Small Memory Software by Weir, Noblea Programmer’S Introduction to Small Memory Software
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Osmosis Study Guide
How to Study in Medical School How to Study in Medical School Written by: Rishi Desai, MD, MPH • Brooke Miller, PhD • Shiv Gaglani, MBA • Ryan Haynes, PhD Edited by: Andrea Day, MA • Fergus Baird, MA • Diana Stanley, MBA • Tanner Marshall, MS Special Thanks to: Henry L. Roediger III, PhD • Robert A. Bjork, PhD • Matthew Lineberry, PhD About Osmosis Created by medical students at Johns Hopkins and the former Khan Academy Medicine team, Os- mosis helps more than 250,000 current and future clinicians better retain and apply knowledge via a web- and mobile platform that takes advantage of cutting-edge cognitive techniques. © Osmosis, 2017 Much of the work you see us do is licensed under a Creative Commons license. We strongly be- lieve educational materials should be made freely available to everyone and be as accessible as possible. We also want to thank the people who support us financially, so we’ve made this exclu- sive book for you as a token of our thanks. This book unlike much of our work, is not under an open license and we reserve all our copyright rights on it. We ask that you not share this book liberally with your friends and colleagues. Any proceeds we generate from this book will be spent on creat- ing more open content for everyone to use. Thank you for your continued support! You can also support us by: • Telling your classmates and friends about us • Donating to us on Patreon (www.patreon.com/osmosis) or YouTube (www.youtube.com/osmosis) • Subscribing to our educational platform (www.osmosis.org) 2 Contents Problem 1: Rapid Forgetting Solution: Spaced Repetition and 1 Interleaved Practice Problem 2: Passive Studying Solution: Testing Effect and 2 "Memory Palace" Problem 3: Past Behaviors Solution: Fogg Behavior Model and 3 Growth Mindset 3 Introduction Students don’t get into medical school by accident. -

Anki Essentialsessentials the Complete Guide to Remembering Anything with Anki
Anki EssentialsEsSentials the Complete Guide to Remembering Anything with Anki By Alex Vermeer – alexvermeer.com Anki Essentials Copyright ©2013 Alex Vermeer. All rights reserved. This book contains no affiliate links. If you enjoy this book, please consider telling your friends about both Anki and Anki Essentials. All layout and content by Alex Vermeer. This is version 1.0. Disclaimer: I am not responsible for any losses or damages you may experience when using Anki (not that I expect either to happen). Also, Anki—a free piece of software written primarily by the brilliant Damien Elmes—is constantly being developed and improved, so some of the information contained in this guide may be out-of-date. Of course, I take every measure to prevent this from happening. Table of Contents 1. Introduction 2. The What and Why of Anki 3. Installation & Configuration 4. Creating Your First Deck 5. Anatomy of a Collection 6. A Day in the Life of a Deck 7. The 20 Rules 8. Getting to Know the Deck List 9. Everything You Need to Know About Creating Notes 10. Cards: Tweaking Layout and Style Using Card Templates 11. Studying 101 12. Advanced Studying and Retention 13. Getting Familiar with the Card Browser 14. Enhancing Notes with Images, Sounds and Other Media 15. Math, Equations, and Scientific Markup Using LaTeX 16. Sharing Decks 17. Creating Notes in Bulk 18. Syncing with AnkiWeb 19. The Secret to Speed: Keyboard Shortcuts 20. Beware these Common Beginner Problems 21. A Collection of Other Possible Uses for Anki 22. Expanding Anki with Add-ons 23. -
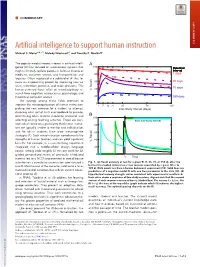
Artificial Intelligence to Support Human Instruction COMMENTARY Michael C
COMMENTARY Artificial intelligence to support human instruction COMMENTARY Michael C. Mozera,b,c,1, Melody Wiseheartd, and Timothy P. Novikoffc The popular media’s recent interest in artificial intelli- A gence (AI) has focused on autonomous systems that 100 Retention might ultimately replace people in fields as diverse as Interval 7 days medicine, customer service, and transportation and 80 logistics. Often neglected is a subfield of AI that fo- 35 days cuses on empowering people by improving how we 60 learn, remember, perceive, and make decisions. This 40 70 days human-centered focus relies on interdisciplinary re- % Recall search from cognitive neuroscience, psychology, and 20 theoretical computer science. 350 days The synergy among these fields promises to 0 improve the microorganization of human instruction: 1 7 14 21 35 70 105 picking the next exercise for a student to attempt, Inter-Study Interval (Days) choosing what sort of hints and feedback to provide, B determining when material should be reviewed, and 100 selecting among teaching activities. These are deci- best inter-study interval sions which occur on a granularity that human instruc- 80 tors are typically unable to monitor and individualize, and for which students have poor metacognitive 60 strategies (1). Such microinstruction complements the strengths of human teachers and can yield significant 40 % Recall benefits. For example, in a semester-long experiment integrated into a middle-school foreign language 20 course, setting aside roughly 30 min per week for AI- guided personalized review of previously introduced 0 t 0 Time material led to a 16.5% improvement in overall course retention on a cumulative examination administered a Fig. -

