Dynamic Programming (Pt 6) Parsing Algorithms Reminders
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
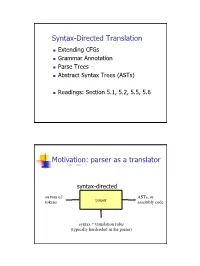
Syntax-Directed Translation, Parse Trees, Abstract Syntax Trees
Syntax-Directed Translation Extending CFGs Grammar Annotation Parse Trees Abstract Syntax Trees (ASTs) Readings: Section 5.1, 5.2, 5.5, 5.6 Motivation: parser as a translator syntax-directed translation stream of ASTs, or tokens parser assembly code syntax + translation rules (typically hardcoded in the parser) 1 Mechanism of syntax-directed translation syntax-directed translation is done by extending the CFG a translation rule is defined for each production given X Æ d A B c the translation of X is defined in terms of translation of nonterminals A, B values of attributes of terminals d, c constants To translate an input string: 1. Build the parse tree. 2. Working bottom-up • Use the translation rules to compute the translation of each nonterminal in the tree Result: the translation of the string is the translation of the parse tree's root nonterminal Why bottom up? a nonterminal's value may depend on the value of the symbols on the right-hand side, so translate a non-terminal node only after children translations are available 2 Example 1: arith expr to its value Syntax-directed translation: the CFG translation rules E Æ E + T E1.trans = E2.trans + T.trans E Æ T E.trans = T.trans T Æ T * F T1.trans = T2.trans * F.trans T Æ F T.trans = F.trans F Æ int F.trans = int.value F Æ ( E ) F.trans = E.trans Example 1 (cont) E (18) Input: 2 * (4 + 5) T (18) T (2) * F (9) F (2) ( E (9) ) int (2) E (4) * T (5) Annotated Parse Tree T (4) F (5) F (4) int (5) int (4) 3 Example 2: Compute type of expr E -> E + E if ((E2.trans == INT) and (E3.trans == INT) then E1.trans = INT else E1.trans = ERROR E -> E and E if ((E2.trans == BOOL) and (E3.trans == BOOL) then E1.trans = BOOL else E1.trans = ERROR E -> E == E if ((E2.trans == E3.trans) and (E2.trans != ERROR)) then E1.trans = BOOL else E1.trans = ERROR E -> true E.trans = BOOL E -> false E.trans = BOOL E -> int E.trans = INT E -> ( E ) E1.trans = E2.trans Example 2 (cont) Input: (2 + 2) == 4 1. -

Metaheuristics1
METAHEURISTICS1 Kenneth Sörensen University of Antwerp, Belgium Fred Glover University of Colorado and OptTek Systems, Inc., USA 1 Definition A metaheuristic is a high-level problem-independent algorithmic framework that provides a set of guidelines or strategies to develop heuristic optimization algorithms (Sörensen and Glover, To appear). Notable examples of metaheuristics include genetic/evolutionary algorithms, tabu search, simulated annealing, and ant colony optimization, although many more exist. A problem-specific implementation of a heuristic optimization algorithm according to the guidelines expressed in a metaheuristic framework is also referred to as a metaheuristic. The term was coined by Glover (1986) and combines the Greek prefix meta- (metá, beyond in the sense of high-level) with heuristic (from the Greek heuriskein or euriskein, to search). Metaheuristic algorithms, i.e., optimization methods designed according to the strategies laid out in a metaheuristic framework, are — as the name suggests — always heuristic in nature. This fact distinguishes them from exact methods, that do come with a proof that the optimal solution will be found in a finite (although often prohibitively large) amount of time. Metaheuristics are therefore developed specifically to find a solution that is “good enough” in a computing time that is “small enough”. As a result, they are not subject to combinatorial explosion – the phenomenon where the computing time required to find the optimal solution of NP- hard problems increases as an exponential function of the problem size. Metaheuristics have been demonstrated by the scientific community to be a viable, and often superior, alternative to more traditional (exact) methods of mixed- integer optimization such as branch and bound and dynamic programming. -

