Experimental Studies on Web, Music and Blog Interfaces
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Open Source Basierte Virtuelle Forschungsumgebungen Für Projekte in Der Ökologischen Langzeitforschung
Open Source basierte Virtuelle Forschungsumgebungen für Projekte in der ökologischen Langzeitforschung Das „Rapid L-TER VRE“ Baukastenkonzept zur schnellen und nachhaltigen Realisierung Von der Fakultät für Umwelt und Naturwissenschaften der Brandenburgischen Techni- schen Universität Cottbus – Senftenberg zur Erlangung des akademischen Grades eines Doktors der Ingenieurwissenschaften genehmigte Dissertation vorgelegt von Diplom-Umweltingenieur Mirko Filetti aus Offenbach, am Main (Hessen) Gutachter: apl. Prof. Dr.-Ing. habil. Frank Molkenthin Gutachter: Prof. Dr. rer. nat. habil. Albrecht Gnauck Gutachter: Prof. Dr. rer. nat. habil. Gerhard Wiegleb Tag der mündlichen Prüfung: 28.06.2018 Kurzfassung Virtuelle Forschungsumgebungen (engl. virtual research environments, im Folgenden als VRE bezeichnet), sind nach allgemeinem Verständnis Plattformen auf Basis von Informations- und Kommunikationstechnologien (engl. ICT) mit ganzheitlichem Ansatz, die das wissenschaftliche Arbeiten im Team und insbesondere dessen Kommunikation und Organisation unterstützen sollen. Sie haben zum Ziel, schneller und besser zu nachvollziehbaren Ergebnissen zu gelangen und Wissen persistent verfügbar zu machen. Derzeit existiert jedoch kein VRE-Software- Framework, das „out-of-the-box“ sofort einsatzfähig oder für alle Anforderungen geeignet wäre („one size fit them all“). Projekte in der ökologischen Langzeitforschung (engl. long-term ecological research, im Folgenden als L-TER bezeichnet) sind durch den Langzeitaspekt und Raumbezug in der Regel umfangreiche Projekte -

Appendix a the Ten Commandments for Websites
Appendix A The Ten Commandments for Websites Welcome to the appendixes! At this stage in your learning, you should have all the basic skills you require to build a high-quality website with insightful consideration given to aspects such as accessibility, search engine optimization, usability, and all the other concepts that web designers and developers think about on a daily basis. Hopefully with all the different elements covered in this book, you now have a solid understanding as to what goes into building a website (much more than code!). The main thing you should take from this book is that you don’t need to be an expert at everything but ensuring that you take the time to notice what’s out there and deciding what will best help your site are among the most important elements of the process. As you leave this book and go on to updating your website over time and perhaps learning new skills, always remember to be brave, take risks (through trial and error), and never feel that things are getting too hard. If you choose to learn skills that were only briefly mentioned in this book, like scripting, or to get involved in using content management systems and web software, go at a pace that you feel comfortable with. With that in mind, let’s go over the 10 most important messages I would personally recommend. After that, I’ll give you some useful resources like important websites for people learning to create for the Internet and handy software. Advice is something many professional designers and developers give out in spades after learning some harsh lessons from what their own bitter experiences. -
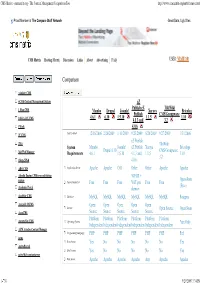
CMS Matrix - Cmsmatrix.Org - the Content Management Comparison Tool
CMS Matrix - cmsmatrix.org - The Content Management Comparison Tool http://www.cmsmatrix.org/matrix/cms-matrix Proud Member of The Compare Stuff Network Great Data, Ugly Sites CMS Matrix Hosting Matrix Discussion Links About Advertising FAQ USER: VISITOR Compare Search Return to Matrix Comparison <sitekit> CMS +CMS Content Management System eZ Publish eZ TikiWiki 1 Man CMS Mambo Drupal Joomla! Xaraya Bricolage Publish CMS/Groupware 4.6.1 6.10 1.5.10 1.1.5 1.10 1024 AJAX CMS 4.1.3 and 3.2 1Work 4.0.6 2F CMS Last Updated 12/16/2006 2/26/2009 1/11/2009 9/23/2009 8/20/2009 9/27/2009 1/31/2006 eZ Publish 2flex TikiWiki System Mambo Joomla! eZ Publish Xaraya Bricolage Drupal 6.10 CMS/Groupware 360 Web Manager Requirements 4.6.1 1.5.10 4.1.3 and 1.1.5 1.10 3.2 4Steps2Web 4.0.6 ABO.CMS Application Server Apache Apache CGI Other Other Apache Apache Absolut Engine CMS/news publishing 30EUR + system Open-Source Approximate Cost Free Free Free VAT per Free Free (Free) Academic Portal domain AccelSite CMS Database MySQL MySQL MySQL MySQL MySQL MySQL Postgres Accessify WCMS Open Open Open Open Open License Open Source Open Source AccuCMS Source Source Source Source Source Platform Platform Platform Platform Platform Platform Accura Site CMS Operating System *nix Only Independent Independent Independent Independent Independent Independent ACM Ariadne Content Manager Programming Language PHP PHP PHP PHP PHP PHP Perl acms Root Access Yes No No No No No Yes ActivePortail Shell Access Yes No No No No No Yes activeWeb contentserver Web Server Apache Apache -

