Anonymizing Classification Data Using Rough Set Theory
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Joint Delay-And-Sum and Fourier Beamforming Method for High Frame Rate Ultrasound Imaging
Computer Modeling in Engineering & Sciences CMES, vol.123, no.1, pp.427-440, 2020 A Joint Delay-and-Sum and Fourier Beamforming Method for High Frame Rate Ultrasound Imaging Wei Zhao1, 2, Shuai Feng1, Yadan Wang1, Yuanguo Wang1, Zhihui Han1 and Hu Peng1, * Abstract: Frame rate is an important metric for ultrasound imaging systems, and high frame rates (HFR) benefit moving-target imaging. One common way to obtain HFR imaging is to transmit a plane wave. Delay-and-sum (DAS) beamformer is a conventional beamforming algorithm, which is simple and has been widely implemented in clinical application. Fourier beamforming is an alternative method for HFR imaging and has high levels of imaging efficiency, imaging speed, and good temporal dynamic characteristics. Nevertheless, the resolution and contrast performance of HFR imaging based on DAS or Fourier beamforming are insufficient due to the single plane wave transmission. To address this problem, a joint DAS and Fourier beamforming method is introduced in this study. The proposed method considers the different distributions of sidelobes in DAS imaging and Fourier imaging and combines the angular spectrum and DAS to reconstruct ultrasound images. The proposed method is evaluated on simulation and experimental phantom datasets to compare its performance with DAS and Fourier beamforming methods. Results demonstrate that the proposed method improves image effective dynamic range and resolution while also retaining a high frame rate of the ultrasound imaging systems. The proposed method improves the effective dynamic range along axial and lateral directions by 10 dB, compared to standard DAS and Fourier beamforming. Keywords: High frame rate imaging, delay-and-sum, Fourier transformation, angular spectrum. -

Complex As Two-Photon Fluorescence Probe for Imaging Nuclear Histidine
Electronic Supplementary Material (ESI) for Chemical Communications. This journal is © The Royal Society of Chemistry 2018 A benzoic acid terpyridine-based cyclometalated iridium (III) complex as two-photon fluorescence probe for imaging nuclear histidine Qiong Zhang¶a, Xin Lu¶a, Hui Wang¶a,c, Xiaohe Tianb*, Aidong Wangd, Hongping Zhoua, Jieying Wua and Yupeng Tiana,e* [a] Department of Chemistry, Key Laboratory of Functional Inorganic Material Chemistry of Anhui Province, Anhui University, Hefei 230601, P. R. China [b] School of Life Science, Anhui University, Hefei 230601, P.R. China [c] Department of Chemistry, Wannan Medical College, Wuhu 241002, P. R. China [d] School of Chemistry and Chemical Engeering, Huangshan University, Huangshan, P. R. China. [e] State Key Laboratory of Coordination Chemistry, Nanjing University, Nanjing 210093, P. R. China ¶ These authors contributed equally to this work. E-mail address: [email protected]; [email protected] 1 Materials and instruments ..................................................................................................................3 Optical Measurements........................................................................................................................3 Synthesis of Ir1 ..................................................................................................................................3 Synthesis of Ir2 ..................................................................................................................................4 Synthesis -

SUBSTR DESCR International Schools CAMEROON 000944
