Phd Dissertation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2-10 Conferences
2nd Conference to 10th Conference Second TANA Conference (Detroit 1979) Tummala Madhava Rao Kakarla Subba Rao - President Souvenir Editorial Co-ordinators Famous artist Puranam Subrahmanya Sarma Nanduri Rammohana Rao S.V. Rama Rao Prof. C.R.Rao P.V. Narasimharao Akkineni Nageswara Rao P.V. Narasimharao Dasaradhi Rangacharya Prabhakar Kakarala Ramoji Rao Committee Chairman Raghavendra Prasad Avula Sambaiva Rao Veeragandham Subbarao, with Lakshmi Parvathi Left to right Bandla Hanumaiah, Madhavarao Tummala, Tirupataiah Tella, Satyanarayana Nallamothu, Gangadhar Nadell, Prabhakar Kakarala, Chandrasekhara rao Kakarala Third TANA Conference (Chicago 1981) Conference Venue - Oak Park and River Forest High School Tella Tirupatiah Tummala Madhava Rao RavindranathGuttikonda Tirupataiah tella,r k , Tella Tirupathaiah Tummala Madhava Rao Narayanganj Bhatnagar M. Baga Reddy C. Narayana Reddy with Tirupathaiah right last Nallamotu Satyanarayana in the middle Mullapudi Harischandra Guttikonda Ravindranath, Padma Prasad Nadella Bhaskar NTR with Tirupathaiah Ramoji Rao, Nadella Bhaskar Tirupathaiah Tella, Narayanganj Saluri Rajeswara Rao Sri Sri Yadlapati Venkata Rao Fourth TANA Conference (Washington DC 1983) Venue of the Conference Chennareddy Tella Titupataiah S.V.Rao Art committee Chairman Jakkampudi Subbaraidu convenor from left 3rd N.G. Ranga, Guttikonda Ravidranath Fifth TANA Conference (Los Angeles 1985) Long Beach Convention Long Beach Convention Center Raghavendra Prasad Potturi Venkateswara Upendra Vasantha Nageswara Rao Mandapaka Sarada Sobhanaidu -
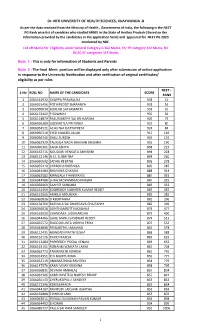
The NEET PG Rank Wise List of Canidates Who Studied MBBS In
Dr. NTR UNIVERSITY OF HEALTH SCIENCES, VIJAYAWADA -8 As per the data received from the Ministry of Health , Government of India, the following is the NEET PG Rank wise list of canidates who studied MBBS in the State of Andhra Pradesh ( Based on the information provided by the candidates in the application form) and appeared for NEET PG 2020 conducted by NBE. Cut off Marks for Eligibility under General Category is 366 Marks, For PH category 342 Marks, for BC,SC,ST categories 319 Marks Note 1 : This is only for information of Students and Parents Note 2 : The final Merit position will be displayed only after submission of online application in response to the University Notification and after verification of original certificates/ eligibility as per rules NEET - S.No ROLL NO NAME OF THE CANDIDATE SCORE RANK 1 2066161932 CHAPPA PRAVALLIKA 938 41 2 2066015456 POTHIREDDY SHARANYA 931 56 3 2066090034 KOULALI SAI SAMARTH 931 61 4 2066153442 P SOWMYA 930 66 5 2066114879 PASUMARTHY SAI SRI HARSHA 926 79 6 2066056289 GUDIMETLA PRIYANKA 925 80 7 2066054521 ACHUTHA DATTATREYA 924 84 8 2066090718 SYED KHALEELULLAH 910 149 9 2066056746 DALLI SURESH 909 152 10 2066062929 TALASILA NAGA BHAVANI KRISHNA 903 190 11 2066090361 SANA ASFIYA 898 223 12 2066162715 NOUDURI VENKATA ABHISHEK 898 224 13 2066112146 N S L SUSMITHA 894 260 14 2066060592 SADHU KEERTHI 892 278 15 2066055410 CHEBOLU HARSHIKA 890 287 16 2066044484 BHAVANA CHANDA 888 314 17 2066062582 MANGALA THANMAYEE 887 319 18 2066044988 SHAIK MOHAMMAD KHASIM 887 325 19 2066056960 SAAHITI SUNKARA 885 -

