Accepted Manuscript1.0
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Volunteers Sought for New Youth Running Series
TONIGHT Clear. Low of 13. Search for The Westfield News The WestfieldNews Search for The Westfield News “I DO NOT Westfield350.com The WestfieldNews Serving Westfield, Southwick, and surrounding Hilltowns “TIME ISUNDERSTAND THE ONLY WEATHER CRITIC THEWITHOUT WORLD , TONIGHT AMBITIONBUT I WATCH.” Partly Cloudy. ITSJOHN PROGRESS STEINBECK .” Low of 55. www.thewestfieldnews.com Search for The Westfield News Westfield350.comWestfield350.org The WestfieldNews — KaTHERINE ANNE PORTER “TIME IS THE ONLY VOL. 86 NO. 151 Serving Westfield,TUESDAY, Southwick, JUNE 27, and2017 surrounding Hilltowns 75 cents VOL.88WEATHER NO. 53 MONDAY, MARCH 4, 2019 CRITIC75 CentsWITHOUT TONIGHT AMBITION.” Partly Cloudy. JOHN STEINBECK Low of 55. www.thewestfieldnews.com Attention Westfield: Open Space VOL. 86 NO. 151 75 cents Let’s ‘Retire the Fire!’ CommitteeTUESDAY, JUNE 27, 2017 By TINA GORMAN discussing Executive Director Westfield Council On Aging With support from the changes at Westfield Fire Department, the Westfield Public Safety Communication Center, the next meeting Westfield News, the Westfield By GREG FITZPATRICK Rotary Club, and Mayor Brian Correspondent Sullivan, the Westfield Council SOUTHWICK – The Open On Aging is once again launch- Space Committee is holding ing its annual Retire the Fire! another meeting on Wednesday at fire prevention and safety cam- 7 p.m. at the Southwick Town paign for the City’s older Hall. TINA GORMAN According to Open Space adults. During the week of Executive Director March 4 to 8, residents of Committee Chairman Dennis Westfield Council Clark, the meeting will consist of Westfield will see Retire the On Aging Fire! flyers hung throughout reviewing at the changes that have the City and buttons with the been made to the plan, including Sunny Sunday Skier at Stanley Park slogan worn by Council On Aging staff, seniors, and the new mapping that will be Kim Saffer of Westfield gets in some cross-country ski practice on a sunny community leaders. -

The Rebirth of Slick: Clinton, Travolta, and Recuperations of Hard-Body Nationhood in the 1990S
THE REBIRTH OF SLICK: CLINTON, TRAVOLTA, AND RECUPERATIONS OF HARD-BODY NATIONHOOD IN THE 1990S Nathan Titman A Thesis Submitted to the Graduate College of Bowling Green State University in partial fulfillment of the requirements for the degree of MASTER OF ARTS August 2006 Committee: Dr. Simon Morgan-Russell, Advisor Dr. Philip Terrie ii ABSTRACT Simon Morgan-Russell, Advisor This thesis analyzes the characters and performances of John Travolta throughout the 1990s and examines how the actor's celebrity persona comments on the shifting meanings of masculinity that emerged in a post-Reagan cultural landscape. A critical analysis of President Clinton's multiple identities⎯in terms of gender, class, and race⎯demonstrates that his popularity in the 1990s resulted from his ability to continue Reagan's "hard-body" masculine national identity while seemingly responding to its more radical aspects. The paper examines how Travolta's own complex identity contributes to the emergent "sensitive patriarch" model for American masculinity that allows contradictory attitudes and identities to coexist. Starting with his iconic turn in 1977's Saturday Night Fever, a diachronic analysis of Travolta's film career shows that his ability to convey femininity, blackness, and working-class experience alongside more normative signifiers of white middle-class masculinity explains why he failed to satisfy the "hard-body" aesthetic of the 1980s, yet reemerged as a valued Hollywood commodity after neoconservative social concerns began emphasizing family values and white male responsibility in the 1990s. A study of the roles that Travolta played in the 1990s demonstrates that he, like Clinton, represented the white male body's potential to act as the benevolent patriarchal figure in a culture increasingly cognizant of its diversity, while justifying the continued cultural dominance of white middle-class males. -

