Second-Generation Stack Computer Architecture
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Unit – I Computer Architecture and Operating System – Scs1315
SCHOOL OF ELECTRICAL AND ELECTRONICS DEPARTMENT OF ELECTRONICS AND COMMMUNICATION ENGINEERING UNIT – I COMPUTER ARCHITECTURE AND OPERATING SYSTEM – SCS1315 UNIT.1 INTRODUCTION Central Processing Unit - Introduction - General Register Organization - Stack organization -- Basic computer Organization - Computer Registers - Computer Instructions - Instruction Cycle. Arithmetic, Logic, Shift Microoperations- Arithmetic Logic Shift Unit -Example Architectures: MIPS, Power PC, RISC, CISC Central Processing Unit The part of the computer that performs the bulk of data-processing operations is called the central processing unit CPU. The CPU is made up of three major parts, as shown in Fig.1 Fig 1. Major components of CPU. The register set stores intermediate data used during the execution of the instructions. The arithmetic logic unit (ALU) performs the required microoperations for executing the instructions. The control unit supervises the transfer of information among the registers and instructs the ALU as to which operation to perform. General Register Organization When a large number of registers are included in the CPU, it is most efficient to connect them through a common bus system. The registers communicate with each other not only for direct data transfers, but also while performing various microoperations. Hence it is necessary to provide a common unit that can perform all the arithmetic, logic, and shift microoperations in the processor. A bus organization for seven CPU registers is shown in Fig.2. The output of each register is connected to two multiplexers (MUX) to form the two buses A and B. The selection lines in each multiplexer select one register or the input data for the particular bus. The A and B buses form the inputs to a common arithmetic logic unit (ALU). -

S.D.M COLLEGE of ENGINEERING and TECHNOLOGY Sridhar Y
VISVESVARAYA TECHNOLOGICAL UNIVERSITY S.D.M COLLEGE OF ENGINEERING AND TECHNOLOGY A seminar report on CUDA Submitted by Sridhar Y 2sd06cs108 8th semester DEPARTMENT OF COMPUTER SCIENCE ENGINEERING 2009-10 Page 1 VISVESVARAYA TECHNOLOGICAL UNIVERSITY S.D.M COLLEGE OF ENGINEERING AND TECHNOLOGY DEPARTMENT OF COMPUTER SCIENCE ENGINEERING CERTIFICATE Certified that the seminar work entitled “CUDA” is a bonafide work presented by Sridhar Y bearing USN 2SD06CS108 in a partial fulfillment for the award of degree of Bachelor of Engineering in Computer Science Engineering of the Visvesvaraya Technological University, Belgaum during the year 2009-10. The seminar report has been approved as it satisfies the academic requirements with respect to seminar work presented for the Bachelor of Engineering Degree. Staff in charge H.O.D CSE Name: Sridhar Y USN: 2SD06CS108 Page 2 Contents 1. Introduction 4 2. Evolution of GPU programming and CUDA 5 3. CUDA Structure for parallel processing 9 4. Programming model of CUDA 10 5. Portability and Security of the code 12 6. Managing Threads with CUDA 14 7. Elimination of Deadlocks in CUDA 17 8. Data distribution among the Thread Processes in CUDA 14 9. Challenges in CUDA for the Developers 19 10. The Pros and Cons of CUDA 19 11. Conclusions 21 Bibliography 21 Page 3 Abstract Parallel processing on multi core processors is the industry’s biggest software challenge, but the real problem is there are too many solutions. One of them is Nvidia’s Compute Unified Device Architecture (CUDA), a software platform for massively parallel high performance computing on the powerful Graphics Processing Units (GPUs). -

Lecture 6: Instruction Set Architecture and the 80X86
Lecture 6: Instruction Set Architecture and the 80x86 Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Review From Last Time • Given sales a function of performance relative to competition, tremendous investment in improving product as reported by performance summary • Good products created when have: – Good benchmarks – Good ways to summarize performance • If not good benchmarks and summary, then choice between improving product for real programs vs. improving product to get more sales=> sales almost always wins • Time is the measure of computer performance! • What about cost? RHK.S96 2 Review: Integrated Circuits Costs IC cost = Die cost + Testing cost + Packaging cost Final test yield Die cost = Wafer cost Dies per Wafer * Die yield Dies per wafer = p * ( Wafer_diam / 2)2 – p * Wafer_diam – Test dies Die Area Ö 2 * Die Area Defects_per_unit_area * Die_Area Die Yield = Wafer yield * { 1 + } 4 Die Cost is goes roughly with area RHK.S96 3 Review From Last Time Price vs. Cost 100% 80% Average Discount 60% Gross Margin 40% Direct Costs 20% Component Costs 0% Mini W/S PC 5 4.7 3.8 4 3.5 Average Discount 3 2.5 Gross Margin 2 1.8 Direct Costs 1.5 1 Component Costs 0 Mini W/S PC RHK.S96 4 Today: Instruction Set Architecture • 1950s to 1960s: Computer Architecture Course Computer Arithmetic • 1970 to mid 1980s: Computer Architecture Course Instruction Set Design, especially ISA appropriate for compilers • 1990s: Computer Architecture Course Design of CPU, memory system, I/O system, Multiprocessors RHK.S96 5 Computer Architecture? . the attributes of a [computing] system as seen by the programmer, i.e. -

