Getting Started
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Reference Guide
Apache Syncope - Reference Guide Version 2.1.9 Table of Contents 1. Introduction. 2 1.1. Identity Technologies. 2 1.1.1. Identity Stores . 2 1.1.2. Provisioning Engines . 4 1.1.3. Access Managers . 5 1.1.4. The Complete Picture . 5 2. Architecture. 7 2.1. Core . 7 2.1.1. REST . 7 2.1.2. Logic . 8 2.1.3. Provisioning . 8 2.1.4. Workflow. 9 2.1.5. Persistence . 9 2.1.6. Security . 9 2.2. Admin UI. 10 2.2.1. Accessibility . 10 2.3. End-user UI. 12 2.3.1. Password Reset . 12 2.3.2. Accessibility . 13 2.4. CLI . 15 2.5. Third Party Applications. 15 2.5.1. Eclipse IDE Plugin . 15 2.5.2. Netbeans IDE Plugin. 15 3. Concepts . 16 3.1. Users, Groups and Any Objects . 16 3.2. Type Management . 17 3.2.1. Schema . 17 Plain . 17 Derived . 18 Virtual . 18 3.2.2. AnyTypeClass . 19 3.2.3. AnyType . 19 3.2.4. RelationshipType . 21 3.2.5. Type Extensions . 22 3.3. External Resources. 23 3.3.1. Connector Bundles . 24 3.3.2. Connector Instance details . 24 3.3.3. External Resource details . 25 3.3.4. Mapping . 26 3.3.5. Linked Accounts . 29 3.4. Realms . 29 3.4.1. Realm Provisioning . 30 3.4.2. LogicActions . 31 3.5. Entitlements. 31 3.6. Privileges . 31 3.7. Roles. 31 3.7.1. Delegated Administration . 32 3.8. Provisioning. 33 3.8.1. Overview. 33 3.8.2. -
Apache Directory Studio™
Main | ApacheDS | Studio | LDAP API | Mavibot | eSCIMo | Fortress | Kerby Apache Directory Studio Apache Directory Studio™ Home News The Eclipse-based LDAP browser and directory client Screenshots Apache Directory Studio is a complete directory tooling platform Downloads intended to be used with any LDAP server however it is particularly Version 2.0.0-M10 designed for use with ApacheDS. It is an Eclipse RCP application, Older Versions composed of several Eclipse (OSGi) plugins, that can be easily upgraded with additional ones. These plugins can even run within Documentation Eclipse itself. User's Guide Developer's Guide Download Apache FAQs Directory Studio 2.0.0-M10 Resources ChangeLog Testimonials LDAP Browser LDIF Editor Support Mailing Lists & IRC The LDAP Browser has been designed to work with almost any The LDIF Editor is a tool for editing LDIF files. It provides syntax Sources LDAP server available. It not only permits to read and display the highlighting and content assistance. Issue Tracking tree of your LDAP Server but also allows you to modify it by creating, editing or removing entries. Commercial Support Community How to Contribute Schema Editor Embedded ApacheDS Team The Schema Editor has been designed to edit the schema files Apache Directory Studio bundles the latest version of the Original Project Proposal in the OpenLDAP format. It allows you to edit easily attribute LDAPV3 certified ApacheDS. Creating and launching a new Special Thanks types and object classes for Apache Directory Server and LDAP server now takes less than 10 seconds! OpenLDAP. About Apache Apache License ApacheDS Configuration ACI Editor Sponsorship Thanks The ApacheDS Configuration Editor can be used to edit the The ACI Editor allows you to define, for an entry or a set of Security server configuration ('server.xml' and 'config.ldif' files) of an entries, graphically or manually (in souce code mode), an ACI Apache Directory Server installation. -

Software AG Infrastructure Administrator's Guide
Software AG Infrastructure Administrator’s Guide Version 10.3 September 2020 This document applies to Software AG Shared Infrastructure 10.3 and to all subsequent releases. Specifications contained herein are subject to change and these changes will be reported in subsequent release notes or new editions. Copyright © 1999-2021 Software AG, Darmstadt, Germany and/or Software AG USA, Inc., Reston, VA, USA, and/or its subsidiaries and/or its affiliates and/or their licensors. The name Software AG and all Software AG product names are either trademarks or registered trademarks of Software AG and/or Software AG USA Inc. and/or its subsidiaries and/or its affiliates and/or their licensors. Other company and product names mentioned herein may be trademarks of their respective owners. Detailed information on trademarks and patents owned by Software AG and/or its subsidiaries is located at https://softwareag.com/licenses/. Use of this software is subject to adherence to Software AG's licensing conditions and terms. These terms are part of the product documentation, located at https://softwareag.com/licenses/ and/or in the root installation directory of the licensed product(s). This software may include portions of third-party products. For third-party copyright notices, license terms, additional rights or restrictions, please refer to "License Texts, Copyright Notices and Disclaimers of Third Party Products". For certain specific third-party license restrictions, please refer to section E of the Legal Notices available under "License Terms and Conditions for Use of Software AG Products / Copyright and Trademark Notices of Software AG Products". These documents are part of the product documentation, located at https://softwareag.com/licenses/ and/or in the root installation directory of the licensed product(s). -