Unclaimed Dividend 2011-12 As on 31.12.2018
NCL INDUSTRIES LTD Dividend A/c No - 0133103000006798 LIST OF UNCLAIMED DIVIDEND AS ON 31/12/2018 FOR THE FY 2011-12 S.No. FOLIO MICR AMOUNT WARDATE NAME WARNO 1 000004 14753 200 01-10-2012 S VISWANATHA RAJU 90 2 000008 13861 20 01-10-2012 G.VENKATA DURGA RAJU 124 3 000025 13862 400 01-10-2012 G VISHWANADHA RAJU 263 4 000028 13863 80 01-10-2012 K SAVITRI 279 5 000053 17525 800 01-10-2012 B BHAGAVATHI RAO 411 6 000054 17524 500 01-10-2012 KADA SRINIVASA RAO 415 7 000056 17503 200 01-10-2012 PENTA ANANDA RAO 425 8 000057 17504 480 01-10-2012 PENTA MANMADA RAO 428 9 000058 17505 400 01-10-2012 PENTA VENKATA RAJU 434 10 000059 17446 500 01-10-2012 CHITTORI VENKATA KRISHNA NARASIMHA RAO439 11 000061 17506 200 01-10-2012 PENTA KRISHNA RAO 455 12 000062 17507 200 01-10-2012 PENTA SURYA RAO 464 13 000063 17508 200 01-10-2012 PENTA KAMESHWARA RAO 468 14 000064 17509 200 01-10-2012 PENTA BALARAMA MURTHY 471 15 000067 17864 240 01-10-2012 BONDA NOOKA RAJU 487 16 000070 17865 200 01-10-2012 MAMIDI VARAHA NARASIMHA MURTHY 504 17 000073 17866 600 01-10-2012 PALURI VENKATA RAMANA 520 18 000075 15536 100 01-10-2012 CH CHANDRA REDDY 530 19 000078 17268 60 01-10-2012 RAVI NAGHABUSHANAM 550 20 000105 13864 1300 01-10-2012 G.SUBBAYAMMA 674 21 000107 13612 30 01-10-2012 RAMESH ARORA 684 22 000133 19937 120 01-10-2012 M VARALAXMI 790 23 000134 14568 120 01-10-2012 K SARADAMBA 794 24 000135 972 120 01-10-2012 T MANIKYAMBA 799 25 000137 973 120 01-10-2012 U SUSHEELA 804 26 000138 13918 120 01-10-2012 K RAJYALAXMI 809 27 000161 12743 500 01-10-2012 RAVI PEDA -

Annexure 1B 18416
Annexure 1 B List of taxpayers allotted to State having turnover of more than or equal to 1.5 Crore Sl.No Taxpayers Name GSTIN 1 BROTHERS OF ST.GABRIEL EDUCATION SOCIETY 36AAAAB0175C1ZE 2 BALAJI BEEDI PRODUCERS PRODUCTIVE INDUSTRIAL COOPERATIVE SOCIETY LIMITED 36AAAAB7475M1ZC 3 CENTRAL POWER RESEARCH INSTITUTE 36AAAAC0268P1ZK 4 CO OPERATIVE ELECTRIC SUPPLY SOCIETY LTD 36AAAAC0346G1Z8 5 CENTRE FOR MATERIALS FOR ELECTRONIC TECHNOLOGY 36AAAAC0801E1ZK 6 CYBER SPAZIO OWNERS WELFARE ASSOCIATION 36AAAAC5706G1Z2 7 DHANALAXMI DHANYA VITHANA RAITHU PARASPARA SAHAKARA PARIMITHA SANGHAM 36AAAAD2220N1ZZ 8 DSRB ASSOCIATES 36AAAAD7272Q1Z7 9 D S R EDUCATIONAL SOCIETY 36AAAAD7497D1ZN 10 DIRECTOR SAINIK WELFARE 36AAAAD9115E1Z2 11 GIRIJAN PRIMARY COOPE MARKETING SOCIETY LIMITED ADILABAD 36AAAAG4299E1ZO 12 GIRIJAN PRIMARY CO OP MARKETING SOCIETY LTD UTNOOR 36AAAAG4426D1Z5 13 GIRIJANA PRIMARY CO-OPERATIVE MARKETING SOCIETY LIMITED VENKATAPURAM 36AAAAG5461E1ZY 14 GANGA HITECH CITY 2 SOCIETY 36AAAAG6290R1Z2 15 GSK - VISHWA (JV) 36AAAAG8669E1ZI 16 HASSAN CO OPERATIVE MILK