SUBSTR DESCR International Schools CAMEROON 000944 Universite Yaounde CANADA 001048 Athabasca University 005528 Augustana University College 005516 Bishops University 005525 Concordia Lutheran College 002464 Keyano College 005536 Lethbridge Comm Coll 005536 Lethbridge Community College 002466 Prairie Bible College 009294 Red Deer College 005464 Southern Alberta Inst Tech 005464 Southrn Alb Inst Tec 005464 Southrn Alberta Inst Tech 005567 Univ Alberta 005435 Univ Alberta Calgary Branch 005435 Univ Calgary 005567 University Of Alberta 005469 University Of Lethbridge 003535 Capilano College 008792 Northern Lights Community Coll 006220 Northwest Cmty Coll 002313 Okanagan College 001054 Royal Roads Military Col 002193 Selkirk Col Castlegar Campus 002194 Selkirk Col Rosemont Campus 002195 Selkirk Col Trail Campus 005454 Selkirk College 005597 Simon Fraser University 005569 University Of British Columbia 005590 University Of Victoria 006310 Vancouver Comm College 005515 Brandon University 007078 Sal Army C Booth Bib 001058 United Col Winnipeg 005575 Univ Manitoba 001058 Univ Winnipeg 001058 Wesley Col Winnipeg 005545 Mount Allison University 001051 Universite De Moncton 005578 University Of New Brunswick 005497 Memorial Univ Newfou 005511 Acadia University 005524 Dalhousie University 005478 Mount St Vincent University 005459 Nova Scotia Agricultural Coll 001052 Nova Scotia Col Art Design 005557 St Francis Xavier University 005562 St Marys University International Schools 001057 Tech Univ Nova Scotia 001049 Univ Col Cape Breton 001055 Universite -
A Modi Catory Screening Protocol for ARDS in Patients with Respiratory
A Modicatory Screening Protocol for ARDS in Patients with Respiratory Support Based on SpO2 and FiO2 Yan Xia The First Aliated Hospital of Wannan Medical College (Yijishan Hospital of Wannan Medical College) Qiancheng Xu The First Aliated Hospital of Wannan Medical College (Yijishan Hospital of Wannan Medical College) Zhiyuan Guo The First Aliated Hospital of Wannan Medical College (Yijishan Hospital of Wannan Medical College) Huijuan Zhang The First Aliated Hospital of Wannan Medical College (Yijishan Hospital of Wannan Medical College) Yingya Cao The First Aliated Hospital of Wannan Medical College (Yijishan Hospital of Wannan Medical College) Yupeng Qi The First Aliated Hospital of Wannan Medical College (Yijishan Hospital of Wannan Medical College) Qun Chen The First Aliated Hospital of Wannan Medical College (Yijishan Hospital of Wannan Medical College) Weihua Lu ( [email protected] ) The First Aliated Hospital of Wannan Medical College (Yijishan Hospital of Wannan Medical College) Research Article Keywords: ARDS, PaO2/fraction of inspired oxygen ratio, SpO2/fraction of inspired oxygen ratio, FiO2, Diagnose Posted Date: August 4th, 2021 DOI: https://doi.org/10.21203/rs.3.rs-744649/v1 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License A Modificatory Screening Protocol for ARDS in Patients with Respiratory Support Based on SpO2 and FiO2 Yan Xia, MD a; Qiancheng Xu, MD a,b; Zhiyuan Guo, MD a,b; Huijuan Zhang, MD a,b; Yingya Cao, MD a,b; Yupeng Qi, MD a,b; Qun Chen, MD a,b;Weihua Lu, MD a,b* a. Department of Critical Care Medicine, The First Affiliated Hospital of Wannan Medical College (Yijishan Hospital of Wannan Medical College), No.2, West road of Zheshan, Jinghu District, Wuhu, Anhui, 241000, China. -

A Benzoic Acid Terpyridine-Based Cyclometalated Iridium(Iii) Complex As a Two-Photon Fluorescence Probe for Imaging Nuclear Hist
ChemComm COMMUNICATION A benzoic acid terpyridine-based cyclometalated iridium(III) complex as a two-photon fluorescence Cite this: Chem. Commun., 2018, 54, 3771 probe for imaging nuclear histidine† Received 2nd February 2018, a a ab c d Accepted 14th March 2018 Qiong Zhang, ‡ Xin Lu, ‡ Hui Wang, ‡ Xiaohe Tian, * Aidong Wang, Hongping Zhou, a Jieying Wu a and Yupeng Tian *ae DOI: 10.1039/c8cc00908b rsc.li/chemcomm A series of two-photon active cyclometalated iridium(III) complexes include reduced photobleaching, autofluorescence, non-invasive (Ir1, Ir2 and Ir3) were designed. Ir1 with a two-photon action cross- excitation, and deeper tissue penetration.8–10 However, two- section of 40 GM in the NIR region has been developed for photon absorption (2PA) materials with moderate two-photon targeting intracellular histidine. Two-photon micrographs showed absorption cross-section (s) values usually possess extended that Ir1 could rapidly and selectively light up the nucleus in both