Race in Hollywood: Quantifying the Effect of Race on Movie Performance
Race in Hollywood: Quantifying the Effect of Race on Movie Performance Kaden Lee Brown University 20 December 2014 Abstract I. Introduction This study investigates the effect of a movie’s racial The underrepresentation of minorities in Hollywood composition on three aspects of its performance: ticket films has long been an issue of social discussion and sales, critical reception, and audience satisfaction. Movies discontent. According to the Census Bureau, minorities featuring minority actors are classified as either composed 37.4% of the U.S. population in 2013, up ‘nonwhite films’ or ‘black films,’ with black films defined from 32.6% in 2004.3 Despite this, a study from USC’s as movies featuring predominantly black actors with Media, Diversity, & Social Change Initiative found that white actors playing peripheral roles. After controlling among 600 popular films, only 25.9% of speaking for various production, distribution, and industry factors, characters were from minority groups (Smith, Choueiti the study finds no statistically significant differences & Pieper 2013). Minorities are even more between films starring white and nonwhite leading actors underrepresented in top roles. Only 15.5% of 1,070 in all three aspects of movie performance. In contrast, movies released from 2004-2013 featured a minority black films outperform in estimated ticket sales by actor in the leading role. almost 40% and earn 5-6 more points on Metacritic’s Directors and production studios have often been 100-point Metascore, a composite score of various movie criticized for ‘whitewashing’ major films. In December critics’ reviews. 1 However, the black film factor reduces 2014, director Ridley Scott faced scrutiny for his movie the film’s Internet Movie Database (IMDb) user rating 2 by 0.6 points out of a scale of 10. -
Businesses Sought for Career Fair
TONIGHT Mostly Cloudy. Low of 44. Search for The Westfield News The WestfieldNews Search for The Westfield News Westfield350.com1913 Towne spentThe WestfieldNews “COMPUTERS $1,150 for drinking Serving Westfield, Southwick, and surrounding Hilltowns “TIMEARE IS USELESSTHE ONLY . WEATHER fountain at Depot THEYCRITIC C ANWITHOUT ONLY GIVE YOU ANSWERS TONIGHT Square. AMBITION.”.” Partly Cloudy. JOHN STEINBECK Low of 55. www.thewestfieldnews.com Search— Pab forLO The P WestfieldICASSO News Westfield350.comWestfield350.org The WestfieldNews VOL. 86 NO. 151 Serving Westfield, Southwick,TUESDAY, JUNE and 27, surrounding 2017 Hilltowns “TIME 75 IS centsTHE ONLY WEATHER CRITIC WITHOUT VOL.88TONIGHT NO. 81 MONDAY, APRIL 8, 2019 75AMBITION Cents .” Partly Cloudy. JOHN STEINBECK Low of 55. www.thewestfieldnews.com BusinessesVOL. 86 NO. 151 sought forTUESDAY, career JUNE 27, 2017 fair 75 cents By LORI SZEPELAK yet, to come back and work here if they For the third year, Beth Cardillo, execu- Correspondent choose a college pathway.” tive director, Armbrook Village in Westfield, WESTFIELD-Students at Westfield High Phelon noted that while some businesses has participated in the event. School and Westfield Technical Academy may benefit “immediately,” most businesses “We have so many jobs at Armbrook will be introduced to more than 30 local “may or may not see a benefit for two to four Village,” said Cardillo, adding “we are very companies during the Westfield Education to years.” hooked into the schools because our wait Business Alliance High School Career Fair “This fair is also for the businesses to staff is high school kids.” on April 25. engage with the students about the various Also, Cardillo said that because many of The 8 to 10:30 a.m. -

Contemporary Cyberpunk in Visual Culture: Identity and Mind/Body Dualism
Contemporary Cyberpunk in Visual Culture: Identity and Mind/Body Dualism 6/3/2019 Contemporary Cyberpunk in Visual Culture Identity and Mind/Body Dualism Benjamin, R. W. Jørgensen and Morten, G. Mortensen Steen Ledet Christensen Master’s Thesis Aalborg University Contemporary Cyberpunk in Visual Culture: Identity and Mind/Body Dualism Abstract In this world of increasing integration with technology, what does it mean to be human and to have your own identity? This paper aims to examine representations of the body and mind related to identity in contemporary cyberpunk. Using three examples of contemporary cyberpunk, Ghost in the Shell (2017), Blade Runner 2049 (2018), and Altered Carbon (2018), this paper focuses on identity in cyberpunk visual culture. The three entries are part of established cyberpunk franchises helped launch cyberpunk into the mainstream as a genre. The three works are important as they represent contemporary developments in cyberpunk and garnered mainstream attention in the West, though not necessarily due to critical acclaim. The paper uses previously established theory by Katherine Hayles and Donna Haraway and expanding upon them into contemporary theory by Graham Murphy and Lars Schmeink, and Sherryl Vint. We make use of the terms posthumanism, transhumanism, dystopia, Cartesian mind/body dualism, embodiment, and disembodiment to analyse our works. These terms have been collected from a variety of sources including anthologies, books and compilations by established cyberpunk and science fiction theorists. A literary review compares and accounts for the terms and their use within the paper. The paper finds the same questions regarding identity and subjectivity in the three works as in older cyberpunk visual culture, but they differ in how they are answered. -

