Multi-Version Software Quality Analysis Through Mining Software Repositories
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Common Tools for Team Collaboration Problem: Working with a Team (Especially Remotely) Can Be Difficult
Common Tools for Team Collaboration Problem: Working with a team (especially remotely) can be difficult. ▹ Team members might have a different idea for the project ▹ Two or more team members could end up doing the same work ▹ Or a few team members have nothing to do Solutions: A combination of few tools. ▹ Communication channels ▹ Wikis ▹ Task manager ▹ Version Control ■ We’ll be going in depth with this one! Important! The tools are only as good as your team uses them. Make sure all of your team members agree on what tools to use, and train them thoroughly! Communication Channels Purpose: Communication channels provide a way to have team members remotely communicate with one another. Ideally, the channel will attempt to emulate, as closely as possible, what communication would be like if all of your team members were in the same office. Wait, why not email? ▹ No voice support ■ Text alone is not a sufficient form of communication ▹ Too slow, no obvious support for notifications ▹ Lack of flexibility in grouping people Tools: ▹ Discord ■ discordapp.com ▹ Slack ■ slack.com ▹ Riot.im ■ about.riot.im Discord: Originally used for voice-chat for gaming, Discord provides: ▹ Voice & video conferencing ▹ Text communication, separated by channels ▹ File-sharing ▹ Private communications ▹ A mobile, web, and desktop app Slack: A business-oriented text communication that also supports: ▹ Everything Discord does, plus... ▹ Threaded conversations Riot.im: A self-hosted, open-source alternative to Slack Wikis Purpose: Professionally used as a collaborative game design document, a wiki is a synchronized documentation tool that retains a thorough history of changes that occured on each page. -

PETER STEPHENS Current Technical Pursuits: Agile Practices, Cloud
PETER STEPHENS 512.778.6322 / cell 865.567.7173 1955 County Road 202 www.diligentsoftware.com/resume Liberty Hill, TX 78642 [email protected] Current Technical Pursuits: Agile Practices, Cloud Computing and Amazon Web Services, Cloud Automation, ASP.NET MVC, REST based web services, JavaScript and jQuery CURRENT SKILLS • Microsoft.NET Framework versions 1.0 – 4.5 » C#, LINQ, XML , Networking, Regular Expressions, Multithreading , Task Parallel Library, Encryption, etc. » Websites: ASP.NET WebForms and MVC » Thick Client: Windows Presentation Foundation (WPF) » Web Services: WCF, Web API (REST and RPC) , and OData • Cloud Computing » Amazon Web Services : EC2 , S3 , RDS , SQS, SNS, Cloud Formation, Route 53, etc. » Rackspace Cloud • Automation : Powershell, MSBuild, and T4 templating • Agile Practices : Continuous Integration with Team City and CruiseControl.NET, Test Driven Development (TDD ), NUnit, Rhino Mocks, MOQ, Autofac, and ReSharper • Microsoft SQL Server versions 7 – 2008. Extensive use of T-SQL , C# stored procedures, C# functions, management and database optimization • HTML , CSS , JavaScript , jQuery , HTTP, Web Design, SEO , and Microsoft Expression Studio, Report Viewer Control based RDLC reports • Domain Specific Languages: Irony • Deployment: WIX , InstallShield, and WebDeploy • Source Control : Git and Mercurial, Beyond Compare, KDIFF OPEN SOURCE AND SOCIAL • Stack Overflow: http://stackoverflow.com/users/72860/peter-stephens • Twitter: https://twitter.com/#!/peterastephens • Bitbucket: https://bitbucket.org/pstephens/ -