Derivatives of Parsing Expression Grammars
Derivatives of Parsing Expression Grammars Aaron Moss Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada [email protected] This paper introduces a new derivative parsing algorithm for recognition of parsing expression gram- mars. Derivative parsing is shown to have a polynomial worst-case time bound, an improvement on the exponential bound of the recursive descent algorithm. This work also introduces asymptotic analysis based on inputs with a constant bound on both grammar nesting depth and number of back- tracking choices; derivative and recursive descent parsing are shown to run in linear time and constant space on this useful class of inputs, with both the theoretical bounds and the reasonability of the in- put class validated empirically. This common-case constant memory usage of derivative parsing is an improvement on the linear space required by the packrat algorithm. 1 Introduction Parsing expression grammars (PEGs) are a parsing formalism introduced by Ford [6]. Any LR(k) lan- guage can be represented as a PEG [7], but there are some non-context-free languages that may also be represented as PEGs (e.g. anbncn [7]). Unlike context-free grammars (CFGs), PEGs are unambiguous, admitting no more than one parse tree for any grammar and input. PEGs are a formalization of recursive descent parsers allowing limited backtracking and infinite lookahead; a string in the language of a PEG can be recognized in exponential time and linear space using a recursive descent algorithm, or linear time and space using the memoized packrat algorithm [6]. PEGs are formally defined and these algo- rithms outlined in Section 3. -

Lecture 4 Dynamic Programming
1/17 Lecture 4 Dynamic Programming Last update: Jan 19, 2021 References: Algorithms, Jeff Erickson, Chapter 3. Algorithms, Gopal Pandurangan, Chapter 6. Dynamic Programming 2/17 Backtracking is incredible powerful in solving all kinds of hard prob- lems, but it can often be very slow; usually exponential. Example: Fibonacci numbers is defined as recurrence: 0 if n = 0 Fn =8 1 if n = 1 > Fn 1 + Fn 2 otherwise < ¡ ¡ > A direct translation in:to recursive program to compute Fibonacci number is RecFib(n): if n=0 return 0 if n=1 return 1 return RecFib(n-1) + RecFib(n-2) Fibonacci Number 3/17 The recursive program has horrible time complexity. How bad? Let's try to compute. Denote T(n) as the time complexity of computing RecFib(n). Based on the recursion, we have the recurrence: T(n) = T(n 1) + T(n 2) + 1; T(0) = T(1) = 1 ¡ ¡ Solving this recurrence, we get p5 + 1 T(n) = O(n); = 1.618 2 So the RecFib(n) program runs at exponential time complexity. RecFib Recursion Tree 4/17 Intuitively, why RecFib() runs exponentially slow. Problem: redun- dant computation! How about memorize the intermediate computa- tion result to avoid recomputation? Fib: Memoization 5/17 To optimize the performance of RecFib, we can memorize the inter- mediate Fn into some kind of cache, and look it up when we need it again. MemFib(n): if n = 0 n = 1 retujrjn n if F[n] is undefined F[n] MemFib(n-1)+MemFib(n-2) retur n F[n] How much does it improve upon RecFib()? Assuming accessing F[n] takes constant time, then at most n additions will be performed (we never recompute). -

Dynamic Programming Via Static Incrementalization 1 Introduction
Dynamic Programming via Static Incrementalization Yanhong A. Liu and Scott D. Stoller Abstract Dynamic programming is an imp ortant algorithm design technique. It is used for solving problems whose solutions involve recursively solving subproblems that share subsubproblems. While a straightforward recursive program solves common subsubproblems rep eatedly and of- ten takes exp onential time, a dynamic programming algorithm solves every subsubproblem just once, saves the result, reuses it when the subsubproblem is encountered again, and takes p oly- nomial time. This pap er describ es a systematic metho d for transforming programs written as straightforward recursions into programs that use dynamic programming. The metho d extends the original program to cache all p ossibly computed values, incrementalizes the extended pro- gram with resp ect to an input increment to use and maintain all cached results, prunes out cached results that are not used in the incremental computation, and uses the resulting in- cremental program to form an optimized new program. Incrementalization statically exploits semantics of b oth control structures and data structures and maintains as invariants equalities characterizing cached results. The principle underlying incrementalization is general for achiev- ing drastic program sp eedups. Compared with previous metho ds that p erform memoization or tabulation, the metho d based on incrementalization is more powerful and systematic. It has b een implemented and applied to numerous problems and succeeded on all of them. 1 Intro duction Dynamic programming is an imp ortant technique for designing ecient algorithms [2, 44 , 13 ]. It is used for problems whose solutions involve recursively solving subproblems that overlap. -

