Reflective Embedding of Domain-Specific Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

MANNING Greenwich (74° W
Object Oriented Perl Object Oriented Perl DAMIAN CONWAY MANNING Greenwich (74° w. long.) For electronic browsing and ordering of this and other Manning books, visit http://www.manning.com. The publisher offers discounts on this book when ordered in quantity. For more information, please contact: Special Sales Department Manning Publications Co. 32 Lafayette Place Fax: (203) 661-9018 Greenwich, CT 06830 email: [email protected] ©2000 by Manning Publications Co. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by means electronic, mechanical, photocopying, or otherwise, without prior written permission of the publisher. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in the book, and Manning Publications was aware of a trademark claim, the designations have been printed in initial caps or all caps. Recognizing the importance of preserving what has been written, it is Manning’s policy to have the books we publish printed on acid-free paper, and we exert our best efforts to that end. Library of Congress Cataloging-in-Publication Data Conway, Damian, 1964- Object oriented Perl / Damian Conway. p. cm. includes bibliographical references. ISBN 1-884777-79-1 (alk. paper) 1. Object-oriented programming (Computer science) 2. Perl (Computer program language) I. Title. QA76.64.C639 1999 005.13'3--dc21 99-27793 CIP Manning Publications Co. Copyeditor: Adrianne Harun 32 Lafayette -

A Comparative Study on the Effect of Multiple Inheritance Mechanism in Java, C++, and Python on Complexity and Reusability of Code
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 8, No. 6, 2017 A Comparative Study on the Effect of Multiple Inheritance Mechanism in Java, C++, and Python on Complexity and Reusability of Code Fawzi Albalooshi Amjad Mahmood Department of Computer Science Department of Computer Science University of Bahrain University of Bahrain Kingdom of Bahrain Kingdom of Bahrain Abstract—Two of the fundamental uses of generalization in Booch, there are two problems associated with multiple object-oriented software development are the reusability of code inheritance and they are how to deal with name collisions from and better structuring of the description of objects. Multiple super classes, and how to handle repeated inheritance. He inheritance is one of the important features of object-oriented presents solutions to these two problems. Other researchers [4] methodologies which enables developers to combine concepts and suggest that there is a real need for multiple inheritance for increase the reusability of the resulting software. However, efficient object implementation. They justify their claim multiple inheritance is implemented differently in commonly referring to the lack of multiple subtyping in the ADA 95 used programming languages. In this paper, we use Chidamber revision which was considered as a deficiency that was and Kemerer (CK) metrics to study the complexity and rectified in the newer version [5]. It is clear that multiple reusability of multiple inheritance as implemented in Python, inheritance is a fundamental concept in object-orientation. The Java, and C++. The analysis of results suggests that out of the three languages investigated Python and C++ offer better ability to incorporate multiple inheritance in system design and reusability of software when using multiple inheritance, whereas implementation will better structure the description of objects Java has major deficiencies when implementing multiple modeling, their natural status and enabling further code reuse inheritance resulting in poor structure of objects. -

