Testing Perceptual Preference
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Differentiation of Physical and Chemical Cross-Linking in Gelatin Methacryloyl Hydrogels Lisa Rebers 1,+ , Raffael Reichsöllner 2,+ , Sophia Regett 1, Günter E
Supplementary Information Differentiation of Physical and Chemical Cross-Linking in Gelatin Methacryloyl Hydrogels Lisa Rebers 1,+ , Raffael Reichsöllner 2,+ , Sophia Regett 1, Günter E. M. Tovar 1,3, *, Kirsten Borchers 1,3 , Stefan Baudis 2 and Alexander Southan 1, * 1 Institute of Interfacial Process Engineering and Plasma Technology, University of Stuttgart, Stuttgart, Germany. 2 Christian Doppler Laboratory for Advanced Polymers for Biomaterials and 3D Printing, Institute of Applied Synthetic Chemistry, TU Wien, Vienna, Austria. 3 Fraunhofer Institute for Interfacial Engineering and Biotechnology, Stuttgart, Germany. * [email protected], [email protected] + These authors contributed equally. Figure S1: 1H-NMR spectra of gelatin used for methacryloylation (GM) (and acetylation (GMA)) and its derivatives. Unmodified lysine groups, only present in the spectrum of the unmodified gelatin, were highlighted in dark grey, acrylic protons of methacryloyl groups in light grey. The figure was created with Origin 2019b (https://www.originlab.com/2019b). Figure S2: Utilized temperature profile for physical gelation prior to chemical cross-linking. The 37 °C warm GM-solutions were cooled for 20 min to 21 °C followed by cooling to 4 °C 40 min (green dotted lines). Afterwards, infrared spectroscopy (IR) acquisition was started (orange dotted line) and the UV light was turned on 5 s later (blue dotted line). The figure was created with Origin 2019b (https://www.originlab.com/2019b). Figure S3: Circular dichroism (CD) spectra of gelatin ( A), GM2 ( B), GM2A8 ( C) and GM10 ( D). CD spectra were recorded at 37 °C or after cooling procedure (37 °C to 21 °C for 20 min followed by cooling to 4 °C for 40 min). -

Probabilistic Engineering Mechanics
PROBABILISTIC ENGINEERING MECHANICS AUTHOR INFORMATION PACK TABLE OF CONTENTS XXX . • Description p.1 • Audience p.2 • Impact Factor p.2 • Abstracting and Indexing p.2 • Editorial Board p.2 • Guide for Authors p.4 ISSN: 0266-8920 DESCRIPTION . This journal provides a forum for scholarly work dealing primarily with probabilistic and statistical approaches to contemporary solid/structural and fluid mechanics problems encountered in diverse technical disciplines such as aerospace, civil, marine, mechanical, and nuclear engineering. The journal aims to maintain a healthy balance between general solution techniques and problem- specific results, encouraging a fruitful exchange of ideas among disparate engineering specialities. From time to time, review papers will be published to provide research and development oriented readers with state-of-the-art analyses of various areas of current interest. In addition, occasional papers of tutorial nature help enhance practice oriented readers' knowledge of the basic probabilistic and statistical techniques that are essential in present-day engineering practice design. In consultation with the editors, distinguished members of the probabilistic mechanics community may serve as guest editors for a special issue dedicated to a particular theme. Fields Covered: Aerospace engineering: • Damage-tolerant and durability design of aircraft • Load spectra characterisation • Random vibration of aerospace structures Civil engineering: • Geotechnical applications • Natural hazards such as earthquakes, hurricanes, -

