabus/ioi-syllabus.pdf Please note that this list simply serves as an outline and that tasks are not limited by the algorithms listed below. However, one can also participate (and even be successful) without knowing the algorithms listed below. To guide you better, the most important topics are in bold. • Sorting1 • Binary Search • Data Structures Stack1 Queue1 List: Linked List, Doubly Linked List1 Tree Sets1 and Tree Maps1 (Binary Search Trees) Priority Queue1 Double ended queue1 Binary Heap Data Structure Interval Tree Segment Tree Disjoint{set Data Structure (Union{Find) Rational Numbers Bignum (Addition, Subtraction, Multiplication, Division) Quad Tree optional: Binary Indexed Tree (BIT) (Fenwick Tree) • Graph Algorithms DFS (Depth{First Search) BFS (Breadth{First Search) Connected Components Topological Sorting (toposort) Shortest Path · Dijkstra's Algorithm · Bellman{Ford Algorithm · Floyd{Warshall's Algorithm (all{pairs shortest path) MST (Minimum Spanning Tree) · Kruskal's Algorithm · Prim's Algorithm · Find Articulation Points (articfind) · Hierholzer's Algorithm (for finding Euler cycles) • Dynamic Programming (DP) Prefix Sum Edit Distance LCS (Longest Common Subsequence) LIS (Longest Increasing Subsequence) MCM (Matrix Chain Multiplication) MER (Maximum Empty Rectangle) -

Survey on Informatics Competitions: Developing Tasks
Olympiads in Informatics, 2011, Vol. 5, 12–25 12 © 2011 Vilnius University Survey on Informatics Competitions: Developing Tasks Lasse HAKULINEN Department of Computer Science and Engineering, Aalto University School of Science P.O.Box 15400, FI-00076 Aalto, Finland e-mail: lasse.hakulinen@aalto.fi Abstract. Informatics competitions offer a motivating way to introduce informatics concepts to students and to find new talents. There are many different competitions in the field of informat- ics with different objectives. In spite of these differences, they all share the same need for high quality tasks. Tasks can be seen as the heart of the competition, so the effort put in developing new tasks should not be underestimated. In this survey, the development of tasks and different task types are discussed. The focus is on the Olympiads in Informatics competitions, but tasks in other competitions are discussed as well. Key words: task development, competition tasks, informatics competitions, IOI, competitions and education. 1. Introduction Motivating students to learn is important for all educators. Competitions offer a conve- nient way to bring informatics concepts to students in a different fashion than regular teaching in schools and universities. It could be said that the tasks are the heart of the competition. Therefore, designing tasks that support the goals of the competition is an important and demanding undertaking. Nowadays, there are many different informatics competitions from small to world- wide events. Also, the types of tasks vary from tasks solved with pen and paper to com- plex problems dealing with large datasets and sophisticated algorithms. Many different types of events offer a wide range of possibilities for students to get involved with infor- matics. -

