Institutionen För Datavetenskap
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Cvs Latest Version Download Cvs Latest Version Download
cvs latest version download Cvs latest version download. cvs (Concurrent Versions System) command in Linux is used to store the history of a file. Whenever a file gets corrupted or anything goes wrong “cvs” help us to go back to the previous version and restore our file. Syntax: –allow-root=rootdir : Specify repository on the command line. It also specify legal cvsroot directory. See ‘Password authentication server’ in the CVS manual. -d, cvs_root_directory : It uses cvs_root_directory as the directory path name of the repository. It also overrides the $CVSROOT environment variable. -e, editor-command : It uses the editor command specified for entering log information. It also overrides $CVSEDITOR and $EDITOR environment variables. -f : It does not read the. CVS Commands: add : Add a new file/directory to the repository. admin : Administration front-end for RCS. annotate : Shows the last revision where each line was modified. checkout : Checkout sources for editing. commit : Check files into the repository. diff : Show differences between revisions. edit : Get ready to edit a watched file. editors : See who is editing a watched file. export : Export sources from CVS, similar to checkout. history : Show repository access history. import : Import sources into CVS, using vendor branches. init : It create a CVS repository if it doesn’t exist. log : Print out history information for files. rdiff : Create ‘patch’ format diffs between revisions. status : Display status information on checked out files. tag : It adds a symbolic tag to checked out version of files. unedit : Undo anedit command. update : Bring work tree in sync with repository. version : Show current CS version(s). -

Common Tools for Team Collaboration Problem: Working with a Team (Especially Remotely) Can Be Difficult
Common Tools for Team Collaboration Problem: Working with a team (especially remotely) can be difficult. ▹ Team members might have a different idea for the project ▹ Two or more team members could end up doing the same work ▹ Or a few team members have nothing to do Solutions: A combination of few tools. ▹ Communication channels ▹ Wikis ▹ Task manager ▹ Version Control ■ We’ll be going in depth with this one! Important! The tools are only as good as your team uses them. Make sure all of your team members agree on what tools to use, and train them thoroughly! Communication Channels Purpose: Communication channels provide a way to have team members remotely communicate with one another. Ideally, the channel will attempt to emulate, as closely as possible, what communication would be like if all of your team members were in the same office. Wait, why not email? ▹ No voice support ■ Text alone is not a sufficient form of communication ▹ Too slow, no obvious support for notifications ▹ Lack of flexibility in grouping people Tools: ▹ Discord ■ discordapp.com ▹ Slack ■ slack.com ▹ Riot.im ■ about.riot.im Discord: Originally used for voice-chat for gaming, Discord provides: ▹ Voice & video conferencing ▹ Text communication, separated by channels ▹ File-sharing ▹ Private communications ▹ A mobile, web, and desktop app Slack: A business-oriented text communication that also supports: ▹ Everything Discord does, plus... ▹ Threaded conversations Riot.im: A self-hosted, open-source alternative to Slack Wikis Purpose: Professionally used as a collaborative game design document, a wiki is a synchronized documentation tool that retains a thorough history of changes that occured on each page. -