Automatic Code Generation Using Dynamic Programming Techniques
! Automatic Code Generation using Dynamic Programming Techniques MASTERARBEIT zur Erlangung des akademischen Grades Diplom-Ingenieur im Masterstudium INFORMATIK Eingereicht von: Igor Böhm, 0155477 Angefertigt am: Institut für System Software Betreuung: o.Univ.-Prof.Dipl.-Ing. Dr. Dr.h.c. Hanspeter Mössenböck Linz, Oktober 2007 Abstract Building compiler back ends from declarative specifications that map tree structured intermediate representations onto target machine code is the topic of this thesis. Although many tools and approaches have been devised to tackle the problem of automated code generation, there is still room for improvement. In this context we present Hburg, an implementation of a code generator generator that emits compiler back ends from concise tree pattern specifications written in our code generator description language. The language features attribute grammar style specifications and allows for great flexibility with respect to the placement of semantic actions. Our main contribution is to show that these language features can be integrated into automatically generated code generators that perform optimal instruction selection based on tree pattern matching combined with dynamic program- ming. In order to substantiate claims about the usefulness of our language we provide two complete examples that demonstrate how to specify code generators for Risc and Cisc architectures. Kurzfassung Diese Diplomarbeit beschreibt Hburg, ein Werkzeug das aus einer Spezi- fikation des abstrakten Syntaxbaums eines Programms und der Spezifika- tion der gewuns¨ chten Zielmaschine automatisch einen Codegenerator fur¨ diese Maschine erzeugt. Abbildungen zwischen abstrakten Syntaxb¨aumen und einer Zielmaschine werden durch Baummuster definiert. Fur¨ diesen Zweck haben wir eine deklarative Beschreibungssprache entwickelt, die es erm¨oglicht den Baummustern Attribute beizugeben, wodurch diese gleich- sam parametrisiert werden k¨onnen. -

Parsing 1. Grammars and Parsing 2. Top-Down and Bottom-Up Parsing 3
Syntax Parsing syntax: from the Greek syntaxis, meaning “setting out together or arrangement.” 1. Grammars and parsing Refers to the way words are arranged together. 2. Top-down and bottom-up parsing Why worry about syntax? 3. Chart parsers • The boy ate the frog. 4. Bottom-up chart parsing • The frog was eaten by the boy. 5. The Earley Algorithm • The frog that the boy ate died. • The boy whom the frog was eaten by died. Slide CS474–1 Slide CS474–2 Grammars and Parsing Need a grammar: a formal specification of the structures allowable in Syntactic Analysis the language. Key ideas: Need a parser: algorithm for assigning syntactic structure to an input • constituency: groups of words may behave as a single unit or phrase sentence. • grammatical relations: refer to the subject, object, indirect Sentence Parse Tree object, etc. Beavis ate the cat. S • subcategorization and dependencies: refer to certain kinds of relations between words and phrases, e.g. want can be followed by an NP VP infinitive, but find and work cannot. NAME V NP All can be modeled by various kinds of grammars that are based on ART N context-free grammars. Beavis ate the cat Slide CS474–3 Slide CS474–4 CFG example CFG’s are also called phrase-structure grammars. CFG’s Equivalent to Backus-Naur Form (BNF). A context free grammar consists of: 1. S → NP VP 5. NAME → Beavis 1. a set of non-terminal symbols N 2. VP → V NP 6. V → ate 2. a set of terminal symbols Σ (disjoint from N) 3. -

