Dissertation Thesis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Clojure.Core 12
clojure #clojure 1 1: Clojure 2 2 2 Examples 3 3 1 : Leiningen 3 3 OS X 3 Homebrew 3 MacPorts 3 Windows 3 2 : 3 3 : 4 ", !" REPL 4 4 ", !" 4 ( ) 5 2: clj-time 6 6 Examples 6 6 - 6 6 6 joda - 7 - - 7 3: Clojure destructuring 8 Examples 8 8 8 9 9 9 fn params 9 10 10 : 10 Key 10 . 11 4: clojure.core 12 12 Examples 12 12 Assoc - / 12 Clojure 12 Dissoc - 13 5: clojure.spec 14 14 14 Examples 14 14 fdef : 14 14 clojure.spec / & clojure.spec / 15 15 16 16 18 6: clojure.test 19 Examples 19 ~. 19 19 deftest 19 20 . 20 Leiningen 20 7: core.async 22 Examples 22 : , , , . 22 chan 22 >!! >!! >! 22 <!! <!! 23 23 put! 24 take! 24 24 8: core.match 26 26 Examples 26 26 26 26 26 9: Java interop 27 27 27 Examples 27 Java 27 Java 27 Java 27 27 Clojure 28 10: 29 29 29 Examples 29 29 11: 30 Examples 30 30 30 31 IntelliJ IDEA + 31 Spacemacs + CIDER 31 32 12: 33 Examples 33 33 . 33 33 34 34 34 34 34 35 35 13: 36 36 36 Examples 36 36 36 14: 38 38 38 Examples 38 38 15: 39 39 Examples 39 (- >>) 39 (->) 39 (as->) 39 16: 40 40 Examples 40 40 40 40 17: 41 Examples 41 http-kit 41 Luminus 41 42 42 42 18: CIDER 43 43 Examples 43 43 43 19: 45 Examples 45 45 45 20: 46 46 Examples 46 46 46 48 52 55 58 21: 63 Examples 63 & 63 22: 64 64 64 Examples 64 64 64 / 65 23: 66 Examples 66 66 : 66 67 You can share this PDF with anyone you feel could benefit from it, downloaded the latest version from: clojure It is an unofficial and free clojure ebook created for educational purposes. -

Calendrical Calculations: Third Edition
Notes and Errata for Calendrical Calculations: Third Edition Nachum Dershowitz and Edward M. Reingold Cambridge University Press, 2008 4:00am, July 24, 2013 Do I contradict myself ? Very well then I contradict myself. (I am large, I contain multitudes.) —Walt Whitman: Song of Myself All those complaints that they mutter about. are on account of many places I have corrected. The Creator knows that in most cases I was misled by following. others whom I will spare the embarrassment of mention. But even were I at fault, I do not claim that I reached my ultimate perfection from the outset, nor that I never erred. Just the opposite, I always retract anything the contrary of which becomes clear to me, whether in my writings or my nature. —Maimonides: Letter to his student Joseph ben Yehuda (circa 1190), Iggerot HaRambam, I. Shilat, Maaliyot, Maaleh Adumim, 1987, volume 1, page 295 [in Judeo-Arabic] Cuiusvis hominis est errare; nullius nisi insipientis in errore perseverare. [Any man can make a mistake; only a fool keeps making the same one.] —Attributed to Marcus Tullius Cicero If you find errors not given below or can suggest improvements to the book, please send us the details (email to [email protected] or hard copy to Edward M. Reingold, Department of Computer Science, Illinois Institute of Technology, 10 West 31st Street, Suite 236, Chicago, IL 60616-3729 U.S.A.). If you have occasion to refer to errors below in corresponding with the authors, please refer to the item by page and line numbers in the book, not by item number. -