Has Akira Always Been a Cyberpunk Comic?
arts Article Has Akira Always Been a Cyberpunk Comic? Martin de la Iglesia ID Institute of European Art History, Heidelberg University, Heidelberg 69117, Germany; [email protected] Received: 14 May 2018; Accepted: 12 July 2018; Published: 1 August 2018 Abstract: Between the late 1980s and early 1990s, interest in the cyberpunk genre peaked in the Western world, perhaps most evidently when Terminator 2: Judgment Day became the highest-grossing film of 1991. It has been argued that the translation of Katsuhiro Otomo’s¯ manga Akira into several European languages at just that time (into English beginning in 1988, into French, Italian, and Spanish beginning in 1990, and into German beginning in 1991) was no coincidence. In hindsight, cyberpunk tropes are easily identified in Akira to the extent that it is nowadays widely regarded as a classic cyberpunk comic. But has this always been the case? When Akira was first published in America and Europe, did readers see it as part of a wave of cyberpunk fiction? Did they draw the connections to previous works of the cyberpunk genre across different media that today seem obvious? In this paper, magazine reviews of Akira in English and German from the time when it first came out in these languages will be analysed in order to gauge the past readers’ genre awareness. The attribution of the cyberpunk label to Akira competed with others such as the post-apocalyptic, or science fiction in general. Alternatively, Akira was sometimes regarded as an exceptional, novel work that transcended genre boundaries. In contrast, reviewers of the Akira anime adaptation, which was released at roughly the same time as the manga in the West (1989 in Germany and the United States), more readily drew comparisons to other cyberpunk films such as Blade Runner. -

Download It, and Transcribe It with the to Create a Network of Arab Correspon- Subscribe to Our Print Edition
Vol. 54 No. 4 NIEMAN REPORTS Winter 2000 THE NIEMAN FOUNDATION FOR JOURNALISM AT HARVARD UNIVERSITY 4 The Internet, Technology and Journalism Peering Into the 6 Technology Is Changing Journalism BY TOM REGAN Digital Future 9 The Beginning (and End) of an Internet Beat BY ELIZABETH WEISE 11 Digitization and the News BY NANCY HICKS MAYNARD 13 The Internet, the Law, and the Press BY ADAM LIPTAK 15 Meeting at the Internet’s Town Square EXCERPTS FROM A SPEECH BY DAN RATHER 17 Why the Internet Is (Mostly) Good for News BY LEE RAINIE 19 Taming Online News for Wall Street BY ARTHUR E. ROWSE 21 While TV Blundered on Election Night, the Internet Gained Users BY HUGH CARTER DONAHUE, STEVEN SCHNEIDER, AND KIRSTEN FOOT 23 Preserving the Old While Adapting to What’s New BY KENNY IRBY 25 Wanted: a 21st Century Journalist BY PATTI BRECKENRIDGE 28 Is Including E-Mail Addresses in Reporters’ Bylines a Good Idea? BY MARK SEIBEL 29 Responding to E-Mail Is an Unrealistic Expectation BY BETTY BAYÉ 30 Interactivity—Via E-Mail—Is Just What Journalism Needs BY TOM REGAN 30 E-Mail Deluge EXCERPT FROM AN ARTICLE BY D.C. DENISON Financing News in 31 On the Web, It’s Survival of the Biggest BY MARK SAUTER The Internet Era 33 Merging Media to Create an Interactive Market EXCERPT FROM A SPEECH BY JACK FULLER 35 Web Journalism Crosses Many Traditional Lines BY DAVID WEIR 37 Independent Journalism Meets Business Realities on the Web BY DANNY SCHECHTER 41 Economics 101 of Internet News BY JAY SMALL 43 The Web Pulled Viewers Away From the Olympic Games BY GERALD B. -

