A Multi-Domain and Multi-Modality Event Dataset
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cruising Guide to the Philippines
Cruising Guide to the Philippines For Yachtsmen By Conant M. Webb Draft of 06/16/09 Webb - Cruising Guide to the Phillippines Page 2 INTRODUCTION The Philippines is the second largest archipelago in the world after Indonesia, with around 7,000 islands. Relatively few yachts cruise here, but there seem to be more every year. In most areas it is still rare to run across another yacht. There are pristine coral reefs, turquoise bays and snug anchorages, as well as more metropolitan delights. The Filipino people are very friendly and sometimes embarrassingly hospitable. Their culture is a unique mixture of indigenous, Spanish, Asian and American. Philippine charts are inexpensive and reasonably good. English is widely (although not universally) spoken. The cost of living is very reasonable. This book is intended to meet the particular needs of the cruising yachtsman with a boat in the 10-20 meter range. It supplements (but is not intended to replace) conventional navigational materials, a discussion of which can be found below on page 16. I have tried to make this book accurate, but responsibility for the safety of your vessel and its crew must remain yours alone. CONVENTIONS IN THIS BOOK Coordinates are given for various features to help you find them on a chart, not for uncritical use with GPS. In most cases the position is approximate, and is only given to the nearest whole minute. Where coordinates are expressed more exactly, in decimal minutes or minutes and seconds, the relevant chart is mentioned or WGS 84 is the datum used. See the References section (page 157) for specific details of the chart edition used. -

APPENDIX Lesson 1.: Introduction
APPENDIX Lesson 1.: Introduction The Academy Awards, informally known as The Oscars, are a set of awards given annually for excellence of cinematic achievements. The Oscar statuette is officially named the Academy Award of Merit and is one of nine types of Academy Awards. Organized and overseen by the Academy of Motion Picture Arts and Sciences (AMPAS),http://en.wikipedia.org/wiki/Academy_Award - cite_note-1 the awards are given each year at a formal ceremony. The AMPAS was originally conceived by Metro-Goldwyn- Mayer studio executive Louis B. Mayer as a professional honorary organization to help improve the film industry’s image and help mediate labor disputes. The awards themselves were later initiated by the Academy as awards "of merit for distinctive achievement" in the industry. The awards were first given in 1929 at a ceremony created for the awards, at the Hotel Roosevelt in Hollywood. Over the years that the award has been given, the categories presented have changed; currently Oscars are given in more than a dozen categories, and include films of various types. As one of the most prominent award ceremonies in the world, the Academy Awards ceremony is televised live in more than 100 countries annually. It is also the oldest award ceremony in the media; its equivalents, the Grammy Awards (for music), the Emmy Awards (for television), and the Tony Awards (for theater), are modeled after the Academy Awards. The 85th Academy Awards were held on February 24, 2013 at the Dolby Theatre in Los Angeles, California. Source: http://en.wikipedia.org/wiki/Academy_Award Time of downloading: 10th January, 2013. -
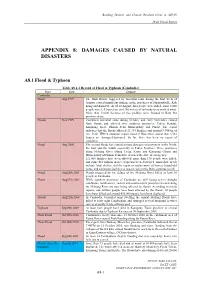
Appendix 8: Damages Caused by Natural Disasters
Building Disaster and Climate Resilient Cities in ASEAN Draft Finnal Report APPENDIX 8: DAMAGES CAUSED BY NATURAL DISASTERS A8.1 Flood & Typhoon Table A8.1.1 Record of Flood & Typhoon (Cambodia) Place Date Damage Cambodia Flood Aug 1999 The flash floods, triggered by torrential rains during the first week of August, caused significant damage in the provinces of Sihanoukville, Koh Kong and Kam Pot. As of 10 August, four people were killed, some 8,000 people were left homeless, and 200 meters of railroads were washed away. More than 12,000 hectares of rice paddies were flooded in Kam Pot province alone. Floods Nov 1999 Continued torrential rains during October and early November caused flash floods and affected five southern provinces: Takeo, Kandal, Kampong Speu, Phnom Penh Municipality and Pursat. The report indicates that the floods affected 21,334 families and around 9,900 ha of rice field. IFRC's situation report dated 9 November stated that 3,561 houses are damaged/destroyed. So far, there has been no report of casualties. Flood Aug 2000 The second floods has caused serious damages on provinces in the North, the East and the South, especially in Takeo Province. Three provinces along Mekong River (Stung Treng, Kratie and Kompong Cham) and Municipality of Phnom Penh have declared the state of emergency. 121,000 families have been affected, more than 170 people were killed, and some $10 million in rice crops has been destroyed. Immediate needs include food, shelter, and the repair or replacement of homes, household items, and sanitation facilities as water levels in the Delta continue to fall. -