p-conjugated planar structures, consequently leading to the use fixed and live cells and is capable of displaying nuclear histidine of biologically unfriendly solvents (e.g. DMSO). Therefore, the distribution in ultra-detail using a super resolution (SR) technique design and synthesis of novel fluorescent probes with histidine under stimulated emission depletion (STED) microscopy. specificity still remain a challenge.11 Recently, the use of precious-metal complexes such as Ru(II), Among the twenty amino acids, histidine is active in maintaining Ir(III) and Pt(II) as luminescent probes has attracted increasing healthy tissues and protecting nerve cells that transport messages interest due to their advantageous photophysical properties and 1,2 12 from the brain to the various other parts of the body. -

A Complete Collection of Chinese Institutes and Universities For
Study in China——All China Universities All China Universities 2019.12 Please download WeChat app and follow our official account (scan QR code below or add WeChat ID: A15810086985), to start your application journey. Study in China——All China Universities Anhui 安徽 【www.studyinanhui.com】 1. Anhui University 安徽大学 http://ahu.admissions.cn 2. University of Science and Technology of China 中国科学技术大学 http://ustc.admissions.cn 3. Hefei University of Technology 合肥工业大学 http://hfut.admissions.cn 4. Anhui University of Technology 安徽工业大学 http://ahut.admissions.cn 5. Anhui University of Science and Technology 安徽理工大学 http://aust.admissions.cn 6. Anhui Engineering University 安徽工程大学 http://ahpu.admissions.cn 7. Anhui Agricultural University 安徽农业大学 http://ahau.admissions.cn 8. Anhui Medical University 安徽医科大学 http://ahmu.admissions.cn 9. Bengbu Medical College 蚌埠医学院 http://bbmc.admissions.cn 10. Wannan Medical College 皖南医学院 http://wnmc.admissions.cn 11. Anhui University of Chinese Medicine 安徽中医药大学 http://ahtcm.admissions.cn 12. Anhui Normal University 安徽师范大学 http://ahnu.admissions.cn 13. Fuyang Normal University 阜阳师范大学 http://fynu.admissions.cn 14. Anqing Teachers College 安庆师范大学 http://aqtc.admissions.cn 15. Huaibei Normal University 淮北师范大学 http://chnu.admissions.cn Please download WeChat app and follow our official account (scan QR code below or add WeChat ID: A15810086985), to start your application journey. Study in China——All China Universities 16. Huangshan University 黄山学院 http://hsu.admissions.cn 17. Western Anhui University 皖西学院 http://wxc.admissions.cn 18. Chuzhou University 滁州学院 http://chzu.admissions.cn 19. Anhui University of Finance & Economics 安徽财经大学 http://aufe.admissions.cn 20. Suzhou University 宿州学院 http://ahszu.admissions.cn 21. -

Research Article the Effects of Sidt2 on the Inflammatory Pathway in Mouse Mesangial Cells
Hindawi Mediators of Inflammation Volume 2020, Article ID 3560793, 9 pages https://doi.org/10.1155/2020/3560793 Research Article The Effects of Sidt2 on the Inflammatory Pathway in Mouse Mesangial Cells Hui Sun,1,2 Jia-ming Ding,3 Hui-hao Zheng,4 Kang-jia Lv,3 Yun-fei Hu,1,2 Ying-hui Luo,5 Xue Wu,1,2 Wen-jun Pei,6 Li-zhuo Wang,2,7 Ming-cai Wu,7 Yao Zhang,6,7 and Jia-lin Gao 1,2,6 1Department of Endocrinology and Genetic Metabolism, Yijishan Hospital of Wannan Medical College, Wuhu 241002, China 2Institute of Endocrine and Metabolic Diseases, Yijishan Hospital of Wannan Medical College, Wuhu 241002, China 3School of Clinical Medicine, Wannan Medical College, Wuhu 241002, China 4School of Medical Imaging, Wannan Medical College, Wuhu 241002, China 5School of Pharmacy, Wannan Medical College, Wuhu 241002, China 6Anhui Province Key Laboratory of Biological Macro-molecules Research, Wannan Medical College, Wuhu 241001, China 7Department of Biochemistry and Molecular Biology, Wannan Medical College, Wuhu 241002, China Correspondence should be addressed to Jia-lin Gao; [email protected] Received 7 March 2020; Accepted 2 May 2020; Published 28 May 2020 Academic Editor: Daniela Caccamo Copyright © 2020 Hui Sun et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. In patients with chronic kidney disease, the abnormal activation of inflammatory pathways is usually an important factor leading to renal fibrosis and further deterioration of renal function. -

