Supplemental Information
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genome Wide Association Study of Response to Interval and Continuous Exercise Training: the Predict‑HIIT Study Camilla J
Williams et al. J Biomed Sci (2021) 28:37 https://doi.org/10.1186/s12929-021-00733-7 RESEARCH Open Access Genome wide association study of response to interval and continuous exercise training: the Predict-HIIT study Camilla J. Williams1†, Zhixiu Li2†, Nicholas Harvey3,4†, Rodney A. Lea4, Brendon J. Gurd5, Jacob T. Bonafglia5, Ioannis Papadimitriou6, Macsue Jacques6, Ilaria Croci1,7,20, Dorthe Stensvold7, Ulrik Wislof1,7, Jenna L. Taylor1, Trishan Gajanand1, Emily R. Cox1, Joyce S. Ramos1,8, Robert G. Fassett1, Jonathan P. Little9, Monique E. Francois9, Christopher M. Hearon Jr10, Satyam Sarma10, Sylvan L. J. E. Janssen10,11, Emeline M. Van Craenenbroeck12, Paul Beckers12, Véronique A. Cornelissen13, Erin J. Howden14, Shelley E. Keating1, Xu Yan6,15, David J. Bishop6,16, Anja Bye7,17, Larisa M. Haupt4, Lyn R. Grifths4, Kevin J. Ashton3, Matthew A. Brown18, Luciana Torquati19, Nir Eynon6 and Jef S. Coombes1* Abstract Background: Low cardiorespiratory ftness (V̇O2peak) is highly associated with chronic disease and mortality from all causes. Whilst exercise training is recommended in health guidelines to improve V̇O2peak, there is considerable inter-individual variability in the V̇O2peak response to the same dose of exercise. Understanding how genetic factors contribute to V̇O2peak training response may improve personalisation of exercise programs. The aim of this study was to identify genetic variants that are associated with the magnitude of V̇O2peak response following exercise training. Methods: Participant change in objectively measured V̇O2peak from 18 diferent interventions was obtained from a multi-centre study (Predict-HIIT). A genome-wide association study was completed (n 507), and a polygenic predictor score (PPS) was developed using alleles from single nucleotide polymorphisms= (SNPs) signifcantly associ- –5 ated (P < 1 10 ) with the magnitude of V̇O2peak response. -

Analysis of Gene Expression Data for Gene Ontology
ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION A Thesis Presented to The Graduate Faculty of The University of Akron In Partial Fulfillment of the Requirements for the Degree Master of Science Robert Daniel Macholan May 2011 ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION Robert Daniel Macholan Thesis Approved: Accepted: _______________________________ _______________________________ Advisor Department Chair Dr. Zhong-Hui Duan Dr. Chien-Chung Chan _______________________________ _______________________________ Committee Member Dean of the College Dr. Chien-Chung Chan Dr. Chand K. Midha _______________________________ _______________________________ Committee Member Dean of the Graduate School Dr. Yingcai Xiao Dr. George R. Newkome _______________________________ Date ii ABSTRACT A tremendous increase in genomic data has encouraged biologists to turn to bioinformatics in order to assist in its interpretation and processing. One of the present challenges that need to be overcome in order to understand this data more completely is the development of a reliable method to accurately predict the function of a protein from its genomic information. This study focuses on developing an effective algorithm for protein function prediction. The algorithm is based on proteins that have similar expression patterns. The similarity of the expression data is determined using a novel measure, the slope matrix. The slope matrix introduces a normalized method for the comparison of expression levels throughout a proteome. The algorithm is tested using real microarray gene expression data. Their functions are characterized using gene ontology annotations. The results of the case study indicate the protein function prediction algorithm developed is comparable to the prediction algorithms that are based on the annotations of homologous proteins. -
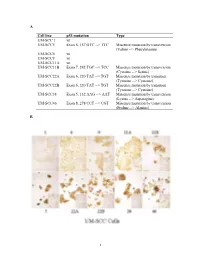
A Cell Line P53 Mutation Type UM
A Cell line p53 mutation Type UM-SCC 1 wt UM-SCC5 Exon 5, 157 GTC --> TTC Missense mutation by transversion (Valine --> Phenylalanine UM-SCC6 wt UM-SCC9 wt UM-SCC11A wt UM-SCC11B Exon 7, 242 TGC --> TCC Missense mutation by transversion (Cysteine --> Serine) UM-SCC22A Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC22B Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC38 Exon 5, 132 AAG --> AAT Missense mutation by transversion (Lysine --> Asparagine) UM-SCC46 Exon 8, 278 CCT --> CGT Missense mutation by transversion (Proline --> Alanine) B 1 Supplementary Methods Cell Lines and Cell Culture A panel of ten established HNSCC cell lines from the University of Michigan series (UM-SCC) was obtained from Dr. T. E. Carey at the University of Michigan, Ann Arbor, MI. The UM-SCC cell lines were derived from eight patients with SCC of the upper aerodigestive tract (supplemental Table 1). Patient age at tumor diagnosis ranged from 37 to 72 years. The cell lines selected were obtained from patients with stage I-IV tumors, distributed among oral, pharyngeal and laryngeal sites. All the patients had aggressive disease, with early recurrence and death within two years of therapy. Cell lines established from single isolates of a patient specimen are designated by a numeric designation, and where isolates from two time points or anatomical sites were obtained, the designation includes an alphabetical suffix (i.e., "A" or "B"). The cell lines were maintained in Eagle's minimal essential media supplemented with 10% fetal bovine serum and penicillin/streptomycin. -

