Characteristics of Dynamic JVM Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Sun Glassfish Enterprise Server V3 Scripting Framework Guide
Sun GlassFish Enterprise Server v3 Scripting Framework Guide Sun Microsystems, Inc. 4150 Network Circle Santa Clara, CA 95054 U.S.A. Part No: 820–7697–11 December 2009 Copyright 2009 Sun Microsystems, Inc. 4150 Network Circle, Santa Clara, CA 95054 U.S.A. All rights reserved. Sun Microsystems, Inc. has intellectual property rights relating to technology embodied in the product that is described in this document. In particular, and without limitation, these intellectual property rights may include one or more U.S. patents or pending patent applications in the U.S. and in other countries. U.S. Government Rights – Commercial software. Government users are subject to the Sun Microsystems, Inc. standard license agreement and applicable provisions of the FAR and its supplements. This distribution may include materials developed by third parties. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, the Solaris logo, the Java Coffee Cup logo, docs.sun.com, Enterprise JavaBeans, EJB, GlassFish, J2EE, J2SE, Java Naming and Directory Interface, JavaBeans, Javadoc, JDBC, JDK, JavaScript, JavaServer, JavaServer Pages, JMX, JRE, JSP,JVM, MySQL, NetBeans, OpenSolaris, SunSolve, Sun GlassFish, ZFS, Java, and Solaris are trademarks or registered trademarks of Sun Microsystems, Inc. or its subsidiaries in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. -

(Cont'd) Current Trends
Scripting vs Systems Programming Languages (cont’d) Designed for gluing Designed for building Does application implement complex algorithms and data applications : flexibility applications : efficiency structures? Does application process large data sets (>10,000 items)? Interpreted Compiled Are application functions well-defined, fixed? Dynamic variable creation Variable declaration If yes, consider a system programming language. Data and code integrated : Data and code separated : meta-programming cannot create/run code on Is the main task to connect components, legacy apps? supported the fly Does the application manipulate a variety of things? Does the application have a GUI? Dynamic typing (typeless) Static typing Are the application's functions evolving rapidly? Examples: PERL, Tcl, Examples: PL/1, Ada, Must the application be extensible? Python, Ruby, Scheme, Java, C/C++, C#, etc Does the application do a lot of string manipulation? Visual Basic, etc If yes, consider a scripting language. cs480 (Prasad) LSysVsScipt 1 cs480 (Prasad) LSysVsScipt 2 Current Trends Jython (for convenient access to Java APIs) Hybrid Languages : Scripting + Systems Programming I:\tkprasad\cs480>jython – Recent JVM-based Scripting Languages Jython 2.1 on java1.4.1_02 (JIT: null) Type "copyright", "credits" or "license" for more information. »Jython : Python dialect >>> import javax.swing as swing >>> win = swing.JFrame("Welcome to Jython") »Clojure : LISP dialect >>> win.size = (200, 200) »Scala : OOP +Functional Hybrid >>> win.show() -

Amazon Codeguru Profiler
Amazon CodeGuru Profiler User Guide Amazon CodeGuru Profiler User Guide Amazon CodeGuru Profiler: User Guide Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Amazon CodeGuru Profiler User Guide Table of Contents What is Amazon CodeGuru Profiler? ..................................................................................................... 1 What can I do with CodeGuru Profiler? ......................................................................................... 1 What languages are supported by CodeGuru Profiler? ..................................................................... 1 How do I get started with CodeGuru Profiler? ................................................................................ 1 Setting up ......................................................................................................................................... 3 Set up in the Lambda console ..................................................................................................... 3 Step 1: Sign up for AWS .................................................................................................... -

Enrico Rubboli
Enrico Rubboli Contact Information Mobile UK: +44 741 4734233 Mobile IT: +39 349 8083244 E-mail: [email protected] Website: http://rubbo.li Personal Citizenship: Italian Information Gender: Male Date of Birth: 1976 October 27th Profile I'm a Senior Software Engineer with experience in several fields of web development. Switched to Ruby few years ago I can now boast several successful projects delivered. I'm currently searching for a new interesting opportunity in the fintech field. • 6 years of experience in Ruby and Rails • 14 years of overall experience as Web Developer • 14 years of experience in UNIX/networking/security • worked for the last 7 years with english speaking companies Technical Skills OS: GNU Linux (debian/arch), FreeBSD, OSX Programming: Ruby, Java, PHP, Perl, Bash/Zsh, C, Go lang Web & frameworks: Ruby on Rails, Sinatra, Symfony (PHP), JBoss (Java) and Torquebox (Jruby) TDD: JUnit, Rspec, Cucumber, Test:Unit Agile: Scrum, Pair Programming, XP Admins: Managing availability, scalability and efficiency of distributed systems, docker Networking: Firewalls (iptables/ipfw), IPsec, SSL, HTTP etc. Professional Experience Bitfinex - iFinex INC, Feb 2016 - present Role: Senior Software Engineer { Working in a very small team. { Different architectures and languages, in particular GoLang - Ruby and NodeJS. { Built the development environment on docker Company info: http://bitfinex.com - Hong Kong Burnside Digital Inc, Nov 2013 - Feb 2016 Role: Senior Software Engineer { Building apps using ruby on rails, nodeJS, AngularJS and Faye. { Assisting the sales team during the estimation process. { Leader of the web team Company info: http://burnsidedigital.com - Portland, OR, USA 1 of 2 Digital Science, Oct 2012 - Nov 2013 Role: Senior Software Engineer { Member of the central team. -

