Identification and in Silico Analysis of the Origin Recognition Complex In
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model
Downloaded from http://www.jimmunol.org/ by guest on September 25, 2021 T + is online at: average * The Journal of Immunology , 34 of which you can access for free at: 2016; 197:1477-1488; Prepublished online 1 July from submission to initial decision 4 weeks from acceptance to publication 2016; doi: 10.4049/jimmunol.1600589 http://www.jimmunol.org/content/197/4/1477 Molecular Profile of Tumor-Specific CD8 Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. Waugh, Sonia M. Leach, Brandon L. Moore, Tullia C. Bruno, Jonathan D. Buhrman and Jill E. Slansky J Immunol cites 95 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html http://www.jimmunol.org/content/suppl/2016/07/01/jimmunol.160058 9.DCSupplemental This article http://www.jimmunol.org/content/197/4/1477.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2016 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 25, 2021. The Journal of Immunology Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -
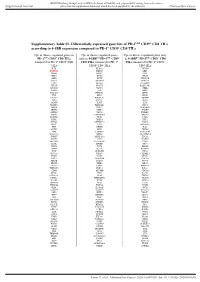
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al. -

Congenital Microcephaly
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Sussex Research Online American Journal of Medical Genetics Part C (Seminars in Medical Genetics) ARTICLE Congenital Microcephaly DIANA ALCANTARA AND MARK O'DRISCOLL* The underlying etiologies of genetic congenital microcephaly are complex and multifactorial. Recently, with the exponential growth in the identification and characterization of novel genetic causes of congenital microcephaly, there has been a consolidation and emergence of certain themes concerning underlying pathomechanisms. These include abnormal mitotic microtubule spindle structure, numerical and structural abnormalities of the centrosome, altered cilia function, impaired DNA repair, DNA Damage Response signaling and DNA replication, along with attenuated cell cycle checkpoint proficiency. Many of these processes are highly interconnected. Interestingly, a defect in a gene whose encoded protein has a canonical function in one of these processes can often have multiple impacts at the cellular level involving several of these pathways. Here, we overview the key pathomechanistic themes underlying profound congenital microcephaly, and emphasize their interconnected nature. © 2014 Wiley Periodicals, Inc. KEY WORDS: cell division; mitosis; DNA replication; cilia How to cite this article: Alcantara D, O'Driscoll M. 2014. Congenital microcephaly. Am J Med Genet Part C Semin Med Genet 9999:1–16. INTRODUCTION mid‐gestation although glial cell division formation of the various cortical layers. and consequent brain volume enlarge- Furthermore, differentiating and devel- Congenital microcephaly, an occipital‐ ment does continue after birth [Spalding oping neurons must migrate to their frontal circumference of equal to or less et al., 2005]. Impaired neurogenesis is defined locations to construct the com- than 2–3 standard deviations below the therefore most obviously reflected clini- plex architecture and laminar layered age‐related population mean, denotes cally as congenital microcephaly. -

Dual Recognition of H3k4me3 and H3k27me3 by a Plant Histone Reader SHL
ARTICLE DOI: 10.1038/s41467-018-04836-y OPEN Dual recognition of H3K4me3 and H3K27me3 by a plant histone reader SHL Shuiming Qian1,2, Xinchen Lv3,4, Ray N. Scheid1,2,LiLu1,2, Zhenlin Yang3,4, Wei Chen3, Rui Liu3, Melissa D. Boersma2, John M. Denu2,5,6, Xuehua Zhong 1,2 & Jiamu Du 3 The ability of a cell to dynamically switch its chromatin between different functional states constitutes a key mechanism regulating gene expression. Histone mark “readers” display 1234567890():,; distinct binding specificity to different histone modifications and play critical roles in reg- ulating chromatin states. Here, we show a plant-specific histone reader SHORT LIFE (SHL) capable of recognizing both H3K27me3 and H3K4me3 via its bromo-adjacent homology (BAH) and plant homeodomain (PHD) domains, respectively. Detailed biochemical and structural studies suggest a binding mechanism that is mutually exclusive for either H3K4me3 or H3K27me3. Furthermore, we show a genome-wide co-localization of SHL with H3K27me3 and H3K4me3, and that BAH-H3K27me3 and PHD-H3K4me3 interactions are important for SHL-mediated floral repression. Together, our study establishes BAH-PHD cassette as a dual histone methyl-lysine binding module that is distinct from others in recognizing both active and repressive histone marks. 1 Laboratory of Genetics, University of Wisconsin-Madison, Madison, WI 53706, USA. 2 Wisconsin Institute for Discovery, University of Wisconsin-Madison, Madison, WI 53706, USA. 3 National Key Laboratory of Plant Molecular Genetics, CAS Center for Excellence in Molecular Plant Sciences, Shanghai Center for Plant Stress Biology, Shanghai Institutes for Biological Sciences, Chinese Academy of Sciences, Shanghai 201602, China. -