Spaced Repetition
PERG Physics Education Research Group Spaced Repetition What Use in Physics? Dr Alison Voice School of Physics & Astronomy University of Leeds Overview Introduce the concept (with references) How students learn (survey results) Practical suggestions ‘Ask the audience’ – share ideas PERG Physics Education Research Group Repetition to Learn ‘Practice makes perfect’ o Learn a language o Learn to drive o Play sport o Musical instrument o Times tables In all these we need regular, cumulative, repeated practice. PERG Physics Education Research Group Repetition not to Forget ‘Use it or lose it’ https://blog.wranx.com/ebbinghaus-forgetting-curve . First systematic investigation of memory in experimental psychology . With each ‘top up’ the decay rate decreases . Top up intervals widen Ebbinghaus forgetting curve Memory: A Contribution to Experimental Psychology 1885 PERG Physics Education Research Group Massed vs Spaced ‘Massed’ ‘Spaced’ Practice occurs all at once Practice spread out at intervals Many studies show enhanced long-term memory with spaced practice. Ebbinghaus 1913 Dempster 1988 Karpicke 2008 Cepeda 2006 Carpenter 2012 Optimal spacing gap depends on when the information should be recalled. Short spaces for short retention time. Long spaces for long retention time. Cepeda 2006 Many students and staff wrongly assume that massed practice is better due to the short-term memory gain. Kornell 2007 PERG Physics Education Research Group Test is Best ‘Active’ repetition is better than ‘Passive’ Mace 1968 i.e recall/testing is better than reading notes Students who self-tested Taking a self-test before a one week after learning, revision session improves remembered 80% in learning. Karpicke 2010 Free recall is better subsequent assessment, as than MCQ. -

Polycommit: Building Better Habits Through Gamification
POLYCOMMIT: BUILDING BETTER HABITS THROUGH GAMIFICATION A Thesis presented to the Faculty of California Polytechnic State University, San Luis Obispo In Partial Fulfillment of the Requirements for the Degree Master of Science in Computer Science by Elliot Fiske June 2017 c 2017 Elliot Fiske ALL RIGHTS RESERVED ii COMMITTEE MEMBERSHIP TITLE: Polycommit: Building Better Habits Through Gamification AUTHOR: Elliot Fiske DATE SUBMITTED: June 2017 COMMITTEE CHAIR: Foaad Khosmood, Ph.D. Professor of Computer Science COMMITTEE MEMBER: Zachary Peterson, Ph.D. Professor of Computer Science COMMITTEE MEMBER: Hugh Smith, Ph.D. Professor of Computer Science iii ABSTRACT Polycommit: Building Better Habits Through Gamification Elliot Fiske Computer-assisted learning is older than Turing machines, and constantly evolves as technology improves. While some teachers are resistant to using technology in the classroom [25], \e-learning" techniques are becoming more common in almost every school, from K-12 to universities [32]. As technology becomes more widespread, it becomes crucial to examine the various methodologies of computer-assisted learning and find the techniques that are most effective. This paper explores the effectiveness of one such methodology, spaced repetition. This technique applies to homework assignments available to students online. We include an exploration of several existing apps that use this technique, and introduce our own novel app, Polycommit. Polycommit was developed for use with several Cal Poly classes and was deployed during the first half of the Spring 2017 quarter. With careful attention to user feedback, we created a tool that motivated students to form better study habits. While our results do not show statistically significant improvement to student grades, this tool gives insight into how modern technology and gamification can be leveraged to create an engaging app that encourages posi- tive study habits, and gives us a platform to develop future applications concerning gamification. -

Digital Balance Resource Pack
Digital Balance Resource Pack October 2019 Introduction The Optus Digital Thumbprint program teaches young people to be safe, responsible and positive online through free, curriculum-aligned workshops that are fun and interactive. The Digital Thumbprint program has five key topics: Cyber Security Cyberbullying and Respectful Relationships Online Digital Identity Digital Discernment Digital Balance Each workshop focuses on two of these topics as Core Concepts. This document contains the teacher resources, top tips and take home sheet that support Digital Balance - the benefits of a balanced online/offline life. The two lesson plans are to be used by teachers in providing students with an interesting and engaging lesson around how technology can help you study better and learn more. Each section of the lesson plan contains: the overall aim of the section, an approximate timing for the section, the interaction between teachers and students, as well as a description of the material and suggestions of how it should be delivered for maximum impact. Lesson Plans: These lesson plans are organised by section, interaction type, and description. The section contains important information about the purpose of each phase as well as an estimated time allocation. The interaction describes the ideal flow of information between teachers (T) and students (S). For example, a T-S interaction could be a teacher asking questions and a student replying. An S-S interaction could be students working in pairs. The description explains the actions and questions or concepts that are communicated throughout the lesson. Teachers can use this information as a ‘run sheet’ for the session to ensure it runs smoothly. -