Low-Power Microprocessor Based on Stack Architecture
Girish Aramanekoppa Subbarao Low-power Microprocessor based on Stack Architecture Stack on based Microprocessor Low-power Master’s Thesis Low-power Microprocessor based on Stack Architecture Girish Aramanekoppa Subbarao Series of Master’s theses Department of Electrical and Information Technology LU/LTH-EIT 2015-464 Department of Electrical and Information Technology, http://www.eit.lth.se Faculty of Engineering, LTH, Lund University, September 2015. Department of Electrical and Information Technology Master of Science Thesis Low-power Microprocessor based on Stack Architecture Supervisors: Author: Prof. Joachim Rodrigues Girish Aramanekoppa Subbarao Prof. Anders Ard¨o Lund 2015 © The Department of Electrical and Information Technology Lund University Box 118, S-221 00 LUND SWEDEN This thesis is set in Computer Modern 10pt, with the LATEX Documentation System ©Girish Aramanekoppa Subbarao 2015 Printed in E-huset Lund, Sweden. Sep. 2015 Abstract There are many applications of microprocessors in embedded applications, where power efficiency becomes a critical requirement, e.g. wearable or mobile devices in healthcare, space instrumentation and handheld devices. One of the methods of achieving low power operation is by simplifying the device architecture. RISC/CISC processors consume considerable power because of their complexity, which is due to their multiplexer system connecting the register file to the func- tional units and their instruction pipeline system. On the other hand, the Stack machines are comparatively less complex due to their implied addressing to the top two registers of the stack and smaller operation codes. This makes the instruction and the address decoder circuit simple by eliminating the multiplex switches for read and write ports of the register file. -

Supplementary Material HR19008 AC
Historical Records of Australian Science © Australian Academy of Science 2020 https://doi.org/10.1071/HR19008_AC Supplementary Material: Historical Records of Australian Science, 2020, 31(1), 17–25 Supplementary material. A bibliography of Australian mathematics to 1960 with observations relating to the history of Australian mathematics Graeme L. Cohen Formerly, School of Mathematical Sciences, University of Technology Sydney, NSW 2007, Australia. Email: [email protected] File S1. Lists List 1—Chronological List of Publications to 1900 2 List 2—Alphabetical by Author List of Publications from 1901 16 to 1960 (Excluding Theses and Most School Books) List 3—Alphabetical by Author List of Theses Leading to the 37 Award of a Higher Degree, to 1960 Index 45 References (further to those in the main text) 56 1 Historical Records of Australian Science © Australian Academy of Science 2020 https://doi.org/10.1071/HR19008_AC Supplementary Material: Historical Records of Australian Science, 2020, 31(1), 17–25 LISTS The main item, article HR19008, should be read first for a full understanding of what is included here. The superscript CAI before an author’s name indicates that biographical information on that author is to be found in Counting Australia In.1 List 1— Chronological List of Publications to 1900 1. RUSSELL, JOHN WM. (18-?) Exercises and examples in expert arithmetic, Kealy & Philip, Sydney. 2. BOWDEN, THOMAS (1812) Bowden’s tables, Ferguson I, 532. [‘Their object is to ascertain at a momentary glance, the difference between sterling and currency … They are calculated with a degree of precision that must have occupied considerable time and attention …’, according to Ferguson. -

X86-64 Machine-Level Programming∗
x86-64 Machine-Level Programming∗ Randal E. Bryant David R. O'Hallaron September 9, 2005 Intel’s IA32 instruction set architecture (ISA), colloquially known as “x86”, is the dominant instruction format for the world’s computers. IA32 is the platform of choice for most Windows and Linux machines. The ISA we use today was defined in 1985 with the introduction of the i386 microprocessor, extending the 16-bit instruction set defined by the original 8086 to 32 bits. Even though subsequent processor generations have introduced new instruction types and formats, many compilers, including GCC, have avoided using these features in the interest of maintaining backward compatibility. A shift is underway to a 64-bit version of the Intel instruction set. Originally developed by Advanced Micro Devices (AMD) and named x86-64, it is now supported by high end processors from AMD (who now call it AMD64) and by Intel, who refer to it as EM64T. Most people still refer to it as “x86-64,” and we follow this convention. Newer versions of Linux and GCC support this extension. In making this switch, the developers of GCC saw an opportunity to also make use of some of the instruction-set features that had been added in more recent generations of IA32 processors. This combination of new hardware and revised compiler makes x86-64 code substantially different in form and in performance than IA32 code. In creating the 64-bit extension, the AMD engineers also adopted some of the features found in reduced-instruction set computers (RISC) [7] that made them the favored targets for optimizing compilers. -