Mixins and Traits
◦ ◦◦◦ TECHNISCHE UNIVERSITAT¨ MUNCHEN¨ ◦◦◦◦ ◦ ◦ ◦◦◦ ◦◦◦◦ ¨ ¨ ◦ ◦◦ FAKULTAT FUR INFORMATIK Programming Languages Mixins and Traits Dr. Michael Petter Winter 2016/17 What advanced techiques are there besides multiple implementation inheritance? Outline Design Problems Cons of Implementation Inheritance 1 Inheritance vs Aggregation 1 2 (De-)Composition Problems Lack of finegrained Control 2 Inappropriate Hierarchies Inheritance in Detail A Focus on Traits 1 A Model for single inheritance 1 2 Inheritance Calculus with Separation of Composition and Inheritance Expressions Modeling 2 3 Modeling Mixins Trait Calculus Mixins in Languages Traits in Languages 1 (Virtual) Extension Methods 1 Simulating Mixins 2 Squeak 2 Native Mixins Reusability ≡ Inheritance? Codesharing in Object Oriented Systems is often inheritance-centric. Inheritance itself comes in different flavours: I single inheritance I multiple inheritance All flavours of inheritance tackle problems of decomposition and composition The Adventure Game Door ShortDoor LockedDoor canPass(Person p) canOpen(Person p) ? ShortLockedDoor canOpen(Person p) canPass(Person p) The Adventure Game Door <interface>Doorlike canPass(Person p) canOpen(Person p) Short canPass(Person p) Locked canOpen(Person p) ShortLockedDoor ! Aggregation & S.-Inheritance Door must explicitely provide canOpen(Person p) chaining canPass(Person p) Doorlike must anticipate wrappers ) Multiple Inheritance X The Wrapper FileStream SocketStream read() read() write() write() ? SynchRW acquireLock() releaseLock() ! Inappropriate Hierarchies -

BERKELEY LOGO 6.1 Berkeley Logo User Manual
BERKELEY LOGO 6.1 Berkeley Logo User Manual Brian Harvey i Short Contents 1 Introduction :::::::::::::::::::::::::::::::::::::::::: 1 2 Data Structure Primitives::::::::::::::::::::::::::::::: 9 3 Communication :::::::::::::::::::::::::::::::::::::: 19 4 Arithmetic :::::::::::::::::::::::::::::::::::::::::: 29 5 Logical Operations ::::::::::::::::::::::::::::::::::: 35 6 Graphics:::::::::::::::::::::::::::::::::::::::::::: 37 7 Workspace Management ::::::::::::::::::::::::::::::: 49 8 Control Structures :::::::::::::::::::::::::::::::::::: 67 9 Macros ::::::::::::::::::::::::::::::::::::::::::::: 83 10 Error Processing ::::::::::::::::::::::::::::::::::::: 87 11 Special Variables ::::::::::::::::::::::::::::::::::::: 89 12 Internationalization ::::::::::::::::::::::::::::::::::: 93 INDEX :::::::::::::::::::::::::::::::::::::::::::::::: 97 iii Table of Contents 1 Introduction ::::::::::::::::::::::::::::::::::::: 1 1.1 Overview ::::::::::::::::::::::::::::::::::::::::::::::::::::::: 1 1.2 Getter/Setter Variable Syntax :::::::::::::::::::::::::::::::::: 2 1.3 Entering and Leaving Logo ::::::::::::::::::::::::::::::::::::: 5 1.4 Tokenization:::::::::::::::::::::::::::::::::::::::::::::::::::: 6 2 Data Structure Primitives :::::::::::::::::::::: 9 2.1 Constructors ::::::::::::::::::::::::::::::::::::::::::::::::::: 9 word ::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 9 list ::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 9 sentence :::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 9 fput :::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: -

