Impact of Driving Behavior on Commuter's Comfort During Cab
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lenovo K6 POWER Quick Start Guide Lenovo K33a42
Lenovo K6 POWER Quick Start Guide Lenovo K33a42 English/Česky/Slovenščina/Tiếng Việt Contents English.............................................................................1 Česky............................................................................ 13 Slovenščina...................................................................25 Tiếng Việt...................................................................... 38 English Reading this guide carefully before using your smartphone. Reading first — regulatory information Be sure to read the Regulatory Notice for your country or region before using the wireless devices contained in your Lenovo Mobile Phone. To obtain a PDF version of the Regulatory Notice, see the “Downloading publications” section. Some regulatory information is also available in Settings > About phone > Regulatory information on your smartphone. Getting support To get support on network service and billing, contact your wireless network operator. To learn how to use your smartphone and view its technical specifications, go to http://support.lenovo.com. Downloading publications To obtain the latest smartphone manuals, go to: http://support.lenovo.com Accessing your User Guide Your User Guide contains detailed information about your smartphone. To access your User Guide, go to http://support.lenovo.com and follow the instructions on the screen. Legal notices Lenovo and the Lenovo logo are trademarks of Lenovo in the United States, other countries, or both. Other company, product, or service names may be trademarks -
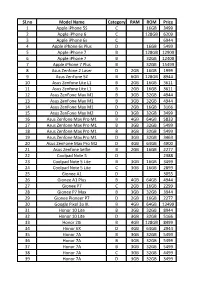
Sl.No Model Name Category RAM ROM Price 1 Apple Iphone 5S C
Sl.no Model Name Category RAM ROM Price 1 Apple iPhone 5S C 16GB 3499 2 Apple iPhone 6 C 128GB 6209 3 Apple iPhone 6s C 6944 4 Apple iPhone 6s Plus D 16GB 5499 5 Apple iPhone 7 B 128GB 12900 6 Apple iPhone 7 B 32GB 12400 7 Apple iPhone 7 Plus B 32GB 15499 8 Asus Zenfone 2 Laser D 2GB 16GB 1999 9 Asus ZenFone 5Z B 6GB 128GB 8944 10 Asus Zenfone Lite L1 B 2GB 16GB 3611 11 Asus Zenfone Lite L1 B 2GB 16GB 3611 12 Asus ZenFone Max M1 B 3GB 32GB 4944 13 Asus ZenFone Max M1 B 3GB 32GB 4944 14 Asus ZenFone Max M1 D 2GB 16GB 3166 15 Asus ZenFone Max M2 D 3GB 32GB 3499 16 Asus Zenfone Max Pro M1 B 4GB 64GB 5833 17 Asus Zenfone Max Pro M1 B 3GB 32GB 5499 18 Asus Zenfone Max Pro M1 B 3GB 32GB 5499 19 Asus Zenfone Max Pro M1 D 3GB 32GB 3463 20 Asus ZenFone Max Pro M2 D 4GB 64GB 4900 21 Asus Zenfone Selfie B 2GB 16GB 2277 22 Coolpad Note 5 D 2388 23 Coolpad Note 5 Lite B 3GB 16GB 3499 24 Coolpad Note 5 Lite C 3GB 16GB 2899 25 Gionee A1 D 3055 26 Gionee A1 Plus B 4GB 64GB 4944 27 Gionee P7 C 2GB 16GB 2299 28 Gionee P7 Max B 3GB 32GB 3944 29 Gionee Pioneer P7 D 2GB 16GB 2277 30 Google Pixel 3a XL B 4GB 64GB 13499 31 Honor 10 Lite B 3GB 32GB 8944 32 Honor 10 Lite D 3GB 32GB 5166 33 Honor 20i B 4GB 128GB 8499 34 Honor 6X D 4GB 64GB 2944 35 Honor 7A B 3GB 32GB 5499 36 Honor 7A B 3GB 32GB 5499 37 Honor 7A B 3GB 32GB 5499 38 Honor 7A C 3GB 32GB 4499 39 Honor 7A D 3GB 32GB 3499 40 Honor 7C B 3GB 32GB 5499 41 Honor 7C C 3GB 32GB 4499 42 Honor 7C D 3GB 32GB 3499 43 Honor 7s B 2GB 16GB 4944 44 Honor 7s B 2GB 16GB 4944 45 Honor 7s B 2GB 16GB 4944 46 Honor 7X D -

Phone Compatibility