Generic Implementation of Parallel Prefix Sums and Their
GENERIC IMPLEMENTATION OF PARALLEL PREFIX SUMS AND THEIR APPLICATIONS A Thesis by TAO HUANG Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE May 2007 Major Subject: Computer Science GENERIC IMPLEMENTATION OF PARALLEL PREFIX SUMS AND THEIR APPLICATIONS A Thesis by TAO HUANG Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE Approved by: Chair of Committee, Lawrence Rauchwerger Committee Members, Nancy M. Amato Jennifer L. Welch Marvin L. Adams Head of Department, Valerie E. Taylor May 2007 Major Subject: Computer Science iii ABSTRACT Generic Implementation of Parallel Prefix Sums and Their Applications. (May 2007) Tao Huang, B.E.; M.E., University of Electronic Science and Technology of China Chair of Advisory Committee: Dr. Lawrence Rauchwerger Parallel prefix sums algorithms are one of the simplest and most useful building blocks for constructing parallel algorithms. A generic implementation is valuable because of the wide range of applications for this method. This thesis presents a generic C++ implementation of parallel prefix sums. The implementation applies two separate parallel prefix sums algorithms: a recursive doubling (RD) algorithm and a binary-tree based (BT) algorithm. This implementation shows how common communication patterns can be sepa- rated from the concrete parallel prefix sums algorithms and thus simplify the work of parallel programming. For each algorithm, the implementation uses two different synchronization options: barrier synchronization and point-to-point synchronization. These synchronization options lead to different communication patterns in the algo- rithms, which are represented by dependency graphs between tasks. -
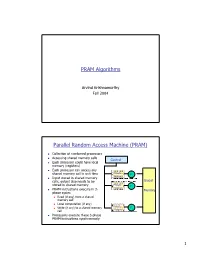
PRAM Algorithms Parallel Random Access Machine
PRAM Algorithms Arvind Krishnamurthy Fall 2004 Parallel Random Access Machine (PRAM) n Collection of numbered processors n Accessing shared memory cells Control n Each processor could have local memory (registers) n Each processor can access any shared memory cell in unit time Private P Memory 1 n Input stored in shared memory cells, output also needs to be Global stored in shared memory Private P Memory 2 n PRAM instructions execute in 3- Memory phase cycles n Read (if any) from a shared memory cell n Local computation (if any) Private n Write (if any) to a shared memory P Memory p cell n Processors execute these 3-phase PRAM instructions synchronously 1 Shared Memory Access Conflicts n Different variations: n Exclusive Read Exclusive Write (EREW) PRAM: no two processors are allowed to read or write the same shared memory cell simultaneously n Concurrent Read Exclusive Write (CREW): simultaneous read allowed, but only one processor can write n Concurrent Read Concurrent Write (CRCW) n Concurrent writes: n Priority CRCW: processors assigned fixed distinct priorities, highest priority wins n Arbitrary CRCW: one randomly chosen write wins n Common CRCW: all processors are allowed to complete write if and only if all the values to be written are equal A Basic PRAM Algorithm n Let there be “n” processors and “2n” inputs n PRAM model: EREW n Construct a tournament where values are compared P0 Processor k is active in step j v if (k % 2j) == 0 At each step: P0 P4 Compare two inputs, Take max of inputs, P0 P2 P4 P6 Write result into shared memory -

Lecture Notes, CSE 232, Fall 2014 Semester
Lecture Notes, CSE 232, Fall 2014 Semester Dr. Brett Olsen Week 1 - Introduction to Competitive Programming Syllabus First, I've handed out along with the syllabus a short pre-questionnaire intended to give us some idea of where you're coming from and what you're hoping to get out of this class. Please fill it out and turn it in at the end of the class. Let me briefly cover the material in the syllabus. This class is CSE 232, Programming Skills Workshop, and we're going to focus on practical programming skills and preparation for programming competitions and similar events. We'll particularly be paying attention to the 2014 Midwest Regional ICPC, which will be November 1st, and I encourage anyone interested to participate. I've been working closely with the local chapter of the ACM, and you should talk to them if you're interesting in joining an ICPC team. My name is Dr. Brett Olsen, and I'm a computational biologist on the Medical School campus. I was invited to teach this course after being contacted by the ACM due to my performance in the Google Code Jam, where I've been consistently performing in the top 5-10%, so I do have some practical experience in these types of contests that I hope can help you improve your performance as well. Assisting me will be TA Joey Woodson, who is also affiliated with the ACM, and would be a good person to contact about the ICPC this fall. Our weekly hour and a half meetings will be split into roughly half lecture and half practical lab work, where I'll provide some sample problems to work on under our guidance. -