Towards an Open Source E-Governance Solution
Technical University of Vienna Towards an Open Source Information Systems Institute e-Governance Solution Distributed Systems Group Benjamin A. Schmit, Nima Heschmat, Schahram Dustdar, Gernot Muller¨ and Jeremy Solarz [email protected] [email protected] [email protected] [email protected] jeremy [email protected] TUV-1841-2006-39 May 17, 2006 Electronic Governance is becoming a more and more important topic in legislative bodies worldwide. In this paper, we present the architecture of an open toolsuite developed for the European Union project MetaLoGo, which aims to support Latin American municipalities with e-governance solutions. It has been developed using only open source components and is fully available under an open source license. The core components are a content management system providing the Web portal, a workflow man- agement system handling administrative processes, and a customer rela- tionship management system. The toolsuite can be deployed on outdated hardware as well and does not impose any license costs. Keywords: e-governance, content management, workflow management Argentinierstr. 8/184-1 A-1040 Vienna, Austria phone: +43 1 58801-18402 c 2006, Distributed Systems Group, Technical University of Vienna fax: +43 1 58801-18491 URL: http://www.infosys.tuwien.ac.at/ Towards an Open Source e-Governance Solution Benjamin A. Schmit, Nima Heschmat, Schahram Dustdar, Gernot M¨uller, Jeremy Solarz Vienna University of Technology Information Systems Institute Distributed Systems Group Vienna, Austria, Europe Abstract Electronic Governance is becoming a more and more important topic in legislative bodies worldwide. In this paper, we present the architecture of an open toolsuite developed for the European Union project MetaLoGo, which aims to support Latin American municipalities with e-governance solutions. -

Joomla / Mambo Community Builder
Joomla / Mambo Community Builder Version 1.9.1 Detailed Guide Software Version 1.9.1 Document Version 1.9.1 version 1 [020] Revision date 06.November.2013 Author Nick A. [email protected] Copyright No portion of this document may be reproduced or re- distributed without the consent of the author. Community Builder 1.9.1 Project Team The Community Builder project is an Open Source project supported by the following CB Core Team members: Community Builder Core Team Membership Name Username Role JoomlaJoe Joomlajoe Lead Developer, Founder Beat B. Beat Lead Developer Nick A. Nant Documentation, Public Relations, JP co-admin Kyle L. Krileon Forums, Developer • The official home of the Community Builder project is located at www.joomlapolis.com Document Distribution The CB Team has decided to offer this documentation on a subscription basis. The reason is to gather some expense money to be used against hosting costs, development tools, libraries, third party service, etc. Page 2 of 170 Community Builder 1.9.1 Table of Contents 1 Introduction .......................................................................................................... 10 1.1 What’s it all about .......................................................................................... 10 1.2 Document Outline .......................................................................................... 12 1.3 Acknowledgements, Credits and Copyrights ................................................. 13 1.4 CMS Compatibility Prerequisites .................................................................. -

Process Innovations for Security Vulnerability Prevention in Open Source Web Applications
Process Innovations For Security Vulnerability Prevention In Open Source Web Applications Diploma Thesis Florian Thiel April 30, 2009 Department of Mathematics and Computer Science Institute for Computer Science Software Engineering Working Group Responsible University Professor: Prof. Dr. Lutz Prechelt Supervisor: Dipl.-Medieninf. Martin Gruhn This work is licensed under the Creative Commons Attribution 3.0 Germany License. To view a copy of this license, visit http://creativecommons.org/licenses/by/3.0/de/ or send a letter to Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA. Please note: Pictures in this work are not licensed under a Creative Commons Attribution license and may not be copied as freely as the rest of this work. Comic strips in this work are by Randall Munroe of xkcd and licensed under a Creative Commons Attribution-NonCommercial 2.5 license. The picture on the title page is by Matteo Carli and licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 2.0 license. It is available at http://www.flickr.com/photos/matteocarli/2489736887/. Affirmation Of Independent Work I hereby declare that I wrote this thesis myself without sources other than those indicated herein. All parts taken from published and unpublished scripts are indicated as such. Berlin, April 30, 2009 ii Acknowledgments First of all, I would like to thank Professor Lutz Prechelt who suggested and supported the topic of this thesis and enabled me to spend months of interesting research in the fascinating world of security research. I also owe a lot to Martin Gruhn, my supervisor, who provided lots of feedback and was especially helpful to flesh out the argumentation and create a good narrative. -