A Post-Apocalyptic Sun.Misc.Unsafe World
A Post-Apocalyptic sun.misc.Unsafe World http://www.superbwallpapers.com/fantasy/post-apocalyptic-tower-bridge-london-26546/ Chris Engelbert Twitter: @noctarius2k Jatumba! 2014, 2015, 2016, … Disclaimer This talk is not going to be negative! Disclaimer But certain things are highly speculative and APIs or ideas might change by tomorrow! sun.misc.Scissors http://www.underwhelmedcomic.com/wp-content/uploads/2012/03/runningdude.jpg sun.misc.Unsafe - What you (don’t) know sun.misc.Unsafe - What you (don’t) know • Internal class (sun.misc Package) sun.misc.Unsafe - What you (don’t) know • Internal class (sun.misc Package) sun.misc.Unsafe - What you (don’t) know • Internal class (sun.misc Package) • Used inside the JVM / JRE sun.misc.Unsafe - What you (don’t) know • Internal class (sun.misc Package) • Used inside the JVM / JRE // Unsafe mechanics private static final sun.misc.Unsafe U; private static final long QBASE; private static final long QLOCK; private static final int ABASE; private static final int ASHIFT; static { try { U = sun.misc.Unsafe.getUnsafe(); Class<?> k = WorkQueue.class; Class<?> ak = ForkJoinTask[].class; example: QBASE = U.objectFieldOffset (k.getDeclaredField("base")); java.util.concurrent.ForkJoinPool QLOCK = U.objectFieldOffset (k.getDeclaredField("qlock")); ABASE = U.arrayBaseOffset(ak); int scale = U.arrayIndexScale(ak); if ((scale & (scale - 1)) != 0) throw new Error("data type scale not a power of two"); ASHIFT = 31 - Integer.numberOfLeadingZeros(scale); } catch (Exception e) { throw new Error(e); } } } sun.misc.Unsafe -

Debian Java Insights and Challenges
Debian Java Insights and challenges Markus Koschany FOSDEM 19 Brussels / Belgium February, 3rd 2019 Markus Koschany Debian Java: Insights and challenges FOSDEM 19 1/7 The importance of Java Source / binary packages maintained by the Java team: 1033 / 1644 (+10,84 % since Debian 9) Source lines of code (Rank 3) : 90,744,884 Popcon value OpenJDK-8 (installed): 78104 / 199604 Popular libraries: apache-commons-*, javamail, xerces2, bouncycastle Popular applications: libreoffice, netbeans, pdfsam, sweethome3d, freeplane, freecol Frequently used for scientific research, medical care and bioinformatics. Markus Koschany Debian Java: Insights and challenges FOSDEM 19 2/7 What is new in Buster? OpenJDK 11 transition completed. (required more than 400! package updates) Build tools: Ant and Maven are up-to-date. Gradle is stuck at the last pre-Kotlin version. SBT is still being worked on. JVM languages: Groovy 2.14, Scala 2.11.12 (2.12 requires SBT), Clojure 1.9, Jython 1.7.1, JRuby 9.1.13 (?), Kotlin is wanted but hard to bootstrap. IDE: Eclipse is gone (lack of maintainers) but there is Netbeans 10 now. Server: Jetty 9.4 and Tomcat 9 fully up-to-date with systemd integration. Reproducibility rate is at 85% (was 75%) https://reproducible-builds.org Markus Koschany Debian Java: Insights and challenges FOSDEM 19 3/7 Packaging challenges “None of the packages in the main archive area require software outside of that area to function” Internet downloads at build time are not allowed No prebuilt jar or class files! Java is version-centric. Every developer has to update every dependency themself in this model. -