Entwicklungsplan 2025 Der Technischen Universität Wien DOKUMENTENHISTORIE
Entwicklungsplan 2025 der Technischen Universität Wien DOKUMENTENHISTORIE Version Datum Änderungen 1.0 Dezember 2017 2.0 April 2018 Tabelle 2: geplante Professuren 2018-2021 3.0 Mai 2019 Tabelle 2: geplante Professuren 2018-2021 Entwicklungsplan 2025 Wien, Dezember 2017 Entwicklungsplan der TU Wien 2025 3 von 52 HERZLICHEN DANK! Dieses Strategiepapier ist als Resultat eines durch das Rektorat der TU Wien initiierten Dialog- prozesses unter engagierter Mitwirkung von Vertreter_innen aller Personengruppen der TU Wien entstanden. Unser besonderer Dank gilt allen involvierten Personen, die einen Beitrag dazu geleistet haben. Entwicklungsplan der TU Wien 2025 4 von 52 Inhalt A AUSGANGSLAGE: EUROPÄISCHER UND NATIONALER KONTEXT 7 B MISSION UND HANDLUNGSFELDER DER TU WIEN 8 B.1 Strategische Kooperationen und Wissenstransfer 8 B.2 Grundsätze der TU Wien 9 B.3 Handlungsfelder der TU Wien 10 C HANDLUNGSFELD „GESELLSCHAFT“ 16 C.1 Ausbau des Wissens- und Innovationstransfers 16 C.2 Unterstützung des lebensbegleitenden Wissenserwerbs 19 C.3 Heranbildung des wissenschaftlichen/künstlerischen Nachwuchses 19 C.4 Förderung von Geschlechtergerechtigkeit und Diversität 21 C.5 TU Wien – Innovativer Treiber in der digitalen Transformation 22 C.6 Erschließung von philanthropen Mitteln 23 D HANDLUNGSFELD „FORSCHUNG/ENTWICKLUNG UND ERSCHLIESSUNG DER KÜNSTE“ 25 D.1 Positionierung der TU Wien als Forschungsuniversität 25 D.2 Einrichtung von Nachwuchsgruppen 26 D.3 Kooperationen mit österreichischen Hochschul- und Forschungseinrichtungen 27 D.4 Kooperationen mit -
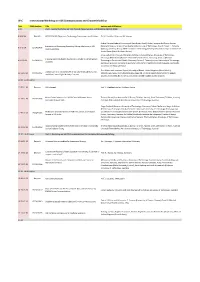
W-C International Workshop on V2X Communications and Channel Modeling
W-C International Workshop on V2X Communications and Channel Modeling Time EDAS Number Title Authors with Affiliations 9.00 Part I - Second Workshop on V2X Channel Measurements and Modeling (WVCM 2018) 9.00-9.36 Keynote H2020 5GCAR: Objectives, Technology Components and Enablers Dr. M. Condoluci, Ericsson AB, Sweden Gabriel Guieiro (Federal University of Ouro Preto, Brazil); Pedro Henrique de Oliveira Gomes Evaluation of Shadowing Caused by Mining Machinery in V2I (Federal University of Ouro Preto & Vale Institute of Technology, Brazil); Erika P. L. Almeida 9.37-9.54 1570460403 Communications (Aalborg University & INDT - Institute of Technology Development, Denmark); Luis Guilherme Uzeda Garcia (Nokia Bell Labs, France) Jonas Gedschold, Christian Schneider and Martin Käske (Ilmenau University of Technology, Germany); Mate Boban (Huawei German Research Center, Germany); Jian Luo (Huawei Tracking Based Multipath Clustering in Vehicle-to-Infrastructure 9.55-10.13 1570459752 Technologies Duesseldorf GmbH, Germany); Reiner S. Thomä (Ilmenau University of Technology, Channels Germany); Giovanni Del Galdo (Fraunhofer Institute for Integrated Circuits IIS & Technische Universität Ilmenau, Germany) Fred Wiffen and Lawrence Sayer (University of Bristol, United Kingdom (Great Britain)); Comparison of OTFS and OFDM in Ray Launched sub-6GHz and 10.13-10.30 1570463462 Mohammud Z Bocus (Toshiba Research Europe Ltd, United Kingdom (Great Britain)); Angela mmWave Line-of-Sight Mobility Channels Doufexi and Andrew Nix (University of Bristol, -