Words: Corner Beam-Column Joint; Hysteresis Loops; Seismic Design; Ductility; Stiffness; Equivalent Viscous Damping
Journal of Mechanical Engineering Vol 16(1), 213-226, 2019 Validation of Corner Beam-column Joint’s Hysteresis Loops between Experimental and Modelled using HYSTERES Program N.F. Hadi, M. Mohamad Faculty of Civil Engineering, Universiti Teknologi MARA 40450 Shah Alam, Selangor, Malaysia N.H. Hamid Institute of Infrastructure Engineering Sustainability and Management Universiti Teknologi MARA 40450 Shah Alam, Selangor, Malaysia ABSTRACT The beam - column joint is an important part of a multi-storey RC building as it caters for lateral and gravitational load during an earthquake event. The beam-column joints should have a medium to high ductility for transferring the earthquake load and gravity load to the foundation. By designing multi- storey RC buildings using Eurocode 8 can avoid any diagonal shear cracks in column which is a major problem in non-seismic design buildings using British Standard (BS8110). This paper presents the experimental hysteresis loops of monolithic corner beam-column joints of multi-storey building which had been designed using Eurocode 8 and tested under in-plane lateral cyclic loading. The experimental hysteresis loops of corner beam-column joint was compared with modelled using the HYSTERES program. The full-scale corner beam- column joint of a two story precast school building was designed, constructed, tested and modelled is presented herein. The seismic performance parameters such as lateral strength capacity, stiffness, ductility and equivalent viscous damping were compared between experimental and modelled hysteresis loops. The experimental hysteresis loops have similar shape with the modeling hysteresis loops with small percentage differences between them. Keywords: Corner beam-column joint; hysteresis loops; seismic design; ductility; stiffness; equivalent viscous damping ___________________ ISSN 1823-5514, eISSN2550-164X Received for review: 2017-07-10 © 2016 Faculty of Mechanical Engineering, Accepted for publication: 2018-05-18 Universiti Teknologi MARA (UiTM), Malaysia. -

Dramaturgies of Power a Dissertat
UNIVERSITY OF CALIFORNIA, SAN DIEGO UNIVERSITY OF CALIFORNIA, IRVINE The Master of Ceremonies: Dramaturgies of Power A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Drama and Theatre by Laura Anne Brueckner Committee in charge: University of California, San Diego Professor James Carmody, Chair Professor Judith Dolan Professor Manuel Rotenberg Professor Ted Shank Professor Janet Smarr University of California, Irvine Professor Ian Munro 2014 © Laura Anne Brueckner, 2014 All rights reserved The Dissertation of Laura Anne Brueckner is approved, and it is acceptable in quality and form for publication on microfilm and electronically: ___________________________________________________________ ___________________________________________________________ ___________________________________________________________ ___________________________________________________________ ___________________________________________________________ ___________________________________________________________ Chair University of California, San Diego University of California, Irvine 2014 iii DEDICATION This study is dedicated in large to the sprawling, variegated community of variety performers, whose work—rarely recorded and rarely examined, so often vanishing into thin air—reveals so much about the workings of our heads and hearts and My committee chair Jim Carmody, whose astonishing insight, intelligence, pragmatism, and support has given me a model for the kind of teacher I hope to be and Christopher -