Ola Bini Computational Metalinguist [email protected] 698E 2885 C1DE 74E3 2CD5 03AD 295C 7469 84AF 7F0C
JRuby For The Win Ola Bini computational metalinguist [email protected] http://olabini.com/blog 698E 2885 C1DE 74E3 2CD5 03AD 295C 7469 84AF 7F0C onsdag 12 juni 13 Logistics and Demographics onsdag 12 juni 13 LAST MINUTE DEMO onsdag 12 juni 13 JRuby Implementation of the Ruby language Java 1.6+ 1.8.7 and 1.9.3 compatible (experimental 2.0 support) Open Source Created 2001 Embraces testing Current version: 1.7.4 Support from EngineYard, RedHat & ThoughtWorks onsdag 12 juni 13 Why JRuby? Threading Unicode Performance Memory Explicit extension API and OO internals Libraries and legacy systems Politics onsdag 12 juni 13 InvokeDynamic onsdag 12 juni 13 JRuby Differences Most compatible alternative implementation Native threads vs Green threads No C extensions (well, some) No continuations No fork ObjectSpace disabled by default onsdag 12 juni 13 Simple JRuby onsdag 12 juni 13 Java integration Java types == Ruby types Call methods, construct instances Static generation of classes camelCase or snake_case .getFoo(), setFoo(v) becomes .foo and .foo = v Interfaces can be implemented Classes can be inherited from Implicit closure conversion Extra added features to Rubyfy Java onsdag 12 juni 13 Ant+Rake onsdag 12 juni 13 Clojure STM onsdag 12 juni 13 Web onsdag 12 juni 13 Rails onsdag 12 juni 13 Sinatra onsdag 12 juni 13 Trinidad onsdag 12 juni 13 Swing Swing API == large and complex Ruby magic simplifies most of the tricky bits Java is a very verbose language Ruby makes Swing fun (more fun at least) No consistent cross-platform GUI library for Ruby -
Android Geeknight Presentation 2011-03
Android Geek Night 3.0 Per Nymann Jørgensen [email protected] Niels Sthen Hansen [email protected] Android Geek Night 3.0 Android at a glance New features in Gingerbread & Honeycomb Demos & Code Android 101 Operating system targeting mobile devices/Tables devices Linux based - with additions Open source under the Apache License Allows development in Java Share of worldwide 2010 Q4 smartphone sales to end users by Or Scala, JRuby, Groovy .. operating system, according toCanalys.[35] Two new versions just came out.. Android 101 - Dalvik VM Virtual machine developed by Google for mobile devices Uses the Dalvik Executable (.dex) format Designed for limited processing power and memory Register-based architecture as opposed to stack machine Java VMs Class library based on Apache Harmony No AWT, Swing No Java ME Android 101 - SDK Android libraries The SDK and AVD manager, for maintaining the SDK components and creating virtual devices LogCat to capture logs from running device DDMS – Dalvik Debug Monitor Tools to convert Java .class files to Dalvik bytecode and create installable .apk files Plugin for Eclipse - Android Development Tools (ADT) Android 101 - Components Activity GUI Service non-GUI Broadcast Receiver Events Content Provider Exposing data/content across applications An Android application can be seen as a collection of components. Android API 10 New stuff New Sensors / New Sensor APIs Gyroscope Rotation vector Acceleration Linear acceleration (acceleration without gravity) Gravity (gravity without acceleration) Barometer (air pressure) Android API 10 New stuff NFC Short range wireless communication. Do not require discovery or pairing Supported mode as of 2.3.3 (reader/writer/P2P limited) Enable application like Mobile ticketing (dare we say rejsekort), Smart poster, etc. -

Reading the Runes for Java Runtimes the Latest IBM Java Sdks
Java Technology Centre Reading the runes for Java runtimes The latest IBM Java SDKs ... and beyond Tim Ellison [email protected] © 2009 IBM Corporation Java Technology Centre Goals . IBM and Java . Explore the changing landscape of hardware and software influences . Discuss the impact to Java runtime technology due to these changes . Show how IBM is leading the way with these changes 2 Mar 9, 2009 © 2009 IBM Corporation Java Technology Centre IBM and Java . Java is critically important to IBM – Provides fundamental infrastructure to IBM software portfolio – Delivers standard development environment – Enables cost effective multi platform support – Delivered to Independent Software Vendors supporting IBM server platforms . IBM is investing strategically in virtual machine technology – Since Java 5.0, a single Java platform technology supports ME, SE and EE – Technology base on which to delivery improved performance, reliability and serviceability • Some IBM owned code (Virtual machine, JIT compiler, ...) • Some open source code (Apache XML parser, Apache Core libraries, Zlib, ...) • Some Sun licensed code (class libraries, tools, ...) . Looking to engender accelerated and open innovation in runtime technologies – Support for Eclipse, Apache (Harmony, XML, Derby, Geronimo, Tuscany) – Broad participation of relevant standards bodies such as JCP and OSGi 3 Mar 9, 2009 © 2009 IBM Corporation Java Technology Centre IBM Java – 2009 key initiatives . Consumability – Deliver value without complexity. – Ensure that problems with our products can be addressed quickly, allowing customers to keep focus on their own business issues. – Deliver a consistent model for solving customer problems. “Scaling Up” - Emerging hardware and applications – Provide a Java implementation that can scale to the most demanding application needs. -