Abstract Syntax Trees & Top-Down Parsing
Abstract Syntax Trees & Top-Down Parsing Review of Parsing • Given a language L(G), a parser consumes a sequence of tokens s and produces a parse tree • Issues: – How do we recognize that s ∈ L(G) ? – A parse tree of s describes how s ∈ L(G) – Ambiguity: more than one parse tree (possible interpretation) for some string s – Error: no parse tree for some string s – How do we construct the parse tree? Compiler Design 1 (2011) 2 Abstract Syntax Trees • So far, a parser traces the derivation of a sequence of tokens • The rest of the compiler needs a structural representation of the program • Abstract syntax trees – Like parse trees but ignore some details – Abbreviated as AST Compiler Design 1 (2011) 3 Abstract Syntax Trees (Cont.) • Consider the grammar E → int | ( E ) | E + E • And the string 5 + (2 + 3) • After lexical analysis (a list of tokens) int5 ‘+’ ‘(‘ int2 ‘+’ int3 ‘)’ • During parsing we build a parse tree … Compiler Design 1 (2011) 4 Example of Parse Tree E • Traces the operation of the parser E + E • Captures the nesting structure • But too much info int5 ( E ) – Parentheses – Single-successor nodes + E E int 2 int3 Compiler Design 1 (2011) 5 Example of Abstract Syntax Tree PLUS PLUS 5 2 3 • Also captures the nesting structure • But abstracts from the concrete syntax a more compact and easier to use • An important data structure in a compiler Compiler Design 1 (2011) 6 Semantic Actions • This is what we’ll use to construct ASTs • Each grammar symbol may have attributes – An attribute is a property of a programming language construct -

1 Introduction 2 Dijkstra's Algorithm
15-451/651: Design & Analysis of Algorithms September 3, 2019 Lecture #3: Dynamic Programming II last changed: August 30, 2019 In this lecture we continue our discussion of dynamic programming, focusing on using it for a variety of path-finding problems in graphs. Topics in this lecture include: • The Bellman-Ford algorithm for single-source (or single-sink) shortest paths. • Matrix-product algorithms for all-pairs shortest paths. • Algorithms for all-pairs shortest paths, including Floyd-Warshall and Johnson. • Dynamic programming for the Travelling Salesperson Problem (TSP). 1 Introduction As a reminder of basic terminology: a graph is a set of nodes or vertices, with edges between some of the nodes. We will use V to denote the set of vertices and E to denote the set of edges. If there is an edge between two vertices, we call them neighbors. The degree of a vertex is the number of neighbors it has. Unless otherwise specified, we will not allow self-loops or multi-edges (multiple edges between the same pair of nodes). As is standard with discussing graphs, we will use n = jV j, and m = jEj, and we will let V = f1; : : : ; ng. The above describes an undirected graph. In a directed graph, each edge now has a direction (and as we said earlier, we will sometimes call the edges in a directed graph arcs). For each node, we can now talk about out-neighbors (and out-degree) and in-neighbors (and in-degree). In a directed graph you may have both an edge from u to v and an edge from v to u. -

Language and Compiler Support for Dynamic Code Generation by Massimiliano A
Language and Compiler Support for Dynamic Code Generation by Massimiliano A. Poletto S.B., Massachusetts Institute of Technology (1995) M.Eng., Massachusetts Institute of Technology (1995) Submitted to the Department of Electrical Engineering and Computer Science in partial fulfillment of the requirements for the degree of Doctor of Philosophy at the MASSACHUSETTS INSTITUTE OF TECHNOLOGY September 1999 © Massachusetts Institute of Technology 1999. All rights reserved. A u th or ............................................................................ Department of Electrical Engineering and Computer Science June 23, 1999 Certified by...............,. ...*V .,., . .* N . .. .*. *.* . -. *.... M. Frans Kaashoek Associate Pro essor of Electrical Engineering and Computer Science Thesis Supervisor A ccepted by ................ ..... ............ ............................. Arthur C. Smith Chairman, Departmental CommitteA on Graduate Students me 2 Language and Compiler Support for Dynamic Code Generation by Massimiliano A. Poletto Submitted to the Department of Electrical Engineering and Computer Science on June 23, 1999, in partial fulfillment of the requirements for the degree of Doctor of Philosophy Abstract Dynamic code generation, also called run-time code generation or dynamic compilation, is the cre- ation of executable code for an application while that application is running. Dynamic compilation can significantly improve the performance of software by giving the compiler access to run-time infor- mation that is not available to a traditional static compiler. A well-designed programming interface to dynamic compilation can also simplify the creation of important classes of computer programs. Until recently, however, no system combined efficient dynamic generation of high-performance code with a powerful and portable language interface. This thesis describes a system that meets these requirements, and discusses several applications of dynamic compilation. -