Entwicklungsplan 2025 Der Technischen Universität Wien 2
Entwicklungsplan 2025 der Technischen Universität Wien 2. überarbeitete Fassung DOKUMENTENHISTORIE Version Datum Änderungen 1.0 Dezember 2017 2.0 Dezember 2020 Entwicklungsplan 2025 Wien, Dezember 2020 Entwicklungsplan der TU Wien 2025 3 von 52 Entwicklungsplan der TU Wien 2025 4 von 52 Inhalt ABKÜRZUNGSVERZEICHNIS 6 TABELLENVERZEICHNIS 7 VORWORT ZUR 2. ÜBERARBEITETEN FASSUNG 8 A AUSGANGSLAGE: EUROPÄISCHER UND NATIONALER KONTEXT 9 B MISSION UND HANDLUNGSFELDER DER TU WIEN 10 B.1 Strategische Kooperationen und Wissenstransfer 10 B.2 Grundsätze der TU Wien 11 B.3 Handlungsfelder der TU Wien 13 C HANDLUNGSFELD „GESELLSCHAFT“ 19 C.1 Ausbau des Wissens- und Innovationstransfers 19 C.2 Unterstützung des lebensbegleitenden Wissenserwerbs 22 C.3 Heranbildung des wissenschaftlichen/künstlerischen Nachwuchses 22 C.4 Förderung von Geschlechter gerechtigkeit und Diversität 23 C.5 TU Wien – Innovativer Treiber in der digitalen Transformation 25 C.6 Erschließung von philanthropen Mitteln 27 D HANDLUNGSFELD „FORSCHUNG/ENTWICKLUNG UND ERSCHLIESSUNG DER KÜNSTE“ 28 D.1 Positionierung der TU Wien als Forschungsuniversität 28 D.2 Einrichtung von Nachwuchsgruppen 29 D.3 Kooperationen mit österreichischen Hochschul- und Forschungseinrichtungen 30 D.4 Kooperationen mit Wirtschaft und Körperschaften 31 D.5 Erhöhung der internationalen Wettbewerbsfähigkeit 31 E HANDLUNGSFELD „LEHRE UND STUDIERENDE“ 40 E.1 Profilierung des Studienangebots 40 E.2 Verbesserung der Studienbedingungen 41 E.3 Steigerung der Mobilität und Internationalität 42 E.4 Einsatz innovativer -

Research Review 2001
Integrated Systems Laboratory Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Microelectronics Design Center Research Review 2001 W. Fichtner Q. Huang H. Kaeslin N. Felber D. Aemmer Grid Adaptation for Device Simulation Automatic grid adaptation is a useful method to construct suitable simula- tion meshes, to control the solution accuracy, and to rllieve the user from manual work. The time-consuming and error-prone grid generation phase of a TCAD simulation suite can thus be shortened which reduces costs in commercial and industrial applications. Though state-of-the-art in many application areas, grid adaptation is not widely used within semiconductor device simulation because the mathematical nature of the underlying par- tial differential equations, expressed in terms of strong internal and bound- ary layers of the solutions, poses tremendous difficulties both for suitable adaptation criteria and the overall robustness of the adaptation module. In this project a novel anisotropic grid adaptation procedure for the stationary 2D drift-diffusion model has been de- veloped. It implements the Scharfetter- Gummel box method on quad-tree based boundary Delaunay grids. The major concern has been to meet practi- cal requirements by addressing the most interesting quantities as device terminal currents, to account for practi- cal simulation cases, to achieve suffi- cient robustness, and to respect cus- tomer’s use of reasonable but quite coarse simulation meshes. The ap- proach is based on estimates of the er- ror of the system dissipation rate, gained by the solution of local Dirichlet Adaptively generated mesh for a 0.18µm nMOSFET suitable for the problems or residual methods. -