PLA 2012 Virtual Conference If You Can’T Make It to Philadelphia This March, You Don’T Have to Miss Out
Preliminary Program www.placonference.org Photo by B. Krist for GPTMC Thank you! PLA thanks the members of the 2012 Conference Committees. Without the hard work of such dedicated professionals, much of what we do would not be possible. PLa 2012 Conference Committee Karen Danczak Lyons, first deputy commissioner, Chicago Take a look inside and see the exciting lineup of educational Public Library (Chair) and entertaining programming heading to Philadelphia this March. I hope you will join me and your colleagues from around PLa 2012 Conference Program Committee the world at the premier event for public library professionals— Sara Dallas, director, Southern Adirondack (N.Y.) Library System PLA 2012. (Chair) PLa 2012 Conference Local arrangements Committee Siobhan Reardon, president and director, Philadelphia Free Library (Chair) Marcia Warner 2011-2012 PLA President For a complete list of PLA 2012 Conference Committee members Director, Grand Rapids (Mich.) Public Library visit www.placonference.org PLA 2012 VirtuAL ConferenCe If you can’t make it to Philadelphia this March, you don’t have to miss out. Attend the PLA 2012 Virtual Conference, March 15-16, instead. Ten top PLA 2012 presenters will repeat their programs live for Virtual Conference attendees. Experience programs, author interviews, networking opportunities, and more—all from the comfort of your computer. Registration for the PLA 2012 Virtual Conference opens in December. Individuals who register for the onsite conference will receive access to the Virtual Conference as part of their registration. 2 Public Library Association • (800) 545-2433 x5PLA SCHeDuLe Photo by B. Krist for GPTMC PLa 2012 SCheduLe-aT-a-GLanCe Tuesday, March 13 9:30 a.m.–4:00 p.m. -

ED431279.Pdf
DOCUMENT RESUME ED 431 279 EC 307 261 TITLE Research Exchange. Quarterly Newsletter of the National Center for the Dissemination of Disability Research (NCDDR). INSTITUTION Southwest Educational Development Lab., Austin, TX. SPONS AGENCY National Inst. on Disability and Rehabilitation Research (ED/OSERS), Washington, DC. PUB DATE 1998-00-00 NOTE 149p. CONTRACT H133D50016 AVAILABLE FROM Available in electronic format on the internet at Web site: http://www.ncddr.org/ PUB TYPE Collected Works - Serials (022) JOURNAL CIT Research Exchange; v1-3 1996-1998 EDRS PRICE MF01/PC06 Plus Postage. DESCRIPTORS Accessibility (for Disabled); *Disabilities; Evaluation Methods; Federal Programs; Grants; *Information Dissemination; *Research and Development; Self Evaluation (Groups); *Theory Practice Relationship IDENTIFIERS *National Center for the Dissem of Disabil Research; National Institute on Disability Rehab Research ABSTRACT These twelve issues (3 years) of the newsletter of the National Center for the Dissemination of Disability Research (NCDDR) present articles summarizing outcomes of National Institute on Disability and Rehabilitation Research (NIDRR) research projects. Articles from Volume 1 include: "What Are the True Outcomes of Research"; "Self Assessment Fosters Dissemination"; "User-Friendly Materials Facilitate Communication"; "Technical Assistance and Training Available for Grantees"; "Strategies for Underserved Groups"; "Availability versus Accessibility"; "Alternate Formats and Accessibility"; "Do You Have a Dissemination Policy?"; -

