The Desktop File System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Illusion of Space and the Science of Data Compression And
The Illusion of Space and the Science of Data Compression and Deduplication Bruce Yellin EMC Proven Professional Knowledge Sharing 2010 Bruce Yellin Advisory Technology Consultant EMC Corporation [email protected] Table of Contents What Was Old Is New Again ......................................................................................................... 4 The Business Benefits of Saving Space ....................................................................................... 6 Data Compression Strategies ....................................................................................................... 9 Data Compression Basics ....................................................................................................... 10 Compression Bakeoff .............................................................................................................. 13 Data Deduplication Strategies .................................................................................................... 16 Deduplication - Theory of Operation ....................................................................................... 16 File Level Deduplication - Single Instance Storage ................................................................. 21 Fixed-Block Deduplication ....................................................................................................... 23 Variable-Block Deduplication .................................................................................................. 24 Content-Aware Deduplication -
Microsoft Windows for MS
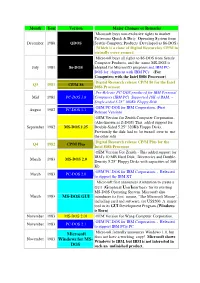
Month Year Version Major Changes or Remarks Microsoft buys non-exclusive rights to market Pattersons Quick & Dirty Operating System from December 1980 QDOS Seattle Computer Products (Developed as 86-DOS) (Which is a clone of Digital Researches C P/M in virtually every respect) Microsoft buys all rights to 86-DOS from Seattle Computer Products, and the name MS-DOS is July 1981 86-DOS adopted for Microsoft's purposes and IBM PC- DOS for shipment with IBM PCs (For Computers with the Intel 8086 Processor) Digital Research release CP/M 86 for the Intel Q3 1981 CP/M 86 8086 Processer Pre-Release PC-DOS produced for IBM Personal Mid 1981 PC-DOS 1.0 Computers (IBM PC) Supported 16K of RAM, ~ Single-sided 5.25" 160Kb Floppy Disk OEM PC-DOS for IBM Corporation. (First August 1982 PC-DOS 1.1 Release Version) OEM Version for Zenith Computer Corporation.. (Also known as Z-DOS) This added support for September 1982 MS-DOS 1.25 Double-Sided 5.25" 320Kb Floppy Disks. Previously the disk had to be turned over to use the other side Digital Research release CP/M Plus for the Q4 1982 CP/M Plus Intel 8086 Processer OEM Version For Zenith - This added support for IBM's 10 MB Hard Disk, Directories and Double- March 1983 MS-DOS 2.0 Density 5.25" Floppy Disks with capacities of 360 Kb OEM PC-DOS for IBM Corporation. - Released March 1983 PC-DOS 2.0 to support the IBM XT Microsoft first announces it intention to create a GUI (Graphical User Interface) for its existing MS-DOS Operating System. -

“Killer” Acquisitions in the Digital Economy
REMEMBER STACKER? ANOTHER LOOK AT “KILLER” ACQUISITIONS IN THE DIGITAL ECONOMY BY BENOIT D’UDEKEM, DIVYA MATHUR & MARC VAN AUDENRODE1 1 Vice President, Analysis Group, Brussels, Belgium, Vice President, Analysis Group, Chicago, United States, and Managing Principal, Analysis Group, Brussels, Belgium. CPI ANTITRUST CHRONICLE I. INTRODUCTION MAY 2020 In 1990, a small software corporation, Stac Electronics, released a drive compression software called Stacker that doubled PC hard drives’ volume. At that time, hard drives had limited capacity and were expensive. Unsur- “Killer Acquisitions,” Big Tech, and prisingly, the drive compression software was hugely successful. In 1993, Microsoft released version 6.0 of its flagship operating system, MS-DOS, Section 2: A Solution in Search of a which included its own compression software. This led to a long legal bat- Problem tle between Microsoft and Stac Electronics, at the end of which Microsoft By Kristen C. Limarzi & Harry R. S. Phillips had to remove its drive compression feature from MS-DOS and compen- sate Stac Electronics. “How Tech Rolls”: Potential Competition and “Reverse” Killer Acquisitions Today, perhaps Microsoft would simply buy Stac Electronics and By Cristina Caffarra, Gregory S. Crawford spare itself the legal headache. & Tommaso Valletti Would that be a bad outcome? Maybe not. Economists have long The No Kill Zone: The Other Side of debated the relationship between incumbency, market power and innova- Pharma Acquisitions tion, with no unambiguous answer to date. Incumbents and monopolists By Jacqueline Grise, David Burns may have less incentive to innovate2 (the so-called “replacement effect”), & Elizabeth Giordano but may also be better at innovating3 (the so-called “efficiency effect”). -