Curriculum Vitae
Curriculum Vitae Name: Allan George Hanbury Born: 5 March 1974 in George, South Africa Citizenship: Irish / South African dual citizenship E-mail: [email protected] www: http://allan.hanbury.eu LinkedIn: http://at.linkedin.com/pub/allan-hanbury/6/3a2/948 Twitter: https://twitter.com/allanhanbury Orcid: https://orcid.org/0000-0002-7149-5843/ Allan Hanbury is Professor for Data Intelligence and head of the E-Commerce Research Unit in the Faculty of Informatics, TU Wien, Austria. He is also faculty member of the Complexity Science Hub Vienna. He was scientific coordinator of the EU-funded Khresmoi Project on medical and health information search and analysis, and is co-founder of contextflow, the spin- off company commercialising the radiology image search technology developed in the Khresmoi project. He is coordinator of DoSSIER, a Marie Curie Innovative Training Network, educating 15 doctoral students on domain-specific systems for information extraction and retrieval. He also coordinated the EU-funded VISCERAL project on evaluation of algorithms on big data, and the EU-funded KConnect project on technology for analysing medical text. He is author or co-author of over 160 publications in refereed journals and refereed international conferences. He contributes to research and innovation strategy development in Austria and Europe, and regularly gives talks on topics related to his research. He was born in George, South Africa in 1974. He was awarded the B.Sc. degree in Physics and Applied Mathematics in 1994, the B.Sc. (Hons) degree in Physics in 1995, and the M.Sc. degree in Physics in 1999, all from the University of Cape Town, South Africa. -

LAND UNIVERSITÄTEN ERASMUS CODE BE Université
LAND UNIVERSITÄTEN ERASMUS CODE BE Université Libre de Bruxelles B BRUXEL04 BE Ghent University B GENT01 BE Katholieke Universiteit Leuven B LEUVEN01 BE University of Antwerp B ANTWERP01 BE Université de Liège B LIEGE01 BG Bulgarian Academy of Sciences BG SOFIA30 BG Plovdiv University "PASII HILENDARSKI" BG PLOVDIV04 BG University of Architecture, Civil Engineering and Geodesy, Sofia, Bulgaria BG SOFIA04 CH Università della Svizzera italiana CH LUGANO01 CH Universität Zürich CH ZURICH01 CH Ecole Polytechnique Fédérale de Lausanne CH LAUSANN06 CH Eidgenössische Technische Hochschule Zürich CH ZURICH07 CH Fachhochschule Nordwestschweiz CH BRUGG02 CH HSR University of Applied Sciences Rapperswil CH ST.GALL08 CH School of Management and Engineering, Vaud CH DELEMON02 CH ZHAW Zurich University of Applied Sciences CH WINTER03 CY University of Nicosia CY NICOSIA14 CZ University of Pardubice CZ PARDUB01 CZ University of West Bohemia CZ PLZEN01 CZ Brno University of Technology CZ BRNO01 CZ Charles University in Prague CZ PRAHA07 CZ Czech Technical University in Prague CZ PRAHA10 CZ Masaryk University Brno CZ BRNO05 CZ Mendel University in Brno CZ BRNO02 CZ Palacký University Olomouc CZ OLOMOUC01 CZ VŠB-Technical University of Ostrava CZ OSTRAVA01 DE Universität Bremen D BREMEN01 DE Universität Kassel D KASSEL01 DE Universität Konstanz D KONSTAN01 DE Universität Leipzig D LEIPZIG01 DE Universität Paderborn D PADERBO01 DE Universität Stuttgart D STUTTGA01 DE Universität Ulm D ULM01 DE Bauhaus-Universität Weimar D WEIMAR01 DE Brandenburgische Technische -