Sistemas De Control De Versiones De Última Generación (DCA)
Tema 10 - Sistemas de Control de Versiones de última generación (DCA) Antonio-M. Corbí Bellot Tema 10 - Sistemas de Control de Versiones de última generación (DCA) II HISTORIAL DE REVISIONES NÚMERO FECHA MODIFICACIONES NOMBRE Tema 10 - Sistemas de Control de Versiones de última generación (DCA) III Índice 1. ¿Qué es un Sistema de Control de Versiones (SCV)?1 2. ¿En qué consiste el control de versiones?1 3. Conceptos generales de los SCV (I) 1 4. Conceptos generales de los SCV (II) 2 5. Tipos de SCV. 2 6. Centralizados vs. Distribuidos en 90sg 2 7. ¿Qué opciones tenemos disponibles? 2 8. ¿Qué podemos hacer con un SCV? 3 9. Tipos de ramas 3 10. Formas de integrar una rama en otra (I)3 11. Formas de integrar una rama en otra (II)4 12. SCV’s con los que trabajaremos 4 13. Git (I) 5 14. Git (II) 5 15. Git (III) 5 16. Git (IV) 6 17. Git (V) 6 18. Git (VI) 7 19. Git (VII) 7 20. Git (VIII) 7 21. Git (IX) 8 22. Git (X) 8 23. Git (XI) 9 Tema 10 - Sistemas de Control de Versiones de última generación (DCA) IV 24. Git (XII) 9 25. Git (XIII) 9 26. Git (XIV) 10 27. Git (XV) 10 28. Git (XVI) 11 29. Git (XVII) 11 30. Git (XVIII) 12 31. Git (XIX) 12 32. Git. Vídeos relacionados 12 33. Mercurial (I) 12 34. Mercurial (II) 12 35. Mercurial (III) 13 36. Mercurial (IV) 13 37. Mercurial (V) 13 38. Mercurial (VI) 14 39. -
Useful Tools for Game Making
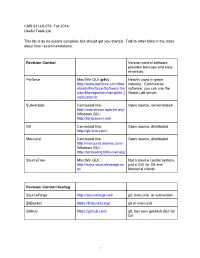
CMS.611J/6.073 Fall 2014 Useful Tools List This list is by no means complete, but should get you started. Talk to other folks in the class about their recommendations. Revision Control Version control software, provides backups and easy reversion. Perforce Mac/Win GUI (p4v): Heavily used in game http://www.perforce.com/dow industry. Commercial nloads/Perforce-Software-Ver software; you can use the sion-Management/complete_l Game Lab server. ist/Customer Subversion Command line: Open source, server-based http://subversion.apache.org/ Windows GUI: http://tortoisesvn.net/ Git Command line: Open source, distributed http://git-scm.com/ Mercurial Command line: Open source, distributed http://mercurial.selenic.com/ Windows GUI: http://tortoisehg.bitbucket.org/ SourceTree Mac/Win GUI: Not a source control system, http://www.sourcetreeapp.co just a GUI for Git and m/ Mercurial clients Revision Control Hosting SourceForge http://sourceforge.net/ git, mercurial, or subversion BitBucket https://bitbucket.org/ git or mercurial GitHub https://github.com/ git, has own (painful) GUI for Git 1 Image Editing MSPaint Windows, pre-installed Surprisingly useful quick pixel art editor (esp for prototypes) Paint.NET Windows, About as easy as MSPaint, but http://www.getpaint.net/download much more powerful .html Photoshop Mac, Windows New Media Center, 26-139 GIMP Many platforms, Easier than photoshop, at http://www.gimp.org/downloads/ least. Sound GarageBand Mac New Media Center, 26-139 Audacity Many platforms, Free, open source. http://audacity.sourceforge.ne -

Change Management
Enterprise Architect User Guide Series Change Management Managing change in a model? Sparx Systems Enterprise Architect has many tools to maintain data, such as Version Control, milestone Baselines, change Auditing, Project Transfer for backups, Validation, Integrity Checking and role-based User Security. Author: Sparx Systems Date: 16/01/2019 Version: 1.0 CREATED WITH Table of Contents Change Management 4 Version Control 5 Introduction 6 Version Control Usage 8 Version Control of Model Data 9 Version Control and Reference Data 10 Version Controlling Packages 11 Applying Version Control in a Team Environment 12 Version Control Nested Packages 14 Add Connectors To Locked Elements 15 Project Browser Indicators 16 Offline Version Control 17 Version Control Branching 19 Version Control Product Setup 20 System Requirements 22 Create a Subversion Environment 24 Create a new Repository Sub-tree 26 Create a Local Working Copy 27 Verify the SVN Workspace 28 Subversion Under Wine-Crossover 29 Preparing a Subversion Environment Under Wine 30 TortoiseSVN 32 Create a TFS Environment 33 TFS Workspaces 35 TFS Exclusive Check Outs 37 Verify the TFS Workspace 38 Create a CVS Environment 39 Prepare a CVS Local Workspace 41 Verify the CVS Workspace 42 TortoiseCVS 43 Create an SCC Environment 44 Upgrade at Enterprise Architect Version 4.5, Under SCC Version Control 46 Version Control Set Up 47 Re-use an Existing Configuration 48 Version Control Settings 49 SCC Settings 51 CVS Settings 53 SVN Settings 55 TFS Settings 57 Use Version Control 59 Configure Controlled -