Phone Compatibility • Compatible with iPhone models 4S and above using iOS versions 7 or higher. Last Updated: February 14, 2017 • Compatible with phone models using Android versions 4.1 (Jelly Bean) or higher, and that have the following four sensors: Accelerometer, Gyroscope, Magnetometer, GPS/Location Services. • Phone compatibility information is provided by phone manufacturers and third-party sources. While every attempt is made to ensure the accuracy of this information, this list should only be used as a guide. As phones are consistently introduced to market, this list may not be all inclusive and will be updated as new information is received. Please check your phone for the required sensors and operating system. Brand Phone Compatible Non-Compatible Acer Acer Iconia Talk S • Acer Acer Jade Primo • Acer Acer Liquid E3 • Acer Acer Liquid E600 • Acer Acer Liquid E700 • Acer Acer Liquid Jade • Acer Acer Liquid Jade 2 • Acer Acer Liquid Jade Primo • Acer Acer Liquid Jade S • Acer Acer Liquid Jade Z • Acer Acer Liquid M220 • Acer Acer Liquid S1 • Acer Acer Liquid S2 • Acer Acer Liquid X1 • Acer Acer Liquid X2 • Acer Acer Liquid Z200 • Acer Acer Liquid Z220 • Acer Acer Liquid Z3 • Acer Acer Liquid Z4 • Acer Acer Liquid Z410 • Acer Acer Liquid Z5 • Acer Acer Liquid Z500 • Acer Acer Liquid Z520 • Acer Acer Liquid Z6 • Acer Acer Liquid Z6 Plus • Acer Acer Liquid Zest • Acer Acer Liquid Zest Plus • Acer Acer Predator 8 • Alcatel Alcatel Fierce • Alcatel Alcatel Fierce 4 • Alcatel Alcatel Flash Plus 2 • Alcatel Alcatel Go Play • Alcatel Alcatel Idol 4 • Alcatel Alcatel Idol 4s • Alcatel Alcatel One Touch Fire C • Alcatel Alcatel One Touch Fire E • Alcatel Alcatel One Touch Fire S • 1 Phone Compatibility • Compatible with iPhone models 4S and above using iOS versions 7 or higher. -

Brand Old Device
# New Device Old Device - Brand Old Device - Model Name 1 Galaxy A6+ Asus Asus Zenfone 2 Laser ZE500KL 2 Galaxy A6+ Asus Asus Zenfone 2 Laser ZE601KL 3 Galaxy A6+ Asus Asus ZenFone 2 ZE550ML 4 Galaxy A6+ Asus Asus Zenfone 2 ZE551ML 5 Galaxy A6+ Asus Asus Zenfone 3 Laser 6 Galaxy A6+ Asus Asus Zenfone 3 Max ZC520TL 7 Galaxy A6+ Asus Asus Zenfone 3 Max ZC553KL 8 Galaxy A6+ Asus Asus Zenfone 3 ZE520KL 9 Galaxy A6+ Asus Asus Zenfone 3 ZE552KL 10 Galaxy A6+ Asus Asus Zenfone 3s Max 11 Galaxy A6+ Asus Asus Zenfone Max 12 Galaxy A6+ Asus Asus Zenfone Selfie 13 Galaxy A6+ Asus Asus ZenFone Zoom ZX550 14 Galaxy A6+ Gionee Gionee A1 15 Galaxy A6+ Gionee Gionee A1 Lite 16 Galaxy A6+ Gionee Gionee A1 Plus 17 Galaxy A6+ Gionee Gionee Elife E8 18 Galaxy A6+ Gionee Gionee Elife S Plus 19 Galaxy A6+ Gionee Gionee Elife S7 20 Galaxy A6+ Gionee Gionee F103 21 Galaxy A6+ Gionee Gionee F103 Pro 22 Galaxy A6+ Gionee Gionee Marathon M4 23 Galaxy A6+ Gionee Gionee Marathon M5 24 Galaxy A6+ Gionee Gionee marathon M5 Lite 25 Galaxy A6+ Gionee Gionee Marathon M5 Plus 26 Galaxy A6+ Gionee Gionee P5L 27 Galaxy A6+ Gionee Gionee P7 Max 28 Galaxy A6+ Gionee Gionee S6 29 Galaxy A6+ Gionee Gionee S6 Pro 30 Galaxy A6+ Gionee Gionee S6s 31 Galaxy A6+ Gionee Gionee X1s 32 Galaxy A6+ Google Google Pixel 33 Galaxy A6+ Google Google Pixel XL LTE 34 Galaxy A6+ Google Nexus 5X 35 Galaxy A6+ Google Nexus 6 36 Galaxy A6+ Google Nexus 6P 37 Galaxy A6+ HTC Htc 10 38 Galaxy A6+ HTC Htc Desire 10 Pro 39 Galaxy A6+ HTC Htc Desire 628 40 Galaxy A6+ HTC HTC Desire 630 41 Galaxy A6+ -

WSN IMEI NO Model QC Remark RAM ROM Selling Price