Natural Disasters 48
ECOLOGICAL THREAT REGISTER THREAT ECOLOGICAL ECOLOGICAL THREAT REGISTER 2020 2020 UNDERSTANDING ECOLOGICAL THREATS, RESILIENCE AND PEACE Institute for Economics & Peace Quantifying Peace and its Benefits The Institute for Economics & Peace (IEP) is an independent, non-partisan, non-profit think tank dedicated to shifting the world’s focus to peace as a positive, achievable, and tangible measure of human well-being and progress. IEP achieves its goals by developing new conceptual frameworks to define peacefulness; providing metrics for measuring peace; and uncovering the relationships between business, peace and prosperity as well as promoting a better understanding of the cultural, economic and political factors that create peace. IEP is headquartered in Sydney, with offices in New York, The Hague, Mexico City, Brussels and Harare. It works with a wide range of partners internationally and collaborates with intergovernmental organisations on measuring and communicating the economic value of peace. For more information visit www.economicsandpeace.org Please cite this report as: Institute for Economics & Peace. Ecological Threat Register 2020: Understanding Ecological Threats, Resilience and Peace, Sydney, September 2020. Available from: http://visionofhumanity.org/reports (accessed Date Month Year). SPECIAL THANKS to Mercy Corps, the Stimson Center, UN75, GCSP and the Institute for Climate and Peace for their cooperation in the launch, PR and marketing activities of the Ecological Threat Register. Contents EXECUTIVE SUMMARY 2 Key Findings -

Cover 2Nd Asean Env Report 2000
SecondSecond ASEANASEAN State State ofof thethe EnvironmentEnvironment ReportReport 20002000 Second ASEAN State of the Environment Report 2000 Our Heritage Our Future Second ASEAN State of the Environment Report 2000 Published by the ASEAN Secretariat For information on publications, contact: Public Information Unit, The ASEAN Secretariat 70 A Jalan Sisingamangaraja, Jakarta 12110, Indonesia Phone: (6221) 724-3372, 726-2991 Fax : (6221) 739-8234, 724-3504 ASEAN website: http://www.aseansec.org The preparation of the Second ASEAN State of the Environment Report 2000 was supervised and co- ordinated by the ASEAN Secretariat. The following focal agencies co-ordinated national inputs from the respective ASEAN member countries: Ministry of Development, Negara Brunei Darussalam; Ministry of Environment, Royal Kingdom of Cambodia; Ministry of State for Environment, Republic of Indonesia; Science, Technology and Environment Agency, Lao People’s Democratic Republic; Ministry of Science Technology and the Environment, Malaysia; National Commission for Environmental Affairs, Union of Myanmar; Department of Environment and Natural Resources, Republic of the Philippines; Ministry of Environment, Republic of Singapore; Ministry of Science, Technology and the Environment, Royal Kingdom of Thailand; and Ministry of Science, Technology and the Environment, Socialist Republic of Viet Nam. The ASEAN Secretariat wishes to express its sincere appreciation to UNEP for the generous financial support provided for the preparation of this Report. The ASEAN Secretariat also wishes to express its sincere appreciation to the experts, officials, institutions and numerous individuals who contributed to the preparation of the Report. Every effort has been made to ensure the accuracy of the information presented, and to fully acknowledge all sources of information, graphics and photographs used in the Report. -

Effect of Fine Content on Soil Dynamic Properties
Journal of Engineering Science and Technology Vol. 13, No. 4 (2018) 851 - 861 © School of Engineering, Taylor’s University EFFECT OF FINE CONTENT ON SOIL DYNAMIC PROPERTIES J. X. LIM, M. L. LEE*, Y. TANAKA Department of Civil Engineering, Lee Kong Chian Faculty of Engineering and Science, Universiti Tunku Abdul Rahman, 43000, Kajang, Selangor DE, Malaysia *Corresponding Author: [email protected] Abstract Dynamic properties of soil have attracted an increasing attention among geotechnical engineers in Malaysia owing to the frequent earthquake incidents reported recently and the demand of high speed railway infrastructures. The present study investigated the effect of fine content on the soil dynamic properties based on three selected soils in Malaysia. One sand mining trail (i.e. silty sand) and two tropical residual soils (i.e. sandy clay and sandy silt) were tested on a 1 g shaking table. The experimental shear moduli were compared with the established degradation curves of sandy and clayey soils obtained from literature. The shear moduli attenuated with the increase of shear strain amplitude for the three soil samples. The amount of fine content in the soil was found to be a more dominant factor affecting the dynamic properties of soil compared with the plasticity and geological characteristics of the soil. The experimental shear moduli of sandy silt were similar to that of sandy clay. It may be attributed to the fact that the two studied residual soils have a similar amount of fine content. In addition, the shear moduli of the studied residual soils could not be fitted to the degradation curves of sand and clay which have been well studied in the past. -