Instruction Set Architecture
The Instruction Set Architecture Application Instruction Set Architecture OiOperating Compiler System Instruction Set Architecture Instr. Set Proc. I/O system or Digital Design “How to talk to computers if Circuit Design you aren’t on Star Trek” CSE 240A Dean Tullsen CSE 240A Dean Tullsen How to Sppmpeak Computer Crafting an ISA High Level Language temp = v[k]; • Designing an ISA is both an art and a science Program v[k] = v[k+ 1]; v[k+1] = temp; • ISA design involves dealing in an extremely rare resource Compiler – instruction bits! lw $15, 0($2) AblLAssembly Language lw $16, 4($2) • Some things we want out of our ISA Program sw $16, 0($2) – completeness sw $15, 4($2) Assembler – orthogonality 1000110001100010000000000000000 – regularity and simplicity Machine Language 1000110011110010000000000000100 – compactness Program 1010110011110010000000000000000 – ease of ppgrogramming 1010110001100010000000000000100 Machine Interpretation – ease of implementation Control Signal Spec ALUOP[0:3] <= InstReg[9:11] & MASK CSE 240A Dean Tullsen CSE 240A Dean Tullsen Where are the instructions? KKyey ISA decisions • Harvard architecture • Von Neumann architecture destination operand operation • operations y = x + b – how many? inst & source operands inst cpu data – which ones storage storage operands cpu • data “stored-program” computer – how many? storage – location – types – how to specify? how does the computer know what L1 • instruction format 0001 0100 1101 1111 inst – size means? cache L2 cpu Mem cache – how many formats? L1 dtdata cache CSE -

The Processor's Structure
Computer Architecture, Lecture 3: The processor's structure Hossam A. H. Fahmy Cairo University Electronics and Communications Engineering 1 / 15 Structure versus organization Architecture: the structure and organization of a computer's hardware or system software. Within the processor: Registers, Operational Units (Integer, Floating Point, special purpose, . ) Outside the processor: Memory, I/O, . Instruction Set Architecture (ISA): What is the best for the target application? Why? Examples: Sun SPARC, MIPS, Intel x86 (IA32), IBM S/390. Defines: data (types, storage, and addressing modes), instruction (operation code) set, and instruction formats. 2 / 15 ISA The instruction set is the \language" that allows the hardware and the software to speak. It defines the exact functionality of the various operations. It defines the manner to perform these operations by specifying the encoding formats. It does not deal with the speed of performing these operations, the power consumed when these operations are invoked, and the specific details of the circuit implementations. 3 / 15 There are many languages Arabic and Hebrew are semitic languages. English and Urdu are Indo-European languages. The ISAs have their \families" as well. Stack architectures push operands onto a stack and issue operations with no explicit operands. The result is put on top of the same stack. Accumulator architectures use one explicit operand with the accumulator as the second operand. The result is put in the accumulator. Register-memory architectures have several registers. The operands and the result may be in the registers or the memory. Register-register architectures have several registers as well. The operands and result are restricted to be in the registers only. -