EHR Usability Test Report of Pediatricxpress, Version 20
Page | 1 EHR Usability Test Report of PediatricXpress, Version 20 Report based on ISO/IEC 25062:2006 Common Industry Format for Usability Test Reports Date of Usability Test: January 30, 2019 – February 8, 2019 Date of Report: February 11, 2019 (updated 10/28/20) Report Prepared by: PhysicianXpress, Inc. Vene Quezada, Product Specialist [email protected] 877-366-7331 409 2nd Avenue, Suite 201 Collegeville, PA 19426 Page | 2 Table of Contents 1 EXECUTIVE SUMMARY 3 2 INTRODUCTION 10 3 METHOD 10 3.1 PARTICIPANTS 10 3.2 STUDY DESIGN 12 3.3 TASKS 13 3.4 RISK ASSESSMENT 1 4 3.4 PROCEDURE 15 3.5 TEST LOCATION 16 3.6 TEST ENVIRONMENT 16 3.7 TEST FORMS AND TOOLS 17 3.8 PARTICIPANT INSTRUCTIONS 17 3.9 USABILITY METRICS 19 3.10 DATA SCORING 20 4 RESULTS 21 4.1 DATA ANALYSIS AND REPORTING 21 4.2 DISCUSSION OF THE FINDINGS 25 5 APPENDICES 29 5.1 Appendix 1: Participant Demographics 30 5.2 Appendix 2: Informed Consent Form 31 5.3 Appendix 3: Example Moderator’s guide 32 5.4 Appendix 4: System Usability Scale questionnaire 43 5.5 Appendix 5: Acknowledgement Form 44 Page | 3 EXECUTIVE SUMMARY A usability test of PediatricXpress, version 20, ambulatory E.H.R. was conducted on selected features of the PediatricXpress version 20 E.H.R. as part of the Safety- Enhanced Design requirements outlined in 170.315(g)(3) between January 30th , 2019 and February 8, 2019 at 409 2nd Avenue, Collegeville, PA 19426. The purpose of this testing was to test and validate the usability of the current user interface and provide evidence of usability in the EHR Under Test (EHRUT). -

Ceph: Distributed Storage for Cloud Infrastructure
ceph: distributed storage for cloud infrastructure sage weil msst – april 16, 2012 outline ● motivation ● practical guide, demo ● overview ● hardware ● ● how it works installation ● failure and recovery ● architecture ● rbd ● data distribution ● libvirt ● rados ● ● rbd project status ● distributed file system storage requirements ● scale ● terabytes, petabytes, exabytes ● heterogeneous hardware ● reliability and fault tolerance ● diverse storage needs ● object storage ● block devices ● shared file system (POSIX, coherent caches) ● structured data time ● ease of administration ● no manual data migration, load balancing ● painless scaling ● expansion and contraction ● seamless migration money ● low cost per gigabyte ● no vendor lock-in ● software solution ● commodity hardware ● open source ceph: unified storage system ● objects ● small or large ● multi-protocol Netflix VM Hadoop ● block devices radosgw RBD Ceph DFS ● snapshots, cloning RADOS ● files ● cache coherent ● snapshots ● usage accounting open source ● LGPLv2 ● copyleft ● free to link to proprietary code ● no copyright assignment ● no dual licensing ● no “enterprise-only” feature set distributed storage system ● data center (not geo) scale ● 10s to 10,000s of machines ● terabytes to exabytes ● fault tolerant ● no SPoF ● commodity hardware – ethernet, SATA/SAS, HDD/SSD – RAID, SAN probably a waste of time, power, and money architecture ● monitors (ceph-mon) ● 1s-10s, paxos ● lightweight process ● authentication, cluster membership, critical cluster state ● object storage daemons (ceph-osd) -

Solution 6: Drag and Drop 169
06_0132344815_ch06.qxd 10/16/07 11:41 AM Page 167 SolutionSolution 1: Drag and Drop 167 6 Drag and Drop The ultimate in user interactivity, drag and drop is taken for granted in desktop appli- cations but is a litmus test of sorts for web applications: If you can easily implement drag and drop with your web application framework, then you know you’ve got something special. Until now, drag and drop for web applications has, for the most part, been limited to specialized JavaScript frameworks such as Script.aculo.us and Rico.1 No more. With the advent of GWT, we have drag-and-drop capabilities in a Java-based web applica- tion framework. Although GWT does not explicitly support drag and drop (drag and drop is an anticipated feature in the future), it provides us with all the necessary ingre- dients to make our own drag-and-drop module. In this solution, we explore drag-and-drop implementation with GWT. We implement drag and drop in a module of its own so that you can easily incorporate drag and drop into your applications. Stuff You’re Going to Learn This solution explores the following aspects of GWT: • Implementing composite widgets with the Composite class (page 174) • Removing widgets from panels (page 169) • Changing cursors for widgets with CSS styles (page 200) • Implementing a GWT module (page 182) • Adding multiple listeners to a widget (page 186) • Using the AbsolutePanel class to place widgets by pixel location (page 211) • Capturing and releasing events for a specific widget (page 191) • Using an event preview to inhibit browser reactions to events (page 196) 1 See http://www.script.aculo.us and http://openrico.org for more information about Script.aculo.us and Rico, respectively. -