GCSE Sources and Links for the Spoken Language
GCSE Sources and Links for the Spoken Language English Language Spoken Language Task Support: Sources and Links for: Interviews and Dialogue (2014) Themes N.B. Many of these sources and links have cross-over and are applicable for use as spoken language texts for: Formal v Informal (2015) Themes. As far as possible this feature has been identified in the summary and content explanation in the relevant section below. Newspaper Sources: The Daily Telegraph ( British broadsheet newspaper) website link: www.telegraph.co.uk. This site/source has an excellent archive of relevant, accessible clips and interviews. The Guardian ( British broadsheet newspaper) website and link to their section dedicated to: Great Interviews of the 20th Century Link: http://www.theguardian.com/theguardian/series/greatinterviews This cites iconic interviews, such as: The Nixon interview is an excellent example of a formal spoken language text and can be used alongside an informal political text ( see link under ‘Political Speech’) such as Barack Obama chatting informally in a pub or his interview at home with his wife Michelle. Richard Nixon interview with David Frost Link: Youtube http://www.youtube.com/watch?v=2c4DBXFDOtg&list=PL02A5A9ACA71E35C6 Another iconic interview can be found at the link below: Denis Potter interview with Melvyn Bragg Link: Youtube http://www.youtube.com/watch?v=oAYckQbZWbU Sources/Archive for Television Interviews: The Radio Times ( Media source with archive footage of television and radio clips). There is a chronology timeline of iconic and significant television interviews dating from 1959–2011. Link: http://www.radiotimes.com/news/2011-08-16/video-the-greatest-broadcast- interviews-of-all-time Fern Britton Meet ( BBC, 2009). -

Lehigh Preserve Institutional Repository
Lehigh Preserve Institutional Repository Embracing Islam in the Age of Terror: Post 9/11 Representations of Islam and Muslims in the United States and Personal Stories of American Converts Brunet, Clemence 2013 Find more at https://preserve.lib.lehigh.edu/ This document is brought to you for free and open access by Lehigh Preserve. It has been accepted for inclusion by an authorized administrator of Lehigh Preserve. For more information, please contact [email protected]. Embracing Islam in the Age of Terror: Post 9/11 Representations of Islam and Muslims in the United States and Personal Stories of American Converts by Clemence Brunet A Thesis Presented to the Graduate and Research Committee of Lehigh University in Candidacy for the Degree of Master of Arts in American Studies Lehigh University May 2013 i © 2013 Copyright Clemence Brunet ii Thesis is accepted and approved in partial fulfillment of the requirements for the Master of Arts in American Studies. Embracing Islam in the Age of Terror: Post 9/11 Representations of Islam and Muslims in the United States and Personal Stories of American Converts Clemence Brunet Date Approved Thesis Director Dr. Saladin Ambar Co-Director Dr. Bruce Whitehouse Department Chair Dr. Edward Whitley iii TABLE OF CONTENTS Abstract 1 Introduction 2 Chapter One: Perceptions and Representations of Islam and Muslims after 9/11: language, media, hate groups and public opinion 8 Chapter Two: Muslim terrorists in the Entertainment Media and American Jihadists in the Media 49 Chapter Three: Personal Stories and Experiences of White American converts to Islam 85 Conclusion 133 Works Cited 138 Vita 155 iv ABSTRACT The terrorist attacks of September 11, 2001 were one of the most traumatic events experienced by the American people on their soil. -