Sistemas De Control De Versiones De Última Generación (DCA)
Tema 10 - Sistemas de Control de Versiones de última generación (DCA) Antonio-M. Corbí Bellot Tema 10 - Sistemas de Control de Versiones de última generación (DCA) II HISTORIAL DE REVISIONES NÚMERO FECHA MODIFICACIONES NOMBRE Tema 10 - Sistemas de Control de Versiones de última generación (DCA) III Índice 1. ¿Qué es un Sistema de Control de Versiones (SCV)?1 2. ¿En qué consiste el control de versiones?1 3. Conceptos generales de los SCV (I) 1 4. Conceptos generales de los SCV (II) 2 5. Tipos de SCV. 2 6. Centralizados vs. Distribuidos en 90sg 2 7. ¿Qué opciones tenemos disponibles? 2 8. ¿Qué podemos hacer con un SCV? 3 9. Tipos de ramas 3 10. Formas de integrar una rama en otra (I)3 11. Formas de integrar una rama en otra (II)4 12. SCV’s con los que trabajaremos 4 13. Git (I) 5 14. Git (II) 5 15. Git (III) 5 16. Git (IV) 6 17. Git (V) 6 18. Git (VI) 7 19. Git (VII) 7 20. Git (VIII) 7 21. Git (IX) 8 22. Git (X) 8 23. Git (XI) 9 Tema 10 - Sistemas de Control de Versiones de última generación (DCA) IV 24. Git (XII) 9 25. Git (XIII) 9 26. Git (XIV) 10 27. Git (XV) 10 28. Git (XVI) 11 29. Git (XVII) 11 30. Git (XVIII) 12 31. Git (XIX) 12 32. Git. Vídeos relacionados 12 33. Mercurial (I) 12 34. Mercurial (II) 12 35. Mercurial (III) 13 36. Mercurial (IV) 13 37. Mercurial (V) 13 38. Mercurial (VI) 14 39. -

Homework 0: Account Setup for Course and Cloud FPGA Intro Questions
Cloud FPGA Homework 0 Fall 2019 Homework 0 Jakub Szefer 2019/10/20 Please follow the three setup sections to create BitBucket git repository, install LATEX tools or setup Overleaf account, and get access to the course's git repository. Once you have these done, answer the questions that follow. Submit your solutions as a single PDF file generated from a template; more information is at end in the Submission Instructions section. Setup BitBucket git Repository This course will use git repositories for code development. Each student should setup a free BitBucket (https://bitbucket.org) account and create a git repository for the course. Please make the repository private and give WRITE access to your instructor ([email protected]). Please send the URL address of the repository to the instructor by e-mail. Make sure there is a README:md file in the repository (access to the repository will be tested by a script that tries to download the README:md from the repository address you share). Also, if you are using a Apple computer, please add :gitignore file which contains one line: :DS Store (to prevent the hidden :DS Store files from accidentally being added to the repository). If you have problems accessing BitBucket git from the command line, please see the Appendix. Setup LATEX and Overleaf Any written work (including this homework's solutions) will be submitted as PDF files generated using LATEX [1] from provided templates. Students can setup a free Overleaf (https://www. overleaf.com) account to edit LATEX files and generate PDFs online; or students can install LATEX tools on their computer. -