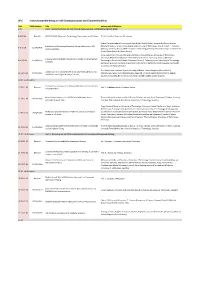
W-C International Workshop on V2X Communications and Channel Modeling
W-C International Workshop on V2X Communications and Channel Modeling Time EDAS Number Title Authors with Affiliations 9.00 Part I - Second Workshop on V2X Channel Measurements and Modeling (WVCM 2018) 9.00-9.36 Keynote H2020 5GCAR: Objectives, Technology Components and Enablers Dr. M. Condoluci, Ericsson AB, Sweden Gabriel Guieiro (Federal University of Ouro Preto, Brazil); Pedro Henrique de Oliveira Gomes Evaluation of Shadowing Caused by Mining Machinery in V2I (Federal University of Ouro Preto & Vale Institute of Technology, Brazil); Erika P. L. Almeida 9.37-9.54 1570460403 Communications (Aalborg University & INDT - Institute of Technology Development, Denmark); Luis Guilherme Uzeda Garcia (Nokia Bell Labs, France) Jonas Gedschold, Christian Schneider and Martin Käske (Ilmenau University of Technology, Germany); Mate Boban (Huawei German Research Center, Germany); Jian Luo (Huawei Tracking Based Multipath Clustering in Vehicle-to-Infrastructure 9.55-10.13 1570459752 Technologies Duesseldorf GmbH, Germany); Reiner S. Thomä (Ilmenau University of Technology, Channels Germany); Giovanni Del Galdo (Fraunhofer Institute for Integrated Circuits IIS & Technische Universität Ilmenau, Germany) Fred Wiffen and Lawrence Sayer (University of Bristol, United Kingdom (Great Britain)); Comparison of OTFS and OFDM in Ray Launched sub-6GHz and 10.13-10.30 1570463462 Mohammud Z Bocus (Toshiba Research Europe Ltd, United Kingdom (Great Britain)); Angela mmWave Line-of-Sight Mobility Channels Doufexi and Andrew Nix (University of Bristol, -

Annex 1 List of Members
Annex 1 List of members WG1 membership Name Affiliation Country Milena STAVRIC TU Graz Austria Roland BILLEN University of Liège Belgium Damir MEDAK University of Zagreb Croatia Odysseas KONTOVOURKIS University of Nicosia Cyprus Bjarne RUDIGER The Royal Danish Academy of Fine Arts Denmark Bruno TOURNAY The Royal Danish Academy of Fine Arts Denmark Mireille BATTON-HUBERT Ecole des Mines de Saint-Etienne France Jérôme GENSEL University Pierre Mendès France of France Grenoble Thomas LEDUC Institute of Science and Technics of France Nantes Giovanni RABINO Politecnico di Milano Italy Irina JACKIVA TTI of Riga Latvia Thomas PANAGOPOULOS University of Algarve Portugal Ognen MARINA University “St. Cyril and Methodius” Former Yugoslav Republic Skopje of Macedonia Bojan KARANAKOV University “St. Cyril and Methodius” Former Yugoslav Republic Skopje of Macedonia Rados SUMRADA University of Ljubljana Slovenia Gregor BERGINC University of Ljubljana Slovenia Roberto SAN JOSE Technical University of Madrid Spain André STREILEIN swisstopo Switzerland 94 3D City Models and urban information: Current issues and perspectives WG2 membership Name Affiliation Country Andrew FRANK TU Wien Austria Rizwan BULBUL TU Wien Austria Lars BODUM Aalborg University Denmark Wan WEN Aalborg University Denmark Anna ERVING Aalto University. School of Science and Finland Technology Sanna ILTANEN Tampere University of Technology Finland Anne-Francoise CUTTING-DECELLE Ecole Centrale de Lille France Bénédicte BUCHER IGN Paris France Alina Dia MIRON Joseph Fourier University of -
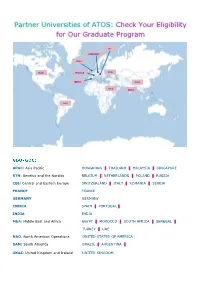