Stockpile of Enriched Uranium to Surpass 300 Kg by June 27
WWW.TEHRANTIMES.COM I N T E R N A T I O N A L D A I L Y Pages Price 40,000 Rials 1.00 EURO 4.00 AED 39th year No.13414 Tuesday JUNE 18, 2019 Khordad 28, 1398 Shawwal 14, 1440 SNSC secretary reveals Iran’s Russia to boost trade Ivankovic on his way out Jagran festival to hold discovery, annihilation of with Iran with easy of Persepolis, Afshin filmmaker Derakhshandeh CIA’s cyber network 2 visa procedures 2 Ghotbi on radar 15 retrospective 16 IMIDRO to establish consortium to Stockpile of enriched uranium accelerate exploration projects TEHRAN — Head of Iranian Mines quoted Khodadad Gharibpour as saying and Mining Industries Development on Monday. and Renovation Organization (IMID- According to the official, based on RO) said the organization is planning the mining potentials and research to surpass 300 kg by June 27 to establish a consortium in order to and academic capabilities of the accelerate exploration projects in the country’s provinces, 10 mining re- mining sector. gions have been defined in order to See page 2 “The consortium is going to help us manage projects and also utilize the in areas like exploration and identifica- country’s academic potentials in this tion of new mines and minerals,” ILNA industry. 4 If Iran does something it will ‘bravely’ announce it, military chief says TEHRAN – Iran will “bravely” announce important Strait of Hormuz. Roughly 30% it if it does something, Armed Forces Chief of the world’s sea-borne crude oil passes of Staff Mohammad Bagheri announced through the strategic choke point. -

Surrogates’ Deserves a Replacement by Zachary Drucker Well Essentially Reprises the Stale Role of the Her Surrogate
Page 6 Arts & Life The Clarion | Oct. 2, 2009 Film Review: ‘Surrogates’ deserves a replacement by Zachary Drucker well essentially reprises the stale role of the her surrogate. Tufts Daily robot inventor, Dr. Alfred Lanning, that he Neither Willis nor Mitchell does Mostow U-Wire Content portrayed in “I, Robot.”) Finally, the fi lm any favors, as Willis proves unable to earn openly contradicts itself: It defi nes surro- the audience’s sympathy through a passion- gates as only responding to the DNA and less, robotic performance that rivals the Let’s try a simple exercise: Rack your neurotransmitters of their specifi c owners, emotionless of the surrogates themselves. brain and try to remember watching “The but it then allows foreign human operators Not even Willis’ sandy-blonde locks and Matrix” (1999) and “I, Robot” (2004). to occupy others’ surrogates. “Benjamin Button” anti-aging cream can Now, slowly strip away all the riveting With a running time of only 88 minutes, help him salvage his deteriorating acting and aesthetic scenes of these two fi lms and “Surrogates” does not have nearly enough skills. Similarly, Mitchell provides a forget- voila! You have basically seen Bruce Willis’ action to sate the thirsts of the average table portrayal as Willis’ partner surrogate, latest fi lm, “Surrogates.” moviegoer. Aside from one scene in which which becomes occupied by several differ- “Surrogates” attempts to creatively a one-armed, gun-toting Greer surrogate ent human operators throughout the fi lm. critique society’s reliance on technology chases after a meatbag suspect, the fi lm Perhaps the most heinous crime com- but succumbs to numerous plot gaps and is virtually devoid of explosions, crashes, mitted by “Surrogates” is that it squanders abysmal acting. -

