Rare Variant Analyses Across Multiethnic Cohorts Identify Novel Genes for Refractive Error
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Analysis of Trans Esnps Infers Regulatory Network Architecture
Analysis of trans eSNPs infers regulatory network architecture Anat Kreimer Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences COLUMBIA UNIVERSITY 2014 © 2014 Anat Kreimer All rights reserved ABSTRACT Analysis of trans eSNPs infers regulatory network architecture Anat Kreimer eSNPs are genetic variants associated with transcript expression levels. The characteristics of such variants highlight their importance and present a unique opportunity for studying gene regulation. eSNPs affect most genes and their cell type specificity can shed light on different processes that are activated in each cell. They can identify functional variants by connecting SNPs that are implicated in disease to a molecular mechanism. Examining eSNPs that are associated with distal genes can provide insights regarding the inference of regulatory networks but also presents challenges due to the high statistical burden of multiple testing. Such association studies allow: simultaneous investigation of many gene expression phenotypes without assuming any prior knowledge and identification of unknown regulators of gene expression while uncovering directionality. This thesis will focus on such distal eSNPs to map regulatory interactions between different loci and expose the architecture of the regulatory network defined by such interactions. We develop novel computational approaches and apply them to genetics-genomics data in human. We go beyond pairwise interactions to define network motifs, including regulatory modules and bi-fan structures, showing them to be prevalent in real data and exposing distinct attributes of such arrangements. We project eSNP associations onto a protein-protein interaction network to expose topological properties of eSNPs and their targets and highlight different modes of distal regulation. -

Mutant IDH, (R)-2-Hydroxyglutarate, and Cancer
Downloaded from genesdev.cshlp.org on October 1, 2021 - Published by Cold Spring Harbor Laboratory Press REVIEW What a difference a hydroxyl makes: mutant IDH, (R)-2-hydroxyglutarate, and cancer Julie-Aurore Losman1 and William G. Kaelin Jr.1,2,3 1Department of Medical Oncology, Dana-Farber Cancer Institute, Brigham and Women’s Hospital, Harvard Medical School, Boston, Massachusetts 02215, USA; 2Howard Hughes Medical Institute, Chevy Chase, Maryland 20815, USA Mutations in metabolic enzymes, including isocitrate whether altered cellular metabolism is a cause of cancer dehydrogenase 1 (IDH1) and IDH2, in cancer strongly or merely an adaptive response of cancer cells in the face implicate altered metabolism in tumorigenesis. IDH1 of accelerated cell proliferation is still a topic of some and IDH2 catalyze the interconversion of isocitrate and debate. 2-oxoglutarate (2OG). 2OG is a TCA cycle intermediate The recent identification of cancer-associated muta- and an essential cofactor for many enzymes, including tions in three metabolic enzymes suggests that altered JmjC domain-containing histone demethylases, TET cellular metabolism can indeed be a cause of some 5-methylcytosine hydroxylases, and EglN prolyl-4-hydrox- cancers (Pollard et al. 2003; King et al. 2006; Raimundo ylases. Cancer-associated IDH mutations alter the enzymes et al. 2011). Two of these enzymes, fumarate hydratase such that they reduce 2OG to the structurally similar (FH) and succinate dehydrogenase (SDH), are bone fide metabolite (R)-2-hydroxyglutarate [(R)-2HG]. Here we tumor suppressors, and loss-of-function mutations in FH review what is known about the molecular mechanisms and SDH have been identified in various cancers, in- of transformation by mutant IDH and discuss their im- cluding renal cell carcinomas and paragangliomas. -

