Sound - Space - Body Reflections on Artistic Practice
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Excesss Karaoke Master by Artist
XS Master by ARTIST Artist Song Title Artist Song Title (hed) Planet Earth Bartender TOOTIMETOOTIMETOOTIM ? & The Mysterians 96 Tears E 10 Years Beautiful UGH! Wasteland 1999 Man United Squad Lift It High (All About 10,000 Maniacs Candy Everybody Wants Belief) More Than This 2 Chainz Bigger Than You (feat. Drake & Quavo) [clean] Trouble Me I'm Different 100 Proof Aged In Soul Somebody's Been Sleeping I'm Different (explicit) 10cc Donna 2 Chainz & Chris Brown Countdown Dreadlock Holiday 2 Chainz & Kendrick Fuckin' Problems I'm Mandy Fly Me Lamar I'm Not In Love 2 Chainz & Pharrell Feds Watching (explicit) Rubber Bullets 2 Chainz feat Drake No Lie (explicit) Things We Do For Love, 2 Chainz feat Kanye West Birthday Song (explicit) The 2 Evisa Oh La La La Wall Street Shuffle 2 Live Crew Do Wah Diddy Diddy 112 Dance With Me Me So Horny It's Over Now We Want Some Pussy Peaches & Cream 2 Pac California Love U Already Know Changes 112 feat Mase Puff Daddy Only You & Notorious B.I.G. Dear Mama 12 Gauge Dunkie Butt I Get Around 12 Stones We Are One Thugz Mansion 1910 Fruitgum Co. Simon Says Until The End Of Time 1975, The Chocolate 2 Pistols & Ray J You Know Me City, The 2 Pistols & T-Pain & Tay She Got It Dizm Girls (clean) 2 Unlimited No Limits If You're Too Shy (Let Me Know) 20 Fingers Short Dick Man If You're Too Shy (Let Me 21 Savage & Offset &Metro Ghostface Killers Know) Boomin & Travis Scott It's Not Living (If It's Not 21st Century Girls 21st Century Girls With You 2am Club Too Fucked Up To Call It's Not Living (If It's Not 2AM Club Not -

The Knowledge-Knower Structures Used in the Assessment of Graphic Design Practical Work in a Multi-Campus Context
The knowledge-knower structures used in the assessment of graphic design practical work in a multi-campus context. A thesis submitted in fulfilment of the requirements for the degree of DOCTOR OF PHILOSOPHY of RHODES UNIVERSITY by SUSAN LOUISE GILOI November 2015 Abstract This case study explicates the knowledge-knower structures that are valued in the assessment of Graphic Design (GD) practical work in a multi-campus Private Higher Education (PHE) context. Assessment, which provides the measure for student success and progression, plays a significant role in Higher Education (HE). It is acknowledged that, in addition to increased pressure on educators to deliver high pass and throughput rates, there is often scrutiny of their assessment practice to ensure that it is fair, reliable, valid and transparent. The aspects of reliability and validity are particularly significant in for-profit private higher education institutions, where a strong focus on efficiency may result in added scrutiny of assessment practices. Although the assessment of GD practical work exemplifies these pressures and objectives, its characteristics and practices set it apart from many of the more standard forms of assessment found in HE. Not only is GD practical work predominantly visual rather than text-based, but complex achievements and tacit knowledge are assessed. This form of assessment traditionally relies on panel or group marking by connoisseurs who consider what is commonly termed ‘person’, ‘process’ and ‘product’ when making value judgements. Therefore, in GD assessment knowledge, the design product, the graphic designer and what the graphic designer does may all be valued. GD assessment, where outcomes are not easily stated, relies on the tacit expertise of assessors and can often be perceived to be subjective and unreliable. -