Opinnäytetyö Ohjeet
Lappeenrannan–Lahden teknillinen yliopisto LUT School of Engineering Science Tietotekniikan koulutusohjelma Kandidaatintyö Mikko Mustonen PARHAITEN OPETUSKÄYTTÖÖN SOVELTUVAN VERSIONHALLINTAJÄRJESTELMÄN LÖYTÄMINEN Työn tarkastaja: Tutkijaopettaja Uolevi Nikula Työn ohjaaja: Tutkijaopettaja Uolevi Nikula TIIVISTELMÄ LUT-yliopisto School of Engineering Science Tietotekniikan koulutusohjelma Mikko Mustonen Parhaiten opetuskäyttöön soveltuvan versionhallintajärjestelmän löytäminen Kandidaatintyö 2019 31 sivua, 8 kuvaa, 2 taulukkoa Työn tarkastajat: Tutkijaopettaja Uolevi Nikula Hakusanat: versionhallinta, versionhallintajärjestelmä, Git, GitLab, SVN, Subversion, oppimateriaali Keywords: version control, version control system, Git, GitLab, SVN, Subversion, learning material LUT-yliopistossa on tietotekniikan opetuksessa käytetty Apache Subversionia versionhallintaan. Subversionin käyttö kuitenkin johtaa ylimääräisiin ylläpitotoimiin LUTin tietohallinnolle. Lisäksi Subversionin julkaisun jälkeen on tullut uusia versionhallintajärjestelmiä ja tässä työssä tutkitaankin, olisiko Subversion syytä vaihtaa johonkin toiseen versionhallintajärjestelmään opetuskäytössä. Työn tavoitteena on löytää opetuskäyttöön parhaiten soveltuva versionhallintajärjestelmä ja tuottaa sille opetusmateriaalia. Työssä havaittiin, että Git on suosituin versionhallintajärjestelmä ja se on myös suhteellisen helppo käyttää. Lisäksi GitLab on tutkimuksen mukaan Suomen yliopistoissa käytetyin ja ominaisuuksiltaan ja hinnaltaan sopivin Gitin web-käyttöliittymä. Näille tehtiin -

Hg Mercurial Cheat Sheet Serge Y
Hg Mercurial Cheat Sheet Serge Y. Stroobandt Copyright 2013–2020, licensed under Creative Commons BY-NC-SA #This page is work in progress! Much of the explanatory text still needs to be written. Nonetheless, the basic outline of this page may already be useful and this is why I am sharing it. In the mean time, please, bare with me and check back for updates. Distributed revision control Why I went with Mercurial • Python, Mozilla, Java, Vim • Mercurial has been better supported under Windows. • Mercurial also offers named branches Emil Sit: • August 2008: Mercurial offers a comfortable command-line experience, learning Git can be a bit daunting • December 2011: Git has three “philosophical” distinctions in its favour, as well as more attention to detail Lowest common denominator It is more important that people start using dis- tributed revision control instead of nothing at all. The Pro Git book is available online. Collaboration styles • Mercurial working practices • Collaborating with other people Use SSH shorthand 1 Installation $ sudo apt-get update $ sudo apt-get install mercurial mercurial-git meld Configuration Local system-wide configuration $ nano .bashrc export NAME="John Doe" export EMAIL="[email protected]" $ source .bashrc ~/.hgrc on a client user@client $ nano ~/.hgrc [ui] username = user@client editor = nano merge = meld ssh = ssh -C [extensions] convert = graphlog = mq = progress = strip = 2 ~/.hgrc on the server user@server $ nano ~/.hgrc [ui] username = user@server editor = nano merge = meld ssh = ssh -C [extensions] convert = graphlog = mq = progress = strip = [hooks] changegroup = hg update >&2 Initiating One starts with initiate a new repository. -