Gene PMID WBS Locus ABR 26603386 AASDH 26603386
Supplementary material J Med Genet Gene PMID WBS Locus ABR 26603386 AASDH 26603386 ABCA1 21304579 ABCA13 26603386 ABCA3 25501393 ABCA7 25501393 ABCC1 25501393 ABCC3 25501393 ABCG1 25501393 ABHD10 21304579 ABHD11 25501393 yes ABHD2 25501393 ABHD5 21304579 ABLIM1 21304579;26603386 ACOT12 25501393 ACSF2,CHAD 26603386 ACSL4 21304579 ACSM3 26603386 ACTA2 25501393 ACTN1 26603386 ACTN3 26603386;25501393;25501393 ACTN4 21304579 ACTR1B 21304579 ACVR2A 21304579 ACY3 19897463 ACYP1 21304579 ADA 25501393 ADAM12 21304579 ADAM19 25501393 ADAM32 26603386 ADAMTS1 25501393 ADAMTS10 25501393 ADAMTS12 26603386 ADAMTS17 26603386 ADAMTS6 21304579 ADAMTS7 25501393 ADAMTSL1 21304579 ADAMTSL4 25501393 ADAMTSL5 25501393 ADCY3 25501393 ADK 21304579 ADRBK2 25501393 AEBP1 25501393 AES 25501393 AFAP1,LOC84740 26603386 AFAP1L2 26603386 AFG3L1 21304579 AGAP1 26603386 AGAP9 21304579 Codina-Sola M, et al. J Med Genet 2019; 56:801–808. doi: 10.1136/jmedgenet-2019-106080 Supplementary material J Med Genet AGBL5 21304579 AGPAT3 19897463;25501393 AGRN 25501393 AGXT2L2 25501393 AHCY 25501393 AHDC1 26603386 AHNAK 26603386 AHRR 26603386 AIDA 25501393 AIFM2 21304579 AIG1 21304579 AIP 21304579 AK5 21304579 AKAP1 25501393 AKAP6 21304579 AKNA 21304579 AKR1E2 26603386 AKR7A2 21304579 AKR7A3 26603386 AKR7L 26603386 AKT3 21304579 ALDH18A1 25501393;25501393 ALDH1A3 21304579 ALDH1B1 21304579 ALDH6A1 21304579 ALDOC 21304579 ALG10B 26603386 ALG13 21304579 ALKBH7 25501393 ALPK2 21304579 AMPH 21304579 ANG 21304579 ANGPTL2,RALGPS1 26603386 ANGPTL6 26603386 ANK2 21304579 ANKMY1 26603386 ANKMY2 -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

4-6 Weeks Old Female C57BL/6 Mice Obtained from Jackson Labs Were Used for Cell Isolation
Methods Mice: 4-6 weeks old female C57BL/6 mice obtained from Jackson labs were used for cell isolation. Female Foxp3-IRES-GFP reporter mice (1), backcrossed to B6/C57 background for 10 generations, were used for the isolation of naïve CD4 and naïve CD8 cells for the RNAseq experiments. The mice were housed in pathogen-free animal facility in the La Jolla Institute for Allergy and Immunology and were used according to protocols approved by the Institutional Animal Care and use Committee. Preparation of cells: Subsets of thymocytes were isolated by cell sorting as previously described (2), after cell surface staining using CD4 (GK1.5), CD8 (53-6.7), CD3ε (145- 2C11), CD24 (M1/69) (all from Biolegend). DP cells: CD4+CD8 int/hi; CD4 SP cells: CD4CD3 hi, CD24 int/lo; CD8 SP cells: CD8 int/hi CD4 CD3 hi, CD24 int/lo (Fig S2). Peripheral subsets were isolated after pooling spleen and lymph nodes. T cells were enriched by negative isolation using Dynabeads (Dynabeads untouched mouse T cells, 11413D, Invitrogen). After surface staining for CD4 (GK1.5), CD8 (53-6.7), CD62L (MEL-14), CD25 (PC61) and CD44 (IM7), naïve CD4+CD62L hiCD25-CD44lo and naïve CD8+CD62L hiCD25-CD44lo were obtained by sorting (BD FACS Aria). Additionally, for the RNAseq experiments, CD4 and CD8 naïve cells were isolated by sorting T cells from the Foxp3- IRES-GFP mice: CD4+CD62LhiCD25–CD44lo GFP(FOXP3)– and CD8+CD62LhiCD25– CD44lo GFP(FOXP3)– (antibodies were from Biolegend). In some cases, naïve CD4 cells were cultured in vitro under Th1 or Th2 polarizing conditions (3, 4). -