Using Computer Programming As an Effective Complement To
Using Computer Programming as an Effective Complement to Mathematics Education: Experimenting with the Standards for Mathematics Practice in a Multidisciplinary Environment for Teaching and Learning with Technology in the 21st Century By Pavel Solin1 and Eugenio Roanes-Lozano2 1University of Nevada, Reno, 1664 N Virginia St, Reno, NV 89557, USA. Founder and Director of NCLab (http://nclab.com). 2Instituto de Matemática Interdisciplinar & Departamento de Didáctica de las Ciencias Experimentales, Sociales y Matemáticas, Facultad de Educación, Universidad Complutense de Madrid, c/ Rector Royo Villanova s/n, 28040 – Madrid, Spain. [email protected], [email protected] Received: 30 September 2018 Revised: 12 February 2019 DOI: 10.1564/tme_v27.3.03 Many mathematics educators are not aware of a strong 2. KAREL THE ROBOT connection that exists between the education of computer programming and mathematics. The reason may be that they Karel the Robot is a widely used educational have not been exposed to computer programming. This programming language which was introduced by Richard E. connection is worth exploring, given the current trends of Pattis in his 1981 textbook Karel the Robot: A Gentle automation and Industry 4.0. Therefore, in this paper we Introduction to the Art of Computer Programming (Pattis, take a closer look at the Common Core's eight Mathematical 1995). Let us note that Karel the Robot constitutes an Practice Standards. We show how each one of them can be environment related to Turtle Geometry (Abbelson and reinforced through computer programming. The following diSessa, 1981), but is not yet another implementation, as will discussion is virtually independent of the choice of a be detailed below. -
Attachment A
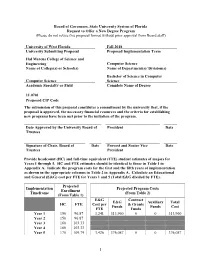
Board of Governors, State University System of Florida Request to Offer a New Degree Program (Please do not revise this proposal format without prior approval from Board staff) University of West Florida Fall 2018 University Submitting Proposal Proposed Implementation Term Hal Marcus College of Science and Engineering Computer Science Name of College(s) or School(s) Name of Department(s)/ Division(s) Bachelor of Science in Computer Computer Science Science Academic Specialty or Field Complete Name of Degree 11.0701 Proposed CIP Code The submission of this proposal constitutes a commitment by the university that, if the proposal is approved, the necessary financial resources and the criteria for establishing new programs have been met prior to the initiation of the program. Date Approved by the University Board of President Date Trustees Signature of Chair, Board of Date Provost and Senior Vice Date Trustees President Provide headcount (HC) and full-time equivalent (FTE) student estimates of majors for Years 1 through 5. HC and FTE estimates should be identical to those in Table 1 in Appendix A. Indicate the program costs for the first and the fifth years of implementation as shown in the appropriate columns in Table 2 in Appendix A. Calculate an Educational and General (E&G) cost per FTE for Years 1 and 5 (Total E&G divided by FTE). Projected Implementation Projected Program Costs Enrollment Timeframe (From Table 2) (From Table 1) E&G Contract E&G Auxiliary Total HC FTE Cost per & Grants Funds Funds Cost FTE Funds Year 1 150 96.87 3,241 313,960 0 0 313,960 Year 2 150 96.87 Year 3 160 103.33 Year 4 160 103.33 Year 5 170 109.79 3,426 376,087 0 0 376,087 1 Note: This outline and the questions pertaining to each section must be reproduced within the body of the proposal to ensure that all sections have been satisfactorily addressed. -

Mixin-Based Programming in C++1
Mixin-Based Programming in C++1 Yannis Smaragdakis Don Batory College of Computing Department of Computer Sciences Georgia Institute of Technology The University of Texas at Austin Atlanta, GA 30332 Austin, Texas 78712 [email protected] [email protected] Abstract. Combinations of C++ features, like inheritance, templates, and class nesting, allow for the expression of powerful component patterns. In particular, research has demonstrated that, using C++ mixin classes, one can express lay- ered component-based designs concisely with efficient implementations. In this paper, we discuss pragmatic issues related to component-based programming using C++ mixins. We explain surprising interactions of C++ features and poli- cies that sometimes complicate mixin implementations, while other times enable additional functionality without extra effort. 1 Introduction Large software artifacts are arguably among the most complex products of human intellect. The complexity of software has led to implementation methodologies that divide a problem into manageable parts and compose the parts to form the final prod- uct. Several research efforts have argued that C++ templates (a powerful parameteriza- tion mechanism) can be used to perform this division elegantly. In particular, the work of VanHilst and Notkin [29][30][31] showed how one can implement collaboration-based (or role-based) designs using a certain templatized class pattern, known as a mixin class (or just mixin). Compared to other techniques (e.g., a straightforward use of application frameworks [17]) the VanHilst and Notkin method yields less redundancy and reusable components that reflect the structure of the design. At the same time, unnecessary dynamic binding can be eliminated, result- ing into more efficient implementations. -