Beginner's Guide to Anki
Beginner’s Guide to Anki Ida Marie Lisle October 2020 Copyright StudyAid 2020 Authors Ida Marie Lisle Booklet Disclaimer All rights reserved. No part of this book may be reproduced in any form on by an electronic or mechanical means, without permission from StudyAid. Although the authors have made every effort to ensure the information in the booklet was correct at date of publishing, the authors do not assume and hereby disclaim any liability to any part for any information that is omitted or possible errors. This is not a collaboration with Anki. It is important to note, the material has not been approved by the creators of Anki. All illustrations in the booklet are original. This booklet is made especially for students at the Jagiellonian University in Krakow by tutors in the StudyAid group (students at JUMC). It is available as a PDF and is available for printing. If you have any questions concerning copyrights of the booklet please contact [email protected]. About StudyAid StudyAid is a student organization at the Jagiellonian University in Krakow. Throughout the academic year we host seminars in the major theoretical subjects: anatomy, physiology, biochemistry, immunology, pathophysiology, supplementing the lectures provided by the university. We are a group of 25 tutors, who are students at JU, each with their own field of specialty. To make our seminars as useful and relevant as possible, we teach in an interactive manner often using drawings and diagrams to help students remember the concepts. In addition to most seminars we create booklets, on which the seminars are based to aid the students in following the presentations. -

Gabriel H. Teninbaum* Abstract Spaced Repetition Is a Learning Method That Al- Lows People to Learn Far More, in Far Less Time
SPACED REPETITION: A METHOD FOR LEARNING MORE LAW IN LESS TIME Gabriel H. Teninbaum* Abstract Spaced repetition is a learning method that al- lows people to learn far more, in far less time. Discov- ered more than 100 years ago, recent advances in mo- bile technology have made its potential even greater to change the way law students, bar preppers and others in the legal field learn. This article describes the sci- ence of spaced repetition and its potential uses in law. It also describes the author’s work in building a plat- form for law students, SpacedRepetition.com, to allow them to harness this technology. Early findings are both exciting and consistent with the benefits of this method found in other fields. In one recent use of the technology, an entire graduating law school class was offered the chance to use SpacedRepetition.com to supplement their traditional bar preparation courses. Those who used the spaced * Professor of Legal Writing, Director of the Institute on Law Practice Technology & Innovation; Director of the Law Practice Technology Concentration, Suffolk University Law School; Visiting Professor, MIT; Visiting Fellow, Information Soci- ety Project, Yale Law School. To implement the theories laid out in this paper, Professor Teninbaum created “SeRiouS” (short for Spaced Repetition System), which is available for use at http://www.spacedrepetition.com. Copyright © 2017 Journal of High Technology Law and Gabriel H. Teninbaum. All Rights Reserved. ISSN 1536-7983. 274 JOURNAL OF HIGH TECHNOLOGY LAW [Vol. XVII: No. 2 repetition method passed the bar exam at a rate 19.2% higher than students who did not make use of it. -