Partner Universities of ATOS: Check Your Eligibility for Our Graduate Program
Partner Universities of ATOS: Check Your Eligibility for Our Graduate Program CEE GERMANY UK&I NAO FRANCE BTN IBERIA APAC MEA INDIA SAM APAC: Asia Pacific HONGKONG THAILAND MALAYSIA SINGAPORE BTN: Benelux and the Nordics BELGIUM NETHERLANDS POLAND RUSSIA CEE: Central and Eastern Europe SWITZERLAND ITALY ROMANIA SERBIA FRANCE FRANCE GERMANY GERMANY IBERIA SPAIN PORTUGAL INDIA INDIA MEA: Middle East and Africa EGYPT MOROCCO SOUTH AFRICA SENEGAL TURKEY UAE NAO: North American Operations UNITED STATED OF AMERICA SAM: South America BRAZIL ARGENTINA UK&I: United Kingdom and Ireland UNITED KINGDOM GBU Partner University Name Location APAC City University of Hong Kong Hong Kong APAC Asia Pacific University of Malaysia Technology & Innovation APAC University Tunku Abdul Rahman Malaysia APAC Nanyang Technological University Singapore APAC National University of Singapore Singapore APAC King Mongkut’s University of Thailand Technology Thonburi APAC Mahidol University Thailand K.U. Leuven (Katholieke BTN Belgium Universiteit Leuven) ULB : Université Libre de BTN Belgium Bruxelles BTN Erasmus University Netherlands BTN University of Amsterdam Netherlands BTN University of Eindhoven Netherlands BTN University of Tilburg Netherlands Technical University Delft (west BTN Netherlands NL) BTN Technical University of Antwerp Netherlands BTN Universiteit van Utrecht Netherlands BTN Radboud University (Nijmegen) Netherlands BTN Rijks Universiteit Groningen Netherlands BTN Thomas Moore Belgium BTN Avans Hogeschool Netherlands Fontys Hogescholen (southern BTN -

Entwicklungsplan Der TU Wien 2010
Entwicklungsplan der TU Wien 2010 Technik für Menschen Wissenschaftliche Exzellenz entwickeln und umfassende Kompetenz vermitteln. Inhalt VORWORT 5 EINLeituNG 6 AUSGANGSLAGE 8 1. ALLGEMEINES 8 1.1. Universität und Standort 8 1.2. Umfeld Forschung 8 1.3. Umfeld Lehre 12 1.4. Technik und Öffentlichkeit /Technik für Menschen 17 2. ORGANISatIONSSTRUKtuR 20 2.1. Universitätsrat 22 2.2. Senat 22 2.3. Rektorat 23 2.4. Schiedskommission 23 2.5. Fakultäten 23 2.6. Besondere Dienstleistungseinrichtungen für Lehre und Forschung 25 2.7. Allgemeine Dienstleistungseinrichtungen 30 2.8. Interessenvertretungen 32 3. FORSCHUNG 35 3.1. Bestehende Forschungsschwerpunkte der Fakultäten 36 3.2. Transferleistungen 40 3.3. Internationalität und Mobilität 43 3.4. Interne und externe Kooperation 45 3.5. Evaluierung und Qualitätssicherung 49 3.6. Anreizsysteme 49 4. LEHRE 51 4.1. Studien und Curricula 51 4.2. e-Learning 52 4.3. Weiterbildung 53 4.4. Internationalität und Mobilität 54 4.5. Evaluierung und Qualitätssicherung 56 5. BETEILIGUNGEN 57 6. PERSONELLE AUSStattuNG 58 7. SaCH- UND RauMauSStattuNG 60 8. BudGETÄRE SItuatION 64 Entwicklungsplan der TU Wien 2010+ Inhalt / 2 von 181 ENtwiCKLUNG 67 1. LEItbILd 67 2. GRUNDSÄTZE DER ENtwICKLUNG 68 3. GESELLSCHaftLICHE ZIELSETZUNGEN 71 4. StRatEGISCHE ENtwICKLUNGSZIELE 75 4.1. Forschung bzw. Erschließung der Künste 75 4.2. Lehre 79 4.3. Supportprozesse und Serviceeinrichtungen 81 5. OPERatIVE ENtwICKLUNGSZIELE UND MaSSNAHMEN 84 5.1. Forschung bzw. Erschließung der Künste 84 5.1.1. Profilbildung der Forschungstätigkeit der TU Wien 84 5.1.2. Fakultätsübergreifende Forschungskooperation 94 5.1.3. Kooperation mit österreichischen Universitäten 95 5.1.4.