Configuration Management with Ansible And
Configuration management with Ansible and Git Paul Waring ([email protected], @pwaring) January 10, 2017 Topics I Configuration management I Version control I Firewall I Apache / nginx I Git Hooks I Bringing it all together Configuration management I Old days: edit files on each server, manual package installation I Boring, repetitive, error-prone I Computers are good at this sort of thing I Automate using shellscripts - doesn’t scale, brittle I Create configuration file and let software do the rest I Less firefighting, more tea-drinking Terminology I Managed node: Machines (physical/virtual) managed by Ansible I Control machine: Runs the Ansible client I Playbook/manifest: Describes how a managed node is configured I Agent: Runs on managed nodes Ansible I One of several options I Free and open source software - GPLv3 I Developed by the community and Ansible Inc. I Ansible Inc now part of RedHat I Support via the usual channels, free and paid Alternatives to Ansible I CfEngine I Puppet, Chef I SaltStack Why Ansible? I Minimal dependencies: SSH and Python 2 I Many Linux distros ship with both I No agents/daemons (except SSH) I Supports really old versions of Python (2.4 / RHEL 5) on nodes I Linux, *BSD, macOS and Windows Why Ansible? I Scales up and down I Gentle learning curve I But. no killer features I A bit like: vim vs emacs Configuration file I Global options which apply to all nodes I INI format I Write once, then leave Configuration file [defaults] inventory= hosts Inventory file I List of managed nodes I Allows overriding of global options on per-node basis I Group similar nodes, e.g. -

MAUS: the MICE Analysis User Software
RAL-P-2018-007 MAUS: The MICE Analysis User Software R. Asfandiyarov,a R. Bayes,b V. Blackmore,c M. Bogomilov,d D. Colling,c A.J. Dobbs,c F. Drielsma,a M. Drews,h M. Ellis,c M. Fedorov,e P. Franchini,f R. Gardener,g J.R. Greis,f P.M. Hanlet,h C. Heidt,i C. Hunt,c G. Kafka,h Y. Karadzhov,a A. Kurup,c P. Kyberd,g M. Littlefield,g A. Liu,j K. Long,c;n D. Maletic,k J. Martyniak,c S. Middleton,c T. Mohayai,h; j J.J. Nebrensky,g J.C. Nugent,b E. Overton,l V. Pec,l C.E. Pidcott,f D. Rajaram,h;1 M. Rayner,m I.D. Reid,g C.T. Rogers,n E. Santos,c M. Savic,k I. Taylor,f Y. Torun,h C.D. Tunnell,m M.A. Uchida,c V. Verguilov,a K. Walaron,b M. Winter,h S. Wilburl aDPNC, section de Physique, Université de Genève, Geneva, Switzerland bSchool of Physics and Astronomy, Kelvin Building, The University of Glasgow, Glasgow, UK cDepartment of Physics, Blackett Laboratory, Imperial College London, London, UK dDepartment of Atomic Physics, St. Kliment Ohridski University of Sofia, Sofia, Bulgaria eRadboud University of Nijmegen, Netherlands f Department of Physics, University of Warwick, Coventry, UK gBrunel University, Uxbridge, UK hPhysics Department, Illinois Institute of Technology, Chicago, IL, USA iUniversity of California, Riverside, CA, USA j Fermilab, Batavia, IL, USA k Institute of Physics, University of Belgrade, Serbia lDepartment of Physics and Astronomy, University of Sheffield, Sheffield, UK mDepartment of Physics, University of Oxford, Denys Wilkinson Building, Oxford, UK nSTFC Rutherford Appleton Laboratory, Harwell Oxford, Didcot, UK E-mail: [email protected] Abstract: The Muon Ionization Cooling Experiment (MICE) collaboration has developed the MICE Analysis User Software (MAUS) to simulate and analyze experimental data. -

Tortoisecvs User's Guide Version 1.8.0
TortoiseCVS User's Guide Version 1.8.0 Ben Campbell Martin Crawford Hartmut Honisch Francis Irving Torsten Martinsen Ian Dees Copyright © 2001 - 2004 TortoiseCVS Table of Contents 1. Getting Started What is CVS? What is TortoiseCVS? Where to Begin? 2. Basic Usage of TortoiseCVS Sandboxes Checking out a Module Windows Explorer and TortoiseCVS Total Commander and TortoiseCVS Updating your Sandbox Committing your Changes to the Repository Resolving Conflicts Adding Files and Directories to the Repository 3. Advanced Usage of TortoiseCVS Creating a New Repository or Module Watch, Edit and Unedit Tagging and Labeling Reverting to an Older Version of a File Branching And Merging Creating a Branch Selecting a Branch to Work On Merging from a Branch Going Back to the Head Branch Binary and Unicode Detection File Revision History History Dialog Revision Graph Dialog Web Log Making a Patch File 4. Customizing TortoiseCVS Overlay Icons Selecting a Different Set of Overlay Icons Changing how the Overlay Icons Work 5. Command Reference for TortoiseCVS Installing TortoiseCVS Obtaining a Working Copy: CVS Checkout... Getting Other People's Changes: CVS Update CVS Update Special... Making Your Changes Available to Others: CVS Commit... Adding New Files: CVS Add and CVS Add Contents... Discarding Obsolete Files: CVS Remove Finding Out What Has Changed: CVS Diff... Making a Snapshot: CVS Tag... Lines of Development: CVS Branch... CVS Merge... CVS Make New Module Watching And Locking Finding Out Who to Blame: CVS Annotate Showing More Information: CVS Explorer Columns Keyboard Shortcuts How Web Log Autodetects the Server URL 6. Dialog Reference for TortoiseCVS Add Dialog Checkout Dialog Update Special Dialog Commit Dialog Branch Dialog Make New Module Dialog Progress Dialog Tag Dialog Preferences Dialog Merge Dialog History Dialog Revision Graph Dialog About Dialog 7. -