Priyanka Saggu
Priyanka Saggu Email: [email protected] Resourceful DevOps enthusiast, having experience working with highly distributed infrastructure on Website: https://priyankasaggu11929.github.io/ hybrid cloud platforms. Having a years long experience as a DevOps Engineer, I’ve been writing fully Gitlab-gnome: https://gitlab.gnome.org/priyankasaggu119 automated product releases, with minimal interference on the client enterprise end. As a contributor at Linux Users Group of Durgapur , I have set up and managed multiple Linux-based servers. Wrote Gitlab-salsa: https://gitlab.gnome.org/priyankasaggu119 Infrastructure as Code (IaC) to automate setting up of tightly-secured and SSH-hardened systems/ Github: https://github.com/Priyankasaggu11929/ servers using Ansible & Jinja templates. Also, carrying an experience with On-Prem deployment environments setup using Rancher. And I’m an Outreachy’19 alumna at GNOME Foundation too. EXPERIENCE SKILLS/ KEYWORDS Linux: Debian family (Ubuntu, Debian Buster), Red Hat AtlanHQ family (CentOS) — DevOps Engineer Scripting: Bash and utils, Python (FEB 2020 - PRESENT) Backend: Python (Django) Working at a DataOps organisation, has resulted in a high level of expertise in writing & maintaining infrastructure for industrial use. In one instance, I’ve worked on optimizing Frontend: HTML, CSS, Javascript (JQuery, PhaserJS) the cost of running an entire data cataloging & discovery stack by 40%, bringing in a lite version of the product. GUI Toolkit: GTK+ 3 in pure C GNOME Foundation Databases: MySQL, SQLite — Outreachy’19 Intern Web Application servers/proxies: Nginx, Apache2 (DEC 2019 - MAR 2020) Version control systems: Git Enhanced GNOME Translation Editor (gtranslator) UI by revamping existing widgets in accordance with Gnome Human Interface Guidelines (HIG). -

Open Source Software
OPEN SOURCE SOFTWARE Product AVD9x0x0-0010 Firmware and version 3.4.57 Notes on Open Source software The TCS device uses Open Source software that has been released under specific licensing requirements such as the ”General Public License“ (GPL) Version 2 or 3, the ”Lesser General Public License“ (LGPL), the ”Apache License“ or similar licenses. Any accompanying material such as instruction manuals, handbooks etc. contain copyright notes, conditions of use or licensing requirements that contradict any applicable Open Source license, these conditions are inapplicable. The use and distribution of any Open Source software used in the product is exclusively governed by the respective Open Source license. The programmers provided their software without ANY WARRANTY, whether implied or expressed, of any fitness for a particular purpose. Further, the programmers DECLINE ALL LIABILITY for damages, direct or indirect, that result from the using this software. This disclaimer does not affect the responsibility of TCS. AVAILABILITY OF SOURCE CODE: Where the applicable license entitles you to the source code of such software and/or other additional data, you may obtain it for a period of three years after purchasing this product, and, if required by the license conditions, for as long as we offer customer support for the device. If this document is available at the website of TCS and TCS offers a download of the firmware, the offer to receive the source code is valid for a period of three years and, if required by the license conditions, for as long as TCS offers customer support for the device. TCS provides an option for obtaining the source code: You may obtain any version of the source code that has been distributed by TCS for the cost of reproduction of the physical copy. -