PRODUCERS SOCIETIES UNION LTD 36AAAAH0229B1ZF 17 HCC SEW MEIL JOINT VENTURE 36AAAAH3286Q1Z5 18 INDIAN FARMERS FERTILISER COOPERATIVE LIMITED 36AAAAI0050M1ZW 19 INDU FORTUNE FIELDS GARDENIA APARTMENT OWNERS ASSOCIATION 36AAAAI4338L1ZJ 20 INDUR INTIDEEPAM MUTUAL AIDED CO-OP THRIFT/CREDIT SOC FEDERATION LIMITED 36AAAAI5080P1ZA 21 INSURANCE INFORMATION BUREAU OF INDIA 36AAAAI6771M1Z8 22 INSTITUTE OF DEFENCE SCIENTISTS AND TECHNOLOGISTS 36AAAAI7233A1Z6 23 KARNATAKA CO-OPERATIVE MILK PRODUCER\S FEDERATION -

Andhra Pradesh State Nandi Film Awards for Year 2011
ANDHRA PRADESH STATE NANDI FILM AWARDS FOR YEAR 2011 (A) FEATURE FILMS First Best Feature Film SRIRAMA RAJYAM 1 9” Golden Nandi with a cash prize of Sri Yalamanchili Sai Babu Rs.75,000 and Commendation Certificate to the Producer 2 6” Copper Nandi and Commendation Sri Bapu Certificate to the Director 3 6” Copper Nandi and Commendation Sri Nandamuri Bala Krishna Certificate to the Hero 4 6” Copper Nandi and Commendation Ms. Nayana Thara Certificate to the Heroine Second Best Feature Film RAJANNA 5 9” Silver Nandi with a cash prize of Sri Akkineni Nagarjuna Rs.40,000 and Commendation Certificate to the Producer 6 6” Copper Nandi and Commendation Sri V Vijayendra Prasad Certificate to the Director 7 6” Copper Nandi and Commendation Sri Akkineni Nagarjuna Certificate to the Hero 8 6” Copper Nandi and Commendation Smt. Sneha Certificate to the Heroine Third Best Feature Film VIRODI 9 9” Bronze Nandi with a cash prize of Sri Meka Anil Kumar Rs.20,000 and Commendation Certificate to the Producer 10 6” Copper Nandi and Commendation Sri Neelakanta Certificate to the Director 11 6” Copper Nandi and Commendation Sri Srikanth Certificate to the Hero 12 6” Copper Nandi and Commendation Ms. Kamalini Mukharji Certificate to the Heroine (i) Best Home Viewing Feature Film A 100% LOVE 13 6” Silver Nandi, Sri Akkineni Sri Allu Arvind Nageshwara Rao Gold Medal with a Cash Prize of Rs.30,000/- and a Commendation Certificate to the Producer (ii) Best Popular Feature Film providing wholesome DOOKUDU entertainment 14 6” Silver Nandi with a Cash Prize of Sri -
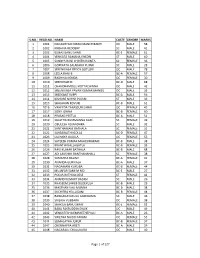
S.No. Regd.No. Name Caste Gender Marks 1 1001
S.NO. REGD.NO. NAME CASTE GENDER MARKS 1 1001 NAGASHYAM KIRAN MANCHIKANTI OC MALE 58 2 1002 KRISHNA REDDERY SC MALE 41 3 1003 ELMAS BANU SHAIK BC-E FEMALE 61 4 1004 VENKATA RAMANA KHEDRI ST MALE 60 5 1005 SANDYA RANI CHINTHAKUNTA SC FEMALE 36 6 1006 GOPINATH SALAKARU PUJARI SC MALE 28 7 1007 SREENIVASA REDDY GOTLURI OC MALE 78 8 1008 LEELA RANI B BC-A FEMALE 57 9 1009 RADHIKA KONDA OC FEMALE 30 10 1010 SREEDHAR M BC-D MALE 68 11 1011 CHANDRAMOULI KOTTACHINNA OC MALE 42 12 1012 SREENIVASA PAVAN KUMAR MANGU OC MALE 35 13 1013 SREEKANT SUPPI BC-A MALE 56 14 1014 KISHORE NAYAK PUJARI ST MALE 39 15 1015 SHAJAHAN KOVURI BC-B MALE 61 16 1016 VAHEEDA TABASSUM SHAIK OC FEMALE 45 17 1017 SONY JONNA BC-B FEMALE 60 18 1018 PRASAD PEETLA BC-A MALE 51 19 1019 SUJATHA BUMMANNA GARI SC FEMALE 49 20 1020 OBULESH