NA-42 TI Shared Software Component Library FY2011 Final Report
PNNL-20567 Prepared for the U.S. Department of Energy under Contract DE-AC05-76RL01830 NA-42 TI Shared Software Component Library FY2011 Final Report CK Knudson FC Rutz KE Dorow July 2011 DISCLAIMER This report was prepared as an account of work sponsored by an agency of the United States Government. Neither the United States Government nor any agency thereof, nor Battelle Memorial Institute, nor any of their employees, makes any warranty, express or implied, or assumes any legal liability or responsibility for the accuracy, completeness, or usefulness of any information, apparatus, product, or process disclosed, or represents that its use would not infringe privately owned rights. Reference herein to any specific commercial product, process, or service by trade name, trademark, manufacturer, or otherwise does not necessarily constitute or imply its endorsement, recommendation, or favoring by the United States Government or any agency thereof, or Battelle Memorial Institute. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States Government or any agency thereof. PACIFIC NORTHWEST NATIONAL LABORATORY operated by BATTELLE for the UNITED STATES DEPARTMENT OF ENERGY under Contract DE-AC05-76RL01830 Printed in the United States of America Available to DOE and DOE contractors from the Office of Scientific and Technical Information, P.O. Box 62, Oak Ridge, TN 37831-0062; ph: (865) 576-8401 fax: (865) 576-5728 email: [email protected] Available to the public from the National Technical Information Service, U.S. Department of Commerce, 5285 Port Royal Rd., Springfield, VA 22161 ph: (800) 553-6847 fax: (703) 605-6900 email: [email protected] online ordering: http://www.ntis.gov/ordering.htm This document was printed on recycled paper. -

Introduction to Version Control
1 Introduction to version control David Rey – DREAM 2 Overview • Collaborative work and version control • CVS vs. SVN • Main CVS/SVN user commands • Advanced use of CVS/SVN 3 Overview • Collaborative work and version control • CVS vs. SVN • Main CVS user commands • Advanced use of CVS 4 Collaborative work and version control: examples • Development • Source files: C, C++, java, Fortran, Tcl, Python, shell scripts, … • Build/config files: Makefile, ant, … • Text documents/articles/bibliographies • Plain text • Latex/bibtex • Web pages • Html • Php, javascripts, … • XML documents • ... 5 A software development process at INRIA • INRIA recommandations about software development: • http://www-sop.inria.fr/dream/rapports/devprocess/index.html • http://www-sop.inria.fr/dream/rapports/devprocess/main005.html#toc8 • « Best practices »: • CVS: http://www.tldp.org/REF/CVS-BestPractices/html/index.html • SVN: http://svn.collab.net/repos/svn/trunk/doc/user/svn-best-practices.html 6 Version control: main ideas • Distributed documents/collaborative work • Automatic merging • Alarms on conflicts • Easy communication between users (log messages, emails, …) • Version control: incremental versions • All previous versions available • Minimal necessary disk space (incremental) • History of changes/logs 7 Version control software • CVS: http://ximbiot.com/cvs/ • TortoiseCVS (http://www.tortoisecvs.org/) • WinCVS (http://www.wincvs.org/) • … • Subversion (SVN): http://subversion.tigris.org/ • TortoiseSVN (http://tortoisesvn.tigris.org/) • … • Forges that use