RBAC-Enable Your Java Web Applications with Apache Directory
RBAC-Enable Your Java Web Applications with How I Built an IAM System using Java and Apache Directory Fortress Shawn McKinney October 29, 2015 JavaOne San Francisco Session Objectives Learn about: Identity and Access Management Specifications (What) System Design Considerations (How) Apache Directory Fortress (Why) JavaOne, San Francisco 2015 2 Introductions Shawn McKinney • Systems Architect http://events.linuxfoundation.org/events/apachecon-core-europe • PMC Apache Directory Project • Engineering Team JavaOne, San Francisco 2015 3 Session Agenda • Examine Specs & Requirements for IAM • Examine Designs for an IAM System • Intro to Apache Fortress – Project Details – Components – Future Image from: HTTP://EVENTS.LINUXFOUNDATION.ORG/EVENTS/APACHECON-NORTH-AMERICA JavaOne, San Francisco 2015 4 Cut to the Chase The recipe for any successful technology project: Mix well: • Well defined set of functional specifications • Understanding of the non-functional requirements • Common elements from the platform • Accepted development practices JavaOne, San Francisco 2015 5 Specs & Requirements What do we Build? Image from: http://www.cockpitseeker.com/aircraft/ JavaOne, San Francisco 2015 6 High-Level System Requirements • Security - Access control checking inside common containers like JavaEE and Spring. • Authentication - May use both simple and complex protocols. • Authorization - Use standards-based access control methodologies. • Administration - Policy usage is managed by delegation policies. • Audit - Record of operations inside persistent data store. • Service-based SLA - Maintain service level agreements for security, performance, and reliability. JavaOne, San Francisco 2015 7 Why Use Functional Specifications? • Saves the trouble (and risk) of deciding ‘what’ to do. • Instead we get to focus on ‘how’ to do it. • Difference between being handed a blank sheet of paper or a coloring book. -
Installation Guide
Installation Guide Apache Roller Weblogger Version 5.0.1 June 2012 Table of Contents 1 Overview...........................................................................................................................................................4 1.1 Copyright and trademark information....................................................................................................... 4 1.2 Feedback.................................................................................................................................................... 4 1.3 Acknowledgments......................................................................................................................................4 1.4 Modifications and Updates........................................................................................................................ 4 2 Securing Roller.................................................................................................................................................5 3 Ready to roll?................................................................................................................................................... 6 4 Download and un-package Roller.................................................................................................................. 7 4.1 Installation directory layout....................................................................................................................... 7 5 Prepare your database for Roller...................................................................................................................8 -
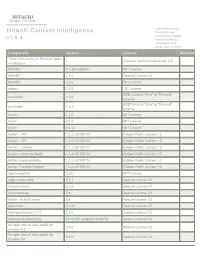
HCI OSS Licenses V1.6.4.Pdf
HITACHI Inspire the Next 2535 Augustine Drive Santa Clara, CA 95054 USA Contact Information : Hitachi Content Intelligence Product Manager Lumada Data Catalog v 1 . 6 . 4 Hitachi Vantara LLC 2535 Augustine Dr. Santa Clara CA 95054 Component Version License Modified "Java Concurrency in Practice" book 1 Creative Commons Attribution 2.5 annotations #NAME? 0.1.38-webpack MIT License #NAME? 2.3.0 Apache License 2.0 #NAME? 3.3.0 MIT License abbrev 1.0.9 ISC License BSD 3-clause "New" or "Revised" ace-builds 1.2.8 License BSD 3-clause "New" or "Revised" ace-builds 1.3.3 License Acorn 1.2.2 MIT License Acorn 2.7.0 MIT License Acorn 4.0.13 MIT License Aether :: API 1.0.2.v20150114 Eclipse Public License 1.0 Aether :: SPI 1.0.2.v20150114 Eclipse Public License 1.0 Aether :: Utilities 1.0.2.v20150114 Eclipse Public License 1.0 Aether Connector Basic 1.0.2.v20150114 Eclipse Public License 1.0 Aether Implementation 1.0.2.v20150114 Eclipse Public License 1.0 Aether Transport Wagon 1.0.2.v20150114 Eclipse Public License 1.0 agentkeepalive 2.2.0 MIT License aggs-matrix-stats 5.3.1 Apache License 2.0 airbnb/chronos 2.3.3 Apache License 2.0 aircompressor 0.8 Apache License 2.0 Airline - io.airlift:airline 0.6 Apache License 2.0 akka-actor 2.3.16 Apache License 2.0 akka-persistence_2.11 2.5.5 Apache License 2.0 alibaba/x-deeplearning 20181224-snapshot-ffc8b733 Apache License 2.0 An open source Java toolkit for 0.9.0 Apache License 2.0 Amazon S3 An open source Java toolkit for 0.9.4 Apache License 2.0 Amazon S3 HITACHI Inspire the Next 2535 Augustine Drive -