The Circle Meta-Model
Document:P2062R0 Revises: (original) Date: 01-11-2020 Audience: SG7 Authors: Wyatt Childers ([email protected]) Andrew Sutton ([email protected]) Faisal Vali ([email protected]) Daveed Vandevoorde ([email protected]) The Circle Meta-model Introduction During the November 2019 meeting in Belfast, some of the SG7 participants enthusiastically mentioned Circle1 as providing a more intuitive compile-time programming model and suggested that SG7 investigate overhauling the de-facto SG7 approach (P1240+P17332) to follow Circle's general approach (to reflection and metaprogramming). This paper describes a framework for understanding metaprogramming systems and provides a high-level overview of some of Circle's main characteristics, contrasting them to P1240's approach augmented with an injection mechanism along the lines of P1717. While we appreciate some of Circle’s powerful capabilities, we also raise some concerns with its underlying model and provide arguments in support of P1240’s choices as being a more suitable fit for C++’s evolution. The Dimensions of Reflective Programming In P0633, we identified three “dimensions” of compile-time reflective metaprogramming: 1. Control: How are compile-time computations effected/interpreted? What are metaprograms? 2. Reflection: How are source constructs are made available as data for use in metaprograms? 3. Synthesis: How can “code” be generated from a programmatic representation? 1 https://www.circle-lang.org/ Circle is an impressive project: Sean Baxter developed a brand new C++17-like front end on top of LLVM, incorporating a variety of new compile-time capabilities that align closely with SG7's goals. For Sean’s motivations, see https://github.com/seanbaxter/circle/blob/master/examples/README.md#why-i-wrote-circle. -

Comp 411 Principles of Programming Languages Lecture 19 Semantics of OO Languages
Comp 411 Principles of Programming Languages Lecture 19 Semantics of OO Languages Corky Cartwright Mar 10-19, 2021 Overview I • In OO languages, OO data values (except for designated non-OO types) are special records [structures] (finite mappings from names to values). In OO parlance, the components of record are called members. • Some members of an object may be functions called methods. Methods take this (the object in question) as an implicit parameter. Some OO languages like Java also support static methods that do not depend on this; these methods have no implicit parameters. In efficient OO language implementations, method members are shared since they are the same for all instances of a class, but this sharing is an optimization in statically typed OO languages since the collection of methods in a class is immutable during program evaluation (computation). • A method (instance method in Java) can only be invoked on an object (the receiver, an implicit parameter). Additional parameters are optional, depending on whether the method expects them. This invocation process is called dynamic dispatch because the executed code is literally extracted from the object: the code invoked at a call site depends on the value of the receiver, which can change with each execution of the call. • A language with objects is OO if it supports dynamic dispatch (discussed in more detail in Overview II & III) and inheritance, an explicit taxonomy for classifying objects based on their members and class names where superclass/parent methods are inherited unless overridden. • In single inheritance, this taxonomy forms a tree; • In multiple inheritance, it forms a rooted DAG (directed acyclic graph) where the root class is the universal class (Object in Java). -