As Schoolwork and the Need for Socializing Pile Up, Students Find Themselves Pushing One of the Most Important Activities out of Their Schedules — Sleep
February 2, 2021 The Octagon 6 Centerpoint 7 TIME IS OF THE As schoolwork and the need for socializing pile up, students find themselves pushing one of the most important activities out of their schedules — sleep. BY ARIJIT TRIVEDI & ETHAN MONASA Anxiety symptoms ucator Pat Reynolds said it’s counterpro- ends and a nap in the evening after his soc- “To hang out with your friends or do “I lay down to go to sleep. It’s 12, and Depressed mood ductive. cer practices. In total, he said he gets nine anything social, you’re basically online,” then I turn around and it’s five in the usually wake up around 10 min- Alcohol use “People who stay up all night and study to 10 hours spaced throughout the day. Boersma said. morning, and I have to get up,” Fesai said. utes before class.” and then don’t get any sleep are not going Fragmented sleep phases often result in He added that he spends a significant “There would be nights where I wouldn’t That’s junior Dylan Margolis. to be able to access what they’ve been try- unrestfulness because the body is usually amount of his free time interacting with sleep at all.” It’s 8:10 a.m. He opens his eyes School and studying ing to learn because it hasn’t gone from not getting the REM sleep it needs, Dha- his friends, more so during senior year than On average, Fesai goes to bed around “Ito the sound of his phone playing “By the short term to longer term memory,” she wan said. -

Getting Started a Guide for Your Apple Mobile Learning Lab Contents
Getting Started A guide for your Apple Mobile Learning Lab Contents Introduction 1 Setting Up and Working with Your Mobile Lab 3 Setting Up Your Mobile Lab 3 Daily Setup 6 Sharing the Mobile Lab 9 Creating and Managing User Accounts 9 Installing Software 11 Sharing and Storing Files 14 Apple Remote Desktop: Managing Student Computers from One Computer 15 Using Parental Controls to Provide Extra Security 16 Maintaining Your Mobile Lab 17 Using the Tools That Come with Your Mobile Lab 20 Using iChat AV to Communicate and Collaborate with Video, Audio, and Text 20 Having Instant Access to Information with Widgets 22 Finding Files in a Flash with Spotlight 23 Crunching Numbers with Calculator and Grapher 24 Browsing the Internet with Safari 25 Staying Up to Date with iCal 27 Producing Digital Media Projects with iLife 28 Creating Digital Stories with iMovie 29 Creating Digital Music and Recording Audio with GarageBand 30 Organizing, Editing, and Sharing Digital Photos with iPhoto 32 Building Websites with Photos, Movies, Podcasts, and Text with iWeb 34 Organizing and Playing Music and Audio with iTunes 36 Reaching All Learners with Built-in Accessibility Features 37 Communicating via Email with Mail 38 Supporting Writing with Dictionary and TextEdit 39 Getting Started: A guide for your Apple Mobile Learning Lab II Contents More Tools to Use with Your Mobile Lab 40 Increasing Student Achievement with the Apple Digital Learning Series 40 Using the iPod as a Portable Learning Tool 44 Creating, Presenting, and Publishing Work with iWork 45 Additional Resources 47 Apple Learning Interchange 47 Apple Education 47 Apple Professional Development 48 Apple Support 48 Mobile Lab Teacher Sign-Up Sheet 49 Mobile Lab Student Checkout Sheet 50 Mobile Lab Teacher Checkout Sheet 51 © 2007 Apple Inc. -