ADIANDHRA SC MALE 32 21 1021 SANTHAMANI BATHALA SC FEMALE 31 22 1022 SARASWATHI GOLLA BC-D FEMALE 47 23 1023 LAVANYA GAJULA OC FEMALE 55 24 1024 SATEESH KUMAR MAHESWARAM BC-B MALE 38 25 1025 KRANTHI NALLAGATLA BC-B FEMALE 33 26 1026 RAVI KUMAR BATHALA BC-B MALE 68 27 1027 ADI LAKSHMI BANTHANAHALL SC FEMALE 38 28 1028 SAMATHA BALIMI BC-A FEMALE 41 29 1030 ANANDA GURIKALA BC-A MALE 37 30 1031 NAGAMANI KURUBA BC-B FEMALE 44 31 1032 MUJAFAR SAMI M MD BC-E MALE 27 32 1033 POOJA RATHOD DESE ST FEMALE 42 33 1034 ANAND KUMART BADIGI SC MALE 26 34 1035 KHASEEM SAHEB DUDEKULA BC-B MALE 29 35 1036 MASTHAN VALI MUNNA BC-B MALE 38 36 1037 SUCHITRA YELLUGANI BC-B FEMALE 44 37 1038 RANGANAYAKULU GUDIDAMA SC MALE 46 38 1039 SAILAJA VUBBARA OC FEMALE 38 39 1040 SHAKILA BANU SHAIK BC-E FEMALE 52 40 1041 BABA FAKRUDDIN SHAIK OC MALE 49 41 1042 VENKATESH DEMAKETHEPALLI BC-A MALE 26 42 1043 SWETHA NAIDU PAKAM OC FEMALE 55 43 1044 SUMALATHA JUKUR BC-B FEMALE 37 44 1047 CHENNAPPA ARETI BC-A MALE 29 45 1048 NAGARAJU CHALUKURU OC MALE 40 Page 1 of 127 S.NO. -

1 High Court of Judicature at Hyderabad for the State Of
1 HIGH COURT OF JUDICATURE AT HYDERABAD FOR THE STATE OF TELANGANA AND THE STATE OF ANDHRA PRADESH REGD. NO. WISE MARKS LIST OF THE CANDIDATES APPEARED IN THE WRITTEN EXAMINATION HELD ON 25-10-2015 FOR THE POSTS OF CIVIL JUDGE (JUNIOR DIVISION) BY DIRECT RECRUITMENT NOTIFIED FOR THE YEAR 2014 HALL PART PART NAME OF TH.. APPLICANT TOTAL S.NO. TICKET GROUP GENDER A B MARKS NO 1 101 ELMAS BANU SHAIK BC-E FEMALE 14 20 ¾ 34 ¾ 2 102 VENKATA RAMANA KHEDRI ST MALE 11 ¼ 12 ¾ 24 3 103 SREENIVASA REDDY GOTLURI OC MALE 23 V4 17 3/4 41 4 104 LEELA RANI B BC-A FEMALE 3 6 Y2 9 ½ 5 105 SREEDHAR M BC-D MALE 13 ½ 14 ¾ 28 ¼ 6 106 SREEKANT SUPPI BC-A MALE 8 ¾ 14 ¾ 23 ½ 7 107 SHAJAHAN KOVURI BC-B MALE 16 ½ 21 37 ½ 8 108 SONY JON NA BC-B FEMALE 13 14 3/4 27 ¾ 9 109 SUJATHA BUMMANNA GARI SC FEMALE 9 1/2 12 ¾ 22 ¼ 10 110 LAVANYA GAJULA OC FEMALE 3 11 ¼ 14 1/4 11 111 RAVI KUMAR BATHALA BC-B MALE 15 14 29 12 112 POOJA RATHOD DESE ST FEMALE 2 ¾ 13 1/2 16 ¼ 13 113 SHAKILA BANU SHAIK BC-E FEMALE 6 ¼ 7 13 ¼ V 14 114 SWETHA NAIDU PAKAM oc FEMALE 12 ¾ 16 1/4 29 15 115 MADHAVI LATHA MAILA BC-A FEMALE 12 ½ 10 ¼ 22 ¾ V V 16 116 MANASA MAYAKUNTLA BC-B FEMALE 29 ¾ 24 53 ¾ V V V 17 118 BHAGYALAKSHMAMMA KADIRI SC FEMALE 8 ¼ 15 23 ¼ V 1/4 18 119 HARI PRASAD KONDAPAKU V SC MALE 13 ¼ 17 30 19 120 JAHARABEE D BC-B FEMALE 8 9 V 17 V2 V 20 121 VARALASHMI DEVI PAGADALA V BC-A FEMALE 8 ¾ 5 V 14 ¼ 1/2 21 122 HEMALATHA SAKE SC FEMALE 3 15 ½ 18 V V 22 123 PULLAIAH GIDDALURU BC-A MALE 13 17 1/2 V 30 1/2 23 124 SARATH BABU RAMAVATH V ST MALE 6 ¼ 18 24 ¼ V V 24 125 ASIA CHITVELU BC-E FEMALE 16 Y2 18 ¾ V 35 ¼ V 1/2 V V 25 126 NAGESH MARRIMEKALA BC-A MALE 15 ½ 16 31 V V 26 134 DOWLATH SHIEK BC-E FEMALE 6 7 1/2 V 13 1/2 V HIMA V 27 135 BINDU GOWRA V OC V FEMALE 16 1/2 15 ½ 32 V 1/2 28 136 PRASANThI PALLEPOGULA SC FEMALE 9 9 V 18 1/2 V V 29 137 VHEMA SRAVANTHI JANKI RAM OC FEMALE 24 ½ 21 45 ½ 30 138 SURESH BABU G.N. -