Seq2pathway Vignette
seq2pathway Vignette Bin Wang, Xinan Holly Yang, Arjun Kinstlick May 19, 2021 Contents 1 Abstract 1 2 Package Installation 2 3 runseq2pathway 2 4 Two main functions 3 4.1 seq2gene . .3 4.1.1 seq2gene flowchart . .3 4.1.2 runseq2gene inputs/parameters . .5 4.1.3 runseq2gene outputs . .8 4.2 gene2pathway . 10 4.2.1 gene2pathway flowchart . 11 4.2.2 gene2pathway test inputs/parameters . 11 4.2.3 gene2pathway test outputs . 12 5 Examples 13 5.1 ChIP-seq data analysis . 13 5.1.1 Map ChIP-seq enriched peaks to genes using runseq2gene .................... 13 5.1.2 Discover enriched GO terms using gene2pathway_test with gene scores . 15 5.1.3 Discover enriched GO terms using Fisher's Exact test without gene scores . 17 5.1.4 Add description for genes . 20 5.2 RNA-seq data analysis . 20 6 R environment session 23 1 Abstract Seq2pathway is a novel computational tool to analyze functional gene-sets (including signaling pathways) using variable next-generation sequencing data[1]. Integral to this tool are the \seq2gene" and \gene2pathway" components in series that infer a quantitative pathway-level profile for each sample. The seq2gene function assigns phenotype-associated significance of genomic regions to gene-level scores, where the significance could be p-values of SNPs or point mutations, protein-binding affinity, or transcriptional expression level. The seq2gene function has the feasibility to assign non-exon regions to a range of neighboring genes besides the nearest one, thus facilitating the study of functional non-coding elements[2]. Then the gene2pathway summarizes gene-level measurements to pathway-level scores, comparing the quantity of significance for gene members within a pathway with those outside a pathway. -

GCAT|Panel, a Comprehensive Structural Variant Haplotype Map of the Iberian Population from High-Coverage Whole-Genome Sequencing
bioRxiv preprint doi: https://doi.org/10.1101/2021.07.20.453041; this version posted July 21, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. GCAT|Panel, a comprehensive structural variant haplotype map of the Iberian population from high-coverage whole-genome sequencing Jordi Valls-Margarit1,#, Iván Galván-Femenía2,3,#, Daniel Matías-Sánchez1,#, Natalia Blay2, Montserrat Puiggròs1, Anna Carreras2, Cecilia Salvoro1, Beatriz Cortés2, Ramon Amela1, Xavier Farre2, Jon Lerga- Jaso4, Marta Puig4, Jose Francisco Sánchez-Herrero5, Victor Moreno6,7,8,9, Manuel Perucho10,11, Lauro Sumoy5, Lluís Armengol12, Olivier Delaneau13,14, Mario Cáceres4,15, Rafael de Cid2,*,† & David Torrents1,15,* 1. Life sciences dept, Barcelona Supercomputing Center (BSC), Barcelona, 08034, Spain. 2. Genomes for Life-GCAT lab Group, Institute for Health Science Research Germans Trias i Pujol (IGTP), Badalona, 08916, Spain. 3. Institute for Research in Biomedicine (IRB Barcelona), The Barcelona Institute of Science and Technology, 08028, Barcelona, Spain (current affiliation). 4. Institut de Biotecnologia i de Biomedicina, Universitat Autònoma de Barcelona, Bellaterra, Barcelona, 08193, Spain. 5. High Content Genomics and Bioinformatics Unit, Institute for Health Science Research Germans Trias i Pujol (IGTP), 08916, Badalona, Spain. 6. Catalan Institute of Oncology, Hospitalet del Llobregat, 08908, Spain. 7. Bellvitge Biomedical Research Institute (IDIBELL), Hospitalet del Llobregat, 08908, Spain. 8. CIBER Epidemiología y Salud Pública (CIBERESP), Madrid, 28029, Spain. 9. Universitat de Barcelona (UB), Barcelona, 08007, Spain. -