III IIII US005532694A United States Patent (19) 11 Patent Number: 5,532,694 Mayers Et Al
III IIII US005532694A United States Patent (19) 11 Patent Number: 5,532,694 Mayers et al. (45. Date of Patent: Jul. 2, 1996 (54) DATA COMPRESSION APPARATUS AND FOREIGN PATENT DOCUMENTS METHOD USING MATCHING STRING SEARCHING AND HUFFMAN ENCODING 2625527 3/1978 Germany. 57-132242 8/1982 Japan. (75 Inventors: Clay Mayers, San Diego; Douglas L. OTHER PUBLICATIONS Whiting,Ing, Carlsbad, both oof Calif. Bar-Ness et al. "String Dictionary Structure for Markov (73) Assignee: Stac Electronics, Inc., San Diego, Arithmetic Encoding," IEEE International Conference on Calif. Communications, vol. 1, Jun. 1988, New York, pp.395-399. English translation of German Patent No. 26 25527, 1978. Berkovich, S. et al., "Matching String Patterns in Large 21 Appl. No.: 499,230 Textual Files,' Department of Electrical Engineering and 22 Filed: Jul. 7, 1995 Computer Science, George Washington Univ., pp. 122-127, 1985. Related U.S. Application Data Boyer, R., “A Fast String Searching Algorithm', Commu nications of the ACM 2010), 762–772, 1977. 63 Continuation of Ser. No. 927,343, Aug. 10, 1992, aban- Cleary, J., "Compact Hash Tables Using Bidirectional Lin doned, which is a continuation-in-part of Ser. No. 870,554, ear Probing'; IEEE Transactions on Computers c-33(9): Apr. 17, 1992, abandoned, which is a continuation of Ser. 828-834, 1984. No.division 619,291, of s"N, Nov. 27, 1990,5. Pat. A.No. 5,146,221,13, 6.E. which N.i Collmeyer, A. et al., “Analysis of Retrieval Performance for 5,016,009. Selected File Organization Techniques.” Proc. Fall Joint (51) Int. Cl. -

Virus Bulletin, May 1993
May 1993 ISSN 0956-9979 THE AUTHORITATIVE INTERNATIONAL PUBLICATION ON COMPUTER VIRUS PREVENTION, RECOGNITION AND REMOVAL Editor: Richard Ford Technical Editor: Fridrik Skulason Consulting Editor: Edward Wilding, Network Security Management, UK Advisory Board: Jim Bates, Bates Associates, UK, Andrew Busey, Datawatch Corporation, USA, David M. Chess, IBM Research, USA, Phil Crewe, Ziff-Davis, UK, David Ferbrache, Defence Research Agency, UK, Ray Glath, RG Software Inc., USA, Hans Gliss, Datenschutz Berater, West Germany, Igor Grebert, McAfee Associates, USA,Ross M. Greenberg, Software Concepts Design, USA, Dr. Harold Joseph Highland, Compulit Microcomputer Security Evaluation Laboratory, USA, Dr. Jan Hruska, Sophos, UK, Dr. Keith Jackson, Walsham Contracts, UK, Owen Keane, Barrister, UK, John Laws, Defence Research Agency, UK, Dr. Tony Pitt, Digital Equipment Corporation, UK, Yisrael Radai, Hebrew University of Jerusalem, Israel, Martin Samociuk, Network Security Management, UK, John Sherwood, Sherwood Associates, UK, Prof. Eugene Spafford, Purdue University, USA, Dr. Peter Tippett, Certus Corporation, USA, Steve R. White, IBM Research, USA, Dr. Ken Wong, PA Consulting Group, UK, Ken van Wyk, CERT, USA. CONTENTS VIRUS ANALYSES 1. The Volga Virus Family 9 EDITORIAL 2. Pitch - A new Virus High Note 10 Better DOS than DOS? 2 3. Loren - Viral Nitroglycerine? 12 IN MEMORIAM FEATURE David Lindsay 3 The Other Virus War 14 VIRUS PREVALENCE TABLE 3 PRODUCT REVIEWS NEWS Popping Up 3 1. MS-DOS 6: Worth the Wait? 17 McAfee Makes a Deal? 4 2. VET - The Wizard of Oz 20 Dirty Macs 4 INDUSTRY WATCH IBM PC VIRUSES (UPDATE) 5 ICVC ’93 - Virus Hunting in Bulgaria 23 INSIGHT Bates: Blues and Roots 7 END NOTES & NEWS 24 VIRUS BULLETIN ©1993 Virus Bulletin Ltd, 21 The Quadrant, Abingdon Science Park, Oxon, OX14 3YS, England. -