Glassfish Server 3.0.1 Scripting Framework Guide
Oracle® GlassFish Server 3.0.1 Scripting Framework Guide Part No: 821–1760–10 June 2010 Copyright © 2010, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related software documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are “commercial computer software” or “commercial technical data” pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, duplication, disclosure, modification, and adaptation shall be subject to the restrictions and license terms setforth in the applicable Government contract, and, to the extent applicable by the terms of the Government contract, the additional rights set forth in FAR 52.227-19, Commercial Computer Software License (December 2007). Oracle America, Inc., 500 Oracle Parkway, Redwood City, CA 94065. -
Hitachi Cloud Accelerator Platform Product Manager HCAP V 1
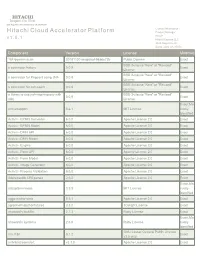
HITACHI Inspire the Next 2535 Augustine Drive Santa Clara, CA 95054 USA Contact Information : Hitachi Cloud Accelerator Platform Product Manager HCAP v 1 . 5 . 1 Hitachi Vantara LLC 2535 Augustine Dr. Santa Clara CA 95054 Component Version License Modified 18F/domain-scan 20181130-snapshot-988de72b Public Domain Exact BSD 3-clause "New" or "Revised" a connector factory 0.0.9 Exact License BSD 3-clause "New" or "Revised" a connector for Pageant using JNA 0.0.9 Exact License BSD 3-clause "New" or "Revised" a connector for ssh-agent 0.0.9 Exact License a library to use jsch-agent-proxy with BSD 3-clause "New" or "Revised" 0.0.9 Exact sshj License Exact,Ma activesupport 5.2.1 MIT License nually Identified Activiti - BPMN Converter 6.0.0 Apache License 2.0 Exact Activiti - BPMN Model 6.0.0 Apache License 2.0 Exact Activiti - DMN API 6.0.0 Apache License 2.0 Exact Activiti - DMN Model 6.0.0 Apache License 2.0 Exact Activiti - Engine 6.0.0 Apache License 2.0 Exact Activiti - Form API 6.0.0 Apache License 2.0 Exact Activiti - Form Model 6.0.0 Apache License 2.0 Exact Activiti - Image Generator 6.0.0 Apache License 2.0 Exact Activiti - Process Validation 6.0.0 Apache License 2.0 Exact Addressable URI parser 2.5.2 Apache License 2.0 Exact Exact,Ma adzap/timeliness 0.3.8 MIT License nually Identified aggs-matrix-stats 5.5.1 Apache License 2.0 Exact agronholm/pythonfutures 3.3.0 3Delight License Exact ahoward's lockfile 2.1.3 Ruby License Exact Exact,Ma ahoward's systemu 2.6.5 Ruby License nually Identified GNU Lesser General Public License ai's -

Deploying with Jruby Is the Definitive Text on Getting Jruby Applications up and Running
Early Praise for Deploying JRuby Deploying with JRuby is the definitive text on getting JRuby applications up and running. Joe has pulled together a great collection of deployment knowledge, and the JRuby story is much stronger as a result. ➤ Charles Oliver Nutter JRuby Core team member and coauthor, Using JRuby Deploying with JRuby answers all of the most frequently asked questions regarding real-world use of JRuby that I have seen, including many we were not able to answer in Using JRuby. Whether you’re coming to JRuby from Ruby or Java, Joe fills in all the gaps you’ll need to deploy JRuby with confidence. ➤ Nick Sieger JRuby Core team member and coauthor, Using JRuby This book is an excellent guide to navigating the various JRuby deployment op- tions. Joe is fair in his assessment of these technologies and describes a clear path for getting your Ruby application up and running on the JVM. ➤ Bob McWhirter TorqueBox team lead at Red Hat Essential reading to learn not only how to deploy web applications on JRuby but also why. ➤ David Calavera Creator of Trinidad Deploying with JRuby is a must-read for anyone interested in production JRuby deployments. The book walks through the major deployment strategies by providing easy-to-follow examples that help the reader take full advantage of the JRuby servers while avoiding the common pitfalls of migrating an application to JRuby. ➤ Ben Browning TorqueBox developer at Red Hat Deploying with JRuby is an invaluable resource for anyone planning on using JRuby for web-based development. For those who have never used JRuby, Joe clearly presents its many advantages and few disadvantages in comparison to MRI.