Supplementary Table 3 Complete List of RNA-Sequencing Analysis of Gene Expression Changed by ≥ Tenfold Between Xenograft and Cells Cultured in 10%O2
Supplementary Table 3 Complete list of RNA-Sequencing analysis of gene expression changed by ≥ tenfold between xenograft and cells cultured in 10%O2 Expr Log2 Ratio Symbol Entrez Gene Name (culture/xenograft) -7.182 PGM5 phosphoglucomutase 5 -6.883 GPBAR1 G protein-coupled bile acid receptor 1 -6.683 CPVL carboxypeptidase, vitellogenic like -6.398 MTMR9LP myotubularin related protein 9-like, pseudogene -6.131 SCN7A sodium voltage-gated channel alpha subunit 7 -6.115 POPDC2 popeye domain containing 2 -6.014 LGI1 leucine rich glioma inactivated 1 -5.86 SCN1A sodium voltage-gated channel alpha subunit 1 -5.713 C6 complement C6 -5.365 ANGPTL1 angiopoietin like 1 -5.327 TNN tenascin N -5.228 DHRS2 dehydrogenase/reductase 2 leucine rich repeat and fibronectin type III domain -5.115 LRFN2 containing 2 -5.076 FOXO6 forkhead box O6 -5.035 ETNPPL ethanolamine-phosphate phospho-lyase -4.993 MYO15A myosin XVA -4.972 IGF1 insulin like growth factor 1 -4.956 DLG2 discs large MAGUK scaffold protein 2 -4.86 SCML4 sex comb on midleg like 4 (Drosophila) Src homology 2 domain containing transforming -4.816 SHD protein D -4.764 PLP1 proteolipid protein 1 -4.764 TSPAN32 tetraspanin 32 -4.713 N4BP3 NEDD4 binding protein 3 -4.705 MYOC myocilin -4.646 CLEC3B C-type lectin domain family 3 member B -4.646 C7 complement C7 -4.62 TGM2 transglutaminase 2 -4.562 COL9A1 collagen type IX alpha 1 chain -4.55 SOSTDC1 sclerostin domain containing 1 -4.55 OGN osteoglycin -4.505 DAPL1 death associated protein like 1 -4.491 C10orf105 chromosome 10 open reading frame 105 -4.491 -

Molecular Profiling of Peripheral Blood Is Associated with Circulating Tumor Cells Content and Poor Survival in Metastatic Castration-Resistant Prostate Cancer
www.impactjournals.com/oncotarget/ Oncotarget, Vol. 6, No. 12 Molecular profiling of peripheral blood is associated with circulating tumor cells content and poor survival in metastatic castration-resistant prostate cancer Mercedes Marín-Aguilera1, Òscar Reig1,2, Juan José Lozano3, Natalia Jiménez1, Susana García-Recio1,4, Nadina Erill5, Lydia Gaba2, Andrea Tagliapietra2, Vanesa Ortega2, Gemma Carrera6, Anna Colomer5, Pedro Gascón4 and Begoña Mellado1,2 1 Translational Genomics Group and Targeted Therapeutics in Solid Tumors Group, Institut d’Investigacions Biomèdiques August Pi i Sunyer (IDIBAPS), Barcelona, Spain 2 Medical Oncology Department, Hospital Clínic, Barcelona, Spain 3 Bioinformatics Platform Department, Centro de Investigación Biomédica en Red en el Área temática de Enfermedades Hepáticas y Digestivas (CIBEREHD), Hospital Clínic, Barcelona, Spain 4 Laboratory of Translational Oncology, Fundació Clínic per a la Recerca Biomèdica, Barcelona, Spain 5 Althia, Barcelona, Spain 6 Medical Oncology Department, Hospital Plató, Barcelona, Spain Correspondence to: Begoña Mellado, email: [email protected] Keywords: circulating tumor cells, peripheral blood, microarrays, cell search system Received: January 22, 2015 Accepted: February 14, 2015 Published: March 12, 2015 This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. ABSTRACT The enumeration of circulating -