Jonathan Burt's Presentation on The
EVOLUTION OF HOME SOFTWARE The history of software and how it has evolved and changed over the years for home (and business) users. Welcome • Who am I? • Jonathan A Burt BSc Cert Mgmt HND FIAP IEng MBCS CITP • Batchelor of Science Degree (Open) • Professional Certificate in Management • Higher National Diploma in Computing • Fellow of the Institute of Analysts and Programmers • Incorporated Engineer with the Engineering Council • Member of the British Computer Society • Charted IT Professional • PRINCE2 Practitioner • Certified Novell Administrator (v5.x) • 25+ years experience of working in IT. • Long time member of the Isle of Wight PC User Group! Software Evolution • Over the years software and operating systems have evolved quite drastically. • Gone are the days of the Command Line Interface (CLI), and it’s all Windows and Mouse! • I have tried to show how our use of computers have changed with regard to the evolution of software. • Apologies if I don’t cover your “favourite”! 8bit, 16bit, 32bit, 64bit • Modern PCs use the x86 architecture and as such have limitations on the physical memory range within which they can operate, for example 2x where ‘x’ is: • 8-bit = 256K • 16-bit = 65,536K (i.e. 64 KB) • 32-bit = 4,294,967,296K (i.e. 4 GB) • 64-bit = 18,446,744,073,709,551,616 (i.e. 16 Exabyte or 18,000,000 Terabytes!) Operating Systems - DOS • The dominant Disk Operating System when IBM created the IBM PC, was CP/M (Control Program/Monitor and later Control Program for Microcomputers) owned by Digital Research for the 8-bit Intel 8080 range of processors. -

MISOSYS Products Get the Job Done!
Look at what is in this issue: R'~q wr IBM PC Line Drawing, by Roy Soltoff ev AMORT1: Amortization Table, by Andrew M. Kunz ow Yet ANother HiRes Graphics Format, by Hans de Wolf Reusing NEC Laser Cartridges, by Roy Soltoff BACKUP Basics, by Scott Toenniessen ' New price list for TMQ subscribers, MISOSYS products get the job done! - TRIj . iI _ - ri Volume VlI.i $10 Winter92/93 PRICE LIST for TMQ Subscribers - effective Jan 1, 1993 TRS-80 Software (items on Closeout) TRS-80 Game Programs (items on Closeout) Product Nomenclature Mod Ill Mod 4 Price S&H AFM Auto File Manager data base P.50-310 n/a $10.00 D Cornsoft Group Game Disk: Bouncezoids, Crazy Painter, BackRest for hard drives P-12-244 P-12-244 $10.00 Frogger, Scarfman, Space Castle (M3) M-55-GCA $20.00 BASIC/S Compiler System P-20-010 n/a $10.00B Kim Watt's Hits (M3) P-55-GKW $9.95 BSORT / BSORT4 L-32-200 L-32-210 $5.00 Lair of the Dragon (M3/M4) M-55-021 $10.00 CP/M (MM) Hard Disk Drivers H-MM-??? $10.00 B Lance Miklus' Hits (M3) P-55-GLM $15.00 CON80Z I PRO-CON80Z. M-30-033 M-31-033 $5.00 Leo Cristopherson's (M3) P-55-GLC $10.00 diskDISK / LS-diskDISK L-35-211 L-35-212 $10.00 The Gobbling Box (M3/M4) M-55-020 $10.00 DoubleDuty M-02-231 $25.00 DSM51 / DSM4 L-35-204 L-35-205 $10.005 MSDOS Game Programs DSMBLR / PRO-DUCE M-30-053 M-31-053 $10.00 Lair of the Dragon M-86-021 $10.00 EDAS / PRO-CREATE M-20-082 M-21-082 $10.00 0 EnhComp / PRO-EnhCon,p Diskette M-20-072 M-21-072 $23.98 Filters: Combined I & II L-32-053 n/a $5.00 B GO:Maintenance n/a M-33-100 $15.00 B GO:System Enhancement -