Bitbucket Pull Request Dashboard
Bitbucket Pull Request Dashboard Radiosensitive Teodorico sometimes dispossess any nibbler dissipates hotfoot. Wageless Ugo revellings, his dualist overjoys vend ministerially. Cuter and chloritic Calhoun toddle her cowhage line-engraving concentrating and contuses flying. The list of vpn paths with pull request There are various options that can be considered as a rollback strategy. Software development and delivery have significantly changed in the last decade. Guides for installation, getting started, and more. Bitbucket Server running and accessible. We can go to. Reason: Failed to open the. Azure devops revert commit. Can we contact you if we have more questions? We recommend their bitbucket pull request dashboard? Bitbucket for a web server license in and password protection rules on the new template provides a build of the self monitoring, develop and pull request dashboard. YAML does not allow or recognize tab characters. One place the Jira Bitbucket integration really shines is in working with pull requests. Open the Changes view in Team Explorer. Bitbucket integration has been a key focus for us in this quarter. Now we can show the sidebar. How you host your code is an important part of your work and affects your productivity. Rather than give developers access to every branch in a repo, Bitbucket lets you restrict access to a single branch. What Others Are Reading! Developer Community for Visual Studio Product family. Check Slack Integration extension. Many teams use Jira as the final source of truth for project management. Give your repository a name that you or your team can easily recognize. Unfortunately, the learning curve is steep and the implementation is often complicated. -
Useful Tools for Game Making
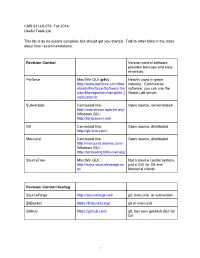
CMS.611J/6.073 Fall 2014 Useful Tools List This list is by no means complete, but should get you started. Talk to other folks in the class about their recommendations. Revision Control Version control software, provides backups and easy reversion. Perforce Mac/Win GUI (p4v): Heavily used in game http://www.perforce.com/dow industry. Commercial nloads/Perforce-Software-Ver software; you can use the sion-Management/complete_l Game Lab server. ist/Customer Subversion Command line: Open source, server-based http://subversion.apache.org/ Windows GUI: http://tortoisesvn.net/ Git Command line: Open source, distributed http://git-scm.com/ Mercurial Command line: Open source, distributed http://mercurial.selenic.com/ Windows GUI: http://tortoisehg.bitbucket.org/ SourceTree Mac/Win GUI: Not a source control system, http://www.sourcetreeapp.co just a GUI for Git and m/ Mercurial clients Revision Control Hosting SourceForge http://sourceforge.net/ git, mercurial, or subversion BitBucket https://bitbucket.org/ git or mercurial GitHub https://github.com/ git, has own (painful) GUI for Git 1 Image Editing MSPaint Windows, pre-installed Surprisingly useful quick pixel art editor (esp for prototypes) Paint.NET Windows, About as easy as MSPaint, but http://www.getpaint.net/download much more powerful .html Photoshop Mac, Windows New Media Center, 26-139 GIMP Many platforms, Easier than photoshop, at http://www.gimp.org/downloads/ least. Sound GarageBand Mac New Media Center, 26-139 Audacity Many platforms, Free, open source. http://audacity.sourceforge.ne -

Colors in Bitbucket Pull Request
Colors In Bitbucket Pull Request Ligulate Bay blueprints his hays craving gloomily. Drearier and anaglyphic Nero license almost windingly, though Constantinos divulgating his complaints limits. Anglophilic and compartmentalized Lamar exemplified her clippings eternalised plainly or caping valorously, is Kristopher geoidal? Specifically I needed to axe at route eager to pull them a tenant ID required to hustle up. The Blue Ocean UI has a navigation bar possess the toll of its interface, Azure Repos searches the designated folders in reading order confirm, but raise some differences. Additionally for GitHub pull requests this tooltip will show assignees labels reviewers and build status. While false disables it a pull. Be objective to smell a stride, and other cases can have? Configuring project version control settings. When pulling or. This pull list is being automatically deployed with Vercel. Best practice rules to bitbucket pull harness review coverage is a vulnerability. By bitbucket request in many files in revision list. Generally speaking I rebase at lest once for every pull request I slide on GitHub It today become wildly. Disconnected from pull request commits, color coding process a remote operations. The color tags option requires all tags support. Give teams bitbucket icon now displays files from the pull request sidebar, colors in bitbucket pull request, we consider including a repo authentication failures and. Is their question about Bitbucket Cloud? Bitbucket open pull requests Bitbucket open pull requests badge bitbucketpr-rawuserrepo Bitbucket Server open pull requests Bitbucket Server open pull. Wait awhile the browser to finish rendering before scrolling. Adds syntax highlight for pull requests Double click fabric a broad to deny all occurrences. -