Gene Prioritization in Type 2 Diabetes Using Domain Interactions And
Sharma et al. BMC Genomics 2010, 11:84 http://www.biomedcentral.com/1471-2164/11/84 RESEARCH ARTICLE Open Access Gene prioritization in Type 2 Diabetes using domain interactions and network analysis Amitabh Sharma1†, Sreenivas Chavali1†, Rubina Tabassum1, Nikhil Tandon2, Dwaipayan Bharadwaj1* Abstract Background: Identification of disease genes for Type 2 Diabetes (T2D) by traditional methods has yielded limited success. Based on our previous observation that T2D may result from disturbed protein-protein interactions affected through disrupting modular domain interactions, here we have designed an approach to rank the candidates in the T2D linked genomic regions as plausible disease genes. Results: Our approach integrates Weight value (Wv) method followed by prioritization using clustering coefficients derived from domain interaction network. Wv for each candidate is calculated based on the assumption that disease genes might be functionally related, mainly facilitated by interactions among domains of the interacting proteins. The benchmarking using a test dataset comprising of both known T2D genes and non-T2D genes revealed that Wv method had a sensitivity and specificity of 0.74 and 0.96 respectively with 9 fold enrichment. The candidate genes having a Wv > 0.5 were called High Weight Elements (HWEs). Further, we ranked HWEs by using the network property-the clustering coefficient (Ci). Each HWE with a Ci < 0.015 was prioritized as plausible disease candidates (HWEc) as previous studies indicate that disease genes tend to avoid dense clustering (with an average Ci of 0.015). This method further prioritized the identified disease genes with a sensitivity of 0.32 and a specificity of 0.98 and enriched the candidate list by 6.8 fold. -

HIC1 Modulates Prostate Cancer Progression by Epigenetic Modification
Author Manuscript Published OnlineFirst on January 22, 2013; DOI: 10.1158/1078-0432.CCR-12-2888 Author manuscripts have been peer reviewed and accepted for publication but have not yet been edited. HIC1 modulates prostate cancer progression by epigenetic modification Jianghua Zheng#1, 2, Jinglong Wang#1, Xueqing Sun#1,Mingang Hao1,Tao Ding3, Dan Xiong 1, Xiumin Wang1, Yu Zhu 4, Gang Xiao 1, Guangcun Cheng1, Meizhong Zhao5, Jian Zhang6, Jianhua Wang1* 1 Department of Biochemistry and Molecular Cell Biology, Shanghai Jiao Tong University School of Medicine, Shanghai, 200025, China. 2 Shanghai Public Health Clinical Center, Fudan University, Shanghai, 201508, China. 3 Department of Urology, Shanghai Putuo Hospital, Shanghai Traditional Chinese Medicine University, Shanghai, 200062, China. 4 Department of Urology, Shanghai Ruijin Hospital, Shanghai, 200025, China. 5 Shanghai Ruijin Hospital, Comprehensive Breast Health Center, Shanghai, 200025, China. 6 Guangxi Medical University, Nanning, 530021, China. # J Zheng, J Wang and X Sun contributed equally to this work. *Corresponding author: Jianhua Wang, PhD, Shanghai Jiao Tong University School of Medicine, Shanghai, 200025, China. Phone: 021-54660871; Fax: 021-63842157; E-mail:[email protected]. No potential conflicts of interest were disclosed 1 Downloaded from clincancerres.aacrjournals.org on October 1, 2021. © 2013 American Association for Cancer Research. Author Manuscript Published OnlineFirst on January 22, 2013; DOI: 10.1158/1078-0432.CCR-12-2888 Author manuscripts have been peer reviewed and accepted for publication but have not yet been edited. Statement of Translational Relevance This study aimed to further our understanding of the role that hypermethylatioted in cancer 1 (HIC1) plays in prostate cancer (PCa) progression. -

Methods in and Applications of the Sequencing of Short Non-Coding Rnas" (2013)
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations 2013 Methods in and Applications of the Sequencing of Short Non- Coding RNAs Paul Ryvkin University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the Bioinformatics Commons, Genetics Commons, and the Molecular Biology Commons Recommended Citation Ryvkin, Paul, "Methods in and Applications of the Sequencing of Short Non-Coding RNAs" (2013). Publicly Accessible Penn Dissertations. 922. https://repository.upenn.edu/edissertations/922 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/922 For more information, please contact [email protected]. Methods in and Applications of the Sequencing of Short Non-Coding RNAs Abstract Short non-coding RNAs are important for all domains of life. With the advent of modern molecular biology their applicability to medicine has become apparent in settings ranging from diagonistic biomarkers to therapeutics and fields angingr from oncology to neurology. In addition, a critical, recent technological development is high-throughput sequencing of nucleic acids. The convergence of modern biotechnology with developments in RNA biology presents opportunities in both basic research and medical settings. Here I present two novel methods for leveraging high-throughput sequencing in the study of short non- coding RNAs, as well as a study in which they are applied to Alzheimer's Disease (AD). The computational methods presented here include High-throughput Annotation of Modified Ribonucleotides (HAMR), which enables researchers to detect post-transcriptional covalent modifications ot RNAs in a high-throughput manner. In addition, I describe Classification of RNAs by Analysis of Length (CoRAL), a computational method that allows researchers to characterize the pathways responsible for short non-coding RNA biogenesis. -