Direct Interactions Promote Eviction of the Sir3 Heterochromatin Protein by the SWI/SNF Chromatin Remodeling Enzyme
Direct interactions promote eviction of the Sir3 heterochromatin protein by the SWI/SNF chromatin remodeling enzyme Benjamin J. Manning and Craig L. Peterson1 Program in Molecular Medicine, University of Massachusetts Medical School, Worcester, MA 01605 Edited by Jasper Rine, University of California, Berkeley, CA, and approved November 11, 2014 (received for review October 20, 2014) Heterochromatin is a specialized chromatin structure that is central the Rsc2p subunit of the remodels structure of chromatin (RSC) to eukaryotic transcriptional regulation and genome stability. remodeling enzyme and the Orc1p subunit of the Origin Recogni- Despite its globally repressive role, heterochromatin must also tion Complex (ORC) (14). The stability of the Sir3p BAH–nucle- be dynamic, allowing for its repair and replication. In budding osome complex requires deacetylated histone H4 lysine 16 (15); yeast, heterochromatin formation requires silent information consequently, amino acid substitutions at H4-K16 disrupt Sir3p– regulators (Sirs) Sir2p, Sir3p, and Sir4p, and these Sir proteins nucleosome binding and eliminate heterochromatin assembly in create specialized chromatin structures at telomeres and silent vivo (15–17). mating-type loci. Previously, we found that the SWI/SNF chromatin Despite the repressive structure of heterochromatin, these remodeling enzyme can catalyze the ATP-dependent eviction of domains must be replicated and repaired, implying that mecha- Sir3p from recombinant nucleosomal arrays, and this activity nisms exist to regulate heterochromatin disassembly. Previously, enhances early steps of recombinational repair in vitro. Here, we we described an in vitro assay to monitor early steps of re- show that the ATPase subunit of SWI/SNF, Swi2p/Snf2p, interacts combinational repair with recombinant nucleosomal array sub- with the heterochromatin structural protein Sir3p. -

Signature of Progression and Negative Outcome in Colorectal Cancer
Oncogene (2010) 29, 876–887 & 2010 Macmillan Publishers Limited All rights reserved 0950-9232/10 $32.00 www.nature.com/onc ORIGINAL ARTICLE A ‘DNA replication’ signature of progression and negative outcome in colorectal cancer M-J Pillaire1,7, J Selves2,7, K Gordien2, P-A Gouraud3, C Gentil3, M Danjoux2,CDo3, V Negre4, A Bieth1, R Guimbaud2, D Trouche5, P Pasero6,MMe´chali6, J-S Hoffmann1 and C Cazaux1 1Genetic Instability and Cancer Group, Department Biology of Cancer, Institute of Pharmacology and Structural Biology, UMR5089 CNRS, University of Toulouse, University Paul Sabatier, Toulouse, France; 2INSERM U563, Federation of Digestive Cancerology and Department of Anatomo-pathology, University of Toulouse, University Paul Sabatier, Toulouse, France; 3Service of Epidemiology, INSERM U558, Faculty of Medicine, University of Toulouse, University Paul Sabatier, Alle´es Jules Guesde, Toulouse, France; 4aCGH GSO Canceropole Platform, INSERM U868, Val d’Aurelle, Montpellier, France; 5Laboratory of Cellular and Molecular Biology of Cell Proliferation Control, UMR 5099 CNRS, University of Toulouse, University Paul Sabatier, Toulouse, France and 6Institute of Human Genetics UPR1142 CNRS, Montpellier, France Colorectal cancer is one of the most frequent cancers Introduction worldwide. As the tumor-node-metastasis (TNM) staging classification does not allow to predict the survival of DNA replication in normal cells is regulated by an patients in many cases, additional prognostic factors are ‘origin licensing’ mechanism that ensures that it occurs needed to better forecast their outcome. Genes involved in just once per cycle. Once cells enter the S-phase, the DNA replication may represent an underexplored source stability of DNA replication forks must be preserved to of such prognostic markers. -