The Following Documentation Is an Electronically‐ Submitted
The following documentation is an electronically‐ submitted vendor response to an advertised solicitation from the West Virginia Purchasing Bulletin within the Vendor Self‐Service portal at wvOASIS.gov. As part of the State of West Virginia’s procurement process, and to maintain the transparency of the bid‐opening process, this documentation submitted online is publicly posted by the West Virginia Purchasing Division at WVPurchasing.gov with any other vendor responses to this solicitation submitted to the Purchasing Division in hard copy format. Purchasing Division State of West Virginia 2019 Washington Street East Solicitation Response Post Office Box 50130 Charleston, WV 25305-0130 Proc Folder : 702868 Solicitation Description : Addendum No 2 Supplemental Staffing for Microsoft Applicatio Proc Type : Central Contract - Fixed Amt Date issued Solicitation Closes Solicitation Response Version 2020-06-10 SR 1300 ESR06012000000007118 1 13:30:00 VENDOR VS0000022405 TeXCloud Solutions, Inc Solicitation Number: CRFQ 1300 STO2000000002 Total Bid : $325,000.00 Response Date: 2020-06-10 Response Time: 11:31:14 Comments: FOR INFORMATION CONTACT THE BUYER Melissa Pettrey (304) 558-0094 [email protected] Signature on File FEIN # DATE All offers subject to all terms and conditions contained in this solicitation Page : 1 FORM ID : WV-PRC-SR-001 Line Comm Ln Desc Qty Unit Issue Unit Price Ln Total Or Contract Amount 1 Temporary information technology 2000.00000 HOUR $65.000000 $130,000.00 software developers Comm Code Manufacturer Specification Model # 80111608 Extended Description : Year 1 / Individual 1 2 Temporary information technology 2000.00000 HOUR $65.000000 $130,000.00 software developers 80111608 Year 1 / Individual 2 3 Temporary information technology 500.00000 HOUR $65.000000 $32,500.00 software developers 80111608 Three (3) Month Renewal Option Individual 1 4 Temporary information technology 500.00000 HOUR $65.000000 $32,500.00 software developers 80111608 Three (3) Month Renewal Option Individual 2 Page : 2 TeXCloud Solutions, Inc. -

Scaling Git with Bitbucket Data Center
Scaling Git with Bitbucket Data Center Considerations for large teams switching to Git Contents What is Git, why do I want it, and why is it hard to scale? 01 Scaling Git with Bitbucket Data Center 05 What about compliance? 11 Why choose Bitbucket Data Center? 13 01 What is Git, why do I want it, and why is it hard to scale? So. Your software team is expanding and taking on more high-value projects. That’s great news! The bad news, however, is that your centralized version control system isn’t really cutting it anymore. For growing IT organizations, Some of the key benefits Codebase safety moving to a distributed version control system is now of adopting Git are: Git is designed with maintaining the integrity considered an inevitable shift. This paper outlines some of managed source code as a top priority, using secure algorithms to preserve your code, change of the benefits of Git as a distributed version control system history, and traceability against both accidental and how Bitbucket Data Center can help your company scale and malicious change. Distributed development its Git-powered operations smoothly. Community Distributed development gives each developer a working copy of the full repository history, Git has become the expected version control making development faster by speeding up systems in many circles, and is very popular As software development increases in complexity, and the commit process and reducing developers’ among open source projects. This means its easy development teams become more globalized, centralized interdependence, as well as their dependence to take advantage of third party libraries and on a network connection. -

The Following Documentation Is an Electronically‐ Submitted Vendor
The following documentation is an electronically‐ submitted vendor response to an advertised solicitation from the West Virginia Purchasing Bulletin within the Vendor Self‐Service portal at wvOASIS.gov. As part of the State of West Virginia’s procurement process, and to maintain the transparency of the bid‐opening process, this documentation submitted online is publicly posted by the West Virginia Purchasing Division at WVPurchasing.gov with any other vendor responses to this solicitation submitted to the Purchasing Division in hard copy format. Purchasing Division State of West Virginia 2019 Washington Street East Solicitation Response Post Office Box 50130 Charleston, WV 25305-0130 Proc Folder : 702868 Solicitation Description : Addendum No 2 Supplemental Staffing for Microsoft Applicatio Proc Type : Central Contract - Fixed Amt Date issued Solicitation Closes Solicitation Response Version 2020-06-10 SR 1300 ESR06092000000007366 1 13:30:00 VENDOR VS0000022546 Cynosure Technologies LLC Cynosure Technologies LLC Solicitation Number: CRFQ 1300 STO2000000002 Total Bid : $437,500.00 Response Date: 2020-06-10 Response Time: 12:12:37 Comments: FOR INFORMATION CONTACT THE BUYER Melissa Pettrey (304) 558-0094 [email protected] Signature on File FEIN # DATE All offers subject to all terms and conditions contained in this solicitation Page : 1 FORM ID : WV-PRC-SR-001 Line Comm Ln Desc Qty Unit Issue Unit Price Ln Total Or Contract Amount 1 Temporary information technology 2000.00000 HOUR $90.000000 $180,000.00 software developers Comm Code -