Digitalocean
UPDATE SAGE WEIL – RED HAT SC16 CEPH BOF – 2016.11.16 2 JEWEL APPAPP APPAPP HOST/VMHOST/VM CLIENTCLIENT RADOSGWRADOSGW RBDRBD CEPHCEPH FSFS LIBRADOSLIBRADOS AA bucket-based bucket-based AA reliable reliable and and fully- fully- AA POSIX-compliant POSIX-compliant AA library library allowing allowing RESTREST gateway, gateway, distributeddistributed block block distributeddistributed file file appsapps to to directly directly compatiblecompatible with with S3 S3 device,device, with with a a Linux Linux system,system, with with a a accessaccess RADOS, RADOS, andand Swift Swift kernelkernel client client and and a a LinuxLinux kernel kernel client client withwith support support for for QEMU/KVMQEMU/KVM driver driver andand support support for for C,C, C++, C++, Java, Java, FUSEFUSE Python,Python, Ruby, Ruby, andand PHP PHP AWESOME AWESOME NEARLY AWESOME AWESOME RADOSRADOS AWESOME AA reliable, reliable, autonomous, autonomous, distributed distributed object object store store comprised comprised of of self-healing, self-healing, self-managing, self-managing, intelligentintelligent storage storage nodes nodes 3 2016 = FULLY AWESOME OBJECT BLOCK FILE RGW RBD CEPHFS S3 and Swift compatible A virtual block device with A distributed POSIX file object storage with object snapshots, copy-on-write system with coherent versioning, multi-site clones, and multi-site caches and snapshots on federation, and replication replication any directory LIBRADOS A library allowing apps to direct access RADOS (C, C++, Java, Python, Ruby, PHP) RADOS A software-based, -

2015 Open Source Yearbook
Opensource.com/yearbook . ........ OPENSOURCE.COM ................... Opensource.com publishes stories about creating, adopting, and sharing open source solutions. Visit Opensource.com to learn more about how the open source way is improving technologies, education, business, government, health, law, entertainment, humanitarian efforts, and more. Submit a story idea: https://opensource.com/story Email us: [email protected] Chat with us in Freenode IRC: #opensource.com Twitter @opensourceway: https://twitter.com/opensourceway Google+: https://plus.google.com/+opensourceway Facebook: https://www.facebook.com/opensourceway Instagram: https://www.instagram.com/opensourceway FROM THE EDITOR ............................. Dear Open Source Yearbook reader, The “open source” label was created back in 1998, not long after I got my start in tech publishing [1]. Fast forward to late 2014, when I was thinking about how much open source technologies, commu- nities, and business models have changed since 1998. I realized that there was no easy way—like a yearbook—to thumb through tech history to get a feel for open source. Sure, you can flip through the virtual pages of a Google search and read the “Best of” lists collected by a variety of technical publications and writers, much like you can thumb through newspapers from the 1980s to see the how big we wore our shoulder pads, neon clothing, and hair back then. But neither research method is particularly efficient, nor do they provide snapshots that show diversity within communities and moments of time. The idea behind the Open Source Yearbook is to collaborate with open source communities to collect a diverse range of stories from the year. -