Human Origin Recognition Complex Is Essential for HP1 Binding to Chromatin and Heterochromatin Organization
Human origin recognition complex is essential for HP1 binding to chromatin and heterochromatin organization Supriya G. Prasantha,b,1, Zhen Shenb, Kannanganattu V. Prasanthb, and Bruce Stillmana,1 aCold Spring Harbor Laboratory, Cold Spring Harbor, NY 11724; and bDepartment of Cell and Developmental Biology, University of Illinois, Urbana- Champaign, IL 61801 Contributed by Bruce Stillman, July 9, 2010 (sent for review April 10, 2010) The origin recognition complex (ORC) is a DNA replication initiator (15, 22, 23), cytokinesis in human cells and Drosophila (24, 25), protein also known to be involved in diverse cellular functions regulation of dendrite development in postmitotic neurons (26), including gene silencing, sister chromatid cohesion, telomere bi- and neural transmission and synaptic function in Drosophila (27) ology, heterochromatin localization, centromere and centrosome (see reviews in refs. 28, 29). activity, and cytokinesis. We show that, in human cells, multiple ORC The human Orc2 subunit is associated with heterochromatin in subunits associate with hetereochromatin protein 1 (HP1) α-and a cell cycle-dependent manner, being present only at the cen- HP1β-containing heterochromatic foci. Fluorescent bleaching studies tromeres during late G2 and mitosis (15, 30). Furthermore, Orc2 indicate that multiple subcomplexes of ORC exist at heterochroma- biochemically interacts indirectly with the heterochromatin protein tin, with Orc1 stably associating with heterochromatin in G1 phase, 1 (HP1) in mammalian, Drosophila,andXenopus cells (14, 15, 31, whereas other ORC subunits have transient interactions throughout 32). Depletion of Orc2 or Orc3 in HeLa cells results in a mitotic the cell-division cycle. Both Orc1 and Orc3 directly bind to HP1α,and arrest with abnormally condensed chromosomes, lack of chromo- two domains of Orc3, a coiled-coil domain and a mod-interacting some alignment at the metaphase plate, and spindle defects (15). -

Transcriptional Silencing Functions of the Yeast Protein Orc1/Sir3 Subfunctionalized After Gene Duplication
Transcriptional silencing functions of the yeast protein Orc1/Sir3 subfunctionalized after gene duplication Meleah A. Hickman1 and Laura N. Rusche2 Biochemistry Department, Institute for Genome Sciences and Policy, Program in Genetics and Genomics, Duke University, Durham, NC 27708 Edited by Jasper Rine, University of California, Berkeley, CA, and approved September 30, 2010 (received for review May 7, 2010) The origin recognition complex (ORC) defines origins of replication divergence is known (12, 13). We previously demonstrated that and also interacts with heterochromatin proteins in a variety of the duplicated deacetylases Sir2 and Hst1 subfunctionalized (14, species, but how ORC functions in heterochromatin assembly 15), and in this study, we propose that the SIR3–ORC1 gene pair remains unclear. The largest subunit of ORC, Orc1, is particularly subfunctionalized and then specialized after duplication. interesting because it contains a nucleosome-binding BAH domain In S. cerevisiae, SIR-mediated silencing occurs at telomeres and and because it gave rise to Sir3, a key silencing protein in Saccha- the mating-type loci, HMLα and HMRa (16). Transcriptional si- romyces cerevisiae, through gene duplication. We examined lencing of the mating-type loci is required to maintain cell-type whether Orc1 possessed a Sir3-like silencing function before du- identity in haploid cells. In contrast, SIR-silenced chromatin at plication and found that Orc1 from the yeast Kluyveromyces lactis, the telomeres is thought to serve a structural role (17). The Sir which diverged from S. cerevisiae before the duplication, acts in proteins are recruited to the mating-type loci through silencer conjunction with the deacetylase Sir2 and the histone-binding pro- sequences that bind ORC, Rap1, and Abf1, which in turn recruit tein Sir4 to generate heterochromatin at telomeres and a mating- the Sir proteins. -