Cyberpunk in a Transnational Context
arts Cyberpunk in a Transnational Context Edited by Takayuki Tatsumi Printed Edition of the Special Issue Published in Arts www.mdpi.com/journal/arts Cyberpunk in a Transnational Context Cyberpunk in a Transnational Context Special Issue Editor Takayuki Tatsumi MDPI • Basel • Beijing • Wuhan • Barcelona • Belgrade Special Issue Editor Takayuki Tatsumi Keio University Japan Editorial Office MDPI St. Alban-Anlage 66 4052 Basel, Switzerland This is a reprint of articles from the Special Issue published online in the open access journal Arts (ISSN 2076-0752) from 2018 to 2019 (available at: https://www.mdpi.com/journal/arts/special issues/cyberpunk) For citation purposes, cite each article independently as indicated on the article page online and as indicated below: LastName, A.A.; LastName, B.B.; LastName, C.C. Article Title. Journal Name Year, Article Number, Page Range. ISBN 978-3-03921-421-1 (Pbk) ISBN 978-3-03921–422-8 (PDF) Cover image courtesy of ni ka: ”Hikari” (Light). c 2019 by the authors. Articles in this book are Open Access and distributed under the Creative Commons Attribution (CC BY) license, which allows users to download, copy and build upon published articles, as long as the author and publisher are properly credited, which ensures maximum dissemination and a wider impact of our publications. The book as a whole is distributed by MDPI under the terms and conditions of the Creative Commons license CC BY-NC-ND. Contents About the Special Issue Editor ...................................... vii Preface to ”Cyberpunk in a Transnational Context” .......................... ix Takayuki Tatsumi The Future of Cyberpunk Criticism: Introduction to Transpacific Cyberpunk Reprinted from: Arts 2019, 8, 40, doi:10.3390/arts8010040 ...................... -
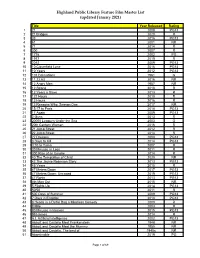
Highland Public Library Feature Film Master List (Updated January 2021)
Highland Public Library Feature Film Master List (updated January 2021) Title Year Released Rating 1 21 2008 PG13 2 21 Bridges 2020 R 3 33 2016 PG13 4 61 2001 NR 5 71 2014 R 6 300 2007 R 7 1776 2002 PG 8 1917 2019 R 9 2012 2009 PG13 10 10 Cloverfield Lane 2016 PG13 11 10 Years 2012 PG13 12 101 Dalmatians 1961 G 13 11.22.63 2016 NR 14 12 Angry Men 1957 NR 15 12 Strong 2018 R 16 12 Years a Slave 2013 R 17 127 Hours 2010 R 18 13 Hours 2016 R 19 13 Reasons Why: Season One 2017 NR 20 15:17 to Paris 2018 PG13 21 17 Again 2009 PG13 22 2 Guns 2013 R 23 20000 Leagues Under the Sea 2003 G 24 20th Century Women 2016 R 25 21 Jump Street 2012 R 26 22 Jump Street 2014 R 27 27 Dresses 2008 PG13 28 3 Days to Kill 2014 PG13 29 3:10 to Yuma 2007 R 30 30 Minutes or Less 2011 R 31 300 Rise of an Empire 2014 R 32 40 The Temptation of Christ 2020 NR 33 42 The Jackie Robinson Story 2013 PG13 34 45 Years 2015 R 35 47 Meters Down 2017 PG13 36 47 Meters Down: Uncaged 2019 PG13 37 47 Ronin 2013 PG13 38 4th Man Out 2015 NR 39 5 Flights Up 2014 PG13 40 50/50 2011 R 41 500 Days of Summer 2009 PG13 42 7 Days in Entebbe 2018 PG13 43 8 Heads in a Duffel Bag a Mindless Comedy 2000 R 44 8 Mile 2003 R 45 90 Minutes in Heaven 2015 PG13 46 99 Homes 2014 R 47 A.I. -

Richard Marvin
RICHARD MARVIN MOTION PICTURES STREET DOGS OF SOUTH Vincent Ueber, Bill Marin, prods. CENTRAL (documentary) Bill Marin , dir. Lions Gate Films A FORK IN THE ROAD Paul F. Bernard, Jim Kouf, prod. Gravitas Ventures Jim Kouf, dir. SURROGATES Max Handelman, David Hoberman, prods. Touchstone Pictures Jonathan Mostow, dir. THE NARROWS Ami Armstrong, Tatiana Blackington, prods. Olympus Pictures Francois Velle, dir. THE BATTLE OF SHAKER HEIGHTS Jeff Balis, Chris Moore, prod. Live Planet Efram Potelle, Kyla Rankin, dir. DESERT SAINTS Meg Ryan, Nina R. Sadowsky, prods. 20 th Century Fox Richard Greenberg, dir. U-571 Martha and Dino De Laurentiis, prods. Universal Pictures Jonathan Mostow, dir. BREAKDOWN Martha and Dino De Laurentiis, prods. Dino De Laurentiis Company Jonathan Mostow, dir. 3 NINJAS KICK BACK Martha Chang, James Kang, prods. Touchstone Pictures Charles T. Kanganis, dir. 3 NINJAS Martha Chang, Yuriko Matsubara, prods. Touchstone Pictures Jon Turteltaub, dir. MOTION PICTURES – VIDEO DEAD LIKE ME Sara Berrisford, Hudson Hickman , prod. MGM Stephen Herek, dir. PICTURE THIS Patrick Hughes, Brian Reilly, prod. MGM Stephen Herek, dir. PROTECTION Lee Faulkner, prod. Alliance Atlantis Communications John Flynn, dir. The Gorfaine/Schwartz Agency, Inc. (818) 260-8500 1 RICHARD MARVIN DEAD MEN CAN’T DANCE Elaine Hastings Edell, prod. City Entertainment Stephen Anderson, dir. THE LEGEND OF GALGAMETH Martha Chang, prod. Sheen Communications Sean McNamara, dir. AURORA: OPERATION INTERCEPT Oliver G. Hess, Kevin Kallberg, prod. Trimark Pictures Paul Levine, dir. FINAL MISSION Oliver G. Hess, Kevin Kallberg, prod. Hess / Kallberg Productions Lee Redmond, dir. SAVE ME Alan Amiel, prod. Spark Films Alan Roberts, dir. INTERCEPTOR Oliver G.