Parallel Prefix Sum on the GPU (Scan)
Parallel Prefix Sum on the GPU (Scan) Presented by Adam O’Donovan Slides adapted from the online course slides for ME964 at Wisconsin taught by Prof. Dan Negrut and from slides Presented by David Luebke Parallel Prefix Sum (Scan) Definition: The all-prefix-sums operation takes a binary associative operator ⊕ with identity I, and an array of n elements a a a [ 0, 1, …, n-1] and returns the ordered set I a a ⊕ a a ⊕ a ⊕ ⊕ a [ , 0, ( 0 1), …, ( 0 1 … n-2)] . Example: Exclusive scan: last input if ⊕ is addition, then scan on the set element is not included in [3 1 7 0 4 1 6 3] the result returns the set [0 3 4 11 11 15 16 22] (From Blelloch, 1990, “Prefix 2 Sums and Their Applications) Applications of Scan Scan is a simple and useful parallel building block Convert recurrences from sequential … for(j=1;j<n;j++) out[j] = out[j-1] + f(j); … into parallel : forall(j) in parallel temp[j] = f(j); scan(out, temp); Useful in implementation of several parallel algorithms: radix sort Polynomial evaluation quicksort Solving recurrences String comparison Tree operations Lexical analysis Histograms Stream compaction Etc. HK-UIUC 3 Scan on the CPU void scan( float* scanned, float* input, int length) { scanned[0] = 0; for(int i = 1; i < length; ++i) { scanned[i] = scanned[i-1] + input[i-1]; } } Just add each element to the sum of the elements before it Trivial, but sequential Exactly n-1 adds: optimal in terms of work efficiency 4 Parallel Scan Algorithm: Solution One Hillis & Steele (1986) Note that a implementation of the algorithm shown in picture requires two buffers of length n (shown is the case n=8=2 3) Assumption: the number n of elements is a power of 2: n=2 M Picture courtesy of Mark Harris 5 The Plain English Perspective First iteration, I go with stride 1=2 0 Start at x[2 M] and apply this stride to all the array elements before x[2 M] to find the mate of each of them. -

TCO10-Program.Pdf
10071_TC_TCO10_Program_PQ_1b.indd 1 25/9/10 1:04:24 AM 10071_TC_TCO10_Program_PQ_1b.indd 1 25/9/10 1:04:26 AM Table Of Contents TCO10 Information Sponsors TCO10 Production Credits 3 NSA 1 Founder’s Letter 4 PayPal X Developer Network 22 Tournament Schedule 5 Yandex 32 Meet the Bloggers 7 Facebook 42 The Digital Run 8 TopCoder Admins 41 TCO10 Competition Tracks DESIGN DEVELOPMENT STUDIO Overview 9 Overview 13 Overview 17 Champion 9 Champion 13 Bracket 18 Competitors 10 Competitors 14 Competitors 19 MOD DASH MARATHON ALGORITHM Overview 23 Overview 27 Overview 33 Bracket 24 Bracket 28 Bracket 34 Competitors 25 Competitors 29 Competitors 35 TCO10 2 10071_TC_TCO10_Program_PQ_1b.indd 2 25/9/10 1:04:29 AM TCO10 Production Credits The 2010 TopCoder Open was not possible without the help and dedication from our talented TopCoder members. All the graphics you see onsite and the amazing TCO10 website were done by the TopCoder and Studio community. A special thanks goes to all the members who helped make the TCO10 great! TCO10 WEBSITE TCO10 GRAPHICS TCO10 REVIEWERS Logo Design Sponsor Banner Logo Contests [ rhorea ] [ oninkxronda ] [ rhorea ] [ sigit.a ] TCO10 Banner Icons Contest Icons Design [ kristofferrouge ] [ rhorea ] [ djnapier ] Table Top Graphic Storyboard Storyboard Design [ djnapier ] [ greenspin ] [ leben ] Program Designs UI Prototype UI Prototype [ djnapier ] [ invisiblepilot ] [ leben ] [ selvaa89 ] T-Shirt Design [ bohuss ] Leaderboard Coding and Navigation [ djnapier ] [ YeGGo ] Edits to the Prototype [ AjJi ] Competitions Description Assembly Flash Video [ snow01 ] Content Coding [ r1cs1 ] [ cyberjag ] [ invisiblepilot ] [ BeBetter ] Wordpress Skin Coding [ dweng ] Assembly [ isv ] TCO10 3 Founder’s Letter It’s my great pleasure to welcome each of you to this year’s 2010 TopCoder Open. -

An Empirical Study on Task Documentation in Software Crowdsourcing on Topcoder
An Empirical Study on Task Documentation in Software Crowdsourcing on TopCoder Luis Vaz Igor Steinmacher Sabrina Marczak MunDDos Research Group School of Informatics, Computing, MunDDos Research Group School of Technology and Cyber Systems School of Technology PUCRS, Brazil Northern Arizona University, USA PUCRS, Brazil [email protected] [email protected] [email protected] Abstract—In the Software Crowdsourcingcompetitive model, challenged by the task description. Thus, in this context, crowd members seek for tasks in a platform and submit their the description (or documentation) of the task presented by solutions seeking rewards. In this model, the task description the platform becomes an important factor for the crowd is important to support the choice and the execution of a task. Despite its importance, little is known about the role of task members—who rely on it to choose and execute the tasks— description as support for these processes. To fill this gap, this and for the clients—who aim to receive complete and correct paper presents a study that explores the role of documentation on solutions to their problems. However, little is known about TopCoder platform, focusing on the task selection and execution. how the documentation influences the selection of the tasks We conducted a two-phased study with professionals that had and their subsequent development in the crowdsourcing model. no prior contact with TopCoder. Based on data collected with questionnaires, diaries, and a retrospective session, we could Seeking to contribute to filling this gap in the literature, this understand how people choose and perform the tasks, and the paper presents an empirical study aiming to understand the role of documentation in the platform. -