Design and Implementation of a Multithreaded Associative Simd Processor
DESIGN AND IMPLEMENTATION OF A MULTITHREADED ASSOCIATIVE SIMD PROCESSOR A dissertation submitted to Kent State University in partial fulfillment of the requirements for the degree of Doctor of Philosophy by Kevin Schaffer December, 2011 Dissertation written by Kevin Schaffer B.S., Kent State University, 2001 M.S., Kent State University, 2003 Ph.D., Kent State University, 2011 Approved by Robert A. Walker, Chair, Doctoral Dissertation Committee Johnnie W. Baker, Members, Doctoral Dissertation Committee Kenneth E. Batcher, Eugene C. Gartland, Accepted by John R. D. Stalvey, Administrator, Department of Computer Science Timothy Moerland, Dean, College of Arts and Sciences ii TABLE OF CONTENTS LIST OF FIGURES ......................................................................................................... viii LIST OF TABLES ............................................................................................................. xi CHAPTER 1 INTRODUCTION ........................................................................................ 1 1.1. Architectural Trends .............................................................................................. 1 1.1.1. Wide-Issue Superscalar Processors............................................................... 2 1.1.2. Chip Multiprocessors (CMPs) ...................................................................... 2 1.2. An Alternative Approach: SIMD ........................................................................... 3 1.3. MTASC Processor ................................................................................................ -
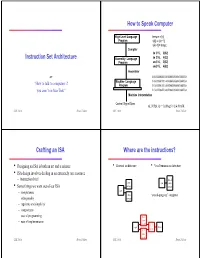
Instruction Set Architecture How to Speak Computer Crafting an ISA Where Are the Instructions?
How to Speak Computer High Level Language temp = v[k]; Program v[k] = v[k+1]; v[k+1] = temp; Compiler lw $15, 0($2) Instruction Set Architecture Assembly Language lw $16, 4($2) Program sw $16, 0($2) sw $15, 4($2) Assembler or 1000110001100010000000000000000 Machine Language 1000110011110010000000000000100 “How to talk to computers if Program 1010110011110010000000000000000 you aren’t on Star Trek” 1010110001100010000000000000100 Machine Interpretation Control Signal Spec ALUOP[0:3] <= InstReg[9:11] & MASK CSE 240A Dean Tullsen CSE 240A Dean Tullsen Crafting an ISA Where are the instructions? • Designing an ISA is both an art and a science • Harvard architecture • Von Neumann architecture • ISA design involves dealing in an extremely rare resource – instruction bits! inst & inst cpu data • Some things we want out of our ISA storage storage – completeness cpu data “stored-program” computer – orthogonality storage – regularity and simplicity – compactness – ease of programming L1 – ease of implementation inst cache L2 cpu Mem cache L1 data cache CSE 240A Dean Tullsen CSE 240A Dean Tullsen Key ISA decisions Choice 1: Operand Location destination operand operation • operations y = x + b • Accumulator –how many? • Stack – which ones source operands Registers • operands • –how many? • Memory – location –types • We can classify most machines into 4 types: accumulator, – how to specify? how does the computer know what stack, register-memory (most operands can be registers or • instruction format 0001 0100 1101 1111 means? memory), load-store (arithmetic -

Second-Generation Stack Computer Architecture
Second-Generation Stack Computer Architecture Charles Eric LaForest A thesis presented to the Independent Studies Program of the University of Waterloo in fulfilment of the thesis requirements for the degree Bachelor of Independent Studies (BIS) Independent Studies University of Waterloo Canada April 2007 ii Declaration I hereby declare that I am the sole author of this research paper. I authorize the University of Waterloo to lend this thesis to other institutions or individuals for the purpose of scholarly research. Signature: I further authorize the University of Waterloo to reproduce this research paper by photocopy- ing or other means, in total or in part, at the request of other institutions or individuals for the purpose of scholarly research. Signature: The work in this research paper is based on research carried out in the Independent Studies Program at the University of Waterloo, Canada. No part of this thesis has been submitted else- where for any other degree or qualification and is all my own work unless referenced to the contrary in the text. Copyright c 2007 by Charles Eric LaForest. The copyright of this thesis rests with the author. Quotations and information derived from it must be acknowledged. iii Second-Generation Stack Computer Architecture Charles Eric LaForest Submitted for the degree of Bachelor of Independent Studies April 2007 Abstract It is commonly held in current computer architecture literature that stack-based computers were entirely superseded by the combination of pipelined, integrated microprocessors and improved compilers. While correct, the literature omits a second, new generation of stack computers that emerged at the same time. -

Special Issue on Charles Hamblin
Special Issue on Charles Hamblin Edited by DOUGLAS WALTON & RALPH H. JOHNSON Editors’ Introduction Charles Leonard Hamblin was professor of philosophy at the Univer- sity of New South Wales in Sydney Australia between 1955 and his premature death in 1985. He is best known in philosophy for his book Fallacies, the best book written on this subject since the time of Aris- totle. The subject of informal fallacies has been a constant presence in logic textbooks from the time of Aristotle, and its continuing impor- tance is recognized by its prominent inclusion in the hundreds of text- books on informal logic written in the last half of the 20th century and continuing to be written up to this day. However, as Hamblin made clear in Fallacies, the subject matter was sadly neglected over the his- tory of logic, so much so that it is fair to say that the advances that were made during the last half of the 20th century were made mainly in the textbooks themselves. Yet the textbooks struggled with the sub- ject matter, and their treatment of the topic lacked consistency, theo- retical organization, and the depth of treatment needed to make the methods they proposed very effective. It was clear that Hamblin‟s strategy was the one recognized by scientists (but not often enough put into practice and carried though) of picking as a topic for study an area that is problematic in its current state of development, understu- died, and badly in need of investigation. The results of Hamblin‟s carrying out this strategy are remarka- ble.