WSN IMEI NO Model QC Remark RAM ROM selling price 1779369897 356631055834974 Samsung GALAXY GRAND B 1GB 8GB 1349 1779750677 356631055377891 Samsung GALAXY GRAND B 1GB 8GB 1349 1780735909 867770021734231 VIVO Y15S B 1GB 8GB 1799 0DSZVY_Y 351893083089618 Moto G B 1GB 8GB 1799 1779613552 352532071090068 HTC Desire 828 dual sim B 2GB 16GB 1999 1779980247 911401501039232 YU Yureka B 2GB 16GB 2388 1780349704 867865021529332 Gionee F103 B 2GB 16GB 2499 1779735228 869440021710288 LENOVO A6000 B 2GB 16GB 2499 1779749254 869440025820430 LENOVO A6000 B 2GB 16GB 2499 1780003300 867804021725475 Lenovo A6000 Plus B 2GB 16GB 2499 1779259849 868415022994181 LENOVO A7000 B 2GB 8GB 2499 0EEJHC_M 867249044195118 Nokia 1 B 1GB 8GB 2499 0DMBI5_X 911471700330245 Micromax Canvas 6 Pro E484 B 2GB 16GB 2499 1779382080 861969033511100 Gionee PIONEER P7 B 2GB 16GB 2722 1779753461 359268077664894 Samsung Galaxy J2 B 1GB 8GB 2722 0DPJ09_B Samsung Galaxy J2 B 1GB 8GB 2755 0DSB49_C 353508075659321 Samsung Galaxy J2 B 1GB 8GB 2755 0DQPQA_E 356271077935739 Samsung Galaxy J2 B 1GB 8GB 2755 0DSA8J_S 358974083902563 Samsung Galaxy J2 B 1GB 8GB 2755 0DSFHS_M Samsung Galaxy J2 B 1GB 8GB 2755 0cukfe_m 861794030134593 Lenovo A6600 B 2GB 16GB 2944 0DRLZY_S 353285072052889 Lava Z61 B 2GB 16GB 2944 0DQR27_F 860732038080633 Vivo Y21L B 1GB 16GB 2944 0DQWCA_O 353088112237597 Vivo Y21L B 1GB 16GB 2944 0DRSDY_Q 863881032494295 Vivo Y21L B 1GB 16GB 2944 0DQOHS_M 356042085091165 Nokia 2 B 1GB 8GB 3055 1781181644 352514084809858 Samsung Galaxy On5 Pro B 2GB 16GB 3277 0DRN0Q_S Xiaomi -

Lenovo K33a48 Lenovo K33a42 Kullanma Kılavuzu V1.0 Temel Bilgiler
Lenovo K33a48 Lenovo K33a42 Kullanma Kılavuzu V1.0 Temel bilgiler Bu bilgileri ve desteklediği ürünü kullanmadan önce aşağıdakileri okuduğunuzdan emin olun: Hızlı Başlangıç Kılavuzu Mevzuat Bildirimi Ek Hızlı Başlangıç Kılavuzu ve Mevzuat Bildirimi şu web sitesine yüklenmiştir: http://support.lenovo.com. Lenovo Companion Yardıma mı ihtiyacınız var? Lenovo Companion uygulaması Lenovo’nın web desteğine ve forumlarına*, sıkça sorulan sorulara ve yanıtlarına*, sistem yükseltmelerine*, donanım çalışma testlerine, garanti durumu kontrollerine*, servis taleplerine** ve onarım durumlarına** doğrudan erişebilmeniz için yardıma hazır. Not: * veri ağı erişimi gerektirir. ** her ülkede geçerli değildir. Bu uygulamayı iki şekilde edinebilirsiniz: Uygulamayı Google Play’de aratarak indirin. Aşağıdaki QR kodunu Lenovo Android aygıtınızla taratın. Teknik özellikler Bu bölüm, yalnız kablosuz iletişimle ilgili teknik spesifikasyonları listeler. Telefonunuzun teknik özelliklerinin tam listesi için http://support.lenovo.com adresine gidin. FDD-LTE/TDD-LTE/WCDMA/GSM Not: Bazı ülkelerde LTE desteklenmemektedir. Akıllı telefonunuzun ülkenizdeki Veri LTE ağlarında çalışıp çalışmadığını öğrenmek için operatörünüzle iletişime geçin. Wi-Fi Wi-Fi 802.11 b/g/n Bluetooth Bluetooth 4.2 GPS Desteklenir GLONASSDesteklenir Ekran düğmeleri Telefonunuz üzerinde üç düğme bulunur. Çoklu Görev düğmesi: Menü seçeneklerini görüntülemek için öğesine basılı tutun. Çalışan uygulamaları görmek için Çoklu görev düğmesine dokunun. Ardından şu işlemleri gerçekleştirebilirsiniz: Açmak -

For Patients