Pa N O R a M a O F S O U T H C I N E M a Vol 1 Issue 1 October 2009 Rs.50 01
Pa n o r a m a o f s o u t h c i n e m a Vol 1 issue 1 october 2009 rs.50 01 01 www.southscope.in siddharth’s intoxicating signature style i am a technique in myself -Balakrishna Why sizzler ileana’s story unfolded follow us on shraddha das will never do that? Panorama of south cinema Publisher Chief Executive Officer Executive Director Editor- in- Chief Assistant Editor Features Editor Features Writer Editorial Coordinators Tamil Nadu & Kerala Karnataka Mumbai Creative Director Visualiser Senior Graphic Designers Graphic Designers Production Head Creative Consultant Branding & Marketing Director Marketing Managers Moorthy Sreenivasulu Allu Sirish Ramakanth T Vanaja Banagiri Mona Ramavat Karthik Pasupulate Vrinda Prasad Sridevi Sreedhar Aravind G Anil Merani Raj Shekar B Jaya Prakash K P Suresh K Palvai, Suresh CH Ravi Kumar K V, Vamshi Vulavapati Krishna P Priya Gazdar Ayyar S, [email protected] Tvishi Zaveri, [email protected] Raja Reddy M, [email protected] Saroj Kumar Biswal, [email protected] Raghu Kumar Gorthy, [email protected] Sanjay Kumar S, [email protected] Mohan Manoharan, [email protected] Ravanam Swaminaidu Vishnuvardhan Induri, Radhakrishna G [email protected] or SMS SCOPE to 56263 [email protected] Circulation National Manager Deputy Manager Regional Manager (Chennai) Consultant- Distribution Board of Advisors Subscriptions: Enquiries: www.southscope.in Southscope takes no responsibility for unsolicited photographs or material. ALL PHOTOGRAPHS, UNLESS OTHERWISE INDICATED, ARE USED FOR ILLUSTRATIVE PURPOSES ONLY Registered Office: #202, Shiva Sai Sannidhi, Dwarakapuri Colony, Punjagutta, Hyderabad 500 034. All rights reserved. Reproducing in any manner without permission prohibited. -

RESUME Dr. SRIDHAR BABU GUMMADI Date of Birth
RESUME Dr. SRIDHAR BABU GUMMADI PERSONAL DETAILS: Date of Birth : 27 March 1977 Sex : Male Martial status : Married Nationality : Indian Communication address : Srinivasa Colony, Near Sumangali Function Hall, Hanamakonda, Warangal-506009, Telangana, India Mobile: +91-9866921912 E.mail: [email protected] EDUCATION: Ph.D. (Pharmaceutical Sciences) Kakatiya University, Warangal, India Advisors: Prof. A.V.N. Appa Rao and Prof. B. Ravi Kumar Dissertation title: “Isolation of some natural products (Caralluma Species) and Screening them for Biological activity” Awarded on: October 2008, By Thesis Masters of Pharmacy (Pharmaceutical chemistry) Kakatiya University, Warangal, India Thesis title: Chemical investigation of Caralluma stalagmifera Date of Graduation: April 2003, First division Bachelor of Pharmacy (Pharmaceutical Sciences) Kakatiya University, Warangal, India Date of Graduation: November 2000, First division EMPLOYMENT HISTORY Working as Professor & Principal, Sri Shivani College of Pharmacy, Mulugu Road, Warangal, Andhra Pradesh, India from 24th August 2016 to till date. Working as Professor & Principal, Pragathi Pharmacy College, Jangaon, Warangal, Andhra Pradesh, India from 1st June 2009 to 23rd August 2016. Worked as an Associate Professor, Talla Padmavathi College of Pharmacy, Orus, Warangal, Andhra Pradesh, India from 17th October 2008 to 31st May 2009. Worked as an Assistant Professor, Talla Padmavathi College of Pharmacy, Orus, Warangal, Andhra Pradesh, India from 10th April 2003 to 16th October 2008. 