Genetic and Genomic Analysis of Hyperlipidemia, Obesity and Diabetes Using (C57BL/6J × TALLYHO/Jngj) F2 Mice
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Nutrition Publications and Other Works Nutrition 12-19-2010 Genetic and genomic analysis of hyperlipidemia, obesity and diabetes using (C57BL/6J × TALLYHO/JngJ) F2 mice Taryn P. Stewart Marshall University Hyoung Y. Kim University of Tennessee - Knoxville, [email protected] Arnold M. Saxton University of Tennessee - Knoxville, [email protected] Jung H. Kim Marshall University Follow this and additional works at: https://trace.tennessee.edu/utk_nutrpubs Part of the Animal Sciences Commons, and the Nutrition Commons Recommended Citation BMC Genomics 2010, 11:713 doi:10.1186/1471-2164-11-713 This Article is brought to you for free and open access by the Nutrition at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Nutrition Publications and Other Works by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. Stewart et al. BMC Genomics 2010, 11:713 http://www.biomedcentral.com/1471-2164/11/713 RESEARCH ARTICLE Open Access Genetic and genomic analysis of hyperlipidemia, obesity and diabetes using (C57BL/6J × TALLYHO/JngJ) F2 mice Taryn P Stewart1, Hyoung Yon Kim2, Arnold M Saxton3, Jung Han Kim1* Abstract Background: Type 2 diabetes (T2D) is the most common form of diabetes in humans and is closely associated with dyslipidemia and obesity that magnifies the mortality and morbidity related to T2D. The genetic contribution to human T2D and related metabolic disorders is evident, and mostly follows polygenic inheritance. The TALLYHO/ JngJ (TH) mice are a polygenic model for T2D characterized by obesity, hyperinsulinemia, impaired glucose uptake and tolerance, hyperlipidemia, and hyperglycemia. -

Noelia Díaz Blanco
Effects of environmental factors on the gonadal transcriptome of European sea bass (Dicentrarchus labrax), juvenile growth and sex ratios Noelia Díaz Blanco Ph.D. thesis 2014 Submitted in partial fulfillment of the requirements for the Ph.D. degree from the Universitat Pompeu Fabra (UPF). This work has been carried out at the Group of Biology of Reproduction (GBR), at the Department of Renewable Marine Resources of the Institute of Marine Sciences (ICM-CSIC). Thesis supervisor: Dr. Francesc Piferrer Professor d’Investigació Institut de Ciències del Mar (ICM-CSIC) i ii A mis padres A Xavi iii iv Acknowledgements This thesis has been made possible by the support of many people who in one way or another, many times unknowingly, gave me the strength to overcome this "long and winding road". First of all, I would like to thank my supervisor, Dr. Francesc Piferrer, for his patience, guidance and wise advice throughout all this Ph.D. experience. But above all, for the trust he placed on me almost seven years ago when he offered me the opportunity to be part of his team. Thanks also for teaching me how to question always everything, for sharing with me your enthusiasm for science and for giving me the opportunity of learning from you by participating in many projects, collaborations and scientific meetings. I am also thankful to my colleagues (former and present Group of Biology of Reproduction members) for your support and encouragement throughout this journey. To the “exGBRs”, thanks for helping me with my first steps into this world. Working as an undergrad with you Dr. -

Role of RUNX1 in Aberrant Retinal Angiogenesis Jonathan D
Page 1 of 25 Diabetes Identification of RUNX1 as a mediator of aberrant retinal angiogenesis Short Title: Role of RUNX1 in aberrant retinal angiogenesis Jonathan D. Lam,†1 Daniel J. Oh,†1 Lindsay L. Wong,1 Dhanesh Amarnani,1 Cindy Park- Windhol,1 Angie V. Sanchez,1 Jonathan Cardona-Velez,1,2 Declan McGuone,3 Anat O. Stemmer- Rachamimov,3 Dean Eliott,4 Diane R. Bielenberg,5 Tave van Zyl,4 Lishuang Shen,1 Xiaowu Gai,6 Patricia A. D’Amore*,1,7 Leo A. Kim*,1,4 Joseph F. Arboleda-Velasquez*1 Author affiliations: 1Schepens Eye Research Institute/Massachusetts Eye and Ear, Department of Ophthalmology, Harvard Medical School, 20 Staniford St., Boston, MA 02114 2Universidad Pontificia Bolivariana, Medellin, Colombia, #68- a, Cq. 1 #68305, Medellín, Antioquia, Colombia 3C.S. Kubik Laboratory for Neuropathology, Massachusetts General Hospital, 55 Fruit St., Boston, MA 02114 4Retina Service, Massachusetts Eye and Ear Infirmary, Department of Ophthalmology, Harvard Medical School, 243 Charles St., Boston, MA 02114 5Vascular Biology Program, Boston Children’s Hospital, Department of Surgery, Harvard Medical School, 300 Longwood Ave., Boston, MA 02115 6Center for Personalized Medicine, Children’s Hospital Los Angeles, Los Angeles, 4650 Sunset Blvd, Los Angeles, CA 90027, USA 7Department of Pathology, Harvard Medical School, 25 Shattuck St., Boston, MA 02115 Corresponding authors: Joseph F. Arboleda-Velasquez: [email protected] Ph: (617) 912-2517 Leo Kim: [email protected] Ph: (617) 912-2562 Patricia D’Amore: [email protected] Ph: (617) 912-2559 Fax: (617) 912-0128 20 Staniford St. Boston MA, 02114 † These authors contributed equally to this manuscript Word Count: 1905 Tables and Figures: 4 Diabetes Publish Ahead of Print, published online April 11, 2017 Diabetes Page 2 of 25 Abstract Proliferative diabetic retinopathy (PDR) is a common cause of blindness in the developed world’s working adult population, and affects those with type 1 and type 2 diabetes mellitus. -