Winter2011.Pdf
WINTER 2011 FARMERS’ MARKETS | FOOD TRUCKS | THE PEARL | INTRAMURALS | MISS VAMP www.leeward.hawaii.edu/kamanao 1 PART-TIME PAYCHECK. FULL-TIME PRESTIGE. 2 KA MANA‘O www.leeward.hawaii.edu/kamanao 3 INSIDE 6- Learning Commons 26- Meals on wheels New look coming to Leeward Eating out at food trucks 8- Help is here 29- The Cleanse Psychologist on campus Drink is more than a diet 9- Tuition increase 30- Recipes Prices going up in UH system Easy dishes to whip up 10- Intramural sports 32- FITTED Students take to the court Latest trends for men 12- Queen of the night 38- Netflix Pageant for vampires Film picks 14- 40 years later 40- Student Showcase Journey continues for Kaneshiro Artwork, photography, poetry 15- Campus Voices 46- Travel What’s your favorite food? Sights from California 16- The Pearl 49- Touch this Five-star dining from students Apps are a tap away 20- Farmers’ markets 50- Puzzles Fresh finds and grinds Sudoku, word puzzles 4 KA MANA‘O OUTSIDE KA MANA’O STAFF Dragon fruits are grown Graphic Designers in Hawaii, Asia, South Maisha Abbott, Joel Gaspar, Jadine Hirchag, and Central America. Jasmine Hirchag, Irene Ilalio, Audrey Mayfield A type of cactus, the inside flesh has the taste Writers and texture similar of Keo Akina, Amanda Barr, Elizabeth Daligdig, pear and kiwi — photo Suzette Farnum, Leimaile Guerrero, Valerie Mako, by Leimaile Guerrero Andrew Outwater, Dwight Relente, Chloe Richie, Sazza Self, Missy Trippett Photographers Ka Mana’o is the student publication of Leeward Com- Carlo Cayetano, Chelsey Dale, Brandon Hicks, munity College. -
Guns N' Roses Entity Partnership Citizenship California Composed Of: W
Trademark Trial and Appeal Board Electronic Filing System. http://estta.uspto.gov ESTTA Tracking number: ESTTA966168 Filing date: 04/10/2019 IN THE UNITED STATES PATENT AND TRADEMARK OFFICE BEFORE THE TRADEMARK TRIAL AND APPEAL BOARD Notice of Opposition Notice is hereby given that the following party opposes registration of the indicated application. Opposer Information Name Guns N' Roses Entity Partnership Citizenship California Composed Of: W. Axl Rose Saul Hudson Michael "Duff" McKagan Address c/o LL Management Group West, LLC 5950 Canoga Ave., Ste. 510 Woodland Hills, CA 91367 UNITED STATES Attorney informa- Jill M. Pietrini Esq. tion Sheppard Mullin Richter & Hampton LLP 1901 Avenue of the Stars, Suite 1600 Los Angeles, CA 90067 UNITED STATES [email protected], [email protected], [email protected], [email protected], MDan- [email protected], [email protected], RLHud- [email protected] 310-228-3700 Applicant Information Application No 87947921 Publication date 03/12/2019 Opposition Filing 04/10/2019 Opposition Peri- 04/11/2019 Date od Ends Applicant ALDI Inc. 1200 N. Kirk Road Batavia, IL 60510 UNITED STATES Goods/Services Affected by Opposition Class 029. First Use: 0 First Use In Commerce: 0 All goods and services in the class are opposed, namely: cheese, namely, cheddar cheese Grounds for Opposition Priority and likelihood of confusion Trademark Act Section 2(d) False suggestion of a connection with persons, Trademark Act Section 2(a) living or dead, institutions, beliefs, or national symbols, or brings them into contempt, or disrep- ute Mark Cited by Opposer as Basis for Opposition U.S. Application/ Registra- NONE Application Date NONE tion No. -

The Meanings of Sleep Among College Students
University of Central Florida STARS HIM 1990-2015 2013 Sleeping, napping and staying up: the meanings of sleep among college students Natasha Tate University of Central Florida Part of the Anthropology Commons Find similar works at: https://stars.library.ucf.edu/honorstheses1990-2015 University of Central Florida Libraries http://library.ucf.edu This Open Access is brought to you for free and open access by STARS. It has been accepted for inclusion in HIM 1990-2015 by an authorized administrator of STARS. For more information, please contact [email protected]. Recommended Citation Tate, Natasha, "Sleeping, napping and staying up: the meanings of sleep among college students" (2013). HIM 1990-2015. 1470. https://stars.library.ucf.edu/honorstheses1990-2015/1470 SLEEPING, NAPPING AND STAYING UP: THE MEANINGS OF SLEEP AMONG COLLEGE STUDENTS by NATASHA L. TATE A thesis submitted in partial fulfillment of the requirements for the Honors in the Major Program in Anthropology in the College of Sciences and in The Burnett Honors College at the University of Central Florida Orlando, Florida Spring 2013 Thesis Chair: Dr. Joanna Mishtal Abstract Throughout public discourse, sleep, despite being a physiological function and an important facet of an individual’s health, is frequently utilized as a rhetorical device to comment on an individual’s productivity within society. As Antje Richter (2003:34) explains, to consider someone early to rise yet late to bed is less a comment on their sleeping behavior and more an assessment of their dedication to their business. Too often productivity is conveyed as existing in the absence of sleep, an idea that has contributed to the association of sleep with laziness (Yi 2003:60) and a general misuse of time (Richter 2003:36). -