1 Professional Appointments: Chief Superintendent, Graduate & post graduate level Examinations, Sri Shivani College of Pharmacy, Kakatiya University University, Warangal. Chief Superintendent, Graduate & post graduate level Examinations, Pragathi Pharmacy college, Jawaharlal Nehru Technology University, Hyderabad. Internal & External Examiner for Graduate level Examinations, Kakatiya University, Warangal. Internal Examiner for post Graduate level Examinations, Kakatiya University, Warangal. -
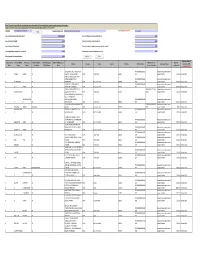
CIN/BCIN Company/Bank Name
Note: This sheet is applicable for uploading the particulars related to the unclaimed and unpaid amount pending with company. Make sure that the details are in accordance with the information already provided in e-form IEPF-2 CIN/BCIN L24110MH1947PLC005719 Prefill Company/Bank Name PIRAMAL ENTERPRISES LIMITED Date Of AGM(DD-MON-YYYY) 30-Jul-2018 Sum of unpaid and unclaimed dividend 12034164.00 Sum of interest on matured debentures 0.00 Sum of matured deposit 0.00 Sum of interest on matured deposit 0.00 Sum of matured debentures 0.00 Sum of interest on application money due for refund 0.00 Sum of application money due for refund 0.00 Redemption amount of preference shares 0.00 Sales proceed for fractional shares 0.00 Validate Clear Proposed Date of Investor First Investor Middle Investor Last Father/Husband Father/Husband Father/Husband Last DP Id-Client Id- Amount Address Country State District Pin Code Folio Number Investment Type transfer to IEPF Name Name Name First Name Middle Name Name Account Number transferred (DD-MON-YYYY) 39A SECOND STREET SMS LAYOUT PIRA000000000BS00 Amount for unclaimed and A ALAGIRI SWAMY NA ONDIPUTHUR COIMBATORE INDIA Tamil Nadu 641016 076 unpaid dividend 300.00 09-Sep-2018 H NO 6-3-598/51/12/B IST FLR ANAND NAGAR COLONY PIRA000000000AS01 Amount for unclaimed and A AMARENDRA NA HYDERABAD INDIA Andhra Pradesh 500004 467 unpaid dividend 300.00 09-Sep-2018 7-1-28/1/A/12 PARK AVENUE PIRA000000000AS01 Amount for unclaimed and A ANJI REDDY NA AMEERPET HYDERABAD INDIA Andhra Pradesh 500016 053 unpaid dividend 1200.00 09-Sep-2018 4/104, BOMMAIKUTTAI MEDU IN300159-10771263- Amount for unclaimed and A ARIVUCHELVAN NA SELLAPPAMPATTY P. -

Commencement May2021 Progr