Lumada Data Catalog Product Manager Lumada Data Catalog V 6
HITACHI Inspire the Next 2535 Augustine Drive Santa Clara, CA 95054 USA Contact Information : Lumada Data Catalog Product Manager Lumada Data Catalog v 6 . 0 . 0 Hitachi Vantara LLC 2535 Augustine Dr. Santa Clara CA 95054 Component Version License Modified "Java Concurrency in Practice" book 1 Creative Commons Attribution 2.5 annotations BSD 3-clause "New" or "Revised" abego TreeLayout Core 1.0.1 License ActiveMQ Artemis JMS Client All 2.9.0 Apache License 2.0 Aliyun Message and Notification 1.1.8.8 Apache License 2.0 Service SDK for Java An open source Java toolkit for 0.9.0 Apache License 2.0 Amazon S3 Annotations for Metrics 3.1.0 Apache License 2.0 ANTLR 2.7.2 ANTLR Software Rights Notice ANTLR 2.7.7 ANTLR Software Rights Notice BSD 3-clause "New" or "Revised" ANTLR 4.5.3 License BSD 3-clause "New" or "Revised" ANTLR 4.7.1 License ANTLR 4.7.1 MIT License BSD 3-clause "New" or "Revised" ANTLR 4 Tool 4.5.3 License AOP Alliance (Java/J2EE AOP 1 Public Domain standard) Aopalliance Version 1.0 Repackaged 2.5.0 Eclipse Public License 2.0 As A Module Aopalliance Version 1.0 Repackaged Common Development and 2.5.0-b05 As A Module Distribution License 1.1 Aopalliance Version 1.0 Repackaged 2.6.0 Eclipse Public License 2.0 As A Module Apache Atlas Common 1.1.0 Apache License 2.0 Apache Atlas Integration 1.1.0 Apache License 2.0 Apache Atlas Typesystem 0.8.4 Apache License 2.0 Apache Avro 1.7.4 Apache License 2.0 Apache Avro 1.7.6 Apache License 2.0 Apache Avro 1.7.6-cdh5.3.3 Apache License 2.0 Apache Avro 1.7.7 Apache License 2.0 HITACHI Inspire -

Installation Guide
Installation Guide Table of Contents 1. Overview . 1 1.1. Copyright and trademark information . 1 1.2. Feedback . 2 1.3. Acknowledgments . 2 2. Securing Roller . 2 3. Ready to roll?. 3 4. Download and un-package Roller . 4 4.1. Installation directory layout . 4 5. Prepare your database for Roller . 4 5.1. Create a database for Roller . 4 5.2. MySQL and Oracle considerations . 6 6. Deploy Roller to Tomcat . 6 6.1. Tomcat: Create Roller Configuration File . 6 6.2. Using Server-provided database & mail resources (optional) . 9 6.3. Tomcat: Add JDBC Driver and JavaMail API Files. 12 6.4. Tomcat: Set URI Encoding. 12 6.5. Tomcat: Deploy Roller . 13 7. Getting started with Roller. 14 7.1. Navigate to Roller and finish the install . 14 7.2. Register a user and create a weblog. 15 8. Configuration tips and tricks. 16 8.1. Setting up Roller’s Planet feed aggregator . 16 8.2. Manual table creation and upgrade. 17 9. Upgrading Roller . 18 9.1. Backup your old Roller . 18 9.2. Install and startup the new Roller . 19 1. Overview This document describes how to install the Apache Roller Weblogger software. It explains what you need to install first, how to download Roller, how to configure Roller and how to install it to your existing Java application server and relational database. 1.1. Copyright and trademark information The contents of this document are subject to the terms of the Apache Software License. 1 All trademarks within this document belong to legitimate owners. 1.2. -