Bibliography on Racism
BIBLIOGRAPHY ON RACISM Teun A. van Dijk Version 1.0, May 31, 2007 Aarim-Heriot, N. (2003). Chinese immigrants, African Americans, and racial anxiety in the United States, 1848-82. Urbana: University of Illinois Press. AARP (Organization) , Leadership Conference on Civil Rights., & Library of Congress. (2004). Voices of civil rights. Ordinary people, extraordinary stories.. Washington, D.C.: AARP. Abad Márquez, L. V., Cucó, A., & Izquierdo Escribano, A. (1993). Inmigración, pluralismo y tolerancia. Madrid: Popular. Abanes, R. (1996). American militias. Rebellion, racism & religion. Downers Grove, Ill.: InterVarsity Press. Abanime, E. P. (1986). Ideologies of Race and Sex in Literature: Racism and Antiracism in the African Francophone Novel. College Language Association Journal, 30(2), 125-143. Abbattista, G., & Imbruglia, G. (1992). Il razzismo e le sue storie. Napoli: Edizioni scientifiche italiane. Abbattista, G., Imbruglia, G., Associazione Sigismondo Malatesta., & Convegni malatestiani sul razzismo e le sue storie (1992). Il razzismo e le sue storie. Napoli: Edizioni scientifiche italiane. Abbott, S. (1971). The prevention of racial discrimination in Britain. London New York: published for the United Nations Institute for Training and the Institute of Race Relations by Oxford U.P. Abd Allah, G. (2000). Waqa i al-yawm al-dirasi al-khass bi-al-manahij al-tarbawiyah al-ta limiyah al-Filastiniyah wa-al-Isra iliyah. al-Quds: Markaz al-Dirasat wa-al-Tatbiqat al- Tarbawiyah. Abdel-Shehid, G. (2005). Who da man? Black masculinities and sporting cultures. Toronto: Canadian Scholars' Press. Abdelaziz, T. (1987). Je, femme d'immigré. Paris: Editions du Cerf. Abdelkhalek, O. (1993). Maghrebins victimes du racisme en France, 1980-1989. -

Society of American Archivists Council Meeting August 25, 2008 San Francisco, California
Agenda Item II.O. Society of American Archivists Council Meeting August 25, 2008 San Francisco, California Report: Website Working Group (Prepared by Brian Doyle, Chair) WORKING GROUP MEMBERS Brian Doyle, Chair Gregory Colati Christine Di Bella Chatham Ewing Jeanne Kramer-Smyth Mark Matienzo Aprille McKay Christopher Prom Seth Shaw Bruce Ambacher, Council Liaison BACKGROUND For several years, there has been a keen and growing interest among SAA’s members in the deployment of a robust content management system (CMS) featuring state-of-the-art Web 2.0 applications—wikis, blogs, RSS feeds, etc. While these types of programs are often associated with social networking, a comprehensive CMS would also redress a number of important organizational challenges that SAA faces: • How can SAA’s component groups (e.g., boards, committees, task forces, etc.) collaborate more effectively in an online environment? • How can official documents (e.g., minutes, reports, newsletters, etc.) be more easily published to the Web by SAA’s component groups, described and accessed via appropriate metadata, and scheduled for retention? • How can SAA enhance its online publishing capabilities and ensure that the necessary tools are available for authorized subject experts to edit and update such official electronic publications as Richard Pearce-Moses’ Glossary of Archival and Records Management Terminology , DACS Online, and the EAD Help Pages, as well as such important resources as an SAA standards portal or the Technology Best Practices Task Force working document? Report: Website Working Group Page 1 of 17 0808-1-WebWG-IIO SAA’s existing Web technology does not adequately fulfill these needs. -

Fall 2013 Catalog by 39 • S
College of Technology WORKFORCE TRAINING FALL CONTINUING 2013 EDUCATION Non-Credit Courses • Web-Based Courses • Evening Courses To enroll, visit our website at cetrain.isu.edu or call (208) 282-3372 2 C ONTINUING FREE, quick job-site safety training is available for E DUCATION general categories like heat Free and cold stress and confined spaces. / W There is industry-specific ORKFORCE Safety training for farm, construction and manufacturing safety. T Take 10 minutes to have your RAINING • C crew watch one of these Training specific, mobile trainings. Did we mention it’s free? ALL (208) 282-3372 F OR C LASS I NFORMATION For online safety courses, visit us at: cetrain.isu.edu/online On-line and Web Supplemented Fall Classes Basic EKG Interpretation .......................................18 CNA (Web Supplemented).....................................28 Agriculture Health Healthcare Online Education (ad) .........................24 Riding Instruction I .................................................5 Assistance with Medications ..................................26 Medication Math ...................................................18 Riding Instruction II ................................................5 Basic EKG Interpretation .......................................18 OSHA Bloodborne Pathogens................................18 Riding Instruction III ..............................................5 Basic First Aid .......................................................19 Home Landscape Care Basics ..................................6 Certificated -

2006 05 25 Internet Do's and Dont's 1.31
Patient Support Websites: Do's and Dont's Development Guideline to set up a website for patient support groups Table of Contents 1 The challenge setting up patient support web sites .................................................................... 2 2 The Do's and Dont's..................................................................................................................... 2 2.1 Set and state goals of your website..................................................................................... 2 2.2 Set general design before starting implementation............................................................. 3 2.3 Follow established design guidelines of the web ................................................................ 5 2.4 Provide Disclaimers............................................................................................................. 8 2.5 Provide and moderate discussion forums........................................................................... 8 2.6 Provide a print function ........................................................................................................ 9 2.7 Provide a search function .................................................................................................... 9 3 How to set up an affordable patient support site easily .............................................................. 9 3.1 PostNuke............................................................................................................................ 10 3.2 Typo3 ................................................................................................................................