CLASS OF COMMENCEMENT MAY 15, 2021 II The pandemic did not diminish your years of hard work, nor did it define who you will become. In fact, it has brought into sharp focus the remarkable humans you already are. Your ability to reach this day — GRADUATING FROM THE UNIVERSITY OF CALIFORNIA, BERKELEY — is nothing short of heroic. Congratulations, CLASS OF 2021. PROGRAM WELCOME AND LAND ACKNOWLEDGEMENT ALFRED DAY ASSOCIATE DEAN OF STUDENTS AND DIRECTOR CENTER FOR SUPPORT AND INTERVENTION NATIONAL ANTHEM JAE JOON (JOSEPH) SHIN ’21 INTRODUCTION OF CHANCELLOR T. CHRIST NIKITA DHAR ’21 VICE PRESIDENT, SENIOR CLASS COUNCIL WELCOME REMARKS AND AWARD PRESENTATION CAROL T. CHRIST CHANCELLOR THE UNIVERSITY MEDALIST LEYLA KABULI ’21 STUDENT PERFORMANCE OWEN FARMER ’21 GUINNESS WORLD RECORD UNICYCLIST CLASS OF 2021 SENIOR GIFT PRESENTATION DOUGLAS WICKHAM ’21 PRESIDENT, CAL STUDENT PHILANTHROPY ERIC MANZO ’21 VICE PRESIDENT OF MEMBERSHIP, CAL STUDENT PHILANTHROPY INTRODUCTION OF KEYNOTE SPEAKER MEGAN WIENER ’21 PRESIDENT, SENIOR CLASS COUNCIL KEYNOTE SPEAKER ADEWALE “WALLY” ADEYEMO ’04 DEPUTY SECRETARY OF THE TREASURY STUDENT PERFORMANCE BARETROUPE CONFERRING OF DEGREES CAROL T. CHRIST CHANCELLOR HAIL TO CALIFORNIA DECADENCE A CAPPELLA 2 KEYNOTE SPEAKER ADEWALE “WALLY” ADEYEMO ’04 Wally Adeyemo, the Deputy Secretary of the Treasury, has spent most of his career in public service, convening governments, companies, and organizations to achieve common goals. Adeyemo came to the Treasury Department from the Obama Foundation, where he served as president beginning in August 2019. Before that he was a senior advisor at the Center for Strategic and International Studies and at Blackrock and held several public service roles. -

The NEET PG Rank Wise List of Canidates Who Studied BDS In
Dr. NTR UNIVERSITY OF HEALTH SCIENCES, VIJAYAWADA -8 As per the data received from the Ministry of Health , Government of India, the following is the NEET PG Rank wise list of canidates who studied BDS in the State of Andhra Pradesh ( Based on the information provided by the candidates in the application form) and appeared for NEET MDS 2020 conducted by NBE. Cut off Marks for Eligibility under General Category is 286 Marks, For PH category 268 Marks, for BC,SC,ST categories 250 Marks Note 1 : This is only for information of Students and Parents Note 2 : The final Merit position will be displayed only after submission of online application in response to the University Notification and after verification of original certificates/ eligibility as per rules NEET - S.No ROLL NO NAME OF THE CANDIDATE SCORE RANK 1 1955226759 MELETI VENKATA SOWMYA 776 2 2 1955209721 KOMMINENI DIVYA SREE 688 138 3 1955202150 B DINAKAR REDDY 670 236 4 1955217258 GIRI KAVYA SWETHA 667 253 5 1955202529 SATRASALA LAKSHMI CHANDANA 660 295 6 1955227142 KALLEPALLI MEGHANA 641 442 7 1955211016 VANGA CHANDANA 640 453 8 1955210407 NALLAMILLI LALITHA SRI ROJA 638 482 9 1955203873 SALLA VINEETHA REDDY 634 529 10 1955210377 NAGATHOTA HIMABINDU 633 537 11 1955210509 NAVEEN REDDY VAJRALA 631 557 12 1955227396 NARENDRA KUMAR YANDRAPU 625 633 13 1955226902 ESWARI PRIYA GUMMADI 622 667 14 1955210546 PONNADA NAVEENA 619 707 15 1955217223 BAGU VENKATA SINDHUJA 618 731 16 1955209842 GUNTI JESU SOLOMON PRAKHYATH 616 744 17 1955202376 MUVVA HIMAPAVANA 614 784 18 1955226992 ABOTHULA