Co-Occurrence Based Meta-Analysis of Scientific Texts
Vol. 21 no. 9 2005, pages 2049–2058 BIOINFORMATICS ORIGINAL PAPER doi:10.1093/bioinformatics/bti268 Data and text mining Co-occurrence based meta-analysis of scientific texts: retrieving biological relationships between genes R. Jelier1,∗ G. Jenster2, L. C. J. Dorssers3, C. C. van der Eijk1, E. M. van Mulligen1, B. Mons1 and J. A. Kors1 1Department of Medical Informatics, 2Department of Urology and 3Department of Pathology, Erasmus MC—University Medical Center, Rotterdam, The Netherlands Received on July 15, 2004; revised on December 22, 2004; accepted on January 6, 2005 Advance Access publication January 18, 2005 ABSTRACT are studied, the number of relevant publications will frequently be Motivation: The advent of high-throughput experiments in molecu- prohibitively large. This renders the traditional approach of manu- lar biology creates a need for methods to efficiently extract and use ally searching bibliographic databases for every gene and reading information for large numbers of genes. Recently, the associative scientific articles inadequate. It is therefore an important challenge concept space (ACS) has been developed for the representation of at this time to make the available information both accessible and information extracted from biomedical literature. The ACS is a Euc- interpretable for molecular biologists. lidean space in which thesaurus concepts are positioned and the An interesting current development is the use of annotations of distances between concepts indicates their relatedness. The ACS genes with gene ontology (GO) terms (Ashburner et al., 2000; Camon uses co-occurrence of concepts as a source of information. In this et al., 2004) for the analysis of the results of microarray experiments paper we evaluate how well the system can retrieve functionally (Zhang et al., 2004; Al Shahrour et al., 2004). -

MYC-Containing Amplicons in Acute Myeloid Leukemia: Genomic Structures, Evolution, and Transcriptional Consequences
Leukemia (2018) 32:2152–2166 https://doi.org/10.1038/s41375-018-0033-0 ARTICLE Acute myeloid leukemia Corrected: Correction MYC-containing amplicons in acute myeloid leukemia: genomic structures, evolution, and transcriptional consequences 1 1 2 2 1 Alberto L’Abbate ● Doron Tolomeo ● Ingrid Cifola ● Marco Severgnini ● Antonella Turchiano ● 3 3 1 1 1 Bartolomeo Augello ● Gabriella Squeo ● Pietro D’Addabbo ● Debora Traversa ● Giulia Daniele ● 1 1 3 3 4 Angelo Lonoce ● Mariella Pafundi ● Massimo Carella ● Orazio Palumbo ● Anna Dolnik ● 5 5 6 2 7 Dominique Muehlematter ● Jacqueline Schoumans ● Nadine Van Roy ● Gianluca De Bellis ● Giovanni Martinelli ● 3 4 8 1 Giuseppe Merla ● Lars Bullinger ● Claudia Haferlach ● Clelia Tiziana Storlazzi Received: 4 August 2017 / Revised: 27 October 2017 / Accepted: 13 November 2017 / Published online: 22 February 2018 © The Author(s) 2018. This article is published with open access Abstract Double minutes (dmin), homogeneously staining regions, and ring chromosomes are vehicles of gene amplification in cancer. The underlying mechanism leading to their formation as well as their structure and function in acute myeloid leukemia (AML) remain mysterious. We combined a range of high-resolution genomic methods to investigate the architecture and expression pattern of amplicons involving chromosome band 8q24 in 23 cases of AML (AML-amp). This 1234567890();,: revealed that different MYC-dmin architectures can coexist within the same leukemic cell population, indicating a step-wise evolution rather than a single event origin, such as through chromothripsis. This was supported also by the analysis of the chromothripsis criteria, that poorly matched the model in our samples. Furthermore, we found that dmin could evolve toward ring chromosomes stabilized by neocentromeres.