Bellman-Ford Algorithm
The many cases offinding shortest paths Dynamic programming Bellman-Ford algorithm We’ve already seen how to calculate the shortest path in an Tyler Moore unweighted graph (BFS traversal) We’ll now study how to compute the shortest path in different CSE 3353, SMU, Dallas, TX circumstances for weighted graphs Lecture 18 1 Single-source shortest path on a weighted DAG 2 Single-source shortest path on a weighted graph with nonnegative weights (Dijkstra’s algorithm) 3 Single-source shortest path on a weighted graph including negative weights (Bellman-Ford algorithm) Some slides created by or adapted from Dr. Kevin Wayne. For more information see http://www.cs.princeton.edu/~wayne/kleinberg-tardos. Some code reused from Python Algorithms by Magnus Lie Hetland. 2 / 13 �������������� Shortest path problem. Given a digraph ����������, with arbitrary edge 6. DYNAMIC PROGRAMMING II weights or costs ���, find cheapest path from node � to node �. ‣ sequence alignment ‣ Hirschberg's algorithm ‣ Bellman-Ford 1 -3 3 5 ‣ distance vector protocols 4 12 �������� 0 -5 ‣ negative cycles in a digraph 8 7 7 2 9 9 -1 1 11 ����������� 5 5 -3 13 4 10 6 ������������� ���������������������������������� 22 3 / 13 4 / 13 �������������������������������� ��������������� Dijkstra. Can fail if negative edge weights. Def. A negative cycle is a directed cycle such that the sum of its edge weights is negative. s 2 u 1 3 v -8 w 5 -3 -3 Reweighting. Adding a constant to every edge weight can fail. 4 -4 u 5 5 2 2 ���������������������� c(W) = ce < 0 t s e W 6 6 �∈ 3 3 0 v -3 w 23 24 5 / 13 6 / 13 ���������������������������������� ���������������������������������� Lemma 1. -

Notes on Dynamic Programming Algorithms & Data Structures 1
Notes on Dynamic Programming Algorithms & Data Structures Dr Mary Cryan These notes are to accompany lectures 10 and 11 of ADS. 1 Introduction The technique of Dynamic Programming (DP) could be described “recursion turned upside-down”. However, it is not usually used as an alternative to recursion. Rather, dynamic programming is used (if possible) for cases when a recurrence for an algorithmic problem will not run in polynomial-time if it is implemented recursively. So in fact Dynamic Programming is a more- powerful technique than basic Divide-and-Conquer. Designing, Analysing and Implementing a dynamic programming algorithm is (like Divide- and-Conquer) highly problem specific. However, there are particular features shared by most dynamic programming algorithms, and we describe them below on page 2 (dp1(a), dp1(b), dp2, dp3). It will be helpful to carry along an introductory example-problem to illustrate these fea- tures. The introductory problem will be the problem of computing the nth Fibonacci number, where F(n) is defined as follows: F0 = 0; F1 = 1; Fn = Fn-1 + Fn-2 (for n ≥ 2). Since Fibonacci numbers are defined recursively, the definition suggests a very natural recursive algorithm to compute F(n): Algorithm REC-FIB(n) 1. if n = 0 then 2. return 0 3. else if n = 1 then 4. return 1 5. else 6. return REC-FIB(n - 1) + REC-FIB(n - 2) First note that were we to implement REC-FIB, we would not be able to use the Master Theo- rem to analyse its running-time. The recurrence for the running-time TREC-FIB(n) that we would get would be TREC-FIB(n) = TREC-FIB(n - 1) + TREC-FIB(n - 2) + Θ(1); (1) where the Θ(1) comes from the fact that, at most, we have to do enough work to add two values together (on line 6).