DISASTER RISK MAPPING and ASSESSMENT (GEORISK 2019) 25-27 February 2019 @ KBN, KUNDASANG, SABAH
WORKSHOP & FORUM ON GEOSPATIAL TECHNOLOGY FOR DISASTER RISK MAPPING AND ASSESSMENT (GEORISK 2019) 25-27 February 2019 @ KBN, KUNDASANG, SABAH THEME: ADVANCING SCIENCE AND TECHNOLOGY FOR DISASTER RISK REDUCTION Workshop & Forum on Geospatial DATE: Technology for Disaster Risk Mapping and 25- 27 FEBRUARY 2019 Assessment (GeoRisk2019) aims to provide an insight into modern and advanced geospatial technology fo r mapping, VENUE: analysing and assessing multi-geohazard KBN KUNDASANG,SABAH and disaster risk in a complex environment. Organized by Global and regional ca s e studies, covering Universiti Teknologi Malaysia (UTM) Kuala Lumpur several benchmarking and best practices will be interactively discussed. This co u rs e With the support of Department of Minerals and Geoscience Malaysia (JMG) addresses the importance of Department of Surveying and Mapping Malaysia (JUPEM) understanding georisk, strengthening risk Sabah Lands and Surveys Department (JTU) governance and elevating disaster Royal Institution of Surveyors Malaysia (RISM) preparedness. New, cutting-edge mapping Society for Engineering Geology and Rock Mechanics (SEGRM) technology (UAV, Terrestrial laser scanning, LiDAR, GNSS, Remote Sensing) coupling Disaster Prevention Research Institute, Kyoto University, Japan with BigData Analytics, early-warning Japan-ASEAN Science, Technology and Innovative Platform system, monitoring system and predictive Climate Change and Disaster Risk Reduction WG, modelling will be shared. Ad va n ced earth Global Young Academy (GYA) observation and geospatial data are highly International Council for Science (ISC)ROAP in demand fo r disaster mitigation, prevention, risk assessment and reduction strategies in a changing climate. GeoRisk2019 promotes an intelligent, integrated and transdisciplinary approach for reducing disaster risk, as in line with the Fee: RM800/person - 3 Days 2 nights Sendai Framework fo r Disaster Risk • Inclusive airport transfer (only limited pick-up time); accommodation @ KBN Ku nd a sa n g; daily Reduction 2015-2030 and national policies. -

CE SUM2016.Indd
Continuing Education Lifelong Learning for Everyone Summer 2016 Schedule www.com.edu/ce SUMMER HOURS CONTINUING EDUCATION OFFICE HOURS (STARTING JUNE 6 AND ENDING AUGUST 7) Monday – Tuesday 7 a.m. – 7 p.m. Wednesday – Thursday 7 a.m. – 6 p.m. 1200 Amburn Rd., Texas City, Texas 409-933-8586 COM CE: LIFELONG LEARNING FOR EVERYONE COM’s Continuing Education division provides access to innovative, fl ex- CONTINUING EDUCATION’S MISSION ible and responsive lifelong learning opportunities. Whether you desire College of the Mainland’s Continuing Education division is dedicated to to acquire new workforce skills, upgrade current skills or seek personal providing workforce development training programs, customized corpo- enrichment, we offer something for you. rate training and lifelong learning opportunities that are innovative, fl ex- ible and responsive to the needs of the diverse communities we serve. We offer career training and certifi cation courses and programs that allow you to acquire the skills needed to enter entry-level positions. CONTINUING EDUCATION’S VISION College of the Mainland’s Continuing Education division will be a vital We offer courses that will help you upgrade your current skills and community partner by providing training opportunities that prepare expand your knowledge as you seek to advance in your career. students for high-growth jobs in the future, offer educational pathways for new and incumbent workers and support continued personal and We also offer professional development courses needed for continued professional development. certifi cation in your chosen profession. HOW TO CONTACT US The Continuing Education offi ce is located in the Technical-Vocational And we offer many courses that may pique your interest in a new hobby, Building, Room TVB-1475, on the main campus.