User Guide for patients CAUTION--Investigational device. Limited by Federal (or United States) law to investigational use. IMPORTANT USER INFORMATION Review the product instructions before using the Bios device. Instructions can be found in this user manual. Failure to use the Bios device and its components according to the instructions for use and all indications, contraindications, warnings, precautions, and cautions may result in injury associated with misuse of device. Manufacturer information GraphWear Technologies Inc. 953 Indiana Street, San Francisco CA 94107 Website: www.graphwear.co Email: [email protected] 1 Table of Contents Safety Statement 4 Indications for use 4 Contraindication 5 No MRI/CT/Diathermy - MR Unsafe 5 Warnings 5 Read user manual 5 Don’t ignore high/low symptoms 5 Don’t use if… 5 Avoid contact with broken skin 5 Inspect 6 Use as directed 6 Check settings 6 Where to wear 6 Precaution 7 Avoid sunscreen and insect repellant 7 Keep transmitter close to display 7 Is It On? 7 Keep dry 8 Application needs to always remain open 8 Device description 8 Purpose of device 8 What’s in the box 8 Operating information 11 Minimum smart device specifications 11 Android 11 iOS 12 Installing the app 12 Setting up Bios devices 32 Setting up Left Wrist (LW) device 32 Setting up Right Wrist (RW) device 42 Setting up Lower Abdomen (LA) device 52 2 Confirming that all devices are connected 64 Removing the devices 65 Removing the sensors 67 How to charge the transmitter 69 Setting up and using your Self Monitoring Blood Glucose (SMBG) meter 78 Inserting blood values into the application 79 Inserting meal and exercise information 85 Inserting medication information 89 Change sensor 92 Providing feedback 98 Troubleshooting information 101 What messages on your transmitter display mean 101 FAQ? 102 I need to access the FAQ from my app 102 I am unable to install the mobile application on my smart device. -

GIONEE P7: a BUDGET SMARTPHONE — Raj Kumar Maurya Ionee Is One of the Few Chinese Companies in India Those Are Selling Their Phones Offline As Well Online
SMaRTPhONE GIONEE P7: A BUDGET SMARTPHONE — Raj Kumar Maurya ionee is one of the few Chinese companies in India those are selling their phones offline as well online. Gionee is Gknown for its premium segment smartphones with great battery backup & big screen like Gionee Marathon m5. Also the Gionee’s phones are easily available in the market unlike the Xiaomi, Coolpad and some other companies which are mostly available online and are often out of stock. The Gionee P7 price in India is Rs 9,999 and under 10k it going to stand against Price: `9,999/- some most popular budget smartphones in India such as Xiaomi Redmi 3S, Redmi Note 3 &4, Moto G4 Play, Coolpad Note 3S, and Lenovo K6 Power. Gionee P7 Design and Build: The design of Gionee P7 is not SCORE unique but looks attractive little bit due to its glossy panel. The Gionee Price: 7/10 P7 we got for review was gray in color from back side and edges, Performance: 7/10 while the front side is complete in black. The phone completely has a Features: 8/10 good quality plastic body and glossy finished all around. The Glossy panel looks attractive but also prone to fingerprints. The back side is comprised of Camera, LED flash, Gionee’s Logo in a vertical symmetry Overall: 7/10 and speaker grills at the bottom. The back cover is removable, under it back cover you will find SIM tray and microSD card slot. Coming to its front side, it has three capacitive buttons below the display which aren’t backlit. -