On Updating and Querying Submatrices
On Updating and Querying Submatrices Jason Yang Mentor: Jun Wan MIT PRIMES Computer Science October 19, 2020 Jason YangMentor: Jun Wan On Updating and Querying Submatrices Range update-query problem A is an array of N numbers A range R = [l; r] is the set of indices fijl ≤ i ≤ rg update(R; v): for all i 2 R, set A[i] to A[i] + v query(R): return mini2R A[i] Segment tree + lazy propagation: O(log N) time updates and queries Jason YangMentor: Jun Wan On Updating and Querying Submatrices Generalizations Using different operators update(R; v): 8i 2 R; A[i] A[i] 5 v query(R; v) : return 4i2R A[i] If 5 and 4 are associative, segment tree + lazy propagation usually works (but not always) Ex. (5; 4) = (+; +) (∗; +) ( ; min) This problem and variants have applications in LCA in a tree image retrieval Jason YangMentor: Jun Wan On Updating and Querying Submatrices Generalizations 2 dimensions: the array becomes a matrix ranges fijl ≤ i ≤ rg becomes submatrices [l0; r0][l1; r1] = fijl0 ≤ i ≤ r0g × fjjl1 ≤ j ≤ r1g We call this the submatrix update-query problem. Jason YangMentor: Jun Wan On Updating and Querying Submatrices Previous Work Generalizing segment tree seems to be very difficult update query d = 1 Segment Tree O(log N) O(log N) d = 2 2D Segment Tree O(N log N) O(log2 N) Quadtree O(N) O(N) d = 2, special operator pairs (5; 4) 2D Fenwick Tree (Mishra) O(16 log2 N) O(16 log2 N) 2D Segment Tree (Ibtehaz) O(log2 N) O(log2 N) 2D Segment Tree (ours) O(log2 N) O(log2 N) Jason YangMentor: Jun Wan On Updating and Querying Submatrices Intuition Why is -

Combinatorial Species and Labelled Structures Brent Yorgey University of Pennsylvania, [email protected]
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations 1-1-2014 Combinatorial Species and Labelled Structures Brent Yorgey University of Pennsylvania, [email protected] Follow this and additional works at: http://repository.upenn.edu/edissertations Part of the Computer Sciences Commons, and the Mathematics Commons Recommended Citation Yorgey, Brent, "Combinatorial Species and Labelled Structures" (2014). Publicly Accessible Penn Dissertations. 1512. http://repository.upenn.edu/edissertations/1512 This paper is posted at ScholarlyCommons. http://repository.upenn.edu/edissertations/1512 For more information, please contact [email protected]. Combinatorial Species and Labelled Structures Abstract The theory of combinatorial species was developed in the 1980s as part of the mathematical subfield of enumerative combinatorics, unifying and putting on a firmer theoretical basis a collection of techniques centered around generating functions. The theory of algebraic data types was developed, around the same time, in functional programming languages such as Hope and Miranda, and is still used today in languages such as Haskell, the ML family, and Scala. Despite their disparate origins, the two theories have striking similarities. In particular, both constitute algebraic frameworks in which to construct structures of interest. Though the similarity has not gone unnoticed, a link between combinatorial species and algebraic data types has never been systematically explored. This dissertation lays the theoretical groundwork for a precise—and, hopefully, useful—bridge bewteen the two theories. One of the key contributions is to port the theory of species from a classical, untyped set theory to a constructive type theory. This porting process is nontrivial, and involves fundamental issues related to equality and finiteness; the recently developed homotopy type theory is put to good use formalizing these issues in a satisfactory way.