Comparative Studies of Programming Languages; Course Lecture Notes
Comparative Studies of Programming Languages, COMP6411 Lecture Notes, Revision 1.9 Joey Paquet Serguei A. Mokhov (Eds.) August 5, 2010 arXiv:1007.2123v6 [cs.PL] 4 Aug 2010 2 Preface Lecture notes for the Comparative Studies of Programming Languages course, COMP6411, taught at the Department of Computer Science and Software Engineering, Faculty of Engineering and Computer Science, Concordia University, Montreal, QC, Canada. These notes include a compiled book of primarily related articles from the Wikipedia, the Free Encyclopedia [24], as well as Comparative Programming Languages book [7] and other resources, including our own. The original notes were compiled by Dr. Paquet [14] 3 4 Contents 1 Brief History and Genealogy of Programming Languages 7 1.1 Introduction . 7 1.1.1 Subreferences . 7 1.2 History . 7 1.2.1 Pre-computer era . 7 1.2.2 Subreferences . 8 1.2.3 Early computer era . 8 1.2.4 Subreferences . 8 1.2.5 Modern/Structured programming languages . 9 1.3 References . 19 2 Programming Paradigms 21 2.1 Introduction . 21 2.2 History . 21 2.2.1 Low-level: binary, assembly . 21 2.2.2 Procedural programming . 22 2.2.3 Object-oriented programming . 23 2.2.4 Declarative programming . 27 3 Program Evaluation 33 3.1 Program analysis and translation phases . 33 3.1.1 Front end . 33 3.1.2 Back end . 34 3.2 Compilation vs. interpretation . 34 3.2.1 Compilation . 34 3.2.2 Interpretation . 36 3.2.3 Subreferences . 37 3.3 Type System . 38 3.3.1 Type checking . 38 3.4 Memory management . -

Sub-Method Structural and Behavioral Reflection Marcus Denker
Sub-method Structural and Behavioral Reflection Marcus Denker To cite this version: Marcus Denker. Sub-method Structural and Behavioral Reflection. Computer Science [cs]. Universität Bern, 2008. English. tel-00555937 HAL Id: tel-00555937 https://tel.archives-ouvertes.fr/tel-00555937 Submitted on 14 Jan 2011 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Sub-method Structural and Behavioral Reflection Inauguraldissertation der Philosophisch-naturwissenschaftlichen Fakultät der Universität Bern vorgelegt von Marcus Denker von Deutschland Leiter der Arbeit: Prof. Dr. O. Nierstrasz Institut für Informatik und angewandte Mathematik Von der Philosophisch-naturwissenschaftlichen Fakultät angenommen. Bern, 26.05.2008 Der Dekan: Prof. Dr. P. Messerli This dissertation is available as a free download from http://scg.unibe.ch Copyright © 2008 Marcus Denker. The contents of this dissertation are protected under Creative Commons Attribution-ShareAlike 3.0 Unported license. You are free: to Share — to copy, distribute and transmit the work to Remix — to adapt the work Under the following conditions: Attribution. You must attribute the work in the manner specified by the author or licensor (but not in any way that suggests that they endorse you or your use of the work). -

Multiple Inheritance and the Resolution of Inheritance Conflicts
JOURNAL OF OBJECT TECHNOLOGY Online at http://www.jot.fm. Published by ETH Zurich, Chair of Software Engineering ©JOT, 2005 Vol. 4, No.2, March-April 2005 The Theory of Classification Part 17: Multiple Inheritance and the Resolution of Inheritance Conflicts Anthony J H Simons, Department of Computer Science, University of Sheffield, Regent Court, 211 Portobello Street, Sheffield S1 4DP, UK 1 INTRODUCTION This is the seventeenth article in a regular series on object-oriented theory for non- specialists. Using a second-order λ-calculus model, we have previously modelled the notion of inheritance as a short-hand mechanism for defining subclasses by extending superclass definitions. Initially, we considered the inheritance of type [1] and implementation [2] separately, but later combined both of these in a model of typed inheritance [3]. By simplifying the short-hand inheritance expressions, we showed how these are equivalent to canonical class definitions. We also showed how classes derived by inheritance are type compatible with their superclass. Further aspects of inheritance have included method combination [4], mixin inheritance [5] and inheritance among generic classes [6]. Most recently, we re-examined the ⊕ inheritance operator [7], to show how extending a class definition (the intension of a class) has the effect of restricting the set of objects that belong to the class (the extension of the class). We also added a type constraint to the ⊕ operator, to restrict the types of fields that may legally be combined with a base class to yield a subclass. By varying the form of this constraint, we modelled the typing of inheritance in Java, Eiffel, C++ and Smalltalk.