Participation, Recognition and Creativity As Resources for Growing up Across Cultures
Playing our way: Participation, recognition and creativity as resources for growing up across cultures Hildegunn Marie Tønnessen Seip University of Oslo, Ansgar University College and ABUP/Sørlandet Hospital Dissertation presented for the degree of Philosophiae Doctor (PhD) 2020 Department of Psychology Faculty of Social Sciences University of Oslo © Hildegunn Marie Tønnessen Seip, 2020 Series of dissertations submitted to the Faculty of Social Sciences, University of Oslo No. 809 ISSN 1564-3991 All rights reserved. No part of this publication may be reproduced or transmitted, in any form or by any means, without permission. Cover: Hanne Baadsgaard Utigard. Cover photo: Lars Verket Print production: Reprosentralen, University of Oslo. Prelude: Puzzles and potential Where did this story begin? Was it when my grandparents brought me gifts from Jamaica and Nairobi after traveling to UN conferences, and I as a child felt the excitement of being part of a big and colorful world? Was it when I admired my other grandfather’s treasures from his migrant years in New York in the early 20th century? Was it when I lived in Mexico or California or Greece, or when I returned home to Norway with my own multilingual children? Whenever it began, I followed my curiosity, and it got me moving. That sense of wonder in encounters with people who had lived different lives from me, as I understood that we therefore saw and moved through the world differently. The ways I learned from and grew in those encounters. The richness of finding different perspectives interacting and unfolding, even in one and the same person – like melodies and rhythms from different musical traditions playing together, blending into something rooted, but also new. -

The Effect of Sleep Deprivation on Information Processing and on the Cortical System
The effect of sleep deprivation on information processing and on the cortical system Investigating functional connectivity and cognitive control Anikó Kusztor Master of Philosophy in Psychology Cognitive Neuroscience UNIVERSITY OF OSLO May 2017 I II The effect of sleep deprivation on information processing and on the cortical system: Investigating functional connectivity and cognitive control Anikó Kusztor Master of Philosophy in Psychology Cognitive Neuroscience Department of Psychology University of Oslo May 2017 III © Anikó Kusztor 2017 The effect of sleep deprivation on information processing and on the cortical system: Investigating functional connectivity and cognitive control Author: Anikó Kusztor Supervisor: Liisa Raud Co-supervisor: Johan Frederik Storm http://www.duo.uio.no/ IV Acknowledgments First and foremost, I would like to thank Liisa Raud for the infinite amount of help and feedback she has provided during the course of the year. Without your supervision, this thesis would not exist. More importantly, you have provided a framework for high quality work and a professional attitude that has been very inspiring. I aim to produce my future work at the standard that you have set. I feel exceptionally grateful to have been able to learn from you. I would also like to thank Nadine Farnes, Bjørn Erik Juel, Andre Sevenius Nilsen and Benjamin Thürer for helping me during the data collection, giving me feedback on my thesis and being truly motivated and exceptional scientists. I had the best time working with you. I would like to thank Johan Frederik Storm for giving me the opportunity to work in his research group and for supporting the whole project with curiosity and enthusiasm. -

Way Cool Apptivities in Educational Settings
2012 UNIVERSITY OF COLORADO, WAY COOL ³$PP´TIVITIES IN ANSCHUTZ EDUCATION MEDICAL CAMPUS Maureen Melonis, M.N.S., CCC-SLP | Assistive Technology Partners Assistive Technology Partners, 303-315-1280 [email protected] Way-&RRO³$SS´WLYLWLHVIRU(GXFDWLRQDO6HWWLQJV Table of Contents General Introductory Information««««««««««««««««««««««««« Resources on Finding & Evaluating Apps««««««««««««««««««««« General information«««««««««««««««««««««««««««««« Document sharing and storage«««««««««««««««««««««««««« Time Management & Teacher/Administrative Resources««««««««««««««« Math««««««««««««««««««««««««««««««««««««.9 0XVLF«««««««««««««««««««««««««««««««««««1 Reading««...«««««««««««««««««««««««««««««««12 Writing««..««««««««««««««««««««««««««««««««7 General Writing«««««««««««««««««««««««««««7 Word Prediction«««««««««««««««««««««««««««9 Text to speech««««««««««««««««««««««««««««20 Speech to Text Voice Recognition Apps««««««««««««««««««20 Mind Mapping (organizing thoughts for writing) «««««««««««««««22 Art««««««««««««««««««««««««««««««.«««««23 Science««««««««««««««««««««««««««««.«««««24 Social Studies«««««««««««««««««««««««««««««««7 Communication«««««««««««««««««««««««««««««««8 Speech Production/Articulation««««««««««««««««««««««8 Language««««««««««««««««««««««««««««««30 AAC««««««««««««««««««««««««««««««««33 Sign Language«««««««««««««««««««««««««««.««««39 Texting««««««««««««««««««««««««««««««.«««40 2FFXSDWLRQDO7KHUDS\«««««««««««««««««««««««««««««40 Schedules«««««««««««««««««««««««««««««««««41 Switch Use«««««««««««««««««««««««««««««.«««42 Vision«««««««««««««««««««««««««««««««.««43 -