Reference Guide
Apache Syncope - Reference Guide Version 2.0.16 Table of Contents 1. Introduction. 2 1.1. Identity Technologies. 2 1.1.1. Identity Stores . 2 1.1.2. Provisioning Engines . 4 1.1.3. Access Managers . 5 1.1.4. The Complete Picture . 5 2. Architecture. 7 2.1. Core . 7 2.1.1. REST . 7 2.1.2. Logic . 8 2.1.3. Provisioning . 8 2.1.4. Workflow. 9 2.1.5. Persistence . 9 2.1.6. Security . 9 2.2. Admin UI. 10 2.2.1. Accessibility . 10 2.3. End-user UI. 12 2.3.1. Accessibility . 12 2.4. CLI . 14 2.5. Third Party Applications. 14 2.5.1. Eclipse IDE Plugin . 14 2.5.2. Netbeans IDE Plugin. 14 3. Concepts . 15 3.1. Users, Groups and Any Objects . 15 3.1.1. Password Reset . 16 3.2. Type Management . 17 3.2.1. Schema . 17 Plain . 17 Derived . 18 Virtual . 18 3.2.2. AnyTypeClass . 19 3.2.3. AnyType . 19 3.2.4. RelationshipType . 21 3.2.5. Type Extensions . 22 3.3. External Resources. 23 3.3.1. Connector Bundles . 24 3.3.2. Connector Instance details . 24 3.3.3. External Resource details . 25 3.3.4. Mapping . 26 3.4. Realms . 29 3.4.1. Realm Provisioning . 30 3.4.2. LogicActions . 30 3.5. Entitlements. 30 3.6. Roles. 31 3.6.1. Delegated Administration . 31 3.7. Provisioning. 33 3.7.1. Overview. 33 3.7.2. Propagation . 35 PropagationActions . 37 3.7.3. Pull . .. -

Twister2: a High-Performance Big Data Programming Environment
Twister2: A High-Performance Big Data Programming Environment HPBDC 2018: The 4th IEEE International Workshop on High-Performance Big Data, Deep Learning, anD ClouD Computing Geoffrey Fox, May 21, 2018 Judy Qiu, Supun Kamburugamuve Department of Intelligent Systems Engineering [email protected], http://www.dsc.soic.indiana.edu/, http://spidal.org/ Work with Shantenu Jha, Kannan Govindarajan, `, Pulasthi Wickramasinghe, Gurhan Gunduz, Ahmet Uyar 8/14/18 1 Abstract • We analyse the components that are needed in programming environments for Big Data Analysis Systems with scalable HPC performance and the functionality of ABDS – the Apache Big Data Software Stack. • One highlight is Harp-DAAL which is a machine library exploiting the Intel node library DAAL and HPC communication collectives within the Hadoop ecosystem. • Another highlight is Twister2 which consists of a set of middleware components to support batch or streaming data capabilities familiar from Apache Hadoop, Spark, Heron and Flink but with high performance • Twister2 covers bulk synchronous and data flow communication; task management as in Mesos, Yarn and Kubernetes; dataflow graph execution models; launching of the Harp-DAAL library; streaming and repository data access interfaces, in-memory databases and fault tolerance at dataflow nodes. • Similar capabilities are available in current Apache systems but as integrated packages which do not allow needed customization for different application scenarios. 8/14/18 2 Requirements • On general principles parallel and distributed -

Apache Overview HOWTO Apache Overview HOWTO Table of Contents
Apache Overview HOWTO Apache Overview HOWTO Table of Contents Apache Overview HOWTO...............................................................................................................................1 Daniel Lopez Ridruejo, ridruejo@apache.org.........................................................................................1 1. Introduction..........................................................................................................................................1 2. Apache.................................................................................................................................................1 3. ASF Projects........................................................................................................................................1 4. Where to find more information..........................................................................................................1 5. Contacting the Author..........................................................................................................................2 6. Open Content Open Publication License.............................................................................................2 1. Introduction..........................................................................................................................................2 1.1 Apache Software Foundation.............................................................................................................2 1.2 Structure of this document.................................................................................................................2 -

Release Notes for Red Hat Fuse 7.7
Red Hat Fuse 7.7 Release Notes for Red Hat Fuse 7.7 What's new in Red Hat Fuse Last Updated: 2021-07-27 Red Hat Fuse 7.7 Release Notes for Red Hat Fuse 7.7 What's new in Red Hat Fuse Legal Notice Copyright © 2021 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent.