Using Web Speech Technology with Language Learning Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Amazon Silk Developer Guide Amazon Silk Developer Guide
Amazon Silk Developer Guide Amazon Silk Developer Guide Amazon Silk: Developer Guide Copyright © 2015 Amazon Web Services, Inc. and/or its affiliates. All rights reserved. The following are trademarks of Amazon Web Services, Inc.: Amazon, Amazon Web Services Design, AWS, Amazon CloudFront, AWS CloudTrail, AWS CodeDeploy, Amazon Cognito, Amazon DevPay, DynamoDB, ElastiCache, Amazon EC2, Amazon Elastic Compute Cloud, Amazon Glacier, Amazon Kinesis, Kindle, Kindle Fire, AWS Marketplace Design, Mechanical Turk, Amazon Redshift, Amazon Route 53, Amazon S3, Amazon VPC, and Amazon WorkDocs. In addition, Amazon.com graphics, logos, page headers, button icons, scripts, and service names are trademarks, or trade dress of Amazon in the U.S. and/or other countries. Amazon©s trademarks and trade dress may not be used in connection with any product or service that is not Amazon©s, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. AWS documentation posted on the Alpha server is for internal testing and review purposes only. It is not intended for external customers. Amazon Silk Developer Guide Table of Contents What Is Amazon Silk? .................................................................................................................... 1 Split Browser Architecture ...................................................................................................... -

Lecture 6: Dynamic Web Pages Lecture 6: Dynamic Web Pages Mechanics • Project Preferences Due • Assignment 1 out • Prelab for Next Week Is Non-Trivial
Lecture 6: Dynamic Web Pages Lecture 6: Dynamic Web Pages Mechanics • Project preferences due • Assignment 1 out • PreLab for next week is non-trivial 1/31/2020 2 Lecture 5: JavaScript JavaScript has its Quirks • Procedural, Functional and Object-Oriented all at once • Objects are very different from Java/C++ o Newer versions have Java-like classes however • Scoping is different o var versus let or const o Declarations can follow uses o Declarations are optional • Automatic type conversion • Strict versus non-strict equality testing • eval function • Semicolons are optional if unambiguous • Read up on the language (prelab) 1/31/2020 3 Lecture 6: Dynamic Web Pages What is an Interactive Application • How do we want to use JavaScript • What does interactive mean • What does it do when you interact o Check inputs, compute next page o Change the page without getting a new page 1/30/2020 4 Lecture 6: Dynamic Web Pages Dynamic Web Page Examples • http://bdognom.cs.brown.edu:5000/ (spheree) • http://conifer.cs.brown.edu/s6 (s6) • http://conifer.cs.brown.edu:8888 (twitter) • http://fred4.cs.brown.edu:8800/ (sign) 1/23/2020 5 Lecture 6: Dynamic Web Pages Interactive Applications • Respond to user inputs • Change the display (e.g. add fields, show errors, …) • Dynamically check and verify inputs • Allow direct manipulation (drag and drop) • Use animation to highlight or emphasize or show things • Display external changes in real time • Provide input help (e.g. text completion) • Handle dynamic resizing of the display 1/23/2020 6 Lecture 6: Dynamic Web Pages Achieving Interactivity • Using CSS • Handling HTML events using JavaScript o Dynamically check and verify inputs o Handle direct manipulation • With modern HTML features • With animation/drawing/multimedia packages • By talking to the server continually • Displaying external changes in real time • Changing styles and the content of the page o Change the display (e.g. -

Advanced HTML5 and CSS3 Specialist Exam 1D0-620
Advanced HTML5 And CSS3 Specialist Exam 1D0-620 Domain 1: HTML5 Essentials 1.1 Consider HTML5 development skills you can apply to both traditional and non-traditional delivery platforms, including mobile apps. 1.2 Identify the Web development trifecta and explain its significance. 1.3 Explain the evolution of HTML and its relevance to modern design techniques. 1.4 Create and deploy HTML5 structure tags. 1.5 Perform HTML5 code validation, which includes explaining the practical value of code validation and listing the steps to validate HTML5 code. 1.6 Explain the importance of universal markup creation. 1.7 Apply the HTML5 <video> element appropriately. 1.8 Use the HTML5 <audio> element. 1.9 Define common elements of HTML5 application programming interfaces (APIs). Domain 2: Using Cascading Style Sheets (CSS) Technology 2.1 Explain the function and purpose of the Cascading Style Sheets (CSS) technology. 2.2 Explain the importance of using style guides when designing sites and documents. 2.3 Define common CSS terms and syntax. 2.4 Apply CSS styles to format pages. 2.5 Develop and apply page layouts with CSS. 2.6 Use CSS to position content and apply document flow. 2.7 Define common CSS positioning schemes. 2.8 Use the CSS Box Model. Domain 3: Introduction to CSS Version 3 (CSS3) 3.1 List the features added to CSS functionality in CSS version 3 (CSS3). 3.2 Apply common CSS3 properties and selectors. 3.3 Apply backgrounds and borders with CSS3. 3.4 Apply fonts and text effects with CSS3. Certification Partners, LLC - 1.800.228.1027 - 1.602.275.7700 www.CIWcertified.com - www.Certification-Partners.com Domain 4: Using Advanced CSS3 Techniques 4.1 Apply 2D and 3D transformations with CSS3. -

What About Sharepoint?
HTML5 & CSS3 ( What about SharePoint? ) presented by @kyleschaeffer The Agenda . HTML5 – What is it? – What can it do? – Does SharePoint do HTML5? . CSS3 – What is it? – What can it do? – Does SharePoint do CSS3? HTML5 evolution, not revolution. How we got here. Tim Berners-Lee Revolution! Revolution! World’s first web server We need layout! We need web (HTML) HTML4 applications! Language based on XHTML HTML5 SGML CSS2 CSS3 ? AJAX Invention of the web Revolution! application (XHTML2) We need standards! HTML2 HTML3 CSS HTML5 . Evolution of features, not language The language is the same (HTML4 is valid HTML5) New features are primarily rich media, web applications, forms, and semantics Targets “annoying” things (form validation, input types, audio, video, vector graphics, etc.) . When will it be ready? When will it be ready? Ian Hickson: “Proposed recommendation in 2022” Getting started: Using HTML5 today. Using HTML5 today. DOCTYPE declarations <!DOCTYPE HTML PUBLIC "- //W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/l oose.dtd"> Using HTML5 today. DOCTYPE declarations <!DOCTYPE html PUBLIC "- //W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/ DTD/xhtml1-transitional.dtd"> Using HTML5 today. DOCTYPE declarations <!DOCTYPE html> HTML5 & keeping it simple. <img src="foo.png" alt="Foo!" /> -VS- <img src="foo.png" alt="Foo!"> HTML5 & keeping it simple. <input type="checkbox" checked="checked" /> -VS- <input type="checkbox" checked> HTML5 features. Rich Media <audio> & <video> <canvas> <svg> . Forms New <input> types Input validation & form enhancements . Semantics HTML5 features. Web Applications Local & session storage Offline applications Drag & drop WebSQL Geolocation Touch HTML5 <audio> and <video>. -

HTML5 Canvas
HTML5 Canvas HTML5 Canvas Native Interactivity and Animation for the Web Steve Fulton and Jeff Fulton Beijing • Cambridge • Farnham • Köln • Sebastopol • Tokyo HTML5 Canvas by Steve Fulton and Jeff Fulton Copyright © 2011 8bitrocket Studios. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://my.safaribooksonline.com). For more information, contact our corporate/institutional sales department: (800) 998-9938 or [email protected]. Editors: Mike Loukides and Simon St.Laurent Indexer: Ellen Troutman Zaig Production Editor: Kristen Borg Cover Designer: Karen Montgomery Copyeditor: Marlowe Shaeffer Interior Designer: David Futato Proofreader: Sada Preisch Illustrator: Robert Romano Printing History: May 2011: First Edition. Nutshell Handbook, the Nutshell Handbook logo, and the O’Reilly logo are registered trademarks of O’Reilly Media, Inc. HTML5 Canvas, the image of a kaka parrot, and related trade dress are trademarks of O’Reilly Media, Inc. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and O’Reilly Media, Inc., was aware of a trademark claim, the designations have been printed in caps or initial caps. While every precaution has been taken in the preparation of this book, the publisher and authors assume no responsibility for errors or omissions, or for damages resulting from the use of the information con- tained herein. ISBN: 978-1-449-39390-8 [LSI] 1303735727 To Flash. -

Video - Dive Into HTML5
Video - Dive Into HTML5 You are here: Home ‣ Dive Into HTML5 ‣ Video on the Web ❧ Diving In nyone who has visited YouTube.com in the past four years knows that you can embed video in a web page. But prior to HTML5, there was no standards- based way to do this. Virtually all the video you’ve ever watched “on the web” has been funneled through a third-party plugin — maybe QuickTime, maybe RealPlayer, maybe Flash. (YouTube uses Flash.) These plugins integrate with your browser well enough that you may not even be aware that you’re using them. That is, until you try to watch a video on a platform that doesn’t support that plugin. HTML5 defines a standard way to embed video in a web page, using a <video> element. Support for the <video> element is still evolving, which is a polite way of saying it doesn’t work yet. At least, it doesn’t work everywhere. But don’t despair! There are alternatives and fallbacks and options galore. <video> element support IE Firefox Safari Chrome Opera iPhone Android 9.0+ 3.5+ 3.0+ 3.0+ 10.5+ 1.0+ 2.0+ But support for the <video> element itself is really only a small part of the story. Before we can talk about HTML5 video, you first need to understand a little about video itself. (If you know about video already, you can skip ahead to What Works on the Web.) ❧ http://diveintohtml5.org/video.html (1 of 50) [6/8/2011 6:36:23 PM] Video - Dive Into HTML5 Video Containers You may think of video files as “AVI files” or “MP4 files.” In reality, “AVI” and “MP4″ are just container formats. -

HTML5 Audio 1 HTML5 Audio
HTML5 Audio 1 HTML5 Audio HTML • HTML and HTML5; HTML editor • Dynamic HTML • XHTML • XHTML Basic (Mobile) • XHTML Mobile Profile and C-HTML • HTML element • Span and div • HTML attribute • Character encodings; Unicode • Language code • Document Object Model • Browser Object Model • Style sheets and CSS • Font family and Web colors • HTML scripting and JavaScript • W3C, WHATWG, and validator • Quirks mode • HTML Frames • HTML5 Canvas, WebGL, and WebCL • HTML5 Audio and HTML5 video • Web storage • Web browser (layout) engine • Comparison of • document markup languages • web browsers • layout engine support for • HTML; Non-standard HTML • XHTML (1.1) • HTML5; HTML5 canvas, • HTML5 media (Audio, Video) • v • t [1] • e HTML5 Audio is a subject of the HTML5 specification, investigating audio input, playback, synthesis, as well as speech to text in the browser. HTML5 Audio 2 <audio> element The <audio> element represents a sound, or an audio stream.[2] It is commonly used to play back a single audio file within a web page, showing a GUI widget with play/pause/volume controls. Supported browsers • PC • Google Chrome • Internet Explorer 9 • Mozilla Firefox 3.5 • Opera 10.5 • Safari 3.1[3] • Mobile • Android Browser 2.3 • Blackberry Browser • Google Chrome for Android • Internet Explorer Mobile 9 • Mobile Safari 4 • Mozilla Firefox for Android • Opera Mobile 11 • Tizen Supported audio codecs This table documents the current support for audio codecs by the <audio> element. Browser Operating Formats supported by different web browsers system Ogg -

HTML5 for Mobile Application Development: Developing HTML5 Mobile Applications
"Charting the Course ... ... to Your Success!" HTML5 for Mobile Application Development: Developing HTML5 Mobile Applications Course Summary Description HTML5 for Mobile Application Development is a fast‐paced, hands‐on class that immerses attending students right into practical lab application using the latest industry development trends and best practices. Students will explore the new HTML5 structural, semantic, and form tags, how to use Canvas to create drawings natively in the browser, how to work with HTML5 audio and video, the new methods for storing variables client‐side, and how to build applications that work offline. Developers will also learn about the current state of browser support for HTML5 and the theory behind all the recent updates and changes in the technology. Objectives By the end of this course, students will: Learn how to start building HTML5 pages today. Learn the major benefits of HTML5. Understand the difference between HTML5 and HTML 4. Become familiar with HTML5's new elements and attributes. Learn to work with audio and video in HTML5. Learn to work with HTML5's new Canvas element to create code‐based drawings. Learn to use Web Storage for offline applications. Learn to use all the cool new HTML5 form elements. Learn the current state of browser support for HTML5 and how to make your HTML5 sites degrade gracefully. Topics Laying out a Page with HTML5 Integrated APIs - MMRS Focus, understand Sections and Articles more of it. HTML5 Audio and Video HTML5 Web Sockets HTML5 Forms HTML5 Web Workers HTML5 Web Storage HTML5 Geolocation HTML5 Canvas JQuery Overview iOS and Android Demo Audience This is an intermediate level course designed for experienced HTML Developers. -

A Practical Guide to HTML5
Using HTML5 A Practical Guide A Practical Guide to HTML5 Atlogys Academy @atlogys Latest trends and innovations in web and mobile technology www.atlogys.com/tips Guides, Tutorials, advice on best practices, standards, Do’s and Don’ts. blog.atlogys.com Practical Notes on getting *Good* software development. Contact Details: Contact: E-mail: Address: (+91) 11 26475155 [email protected] R-8, Nehru Enclave, New Delhi – 110019, India Copyright© Automated Logical Software Pvt. Ltd. All Rights Reserved Table of Contents C H A P T E R 1 INTRODUCTION TO H T M L 5 HTML5: Why do we need it? HTML5 Elements: What’s new and who’s in the family? C H A P T E R 2 STRUCTURING PAGES IS N O W E A S I E R The New Semantic Elements: Structural Elements Block Elements Inline Elements Structuring for search visibility: Google Rich Snippets Resources CHAPTER 3 REDEFINED WEB FORMS New Types of Input New Elements Resources CHAPTER 4 AUDIO AND VIDEO Audio in HTML5: Long due upgrade Open source HTML5 audio players Video in HTML5: Can we bid Flash Farewell? Open source HTML5 video players. Additional Resources CHAPTER 5 T H E C A N V A S ELEMENT : WITH CSS3 AND JAVA SCRIPT What is Canvas? Graphic and Games in Canvas Picture Galleries Presentation in Canvas Cool Canvas Use Three.js Additional Resources C H A P T E R 6 WEB STORAGE Web Storage Basics Deeper into Web Storage Reading Files C H A P T E R 7 OFFLINE APPLICATIONS Caching Files with a Manifest Practical Caching Techniques C H A P T E R 8 ENHANCED COMMUNICATI ON WITH THE WEB SERV ER Sending Messages to the Web Server Server-Sent Events Web Sockets C H A P T E R 9 MORE COOL JAVASCRIPT TRICKS Geolocation Web Workers History Management Pdf.js CHAPTER 10 START PLAYING APPENDIX I Browser usage Checking for features Modernizr ABOUT ATLOGYS Who are We? What We Do? Note The World Wide Web Consortium (W3C) has recently announced that the upcoming version of HTML will not be referred to as HTML5 but, as HTML. -

Take a Dive Into HTML5
Paper 2670-2018 Take a Dive into HTML5 Brandon George and Nathan Bernicchi, Grand Valley State University and Spectrum Health Office of Research Administration; Paul Egeler, Spectrum Health Office of Research Administration ABSTRACT The SAS® Output Delivery System (ODS) provides several options to save and display SAS graphs and tables. You are likely familiar with some of these ODS statements already, such as ODS RTF for rich text format, ODS PDF for portable document format, and ODS HTML for hypertext markup language. New to SAS 9.4, users have several additional ODS statements to choose from; among them is ODS HTML5. The ODS HTML5 statement differs from ODS HTML in that it uses HTML version 5.0 instead of HTML version 4.01. As such, the user can now take advantage of several new features introduced to the language. ODS HTML5 also uses a different default graphics output device, trading out the old standby portable network graphics (PNG) for the up-and-coming scalable vector graphics format (SVG). Throughout the paper, we will look at some of the differences between ODS HTML and ODS HTML5, with a focus on computer graphics. The paper also begins with a short primer on technologies such as HTML, CSS, and computer graphics. We will also demonstrate a few ways that you can enhance your reports using some ODS tricks. Our goal is to convince you to switch to ODS HTML5 and start using SVG as your graphical output of choice. INTRODUCTION In SAS®, you have numerous options for how to output your graphs and tables. -

Using HTML5 for Games
Chapter 1 Gaming on the Web in this chapter ❍ Figuring out what HTML5 is and where it came from ❍ Seeing HTML5 in the context of games ❍ Looking at important new features ❍ Enabling feature detection and dealing with legacy browsers COPYRIGHTED MATERIAL 005_9781119975083-ch01.indd5_9781119975083-ch01.indd 7 111/16/111/16/11 77:57:57 PPMM 8 HTML5 GAMES CREATING FUN WITH HTML5, CSS3, AND WEBGL BEFORE I DIVE into code, I want to establish the context of the technology we use. In this fi rst chapter, I discuss what HTML5 is as well as some of the history that led to the HTML5 specifi cation. One of the most interesting aspects of HTML5 is how game developers can profi t from many of the new features. In this chapter, I introduce some of these features and give a few quick examples of how they are used. I talk about the canvas element and WebGL and the huge improvements these additions make in terms of our ability to create dynamic graphics. I also cover the audio element and the added multiplayer possibilities created by the WebSockets specifi cation. Everybody likes new toys, but we mustn’t forget that in the real world, old and outdated browsers keep many users from using these bleeding-edge features. In this chapter, I show a few helpful tools for detecting which features you can safely use as well as how you can use these feature tests to load appropriate fallback solutions when necessary. Finally, I briefl y introduce the puzzle game that I use throughout the rest of the book to take you through the creation of a complete HTML5 game. -
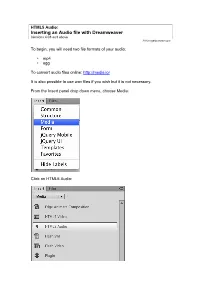
Inserting an Audio File with Dreamweaver Versions CS6 and Above 2013 Nigelbuckner.Com
HTML5 Audio: Inserting an Audio file with Dreamweaver Versions CS6 and above 2013 nigelbuckner.com To begin, you will need two file formats of your audio: • mp4 • ogg To convert audio files online: http://media.io/ It is also possible to use wav files if you wish but it is not necessary. From the Insert panel drop down menu, choose Media: Click on HTML5 Audio: An audio icon will appear in the Design view and the <audio> tag will be entered into the code: Insert the audio files. Do this from the Properties panel at the base of the screen. In order to see the correct content in the Properties you may need to click away from the audio icon and then select it again or place the cursor in the audio tag. The audio files can be inserted from the Source field. The Source is the primary or best quality audio, generally an mp3 file. Selecting the primary source video should auto complete the Alt Source entries as well. Source 1 and 2 are optional audio files in case the primary source does not play. The other options are ogg and wav files. The code will now look like this: Choose Live view and the audio control will appear in the page but not play. Preview in a browser to play the audio. There are no options in the Properties panel to alter the width of the audio control. This needs to be done with a CSS rule. Exit live view to continue editing. Enter text in the Fallback Text field to the effect of “Your browser does not support HTML5 audio”.