Belkasoft Evidence Center X User Reference Contents About
702 San Conrado Terrace, Unit 1 Sunnyvale CA 94085 USA and Canada: +1 650 272 0384 Europe, other regions: +48 663 247 314 Web: https://belkasoft.com Email: [email protected] Belkasoft Evidence Center X User Reference Contents About ............................................................................................................................................... 7 What is this document about? .................................................................................................... 7 Other resources .......................................................................................................................... 7 Legal notes and disclaimers ........................................................................................................ 7 Introduction .................................................................................................................................... 9 What is Belkasoft Evidence Center (Belkasoft X) and who are its users? ................................... 9 Types of tasks Belkasoft X is used for ........................................................................................ 10 Typical Belkasoft X workflow .................................................................................................... 10 Forensically sound software ..................................................................................................... 11 When Belkasoft X uses the Internet ........................................................................................ -

Lenovo K6 POWER Quick Start Guide Lenovo K33a42
Lenovo K6 POWER Quick Start Guide Lenovo K33a42 English/Українська/Русский/Română/ქართული Contents English............................................................................1 Українська.....................................................................13 Русский..........................................................................17 Română..........................................................................22 ქართული....................................................................... 26 English Reading this guide carefully before using your smartphone. Reading first — regulatory information Be sure to read the Regulatory Notice for your country or region before using the wireless devices contained in your Lenovo Mobile Phone. To obtain a PDF version of the Regulatory Notice, see the “Downloading publications” section. Some regulatory information is also available in Settings > About phone > Regulatory information on your smartphone. Getting support To get support on network service and billing, contact your wireless network operator. To learn how to use your smartphone and view its technical specifications, go to http://support.lenovo.com. Downloading publications To obtain the latest smartphone manuals, go to: http://support.lenovo.com Accessing your User Guide Your User Guide contains detailed information about your smartphone. To access your User Guide, go to http://support.lenovo.com and follow the instructions on the screen. Legal notices Lenovo and the Lenovo logo are trademarks of Lenovo in the United States, -

ETUI W Kolorze Czarnym ALCATEL A3