Getting Started a Guide for Your Apple Macbook Learning Lab Contents
Getting Started A guide for your Apple MacBook Learning Lab Contents Introduction 4 Setting Up and Working with Your Apple MacBook Learning Lab 6 Setting Up Your Apple MacBook Learning Lab 6 Daily Setup 9 Sharing the Lab 12 Creating and Managing User Accounts 12 Installing Software 14 Sharing and Storing Files 16 Apple Remote Desktop: Managing Student Computers from One Computer 17 Using Parental Controls to Provide Extra Security 18 Maintaining Your Apple MacBook Learning Lab 19 Using the Tools That Come with Your Apple MacBook Learning Lab 22 Using iChat to Communicate and Collaborate 22 Having Instant Access to Information with Widgets 24 Finding Files in a Flash with Spotlight 25 Crunching Numbers with Calculator and Grapher 26 Browsing the Internet with Safari 27 Staying Up to Date with iCal 28 Producing Digital Media Projects with iLife 29 Creating Digital Stories with iMovie 30 Creating Digital Music and Podcasts with GarageBand 31 Organizing, Editing, and Sharing Digital Photos with iPhoto 32 Building Websites and Blogs with iWeb 33 Organizing and Playing Music and Audio with iTunes 34 Reaching All Learners with Built-in Accessibility Features 35 Communicating via Email with Mail 36 Supporting Writing with Dictionary and TextEdit 37 Getting Started: A guide for your Apple MacBook Learning Lab Contents 3 More Tools to Use with Your Apple MacBook Learning Lab 38 Enhancing Student Learning with K-12 Curriculum Collections 38 Using iPod as a Mobile Learning Tool 39 Creating, Presenting, and Publishing Work with iWork 40 Additional Resources 41 Apple Learning Interchange 41 Apple Websites 41 Apple Professional Development 42 Apple Support 42 Apple MacBook Learning Lab Teacher Sign-Up Sheet 43 Apple MacBook Learning Lab Student Checkout Sheet 44 Apple MacBook Learning Lab Teacher Checkout Sheet 45 © 2009 Apple Inc. -
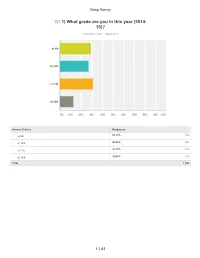
LMSD Sleep Survey
Sleep Survey Q1 1) What grade are you in this year (2014- 15)? Answered: 1,200 Skipped: 4 a) 9th b) 10th c) 11th d) 12th 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% Answer Choices Responses a) 9th 29.17% 350 b) 10th ..26.83% 322 c) 11th 31.17% 374 + d) 12th 12.83% 154 Total 1,200 1 / 41 Sleep Survey Q2 On average, how many hours of sleep do you get on school nights (Sunday - Thursday nights)? Answered: 1,202 Skipped: 2 a) 5 hours or less b) 5 1/2 hours c) 6 hours d) 6 1/2 hours e) 7 hours f) 7 1/2 hours g) 8 hours I h) 8 1/2 hours ~ i) 9 hours I I j) 9 1/2 hours I k) 10 or more hours 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% Answer Choices Responses a) 5 hours or less 11.06% 133 b) 5 1/2 hours 11.48% 138 c) 6 hours 18.05% 217 d) 6 1/2 hours 16.72% 201 e) 7 hours 20.13% 242 f) 7 1/2 hours 12.06% 145 g) 8 hours 6.91% 83 2 / 41 Sleep Survey h) 8 1/2 hours 1.66% 20 i) 9 hours 1.00% 12 j) 9 1/2 hours 0.58% 7 0k) 1 or more hours 0.33% 4 Total 1,202 3 / 41 Sleep Survey Q3 3) What time do you typically fall asleep on school nights? Answered: 1,202 Skipped: 2 a) Before 8:30 pm b) 8:30 p.m.