How to Use the Forest Workers Online Training Tool in a Teaching Situation
How to use the Forest Workers Online Training Tool in a teaching situation Photeinos Santas Athanasios Stavropoulos Regas Santas OikoTechnics Institute Athens 2016 “...Just because you are up there teaching, doesn't mean that we' re learning” From the top student in a Physics class to the professor who happened to be the student’s father... i TABLE OF CONTENTS INTRODUCTION...............................................................................................1 ASSUMPTIONS.................................................................................................3 THE FOREST WORKER’S ONLINE TRAINING TOOL....................................3 Statistics.........................................................................................................3 Number of Lessons.....................................................................................3 Number of Terms by Lesson and Case Studies........................................4 Authoring workload distribution......................................................................4 Numbering Conventions.................................................................................4 Chapter And Lesson Layout...........................................................................5 Non-linear Lesson Teaching Order................................................................5 NAVIGATING THE FOREST WORKERS ONLINE TRAINING TOOL.............5 LEARNING OBJECTIVES.................................................................................8 Reading..........................................................................................................8 -
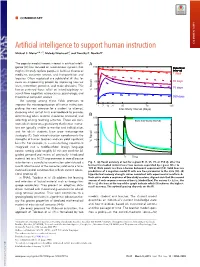
Artificial Intelligence to Support Human Instruction COMMENTARY Michael C
COMMENTARY Artificial intelligence to support human instruction COMMENTARY Michael C. Mozera,b,c,1, Melody Wiseheartd, and Timothy P. Novikoffc The popular media’s recent interest in artificial intelli- A gence (AI) has focused on autonomous systems that 100 Retention might ultimately replace people in fields as diverse as Interval 7 days medicine, customer service, and transportation and 80 logistics. Often neglected is a subfield of AI that fo- 35 days cuses on empowering people by improving how we 60 learn, remember, perceive, and make decisions. This 40 70 days human-centered focus relies on interdisciplinary re- % Recall search from cognitive neuroscience, psychology, and 20 theoretical computer science. 350 days The synergy among these fields promises to 0 improve the microorganization of human instruction: 1 7 14 21 35 70 105 picking the next exercise for a student to attempt, Inter-Study Interval (Days) choosing what sort of hints and feedback to provide, B determining when material should be reviewed, and 100 selecting among teaching activities. These are deci- best inter-study interval sions which occur on a granularity that human instruc- 80 tors are typically unable to monitor and individualize, and for which students have poor metacognitive 60 strategies (1). Such microinstruction complements the strengths of human teachers and can yield significant 40 % Recall benefits. For example, in a semester-long experiment integrated into a middle-school foreign language 20 course, setting aside roughly 30 min per week for AI- guided personalized review of previously introduced 0 t 0 Time material led to a 16.5% improvement in overall course retention on a cumulative examination administered a Fig. -

Spaced Repetition: Towards More Effective Learning in STEM
1 RESEARCH DIRECTIONS Spaced Repetition: towards more effective learning in STEM Alison Voice1*and Arran Stirton2 1School of Physics & Astronomy, University of Leeds, Leeds, LS2 9JT 2School of Physics & Astronomy, University of Leicester, Leicester, LE1 7RH Corresponding author: [email protected] Keywords: Spaced repetition; Long term memory; Cramming; Web app Abstract Introduction The use of spaced repetition within a physics The benefit of spaced repetition on learning higher education thermodynamics module has has been recognised for over a century, with been analysed for: its pattern of use by Ebbinghaus (1885) making the first systematic students; its effect on memory and investigation of memory, developing a performance in the end of module exam; and ‘forgetting curve’. This shows exponential performance in a delayed test after the summer decay of information from the memory when no vacation. A custom-built web app with the effort is made to revisit that information. facility to generate a personalised repetition However, if the information is revisited the rate timetable was used to deliver practice of decay reduces, thus allowing for ever questions on the material throughout the increasing time intervals between repetitions to module. Just over a quarter of students, retain long term memory of it. This psychology spanning the whole ability range of the class, research was first applied to education by made use of the app in some way, about half Mace (1968) suggesting that regular revision of using it in a spaced manner and half using it for curriculum material would be much more massed practice just before the exam. -

Tecnología E Impacto Social En La Enseñanza De Español Technology and Social Impact in Teaching Spanish
Tecnología e impacto social en la enseñanza de español Technology and social impact in teaching Spanish GABRIEL GUILLÉN MIDDLEBURY INSTITUTE OF INTERNATIONAL STUDIES AT MONTEREY [email protected] Resumen La presencia de 1256 startups de aprendizaje de lenguas en la plataforma Crunchbase y la existencia de una aplicación con más de 300 millones de usuarios son un indicador sólido tanto del interés por las lenguas como del deseo de rentabilizar este apetito sociocognitivo. Sin embargo, pocos de estos productos satisfacen las necesidades sociales de los estudiantes de lenguas (Heil et al, 2016; Dubreil y Thorne, 2017; Sawin y Guillén, 2017; Sykes, 2018). En este artículo se analiza el discurso, la experiencia de aprendizaje y el impacto social de tres proyectos tecnológicos para la adquisición de español como lengua extranjera, en el contexto de un supuesto boom tecnológico para el aprendizaje de lenguas. Palaras clave: enseñanza de español, impacto social, startups de aprendizaje de lenguas, aprendizaje de lenguas asistido por ordenador, aprendizaje móvil de lenguas Abstract The presence of 1256 language learning startups on Crunchbase and the existence of an application with more than 300 million users are a solid indicator of both an interest in language in the society and a desire to make this sociocognitive appetite profitable. However, few of these products meet the social needs of language learners (Heil, Wu, Lee and Schmidt, 2016; Dubreil & Thorne, 2017; Sawin & Guillén, 2017; Sykes, 2018). This article explores the discourse, learning experience, and social impact of three popular platforms for learning Spanish, in the context of what seems to be a bonanza for language learning and technology products.