Op E N So U R C E Yea R B O O K 2 0
OPEN SOURCE YEARBOOK 2016 ..... ........ .... ... .. .... .. .. ... .. OPENSOURCE.COM Opensource.com publishes stories about creating, adopting, and sharing open source solutions. Visit Opensource.com to learn more about how the open source way is improving technologies, education, business, government, health, law, entertainment, humanitarian efforts, and more. Submit a story idea: https://opensource.com/story Email us: [email protected] Chat with us in Freenode IRC: #opensource.com . OPEN SOURCE YEARBOOK 2016 . OPENSOURCE.COM 3 ...... ........ .. .. .. ... .... AUTOGRAPHS . ... .. .... .. .. ... .. ........ ...... ........ .. .. .. ... .... AUTOGRAPHS . ... .. .... .. .. ... .. ........ OPENSOURCE.COM...... ........ .. .. .. ... .... ........ WRITE FOR US ..... .. .. .. ... .... 7 big reasons to contribute to Opensource.com: Career benefits: “I probably would not have gotten my most recent job if it had not been for my articles on 1 Opensource.com.” Raise awareness: “The platform and publicity that is available through Opensource.com is extremely 2 valuable.” Grow your network: “I met a lot of interesting people after that, boosted my blog stats immediately, and 3 even got some business offers!” Contribute back to open source communities: “Writing for Opensource.com has allowed me to give 4 back to a community of users and developers from whom I have truly benefited for many years.” Receive free, professional editing services: “The team helps me, through feedback, on improving my 5 writing skills.” We’re loveable: “I love the Opensource.com team. I have known some of them for years and they are 6 good people.” 7 Writing for us is easy: “I couldn't have been more pleased with my writing experience.” Email us to learn more or to share your feedback about writing for us: https://opensource.com/story Visit our Participate page to more about joining in the Opensource.com community: https://opensource.com/participate Find our editorial team, moderators, authors, and readers on Freenode IRC at #opensource.com: https://opensource.com/irc . -
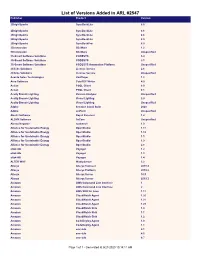
List of Versions Added in ARL #2547 Publisher Product Version
List of Versions Added in ARL #2547 Publisher Product Version 2BrightSparks SyncBackLite 8.5 2BrightSparks SyncBackLite 8.6 2BrightSparks SyncBackLite 8.8 2BrightSparks SyncBackLite 8.9 2BrightSparks SyncBackPro 5.9 3Dconnexion 3DxWare 1.2 3Dconnexion 3DxWare Unspecified 3S-Smart Software Solutions CODESYS 3.4 3S-Smart Software Solutions CODESYS 3.5 3S-Smart Software Solutions CODESYS Automation Platform Unspecified 4Clicks Solutions License Service 2.6 4Clicks Solutions License Service Unspecified Acarda Sales Technologies VoxPlayer 1.2 Acro Software CutePDF Writer 4.0 Actian PSQL Client 8.0 Actian PSQL Client 8.1 Acuity Brands Lighting Version Analyzer Unspecified Acuity Brands Lighting Visual Lighting 2.0 Acuity Brands Lighting Visual Lighting Unspecified Adobe Creative Cloud Suite 2020 Adobe JetForm Unspecified Alastri Software Rapid Reserver 1.4 ALDYN Software SvCom Unspecified Alexey Kopytov sysbench 1.0 Alliance for Sustainable Energy OpenStudio 1.11 Alliance for Sustainable Energy OpenStudio 1.12 Alliance for Sustainable Energy OpenStudio 1.5 Alliance for Sustainable Energy OpenStudio 1.9 Alliance for Sustainable Energy OpenStudio 2.8 alta4 AG Voyager 1.2 alta4 AG Voyager 1.3 alta4 AG Voyager 1.4 ALTER WAY WampServer 3.2 Alteryx Alteryx Connect 2019.4 Alteryx Alteryx Platform 2019.2 Alteryx Alteryx Server 10.5 Alteryx Alteryx Server 2019.3 Amazon AWS Command Line Interface 1 Amazon AWS Command Line Interface 2 Amazon AWS SDK for Java 1.11 Amazon CloudWatch Agent 1.20 Amazon CloudWatch Agent 1.21 Amazon CloudWatch Agent 1.23 Amazon -

Diversity Neither in Promises Nor Whispers Only : Gender and Other Factors from the Otrv4 Project
Diversity neither in promises nor whispers only : gender and other factors from the OTRv4 project. Camille Akmut February 6, 2020 abstract Commits : >1. (Three more participants were part of this project and had each 1 commit only.) Brief remarks on select other projects. 1 1 claucece 975 commits Sofia Celi f 2 juniorz 151 commits Reinaldo de Souza Jr m 3 tcz001 91 commits ? ? 4 rosatolen 71 commits Rosalie Tolentino (?) f (?) 5 tdruiva 65 commits Tania S f 6 natalieesk 63 commits Natalie Eskinazi f 7 yakiradixon 58 commits Yakira Dixon ? 8 iapazmino 57 commits Ivan Pazmino m 9 olabini 32 commits Ola Bini m 10 chelseakomlo 24 commits Chelsea Komlo f 11 annacruz 20 commits Anna Cruz f 12 DrWhax 19 commits Jurre van Bergen (?) m (?) 13 deniscostadsc 15 commits Denis Costa m 14 cobratbq 11 commits ? m Table 1: Diversity in the OTRv4 project measured 06/02/2020 c. 12.30 pm There are at least 6 women for 14 participants among those who have made more than one recorded contribution. In that population, we observe also a certain diversity in terms of white and black or non-white participants as well as geographical origins (at least 3 participants were from South America, for instance). 2 Conclusion A series of publications on diversity hereby comes to an end. Of all projects reviewed so far, this one came closest to what we had pictured as "diverse". Diversity : a problematic notion, yet it remains that projects such as GNU or the Linux kernel, lead almost entirely by men, and resulting in extraordinarily aberrant statistics such as "100%" or "99%" per cent male participants, cannot be said to be diverse by any stretch of the imagination or the human mind.