Trematodos Aspidogastrea Encontrados En Los Mejillones De
Nutr Hosp. 2017; 34(2):460-462 ISSN 0212-1611 - CODEN NUHOEQ S.V.R. 318 Nutrición Hospitalaria Trabajo Original Otros Trematode Aspidogastrea found in the freshwater mussels in the Yangtze River basin Trematodos Aspidogastrea encontrados en los mejillones de agua dulce en la cuenca del río Yangtze Xiaodong Zhan1, Chaopin Li1,2 and Hua Wu1 1Department of Medical Parasitology. Wannan Medical College. Wuhu, Anhu. China. 2School of Medicine. Anhui University of Science & Technology. Huainan, Anhui. China Abstract Objective: To investigate the prevalence of trematode Aspidogastrea in the freshwater mussels in the Yangtze River basin within Anhui province, China. Methods: We initially harvested the freshwater mussels living in the Yangtze River running through Anhui area, and labeled them with corre- sponding number. Then the samples were dissected for isolating the fl ukes, which were identifi ed by conventional staining. Results: Infection rate of trematode Aspidogastrea in freshwater mussels in the Yangtze River basin within the territory of Anhui province was Key words: 30.38% (103/339) in general, and a total of 912 fl ukes of Aspidogastrea were detected in the 103 mussels, with average infection rate of 8.85 for each mussel. Freshwater mussels. Aspidogastrea. Conclusion: Trematode Aspidogastrea is prevalent in the freshwater bivalves living in the Yangtze River basin running through Anhui area, and Trematode. the treamatode was identifi ed asAspidogaster sp. belong to Aspidogaste under Aspidogastridae of Aspidogastrea. Resumen Objetivo: investigar la prevalencia de trematodos Aspidogastrea en mejillones de agua dulce en la cuenca del río Yangtze en la provincia de Anhui, China. Métodos: se recogieron mejillones de agua dulce en el río Yangtze a su paso por la provincia de Anhui y se etiquetaron con su número corres- pondiente. -
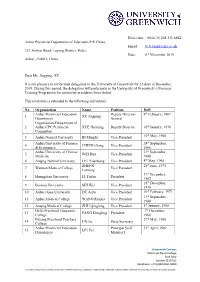
Dear Ms. Jingping, XU It Is My Pleasure to Invite Your Delegation To
Direct line: 0044 (0) 208 331 8882 Anhui Provincial Department of Education P.R China, Email: [email protected] 321 Jinzhai Road, Luyang District, Hefei, Date: 6th November 2019 Anhui, 230061, China Dear Ms. Jingping, XU It is my pleasure to invite your delegation to the University of Greenwich for 21 days in December, 2019. During this period, the delegation will participate in the University of Greenwich’s Overseas Training Programme for university presidents from Anhui. This invitation is extended to the following individuals: No. Organisation Name Position DoB Anhui Provincial Education Deputy Director- 9th February, 1967 1 XU Jingping Department General Organisation Department of 2 Anhui CPC Provincial XUE Huiming Deputy Director 10th January, 1976 Committee th 3 Anhui Normal University BI Mingfu Vice President 10 May, 1968 Anhui University of Finance 24th September, 4 CHENG Gang Vice President & Economics 1966 Anhui University of Chinese 21st September, 5 WEI Hua Vice President Medicine 1966 6 Anqing Normal University LIU Youzhong Vice President 4th May, 1965 ZHENG 28th June, 1975 7 Wannan Medical College Vice President Lanrong 31st December, 8 Huangshan University LI Tiefan President 1967 18th December, 9 Bozhou University SHI Wei Vice President 1970 10 Anhui Open University DU Aiyu Vice President 16th February, 1971 11th September, 11 Anhui Medical College WANG Runxia Vice President 1968 12 Anqing Medical College ZHU Qingfeng Vice President 5th January, 1968 Hefei Preschool Education 7th December, 13 FANG Dongling President College 1968 Fuyang Preschool Teachers 27th May, 1968 14 JIN Jie Party Secretary College Anhui Provincial Education Principal Staff 21st April, 1981 15 LIU Fei Department Member I Greenwich Campus Old Royal Naval College Park Row London SE10 9LS Telephone: +44 (0)20 8331 8000 University of Greenwich, a charity and company limited by guarantee, registered in England (reg no.986729). -