ETUI w kolorze czarnym ALCATEL A3 5.0'' CZARNY ALCATEL PIXI 4 4.0'' 4034A CZARNY ALCATEL PIXI 4 5.0'' 5045X CZARNY ALCATEL POP C3 4033A CZARNY ALCATEL POP C5 5036A CZARNY ALCATEL POP C7 7041X CZARNY ALCATEL POP C9 7047D CZARNY ALCATEL U5 5044D 5044Y CZARNY HTC 10 CZARNY HTC DESIRE 310 CZARNY HTC DESIRE 500 CZARNY HTC DESIRE 516 CZARNY HTC DESIRE 610 CZARNY HTC DESIRE 616 CZARNY HTC DESIRE 626 CZARNY HTC DESIRE 650 CZARNY HTC DESIRE 816 CZARNY HTC ONE A9 CZARNY HTC ONE A9s CZARNY HTC ONE M9 CZARNY HTC U11 CZARNY HUAWEI ASCEND G510 CZARNY HUAWEI ASCEND Y530 CZARNY HUAWEI ASCEND Y600 CZARNY HUAWEI G8 GX8 CZARNY HUAWEI HONOR 4C CZARNY HUAWEI HONOR 6X CZARNY HUAWEI HONOR 7 LITE 5C CZARNY HUAWEI HONOR 8 CZARNY HUAWEI HONOR 9 CZARNY HUAWEI MATE 10 CZARNY HUAWEI MATE 10 LITE CZARNY HUAWEI MATE 10 PRO CZARNY HUAWEI MATE S CZARNY HUAWEI P10 CZARNY HUAWEI P10 LITE CZARNY HUAWEI P10 PLUS CZARNY HUAWEI P8 CZARNY HUAWEI P8 LITE 2017 CZARNY HUAWEI P8 LITE CZARNY HUAWEI P9 CZARNY HUAWEI P9 LITE CZARNY HUAWEI P9 LITE MINI CZARNY HUAWEI Y3 2017 CZARNY HUAWEI Y3 II CZARNY HUAWEI Y5 2017 Y6 2017 CZARNY HUAWEI Y5 Y560 CZARNY HUAWEI Y520 Y540 CZARNY HUAWEI Y541 CZARNY HUAWEI Y6 II CZARNY HUAWEI Y625 CZARNY HUAWEI Y7 CZARNY iPHONE 5C CZARNY iPHONE 5G CZARNY iPHONE 6 4.7'' CZARNY iPHONE 7 4.7'' 8 4.7'' CZARNY iPHONE 7 PLUS 5.5'' 8 PLUS CZARNY iPHONE X A1865 A1901 CZARNY LENOVO K6 NOTE CZARNY LENOVO MOTO C CZARNY LENOVO MOTO C PLUS CZARNY LENOVO MOTO E4 CZARNY LENOVO MOTO E4 PLUS CZARNY LENOVO MOTO G4 XT1622 CZARNY LENOVO VIBE C2 CZARNY LENOVO VIBE K5 CZARNY -

„Kup Laptopa, Odbierz Tablet Za 1 Zł”
REGULAMIN AKCJI PROMOCYJNEJ „Kup laptopa, odbierz tablet za 1 zł” § 1 POSTANOWIENIA OGÓLNE 1. Organizatorem akcji promocyjnej „Kup laptopa, odbierz tablet za 1 zł” (dalej jako „Akcja Promocyjna”) jest NEONET S.A. z siedzibą we Wrocławiu przy ul. Nyskiej 48A, 50-505 Wrocław, NIP: 895-00-21-311, REGON 930310841, wpisana do rejestru przedsiębiorców KRS przez Sąd Rejonowy dla Wrocławia - Fabrycznej we Wrocławiu VI Wydział Gospodarczy Krajowego Rejestru Sądowego pod nr 0000218498, o kapitale zakładowym wynoszącym 1.251.000,00 złotych, w całości wpłaconym (dalej zwana „Organizatorem”). 2. Akcja Promocyjna organizowana jest w sklepach naziemnych Organizatora i w sklepie internetowym neonet.pl 3. Akcja Promocyjna trwa w okresie: od 26.10.2017 r. do 08.11.2017 r. § 2 ZASADY AKCJI PROMOCYJNEJ 1. Akcja Promocyjna dotyczy sprzedaży w sklepach naziemnych Organizatora, tj. w salonach sprzedaży detalicznej NEONET i w sklepie internetowym www.neonet.pl 2. Akcja Promocyjna dotyczy wyłącznie wybranych modeli laptopów wyszczególnionych w załączniku nr 1. 3. W salonach sprzedaży detalicznej NEONET akcja promocyjna polega na tym, że Klienci dokonujący zakupu wybranych modeli laptopów objętych promocją, otrzymają możliwość zakupu 1 szt. tabletu NAVITEL. W przypadku zamówień złożonych na www.neonet.pl akcja polega na dodaniu do koszyka zakupowego laptopa objętego promocją. Tablet doda się automatycznie do koszyka zakupowego. Wartość koszyka zakupowego obniży się automatycznie. 4. Na jednym dokumencie sprzedaży może się znaleźć maksymalnie 1 Produkt Promocyjny. W przypadku zakupu większej ilości Produktów Promocyjnych należy umieścić je na oddzielnych dokumentach sprzedaży. 5. W przypadku zwrotu towaru do sklepu bez podania przyczyny należy zwrócić wszystkie produkty promocyjne. 6. Promocja nie sumuje się z żadną inną promocją, z wyłączeniem promocji „Kup komputer i odbierz Antivirus G DATA za 1 zł oraz zgarnij 100 zł zniżki na zakup pakietu Office 365 Personal”.