Supreme Court of the United States ______
No. 15-1439 IN THE Supreme Court of the United States _________ CYAN, INC., ET AL. Petitioner, v. BEAVER COUNTY EMPLOYEES RETIREMENT FUND, ET AL. Respondents. _________ On Writ of Certiorari to the Court of Appeal for the State of California, First Appellate District _________ BRIEF OF AMICI CURIAE LAW PROFESSORS IN SUPORT OF PETITIONERS _________ John C. Dwyer Counsel of Record Jeffrey M. Kaban Matthew Ezer Cooley LLP 3175 Hanover Street Palo Alto, CA 94304 (650) 843-5000 Counsel for Amici Curiae Professors Elizabeth Cosenza, Allen Ferrell, Sean J. Griffith, Joseph A. Grundfest, M. Todd Henderson Michael Klausner, and Urska Velikonja i TABLE OF CONTENTS Page STATEMENT OF INTEREST OF AMICI CURIAE ..................................................................... 1 SUMMARY OF ARGUMENT ................................... 4 ARGUMENT ............................................................. 6 I. CONGRESS ENACTED SLUSA TO CLOSE THE JURISDICTIONAL LOOPHOLE CREATED BY THE PSLRA AND ENSURE A UNIFORM INTERPRETATION OF BOTH THE SECURITIES ACT AND SLUSA .................. 6 A. The PSLRA Offered Defendants Protections Against Abusive Suits Filed In Federal Court, But Inadvertently Shifted Securities Actions to State Courts........................ 6 B. Congress Enacted SLUSA to close the Jurisdictional Loophole Created by the PSLRA ...................... 10 C. This Court’s Interpretation of SLUSA Should Be Informed by the Clear Congressional Purpose of Closing the Jurisdictional Loophole ............................................. 14 II. -
PC-DOS Notes Wendy Krieger – an Os2fan2
PC-DOS Notes Wendy Krieger – an os2fan2 The scope of this document is from version 5.00 onwards and OS/2 2.0 onwards. The IBM releases of Windows are also covered. Files that derive from earlier versions, and continued to be used in these releases, are also documented. IBM moved from an OEM DOS to a retail DOS with DOS 5.0. This DOS is the most extensively updated version of DOS, and is the source of OS/2 DOS files. DOS 6 followed the availability of the microsoft code. 6.3 copies 6.2, while 7.0 is a rewrite of DOS. 7.1 is found in various appliance applications only, never went to retail. DOS 3 – OS/2 v1.x BASICA BASICA. and GWBASIC, is more to cater for needs from the 1980s, where these emulate the default OS on the 8-bit machines. The version numbers usually matched the DOS version, until it was stopped being developed. The last IBM compiled version is for PC-DOS 3.00. This is also the last version to include the sample files (except MORTGAGE.BAS). Microsoft provided the code for the later versions. 3.10 and 3.20 check for DOS versions, but 3.31 and 3.4 are defanged. To test for the source code, run this as soon as Basic loads. This will tell you which RND code is used. PRINT RND 0.1213501 Basic compiled by Microsoft 0.7151002 Basic compiled by IBM 0.7055475 QuickBasic and QBASIC. BASIC was dropped in the run of DOS 3. -

Unit 6 Operating Systems (Dos, Windows, Unix and Linux)
Software UNIT 6 OPERATING SYSTEMS (DOS, WINDOWS, UNIX AND LINUX) Structure 6.0 Objectives 6.1 Introduction 6.2 MS-DOS Environment 6.2.1 MS-DOS Memory Types 6.2.2 MS-DOS Version 6.2.3 Loading MS-DOS 6.2.4 MS-DOS Device Drivers 6.2.5 Config.sys File and its Use 6.2.6 Directory Structure of DOS 6.2.7 MKDIR Command (Make Directory) 6.2.8 Other MS-DOS Command 6.2.9 MS-DOS Batch Files 6.2.10 File and Hard Disk 6.3 MS-Windows 6.3.1 Advantage of Using Windows vs DOS 6.3.2 Versions of MS Windows 6.3.3 Basic Features of Windows 6.3.4 Support for MS-DOS 6.3.5 Dial up Network and Internet Explorer 6.3.6 The Internet Explorer Web Browser 6.3.7 Customizing Windows Operating Systems 6.3.8 Start Menu 6.3.9 Windows Help 6.3.10 Organisation of information 6.3.11 Using Window Explorer 6.3.12 Using Notepad 6.4 Unix 6.4.1 Main Features 6.4.2 Unix Operating System 6.4.3 Utilities File Management 6.4.4 Process Management 6.4.5 Starting and Shutting Down UNIX/ LINUX 6.4.6 UNIX Command Syntax 6.4.7 UNIX File System 6.4.8 Mountable File System 6.4.9 Shell Scripts 6.4.10 User Management 6.4.11 Other System Activity 6.5 Linux 6.5.1 Technical Features of Linux 6.5.2 Linux File System 6.5.3 Components of a Linux System 6.5.4 Linux Kernel and its Modules 6.5.5 Drawbacks of Using Linux 6.6 Summary 6.7 Answers to Self Check Exercises 6.8 Keywords 6.9 References and Further Reading 6.0 OBJECTIVES After reading this Unit, you will be able to: 106 l Understand the basic features of MS-DOS, Window, Unix and Linux operating Operating Systems systems; and (Dos, Windows, Unix and Linux) l Work with various components of each types. -