1 Mutational Heterogeneity in Cancer Akash Kumar a Dissertation
Mutational Heterogeneity in Cancer Akash Kumar A dissertation Submitted in partial fulfillment of requirements for the degree of Doctor of Philosophy University of Washington 2014 June 5 Reading Committee: Jay Shendure Pete Nelson Mary Claire King Program Authorized to Offer Degree: Genome Sciences 1 University of Washington ABSTRACT Mutational Heterogeneity in Cancer Akash Kumar Chair of the Supervisory Committee: Associate Professor Jay Shendure Department of Genome Sciences Somatic mutation plays a key role in the formation and progression of cancer. Differences in mutation patterns likely explain much of the heterogeneity seen in prognosis and treatment response among patients. Recent advances in massively parallel sequencing have greatly expanded our capability to investigate somatic mutation. Genomic profiling of tumor biopsies could guide the administration of targeted therapeutics on the basis of the tumor’s collection of mutations. Central to the success of this approach is the general applicability of targeted therapies to a patient’s entire tumor burden. This requires a better understanding of the genomic heterogeneity present both within individual tumors (intratumoral) and amongst tumors from the same patient (intrapatient). My dissertation is broadly organized around investigating mutational heterogeneity in cancer. Three projects are discussed in detail: analysis of (1) interpatient and (2) intrapatient heterogeneity in men with disseminated prostate cancer, and (3) investigation of regional intratumoral heterogeneity in -