University of Leeds Chinese Accepted Institution List 2021
University of Leeds Chinese accepted Institution List 2021 This list applies to courses in: All Engineering and Computing courses School of Mathematics School of Education School of Politics and International Studies School of Sociology and Social Policy GPA Requirements 2:1 = 75-85% 2:2 = 70-80% Please visit https://courses.leeds.ac.uk to find out which courses require a 2:1 and a 2:2. Please note: This document is to be used as a guide only. Final decisions will be made by the University of Leeds admissions teams. -

The Association of Suicidal Ideation with Family Characteristics And
ORIGINAL RESEARCH published: 28 June 2021 doi: 10.3389/fpsyt.2021.653245 The Association of Suicidal Ideation With Family Characteristics and Social Support of the First Batch of Students Returning to a College During the COVID-19 Epidemic Period: A Cross Sectional Study in China Yan Chen 1,2, Li-jun Zhu 2, Zheng-mei Fang 2, Nan Wu 2, Meng-xue Du 2, Min-min Jiang 2, Jing Wang 2, Ying-shui Yao 2,3* and Cheng-chao Zhou 1,4* 1 Centre for Health Management and Policy Research, School of Public Health, Cheeloo College of Medicine, Shandong Edited by: University, Jinan, China, 2 School of Public Health, Wannan Medical College, Wuhu, China, 3 Anhui College of Traditional Mohammed A. Mamun, Chinese Medicine, Wuhu, China, 4 National Health Commission (NHC) Key Laboratory of Health Economics and Policy Centre for Health Innovation, Research, Shandong University, Jinan, China Networking, Training, Action and Research - Bangladesh, Bangladesh Reviewed by: Objective: To investigate the prevalence of suicidal ideation among the first batch Si-Tong Chen, of students returning to a college during the COVID-19 epidemic, and to explore the Victoria University, Australia Thomas Wenzel, correlation of suicidal ideation with family characteristics and social support. Medizinische Universität Wien, Austria Methods: A cluster sampling survey with a self-designed questionnaire was conducted *Correspondence: among the first batch of students returning to a college in Wuhu, China. The Positive Ying-shui Yao [email protected] and Negative Suicidal ideation (PANSI) and Social Support Scale (SSRS) were used to Cheng-chao Zhou define students’ suicidal ideation and social support, respectively. -
1 Please Read These Instructions Carefully
PLEASE READ THESE INSTRUCTIONS CAREFULLY. MISTAKES IN YOUR CSC APPLICATION COULD LEAD TO YOUR APPLICATION BEING REJECTED. Visit http://studyinchina.csc.edu.cn/#/login to CREATE AN ACCOUNT. • The online application works best with Firefox or Internet Explorer (11.0). Menu selection functions may not work with other browsers. • The online application is only available in Chinese and English. 1 • Please read this page carefully before clicking on the “Application online” tab to start your application. 2 • CLIC on the Edit Personal Details button. 3 • Fill out your personal information accurately. o Make sure to have a valid passport at the time of your application. o Use the name and date of birth that are on your passport. Use the name on your passport for all correspondences with the CLIC office or Chinese institutions. o List Canadian as your Nationality, even if you have dual citizenship. Only Canadian citizens are eligible for CLIC support. o Enter the mailing address for where you want your admission documents to be sent under Permanent Address. Leave Current Address blank. o Once you have completed this section click Verify and Save. 4 • Fill out your Education and Employment History accurately. o For Highest Education enter your current degree studies. o Once you have completed this section, click Verify and Save. 5 • Provide the contact information of the host Chinese university. o The contact information for summer programs is available on the CLIC website in the Program Finder. o For exchange programs, please contact your home university international office to get your host university contact information (http://clicstudyinchina.com/contact-us/).