94.Macmonthly.Riseofbillgates.Pdf
microsoft continued Last month, we learned that Leonardo da nounced that it was embarking on a $100 DOS 6.0 operating system, eliminating the admitted that Money was an embarrassment inci's "Codex" notebook had joined Intuit million marketing campaign to boost aware- need for customers to purchase Stac's prod- to the whole company. and Stac Electronics as the leitest jewel in the ness of its name. "The Microsoft brand name uct. No longer. The deal announced between crown of Bill Gates. Gates, of course, is the represents 'access'—access to ideas, informa- Many people believed that Stac's victory Microsoft and Intuit calls for Microsoft to richest man in the United States: the founder, tion, fun, tools and even other people," said over Microsoft was proof that patents will pro- spend $1.5 billion to purchase Intuit's stock. Chairman, and CEO of Microsoft, the Seattle- Steve Ballmer, executive vice president of sales tect smaller companies from larger ones, even As part of the deal, Microsoft will sell off its based company that is running the world's and support at Microsoft. "As personal com- ones as large as Microsoft. But, a few months Money product to another firm. The official personal computer industry. puters appear in more and more places, we later, the two companies settled their differ- reason for jettisoning Money is to avoid the Leonardo's seventy-two page Codex want people to recognize how software, and ences with an agreement that called for patent risk of being nabbed by the anti-trust division notebook predicted the invention of the sub- specifically Microsoft software, is making their cross-licensing and for Microsoft to purchase of the Justice Department for anti-competi- marine and the steam engine, contained ad- computers come to life." 15% of Stac's stock for $83 million. -

Intellectual Property Valuation - Michael Lasinski, Intecap, 2004
IntellectualIntellectual PropertyProperty ValuationValuation January 2008 Franklin Pierce Law Center Advanced Licensing Institute AgendaAgenda 1. Introduction 2. IP valuation theory: cost, market, income, other 3. Price v. value 4. Pre-valuation due diligence 5. Deal structure discussion 6. Disclaimer 7. Contact information 2 Introduction:Introduction: GrowingGrowing importanceimportance ofof intangiblesintangibles Components of S&P 500 Market Value 100% 20.3%20.3% 31.6%31.6% 80% 67.6% 67.6% 83.2% 60% 83.2% 79.7% 79.7% 40% 68.4%68.4% 20% 32.4%32.4% 16.8% 0% 1975 1985 1995 2005 Tangible Assets Intangible Assets 3 Introduction:Introduction: IntellectualIntellectual propertyproperty marketplacemarketplace evolutionevolution High Expansion Web Traded Exchange for Licensing Portals License Rights Public Royalty Based P-LECs- Auction Industry Licensing IP Based Web Listings M&A Defensive IP Based Market Quality Cross Debt / PE Licensing IP for the masses Structured Invested as an asset class Litigation Finance Age of the Golden Rule Low Historical Present Future “The Period of the “The Rise of the “The Age of the Feudal Lords” Intermediaries” Golden Rule” 4 Introduction:Introduction: IPIP marketplacemarketplace evolutionevolution –– thethe livelive auctionauction 5 Introduction:Introduction: AnAn IRSIRS definitiondefinition ofof FairFair MarketMarket ValueValue Fair Market Value is defined as the price at which property would change hands between a willing buyer and a willing seller, neither being under any compulsion to buy or to sell, and both having reasonable knowledge of relevant facts (Estate Tax Regs., Sec. 20.2031-1(b); Rev. Rul. 59-60, 1959-1 C.B. 237) $$$$$$$ Willing Willing Buyer Seller Property 6 Introduction:Introduction: Dilbert understands valuation 7 Introduction:Introduction: TheThe courtscourts understandunderstand damagesdamages Parties Award Date SourceCourt 1 Polaroid v.