Coupling of H3k27me3 Recognition with Transcriptional Repression Through the BAH-PHD-CPL2 Complex in Arabidopsis
ARTICLE https://doi.org/10.1038/s41467-020-20089-0 OPEN Coupling of H3K27me3 recognition with transcriptional repression through the BAH-PHD-CPL2 complex in Arabidopsis Yi-Zhe Zhang 1,2,6, Jianlong Yuan 1,2,6, Lingrui Zhang3,6, Chunxiang Chen1, Yuhua Wang1, Guiping Zhang1, ✉ ✉ ✉ Li Peng1, Si-Si Xie 1,2, Jing Jiang4, Jian-Kang Zhu 1,3 , Jiamu Du 5 & Cheng-Guo Duan 1,4 1234567890():,; Histone 3 Lys 27 trimethylation (H3K27me3)-mediated epigenetic silencing plays a critical role in multiple biological processes. However, the H3K27me3 recognition and transcriptional repression mechanisms are only partially understood. Here, we report a mechanism for H3K27me3 recognition and transcriptional repression. Our structural and biochemical data showed that the BAH domain protein AIPP3 and the PHD proteins AIPP2 and PAIPP2 cooperate to read H3K27me3 and unmodified H3K4 histone marks, respectively, in Arabi- dopsis. The BAH-PHD bivalent histone reader complex silences a substantial subset of H3K27me3-enriched loci, including a number of development and stress response-related genes such as the RNA silencing effector gene ARGONAUTE 5 (AGO5). We found that the BAH-PHD module associates with CPL2, a plant-specific Pol II carboxyl terminal domain (CTD) phosphatase, to form the BAH-PHD-CPL2 complex (BPC) for transcriptional repres- sion. The BPC complex represses transcription through CPL2-mediated CTD depho- sphorylation, thereby causing inhibition of Pol II release from the transcriptional start site. Our work reveals a mechanism coupling H3K27me3 recognition with transcriptional repression through the alteration of Pol II phosphorylation states, thereby contributing to our understanding of the mechanism of H3K27me3-dependent silencing. -

Diversity of DNA Replication in the Archaea
G C A T T A C G G C A T genes Review Diversity of DNA Replication in the Archaea Darya Ausiannikava * and Thorsten Allers School of Life Sciences, University of Nottingham, Nottingham NG7 2UH, UK; [email protected] * Correspondence: [email protected]; Tel.: +44-115-823-0304 Academic Editor: Eishi Noguchi Received: 29 November 2016; Accepted: 20 January 2017; Published: 31 January 2017 Abstract: DNA replication is arguably the most fundamental biological process. On account of their shared evolutionary ancestry, the replication machinery found in archaea is similar to that found in eukaryotes. DNA replication is initiated at origins and is highly conserved in eukaryotes, but our limited understanding of archaea has uncovered a wide diversity of replication initiation mechanisms. Archaeal origins are sequence-based, as in bacteria, but are bound by initiator proteins that share homology with the eukaryotic origin recognition complex subunit Orc1 and helicase loader Cdc6). Unlike bacteria, archaea may have multiple origins per chromosome and multiple Orc1/Cdc6 initiator proteins. There is no consensus on how these archaeal origins are recognised—some are bound by a single Orc1/Cdc6 protein while others require a multi- Orc1/Cdc6 complex. Many archaeal genomes consist of multiple parts—the main chromosome plus several megaplasmids—and in polyploid species these parts are present in multiple copies. This poses a challenge to the regulation of DNA replication. However, one archaeal species (Haloferax volcanii) can survive without replication origins; instead, it uses homologous recombination as an alternative mechanism of initiation. This diversity in DNA replication initiation is all the more remarkable for having been discovered in only three groups of archaea where in vivo studies are possible. -

A Novel Motif Governs APC-Dependent Degradation of Drosophila ORC1 in Vivo
Downloaded from genesdev.cshlp.org on September 27, 2021 - Published by Cold Spring Harbor Laboratory Press A novel motif governs APC-dependent degradation of Drosophila ORC1 in vivo Marito Araki,1 Hongtao Yu,2 and Maki Asano1,3 1Department of Molecular Genetics and Microbiology, Duke University Medical Center, Durham, North Carolina 27710, USA; 2Department of Pharmacology, University of Texas Southwestern Medical Center, Dallas, Texas 75390, USA Regulated degradation plays a key role in setting the level of many factors that govern cell cycle progression. In Drosophila, the largest subunit of the origin recognition complex protein 1 (ORC1) is degraded at the end of M phase and throughout much of G1 by anaphase-promoting complexes (APC) activated by Fzr/Cdh1. We show here that none of the previously identified APC motifs targets ORC1 for degradation. Instead, a novel sequence, the O-box, is necessary and sufficient to direct Fzr/Cdh1-dependent polyubiquitylation in vitro and degradation in vivo. The O-box is similar to but distinct from the well characterized D-box. Finally, we show that O-box motifs in two other proteins, Drosophila Abnormal Spindle and Schizosaccharomyces pombe Cut2, contribute to Cdh1-dependent polyubiquitylation in vitro, suggesting that the O-box may mediate degradation of a variety of cell cycle factors. [Keywords: APC; cell cycle; ORC1; proteolysis; replication] Received August 5, 2005; revised version accepted August 16, 2005. Progression through the cell cycle relies critically on the and Kirschner 2000), A-box (Littlepage and Ruderman scheduled degradation of an ensemble of proteins. Mis- 2002), and GxEN-box (Castro et al.