Analysis of the Indacaterol-Regulated Transcriptome in Human Airway
Supplemental material to this article can be found at: http://jpet.aspetjournals.org/content/suppl/2018/04/13/jpet.118.249292.DC1 1521-0103/366/1/220–236$35.00 https://doi.org/10.1124/jpet.118.249292 THE JOURNAL OF PHARMACOLOGY AND EXPERIMENTAL THERAPEUTICS J Pharmacol Exp Ther 366:220–236, July 2018 Copyright ª 2018 by The American Society for Pharmacology and Experimental Therapeutics Analysis of the Indacaterol-Regulated Transcriptome in Human Airway Epithelial Cells Implicates Gene Expression Changes in the s Adverse and Therapeutic Effects of b2-Adrenoceptor Agonists Dong Yan, Omar Hamed, Taruna Joshi,1 Mahmoud M. Mostafa, Kyla C. Jamieson, Radhika Joshi, Robert Newton, and Mark A. Giembycz Departments of Physiology and Pharmacology (D.Y., O.H., T.J., K.C.J., R.J., M.A.G.) and Cell Biology and Anatomy (M.M.M., R.N.), Snyder Institute for Chronic Diseases, Cumming School of Medicine, University of Calgary, Calgary, Alberta, Canada Received March 22, 2018; accepted April 11, 2018 Downloaded from ABSTRACT The contribution of gene expression changes to the adverse and activity, and positive regulation of neutrophil chemotaxis. The therapeutic effects of b2-adrenoceptor agonists in asthma was general enriched GO term extracellular space was also associ- investigated using human airway epithelial cells as a therapeu- ated with indacaterol-induced genes, and many of those, in- tically relevant target. Operational model-fitting established that cluding CRISPLD2, DMBT1, GAS1, and SOCS3, have putative jpet.aspetjournals.org the long-acting b2-adrenoceptor agonists (LABA) indacaterol, anti-inflammatory, antibacterial, and/or antiviral activity. Numer- salmeterol, formoterol, and picumeterol were full agonists on ous indacaterol-regulated genes were also induced or repressed BEAS-2B cells transfected with a cAMP-response element in BEAS-2B cells and human primary bronchial epithelial cells by reporter but differed in efficacy (indacaterol $ formoterol . -
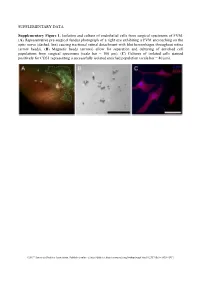
Supplementary Figures and Tables
SUPPLEMENTARY DATA Supplementary Figure 1. Isolation and culture of endothelial cells from surgical specimens of FVM. (A) Representative pre-surgical fundus photograph of a right eye exhibiting a FVM encroaching on the optic nerve (dashed line) causing tractional retinal detachment with blot hemorrhages throughout retina (arrow heads). (B) Magnetic beads (arrows) allow for separation and culturing of enriched cell populations from surgical specimens (scale bar = 100 μm). (C) Cultures of isolated cells stained positively for CD31 representing a successfully isolated enriched population (scale bar = 40 μm). ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Figure 2. Efficient siRNA knockdown of RUNX1 expression and function demonstrated by qRT-PCR, Western Blot, and scratch assay. (A) RUNX1 siRNA induced a 60% reduction of RUNX1 expression measured by qRT-PCR 48 hrs post-transfection whereas expression of RUNX2 and RUNX3, the two other mammalian RUNX orthologues, showed no significant changes, indicating specificity of our siRNA. Functional inhibition of Runx1 signaling was demonstrated by a 330% increase in insulin-like growth factor binding protein-3 (IGFBP3) RNA expression level, a known target of RUNX1 inhibition. Western blot demonstrated similar reduction in protein levels. (B) siRNA- 2’s effect on RUNX1 was validated by qRT-PCR and western blot, demonstrating a similar reduction in both RNA and protein. Scratch assay demonstrates functional inhibition of RUNX1 by siRNA-2. ns: not significant, * p < 0.05, *** p < 0.001 ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Table 1. -

Research Article Association Between Programmed Cell Death 6 Interacting Protein Insertion/Deletion Polymorphism and the Risk Of
Research Article Association between Programmed Cell Death 6 Interacting Protein Insertion/Deletion Polymorphism and the Risk of Breast Cancer in a Sample of Iranian Population Mohammad Hashemi,1,2 Javad Yousefi,3 Seyed Mehdi Hashemi,3 Shadi Amininia,2 Mahboubeh Ebrahimi,2 Mohsen Taheri,4 and Saeid Ghavami5,6,7 1 Cellular and Molecular Research Center, Zahedan University of Medical Sciences, Zahedan, Iran 2Department of Clinical Biochemistry, School of Medicine, Zahedan University of Medical Sciences, Zahedan, Iran 3Department of Internal Medicine, School of Medicine, Zahedan University of Medical Sciences, Zahedan, Iran 4Genetic of Non-Communicable Disease Research Center, Zahedan University of Medical Sciences, Zahedan, Iran 5Department of Human Anatomy and Cell Science, College of Medicine, Faculty of Health Sciences, University of Manitoba, Winnipeg,MB,CanadaR3E0J9 6Manitoba Institute of Child Health, University of Manitoba, Winnipeg, MB, Canada R3E 0J9 7Health Policy Research Center, Shiraz University of Medical Sciences, Shiraz, Iran Correspondence should be addressed to Mohammad Hashemi; [email protected] and Saeid Ghavami; [email protected] Received 13 January 2015; Revised 1 April 2015; Accepted 15 April 2015 Academic Editor: Grant Izmirlian Copyright © 2015 Mohammad Hashemi et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. It has been suggested that genetic factors contribute to patients’ vulnerability to breast cancer (BC). The programmed cell death 6 interacting protein (PDCD6IP) encodes for a protein that is known to bind to the products of the PDCD6 gene, which is involved in the apoptosis pathway.