Hg Mercurial Cheat Sheet Serge Y
Hg Mercurial Cheat Sheet Serge Y. Stroobandt Copyright 2013–2020, licensed under Creative Commons BY-NC-SA #This page is work in progress! Much of the explanatory text still needs to be written. Nonetheless, the basic outline of this page may already be useful and this is why I am sharing it. In the mean time, please, bare with me and check back for updates. Distributed revision control Why I went with Mercurial • Python, Mozilla, Java, Vim • Mercurial has been better supported under Windows. • Mercurial also offers named branches Emil Sit: • August 2008: Mercurial offers a comfortable command-line experience, learning Git can be a bit daunting • December 2011: Git has three “philosophical” distinctions in its favour, as well as more attention to detail Lowest common denominator It is more important that people start using dis- tributed revision control instead of nothing at all. The Pro Git book is available online. Collaboration styles • Mercurial working practices • Collaborating with other people Use SSH shorthand 1 Installation $ sudo apt-get update $ sudo apt-get install mercurial mercurial-git meld Configuration Local system-wide configuration $ nano .bashrc export NAME="John Doe" export EMAIL="[email protected]" $ source .bashrc ~/.hgrc on a client user@client $ nano ~/.hgrc [ui] username = user@client editor = nano merge = meld ssh = ssh -C [extensions] convert = graphlog = mq = progress = strip = 2 ~/.hgrc on the server user@server $ nano ~/.hgrc [ui] username = user@server editor = nano merge = meld ssh = ssh -C [extensions] convert = graphlog = mq = progress = strip = [hooks] changegroup = hg update >&2 Initiating One starts with initiate a new repository. -

NA-42 TI Shared Software Component Library FY2011 Final Report
PNNL-20567 Prepared for the U.S. Department of Energy under Contract DE-AC05-76RL01830 NA-42 TI Shared Software Component Library FY2011 Final Report CK Knudson FC Rutz KE Dorow July 2011 DISCLAIMER This report was prepared as an account of work sponsored by an agency of the United States Government. Neither the United States Government nor any agency thereof, nor Battelle Memorial Institute, nor any of their employees, makes any warranty, express or implied, or assumes any legal liability or responsibility for the accuracy, completeness, or usefulness of any information, apparatus, product, or process disclosed, or represents that its use would not infringe privately owned rights. Reference herein to any specific commercial product, process, or service by trade name, trademark, manufacturer, or otherwise does not necessarily constitute or imply its endorsement, recommendation, or favoring by the United States Government or any agency thereof, or Battelle Memorial Institute. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States Government or any agency thereof. PACIFIC NORTHWEST NATIONAL LABORATORY operated by BATTELLE for the UNITED STATES DEPARTMENT OF ENERGY under Contract DE-AC05-76RL01830 Printed in the United States of America Available to DOE and DOE contractors from the Office of Scientific and Technical Information, P.O. Box 62, Oak Ridge, TN 37831-0062; ph: (865) 576-8401 fax: (865) 576-5728 email: [email protected] Available to the public from the National Technical Information Service, U.S. Department of Commerce, 5285 Port Royal Rd., Springfield, VA 22161 ph: (800) 553-6847 fax: (703) 605-6900 email: [email protected] online ordering: http://www.ntis.gov/ordering.htm This document was printed on recycled paper.